一、Pulsar存储架构简析
Pulsar作为新一代MQ中间件,在底层架构设计上充分贯彻了存算分离的思想,broker与Bookeeper两个组件独立部署,前者负责流量的调度、聚合、计算,后者负责数据的存储,这也契合了云原生下k8s大行其道的时代背景。Bookeeper又名Bookie ,是一个单独的存储引擎。在组件关系上,broker深度依赖Bookie,内部集成了 Bookie的client端,broker和Bookie之间基于TCP通信,使用protobuf。
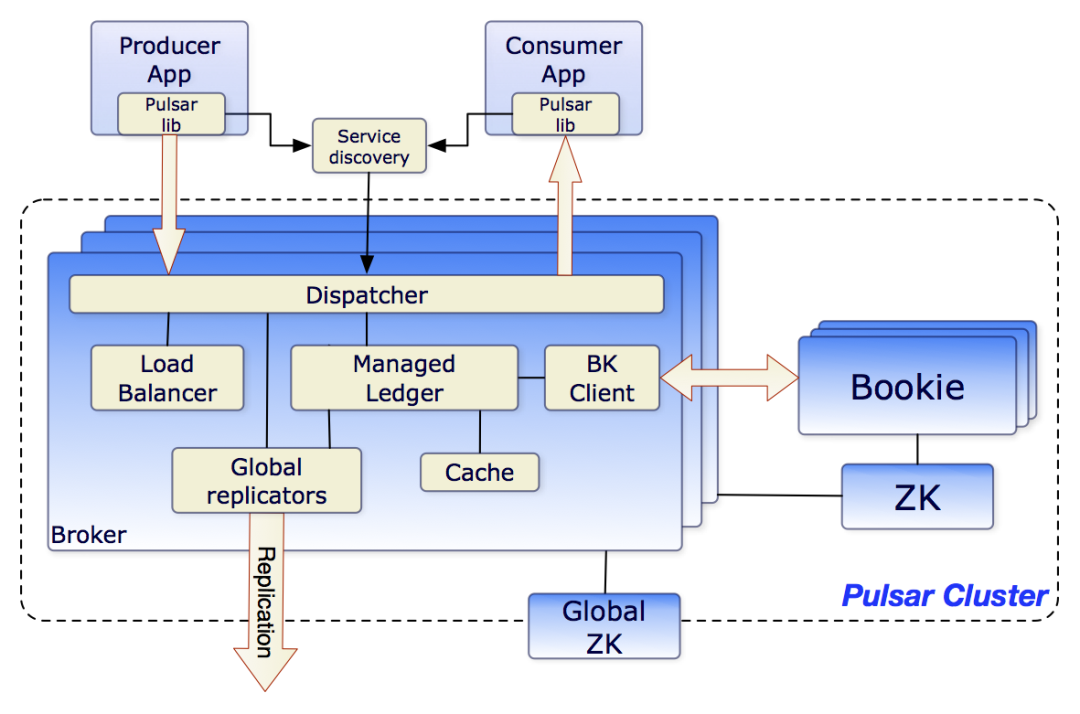
Pulsar整体架构
消息流从client端发送到broker,经过broker的计算、转化、路由后再次被分发到具体的Bookie节点,一条消息被存储几份是可配置的。数据的高可用由broker来保障而非Bookie,Bookie只是一个简单的单机存储引擎。一般而言数据多副本有两种主要的分发方式:一种是基于主从模式,主节点在收到数据写入后,将数据二次分发到从节点,从节点的数据流源头只有主节点,可以存在多个从节点,这种架构典型实现有rocketMQ ,MySQL等;另一种方式是并行多份写入多份相同的数据,在接收到SDK侧数据后进行多路分发。两种方式各有优劣,前者实现简单,但是延迟较高,在开启同步复制(异步复制可能丢数据)的情况下延迟为: master写入延迟+slave写入延迟;后者实现复杂,需要处理单节点分发失败补偿的问题,但是延迟较低,实际的写入延迟为Max(shard1写入延迟,shard2写入延迟,.....)。Pulsar的数据分发模式为后者。

Pulsar数据流架构
一个topic在时间序列上被分为多个Ledger,使用LedgerId标识,在一个物理集群中,LedgerId不会重复,采用全局分配模式,对于单个topic(分区topic)而言同一时刻只会有一个Ledger在写入,关闭的Ledger不可以写入,以topicA-partition1的 Ledgers[ledger1, ledger3, ledger7, ...., ledgerN]为例,可写入的Ledger只有N,小于N的Ledger均不可写入,单个Ledger默认可以存储5W条消息,当broker以 (3,2,2)模式写入数据时,具体架构如下图所示。3,2,2 可以解释为当前topic可以写入的节点有3个,每次数据写入2份,并且收到2个数据写入成功的ACK后才会返回响应client端。
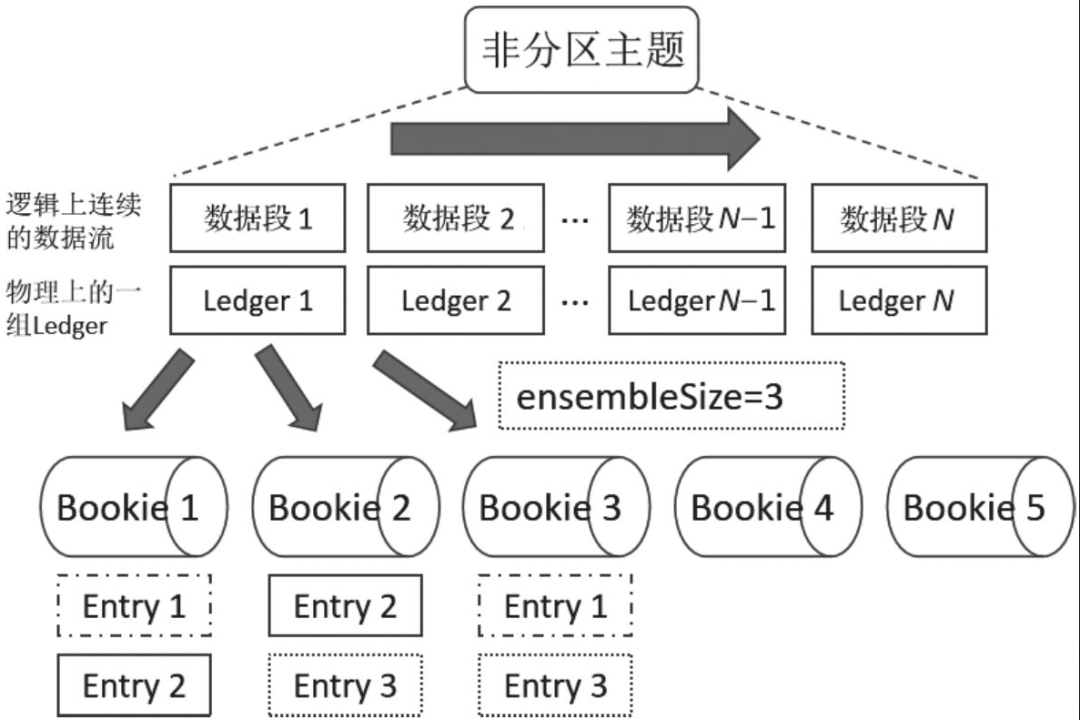
Ledger分段机制
二、Bookie的架构设计
对Pulsar的架构有了大致的了解后,我们重点剖析下Bookie这个核心的存储引擎。消息系统为了追求最大写入吞吐,一般都采用顺序写的方式来压榨磁盘的IO性能。Bookie也是一样,默认情况下Bookie的数据会写入journal日志文件,这个日志类似于MySQL中的binlog文件或者rocketMQ中的commitlog文件,采用乱序追加写的方式,存在多个topic的数据写入同一个文件的情况。
为了更好的IO隔离,官方建议journal单独挂一块盘。为了充分发挥磁盘IO性能,journal目录可以有多个,即同时存在多个并行写入的journal日志,每个journal日志会绑定一个写入线程,写入请求提交后会被归一化到某个具体线程,实现无锁化,单个消息写入是按照LedgerId对目录数量取模,决定当前数据落到哪个journal目录。journal日志落盘策略是可配置的,当配置同步落盘时,数据实时落盘后才会返回写入成功。journal日志数据写入后会确认返回写入成功,而entrylog的数据是否落盘并不影响请求的立即返回。journal和entrylog均可以配置为异步刷盘,这种情况下落盘的时序上并没有先后之分。
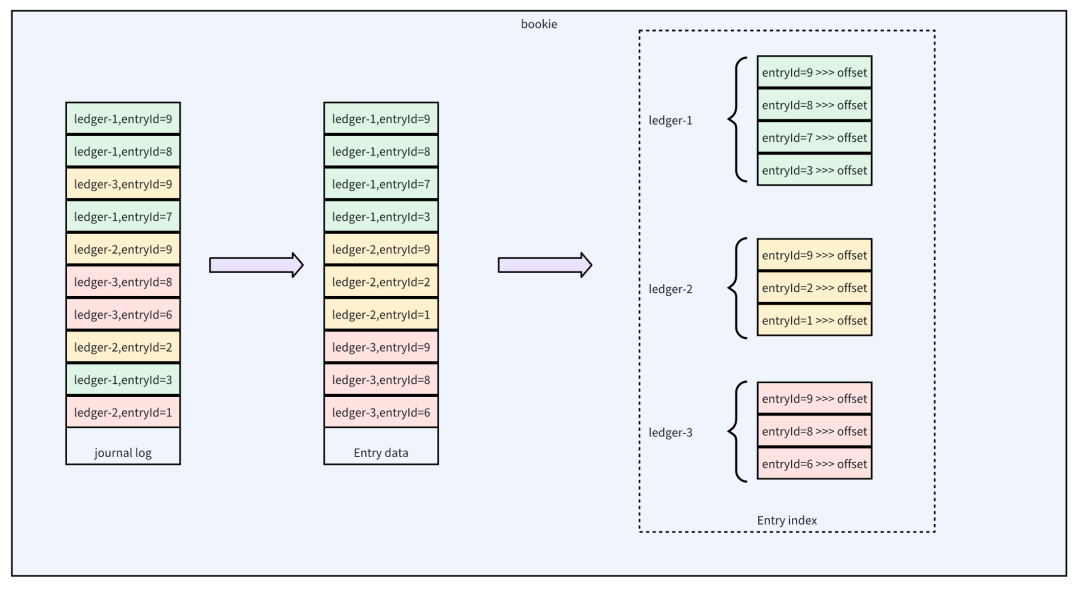
Bookie数据存储架构
Journal日志的主要作用是保证数据不丢失,同时提供足够快的性能,因此采用了混合落盘的模式。实际业务消费时,针对单个topic的数据在时间序列上是顺序消费,如果实际的数据从journal文件中读取则会出现大量的随机IO,性能较差。Bookie通过将数据进行二次转写的方式实现数据的局部有序从而提升读取性能,默认情况下一份数据在磁盘上会存两份:一份在journal日志中,一份在entry日志中。entry日志中的数据具备局部有序的特性,在一批数据刷盘时,会针对这批数据按照LedgerId,entryId进行排序后落盘。这样消费侧在消费数据时能够实现一定程度上的顺序IO,以提升性能。
entryIndex的作用是保存(LedgerId+entryId)到offset的映射关系,这里的offset是指entry data文件中的offset。
这样的一组映射关系很容易想到其在内存中的组织形式,一个map。实际的存储 Pulsar选择rocksDB来存储这样的KV关系,但Bookie本身也有自己的KV 存储实现;
通过对Bookie架构的上分析,我们发现针对读写场景Bookie做了两件事来支撑:
-
混合Ledger顺序写的journal日志支撑高吞吐低延迟的写入场景;
-
局部有序的entry data 支撑消费场景下的Ledger级别的顺序读。
三、Bookie的数据写入流程
对于Bookie的写入流程大致如下图所示。Bookie收到数据后会同时写入journal日志和memtable,memtable是一个内存buffer。memtable再次分发到entry logger以及entry index,数据在journal中append完后会立即返回写入成功。entry data和entry index的构建可以理解都是异步操作。
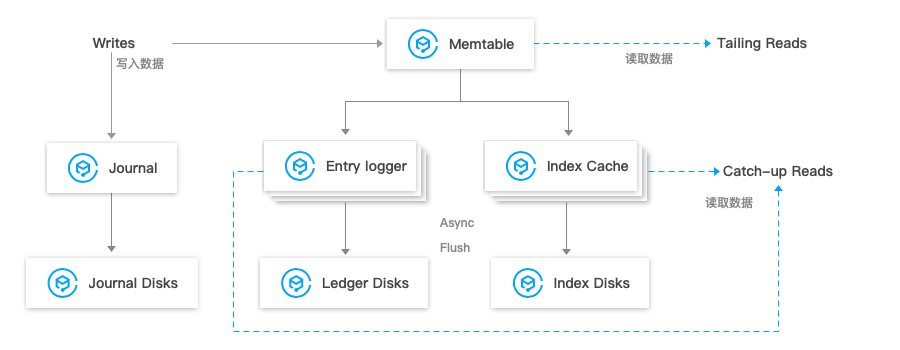
Bookie数据写入流程
client端源码分析
Pulsar中broker组件 使用low level API与Bookie进行通信。下文结合具体代码进行分析。
ClientConfiguration conf = new ClientConfiguration();
conf.setThrottleValue(bkthrottle);
conf.setMetadataServiceUri("zk://" + zkservers + "/ledgers");
BookKeeper bkc = new BookKeeper(conf);
final LedgerHandle ledger = bkc.createLedger(3, 2, 2, DigestType.CRC32, new byte[]{'a', 'b'});
final long entryId = ledger.addEntry("ABC".getBytes(UTF_8));使用low level api时,借助于LedgerHandle添加entry对象。在Pulsar中entryId为一个递增的序列,在broker中Bookie的源码调用顺序如下所示,其中LedgerHandle,OpAddEntry,LedgerHandle class对象为Bookeeper模块提供。
-
ManagedLedgerImpl#asyncAddEntry()方法(参数省略,下同)
-
ManagedLedgerImpl#internalAsyncAddEntry()方法
-
LedgerHandle#asyncAddEntry()方法
-
OpAddEntry#initiate()方法
-
LedgerHandle#doAsyncAddEntry()方法
-
BookieClient#addEntry()方法
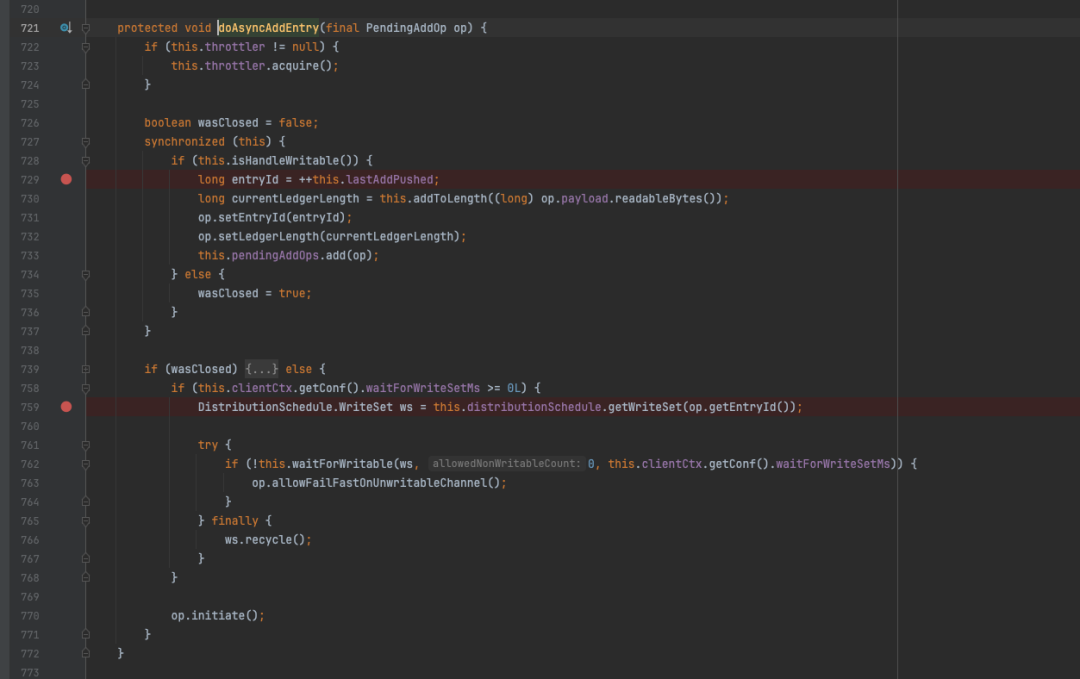
LedgerHandle#doAsyncAddEntry方法
在doAsyncAddEntry中的729行,发现entryId其实是由lastAddPushed递增得到,并且这段代码也被加上了重量级锁。PendingAddOp对象构建完成后会进入一个pendingAddOps队列,该队列与当前Ledger绑定。
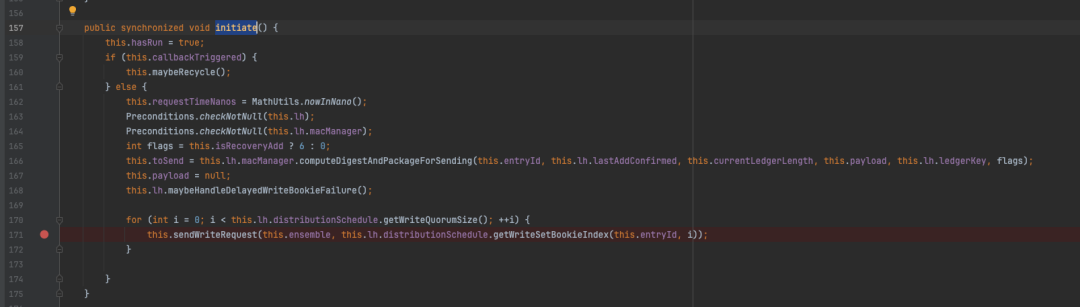
PendingAddOp#initiate方法
这里的PendingAddOp对象代表着一个写数据的请求,在initiate进一步加锁,结合写入节点的数量分别向不同的Bookie存储节点发送写请求,sendWriteRequest方法内容比较简单,直接调用addEntry方法即可。
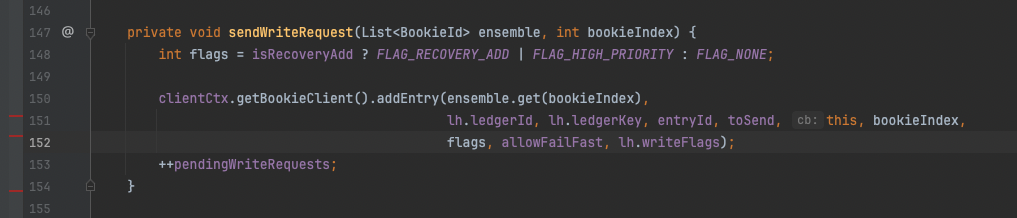
PendingAddOp#sendWriteRequest
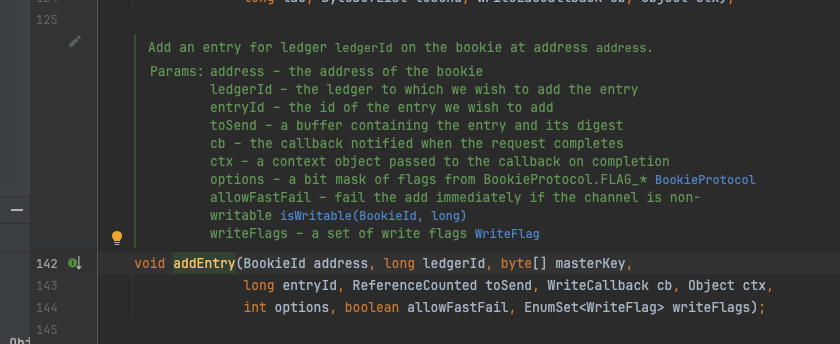
BookieClient#addEntry
addEntry方法的实现依然有很多方法包装的细节,但最终通过网络调用server端的相关接口,这里篇幅有限,不过度展开。
server端源码分析
请求路由组件:BookieRequestProcessor
直接跳转bookeeper的server端的核心处理方法上,BookieRequestHandler为server端的处理类,其继承了Netty的ChannelInboundHandlerAdapter,是最外层与netty组合工作的handler。
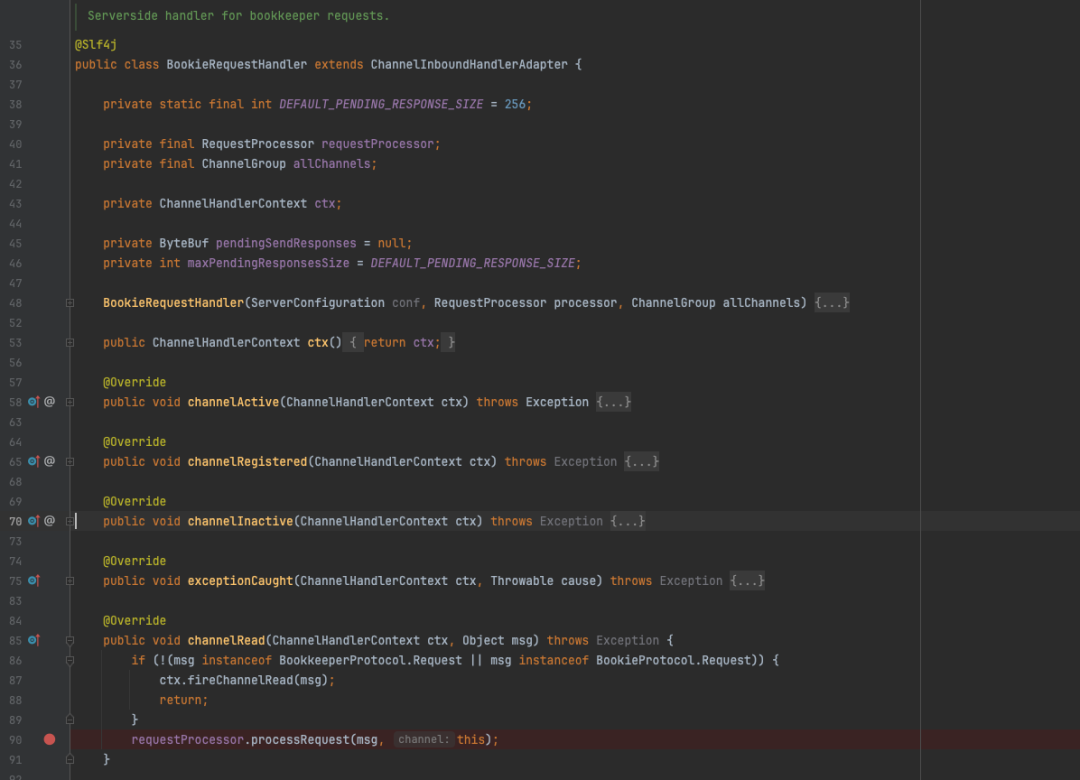
BookieRequestHandler
在channelRead方法中触发了requestProcessor的处理逻辑,这里的processor实际为BookieRequestProcessor,具体的相关代码在BookieServer类的构造函数中,BookieServer是整个bookeeper server端的启动类。
BookieRequestProcessor#processRequest方法为数据流的核心指令分发器。

BookieRequestProcessor#processRequest
这里围绕processAddRequestV3方法展开分析;Bookie中有个很有意思的设定,将请求处理线程池分为普通线程池和高优线程池;两者执行逻辑相同。在下图的452行将写操作请求放入了线程池,需要说明的是这个线程池是经过改良的,多了一个 orderingKey参数,在内部会将根据该参数进行hash运算,映射具体的线程上,其内部由多个单线程的线程池组成。这样做的好处是可以大幅度减少投递任务时的队列头部竞争,相比传统线程池有一定的性能优势。
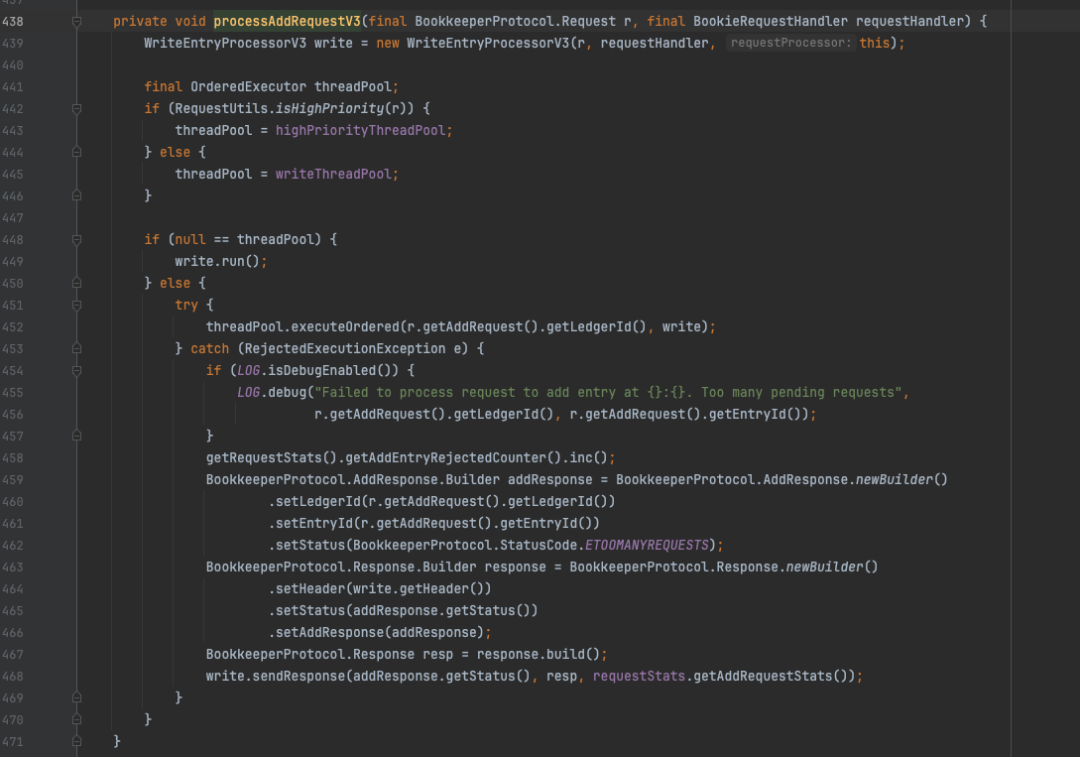
processAddRequestV3
核心线程池任务:WriteEntryProcessorV3
显然,核心的处理逻辑在write.run方法内,继续开扒。run方法中核心逻辑封装在 getAddResponse()。
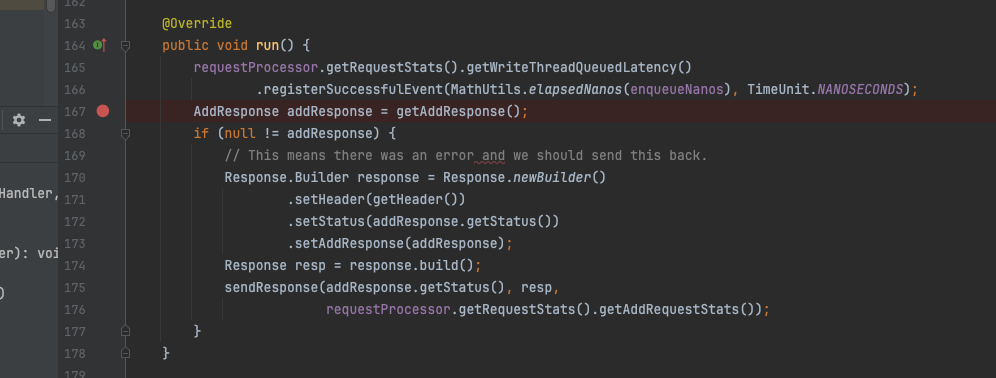
WriteEntryProcessorV3#run
getAddResponse方法内会对当前请求的标记,判断后分别调用recoveryAddEntry 和addEntry这两个方法。前者的使用场景顾名思义是在异常恢复流程中被触发,一般是节点启动,宕机后重启等过程中恢复数据。addEntry方法位于Bookie内,Bookie是个接口,只有一个实现类BookieImpl。
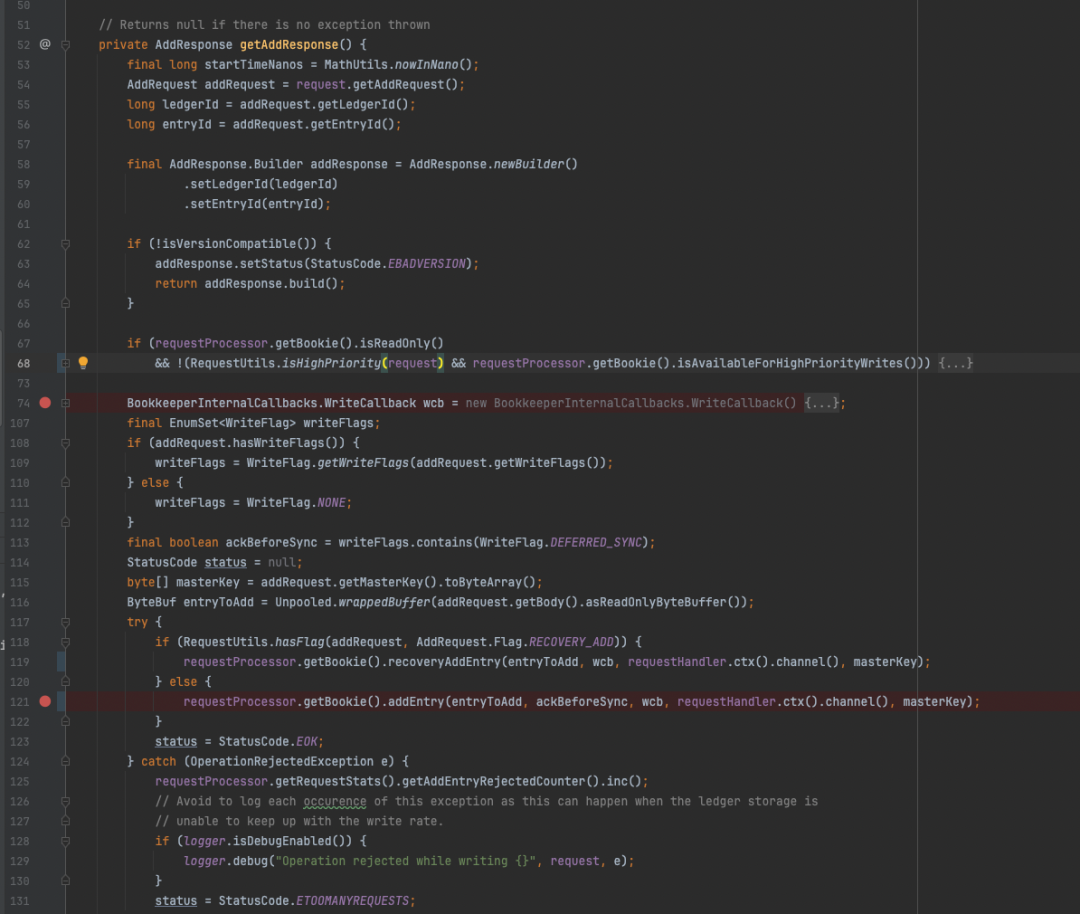
WriteEntryProcessorV3#getAddResponse
存储引擎接口抽象:Bookie
继续来看BookieImpl#addEntry方法,在1067这一行加上了synchronized锁,锁的对象为handle,具体为LedgerDescriptor类型,这表示在单个Ledger内部的数据在写入时通过加锁的方式实现串行化写入。
1073行的addEntryInternal 方法内部是核心的写入逻辑。

BookieImpl#addEntry
Ledger的管理者:LedgerDescriptor
getLedgerForEntry方法基于传入的参数LedgerId查找到对应的LedgerDescriptor,该类是一个抽象类,有两个实现类,分别是 LedgerDescriptorImpl 和 LedgerDescriptorReadOnlyImpl,顾名思义,二者分别提供读写功能。
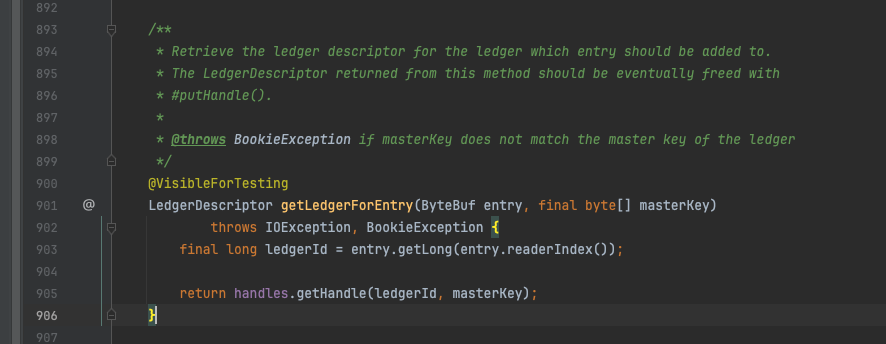
BookieImpl#getLedgerForEntry
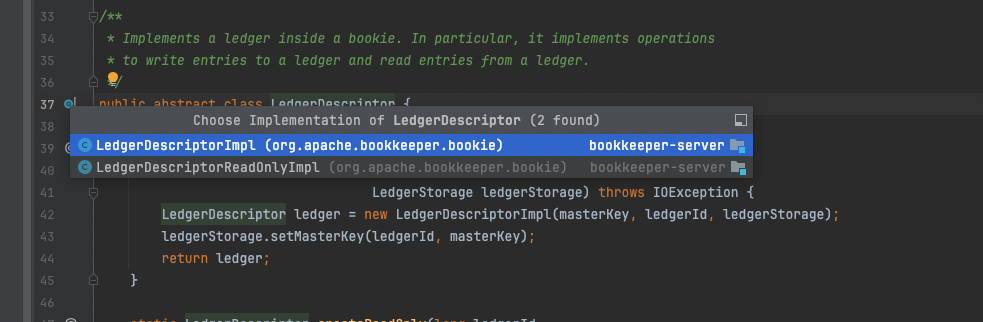
LedgerDescriptor的两个实现类
handles是HandleFactory类型接口,从其定义的接口来看主要作用就是实现LedgerDescriptor的读写分离,且只有一个实现HandleFactoryImpl,在HandleFactoryImpl 中保存了2个Map类型的MAP。分别服务于两个接口的调用,getHandle方法就是从map中获取可以写入的LedgerDescriptor。
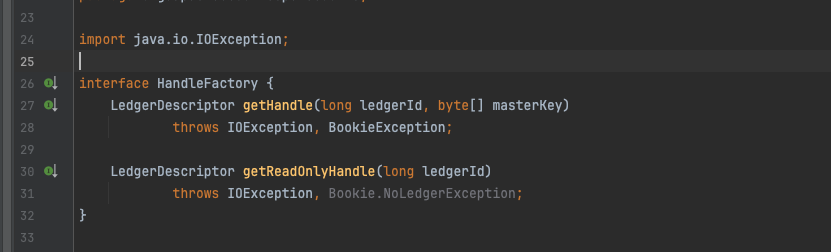
HandleFactory
事实上LedgerDescriptorReadOnlyImpl的实现很简单,继承了LedgerDescriptorImpl后将该类涉及到写入的方法全部重写为抛出异常!
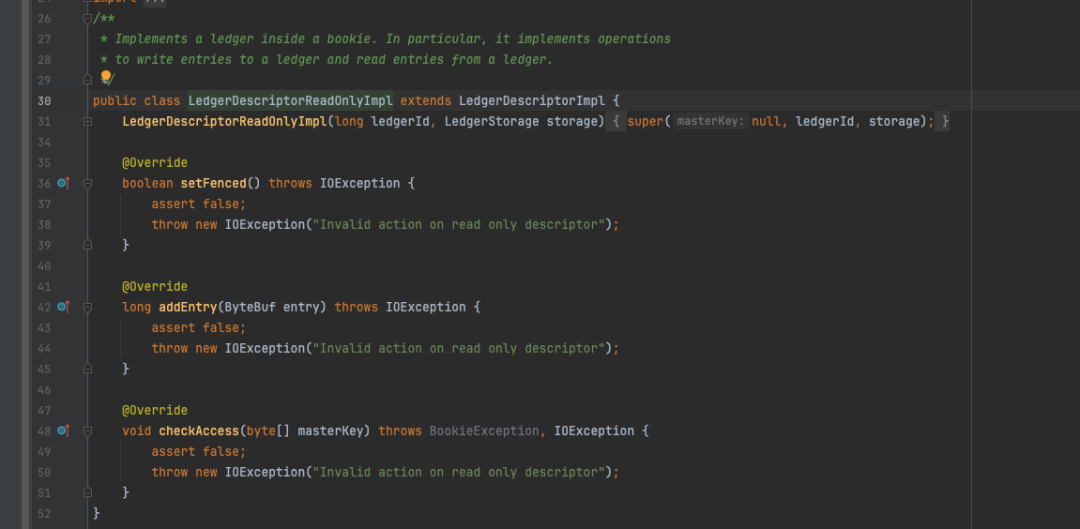
LedgerDescriptorReadOnlyImpl
获取到对应的LedgerDescriptor后,就需要进行写入操作,下面分析BookieImpl#addEntryInternal方法。
从逻辑上来讲,entry先是被写入Ledger storage(930行),其次才被写入journal 日志,同时journal日志的写入是可选的,默认情况下开启;journal 关闭后将不存在数据落盘的逻辑,这意味着将无法依靠journal日志进行数据恢复。但考虑到消息写入时一般是多份,不考虑写入的多个节点同时宕机的情况,数据某种程度上依然是可靠的。
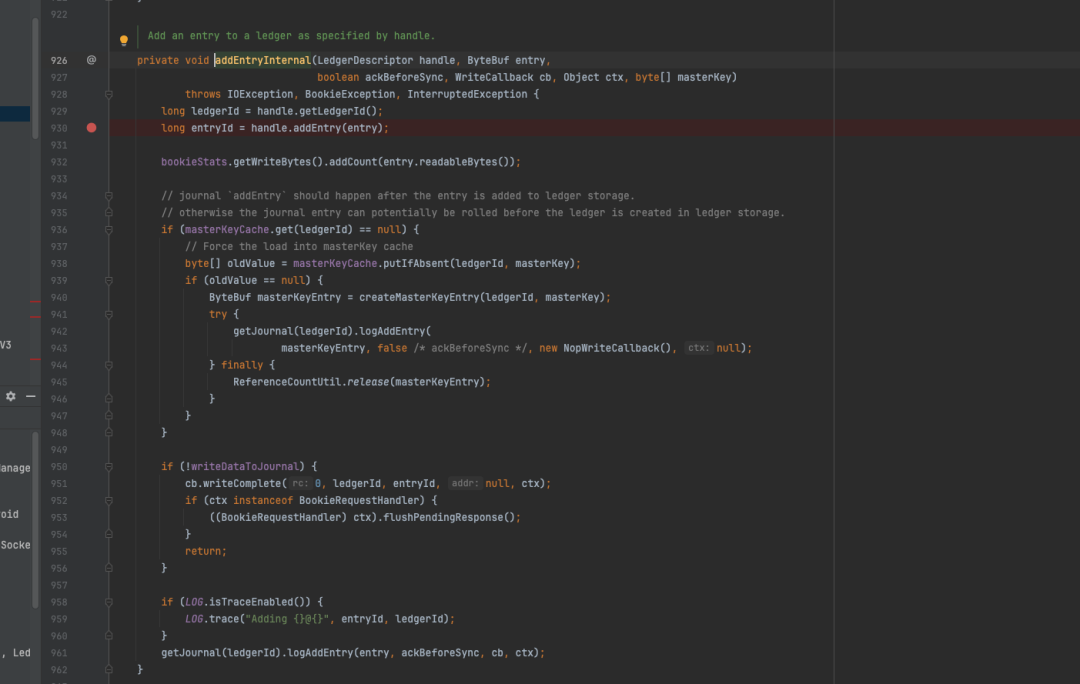
BookieImpl#addEntryInternal
Ledger级的接口抽象:LedgerStorage
LedgerDescriptorImpl中持有一个ledgerStorage类型,该组件负责最终的entry对象写入,存在多个实现类,分别是:DbLedgerStorage,SingleDirectoryDbLedgerStorage,InterleavedLedgerStorage,SortedLedgerStorage。
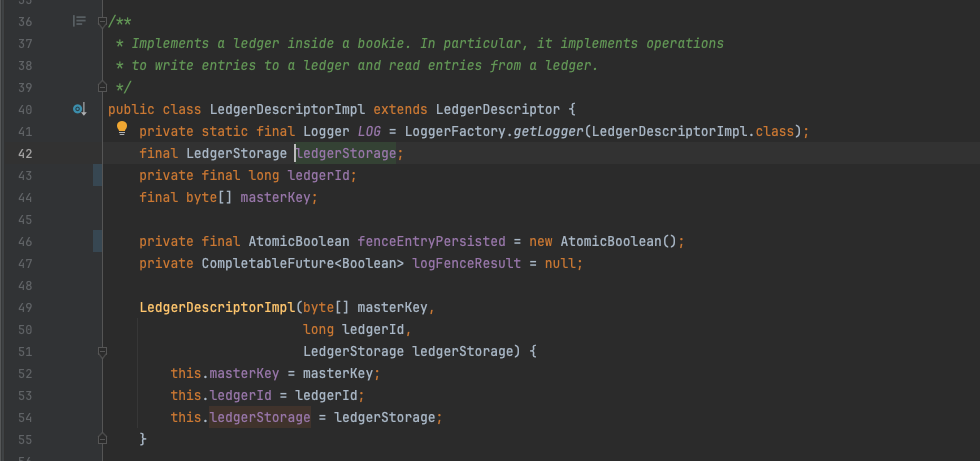
LedgerDescriptorImpl
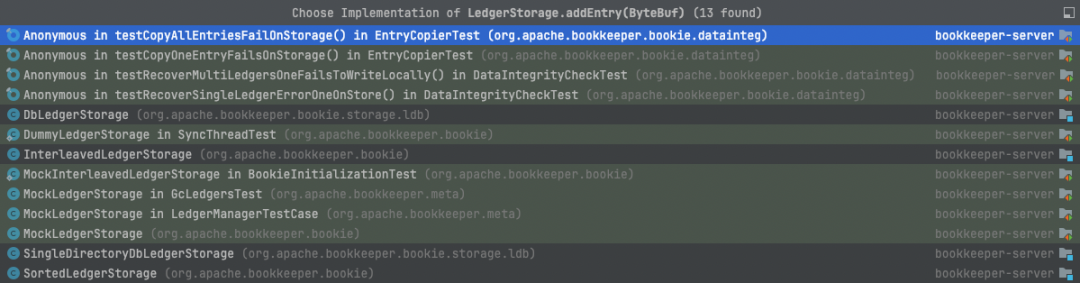
LedgerStorage实现类
Bookie默认使用SortedLedgerStorage,但Pulsar 中使用 DbLedgerStorage 进行管理。
实际可配置的实现只有三个选项,下面依次对每个实现类进行分析。
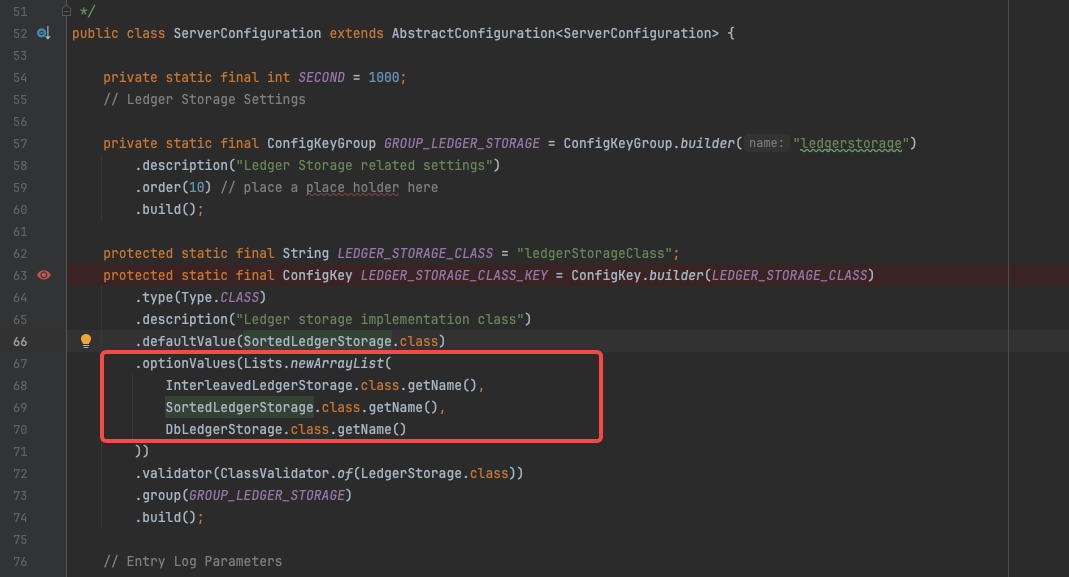
ServerConfiguration
1
DbLedgerStorage->SingleDirectoryDbLedgerStorage
writeCache写入
DbLedgerStorage主要特点是使用了rocksDB保存[ledgerId+entryId --> location]的映射关系;内部又存在了一层套娃。addEntry方法中先获取到LedgerId, 再根据LedgerId获取ledgerStorage,也就是说LedgerId和实际的LedgerStorage 存在映射关系;DbLedgerStorage内部又继续封装了SingleDirectoryDbLedgerStorage 类来支撑数据写入,具体是一个ListledgerStrageList;字段。经过hash后获得真实的SingleDirectoryDbLedgerStorage对象进行实际的addEntry操作;下文首先对该实现进行分析。

DbLedgerStorage#addEntry

DbLedgerStorage#getLedgerStorage
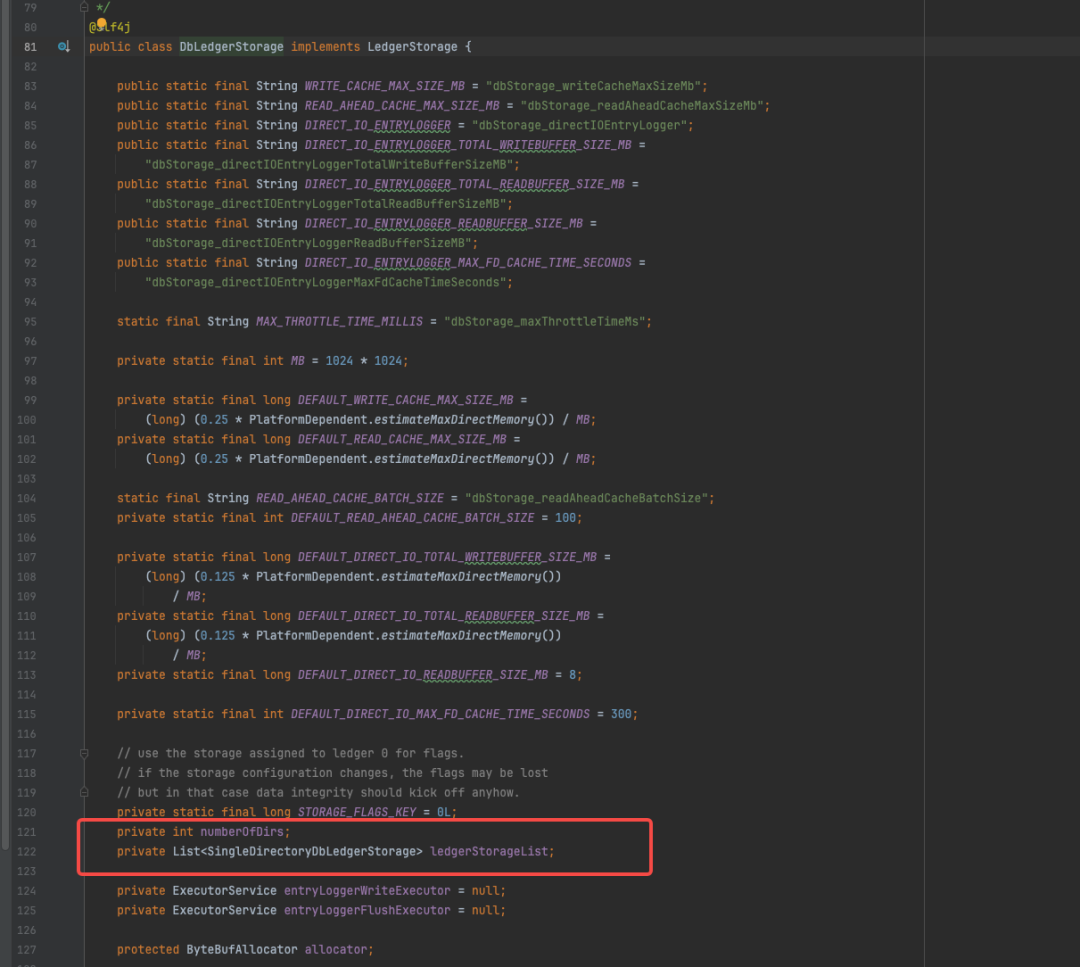
DbLedgerStorage的成员变量
在SingleDirectoryDbLedgerStorage的源码中,待写入的entry仅仅是被放入writeCache 中,put成功后更新LAC并通知相关监听者,同时触发写入成功事件,貌似没有任何写盘的操作出现!!!进一步分析497行,如果put失败会触发flush操作并尝试再次addEntry,这里的flush有点眼熟,有必要展开分析一波。
不难发现这里的写入操作和刷盘操作其实是线程隔离的,默认情况下,类比于RMQ,大部分存储组件的刷盘操作和实际写入动作切分为两个线程在执行,刷盘线程会不断地巡检是否需要刷盘,主要基于当前未刷盘的数据量以及距离上次刷盘的时间间隔,如果开启同步刷盘,一般写入线程会被挂起在req请求上,当刷盘进度已经cover写入请求的offset时,被挂起的请求上的线程会被唤醒继续执行,这是一种非常典型的存储引擎设计模式。这里writeCache就是个buffer,既可以充当写入缓冲也可以充当读取缓冲,在tail read场景下会有非常好的性能收益。

SingleDirectoryDbLedgerStorage#addEntry
writeCache背后的flush
triggerFlushAndAddEntry的逻辑并不复杂,在超时时间到来之前会不断的检查当前的刷盘标记位,如果没有正在刷盘以及刷盘逻辑没有被触发,会尝试刷盘,同时尝试继续向writeCache中put数据,因为刷盘成功后会在cache中清理出一部分空间,用于put新的的数据,一旦put成功立即返回,跟外层的addEntry方法类似,只是多了个刷盘逻辑的处理。

SingleDirectoryDbLedgerStorage#triggerFlushAndAddEntry方法
flush方法其实是个空壳,核心逻辑在checkpoint()方法内,该方法的主要逻辑为:
-
交换writeCache,避免刷盘过程中数据无法写入,导致写入抖动;
-
对writeCache内的数据进行排序,实现局部有序;
-
分别调用entryLog的add方法和entryIndex的add方法;
-
调用entrylog的flush和entryIndex的flush进行刷盘。
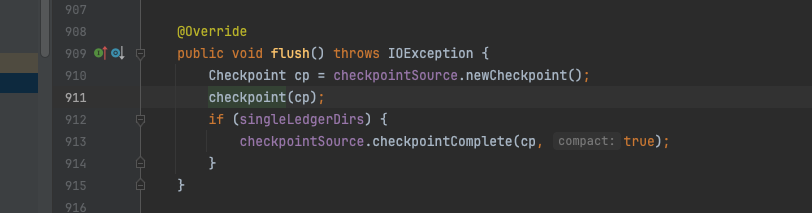
SingleDirectoryDbLedgerStorage#flush
SingleDirectoryDbLedgerStorage#checkpoint
源码中的writeCacheBeingFlushed实际上和writeCache一体两面,上一次刷盘结束后writeCacheBeingFlushed会被clear,再次刷盘时会交换两者;保证写入的稳定性;如果实际查询数据时要利用这部分cache,需要查询两次,先查writeCache如果不存在 ,再查writeCacheBeingFlushed。
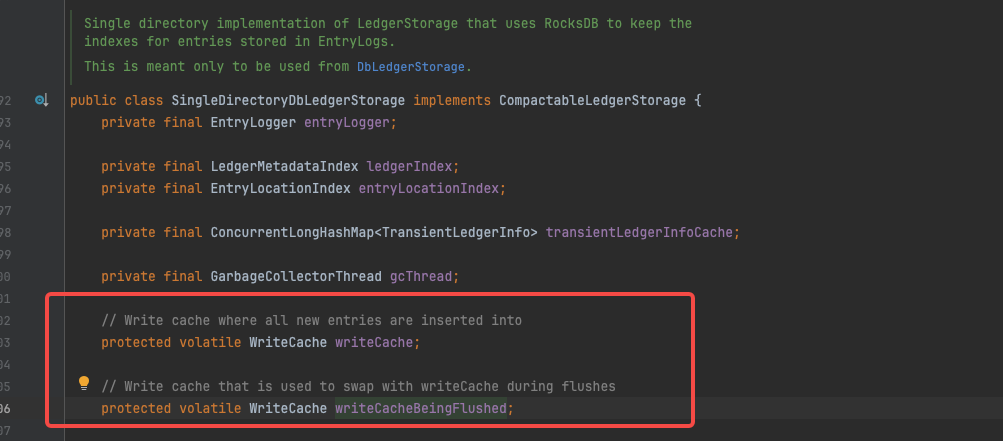
writeCacheBeingFlushed的注释

entryLocationIndex.addLocation(batch, ledgerId, entryId, location);方法底层依赖rocksDB 建立了[ledgerId, entryId]-->location的映射关系,Batch在这里代表着 一个 RocksDBBatch,location可以理解为实际磁盘文件上的offset。rocksDB引擎超出本文范畴,这里不做分析。
EntryLogger
entryLogger代表着存储实际数据的组件抽象,调用addEntry(ledgerId, entry)方法完成数据写入。进一步对addEntry方法展开分析,发现EntryLogger是一个接口,有2个直接实现类,分别是DefaultEntryLogger和DirectEntryLogger,默认使用DefaultEntryLogger参见源码:
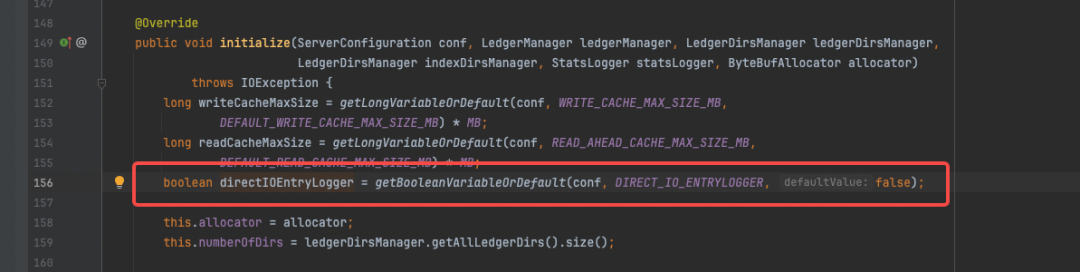
DbLedgerStorage#initialize -part1

DbLedgerStorage#initialize -part2
最终的调用来到了EntryLogManagerBase#addEntry方法,首先获取到待写入的数据,然后调用BufferedLogChannel#write将其写入,可以看到实际的数据长度为:entry.readableBytes() + 4,4个字节用于记录长度,先写入长度值,再写入entry的二进制数据;addEntry方法返回值为location,方法的最后一行表明location由2部分组成,分别是logId和pos,各暂用高位和低位的4个字节。很容易想到随着时间的推移EntryLogger中的文件不止一个,因此需要一个logId来标识不同文件,具体到文件上又需要一个偏移量来定位具体的一条数据,4个字节的pos也表明了单个entryLog文件理论大小值不能超过4个G,实际默认值为1G。
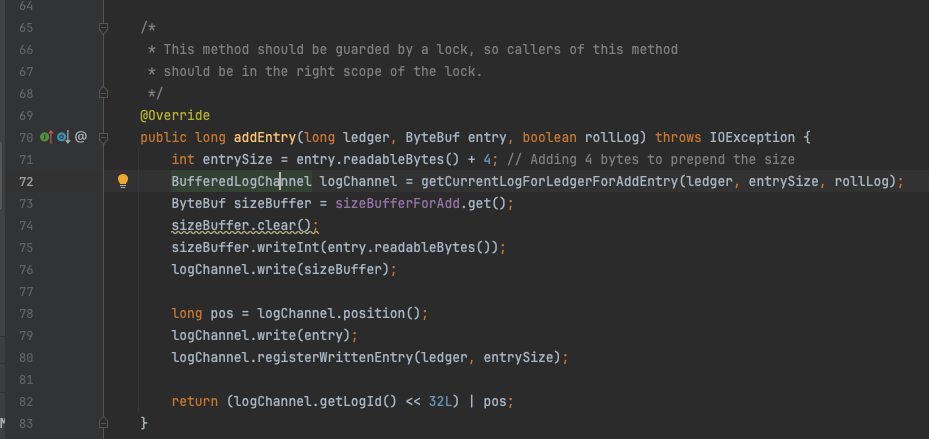
EntryLogManagerBase#addEntry
进一步分析BufferedLogChannel#write方法,发现BufferedLogChannel 继承置之BufferedChannel ,在BufferedChannel中有一个writeBuffer ,write方法只是将数据写入到这个writeBuffer 中,至于是否刷盘则不一定。
只在满足下列两种情况时数据才会刷盘:
-
当前writeBuffer 已经写满,writeBuffer默认值64KB;
-
ServerConfiguration中配置了FLUSH_ENTRYLOG_INTERVAL_BYTES参数,且值大于0,默认值为0。
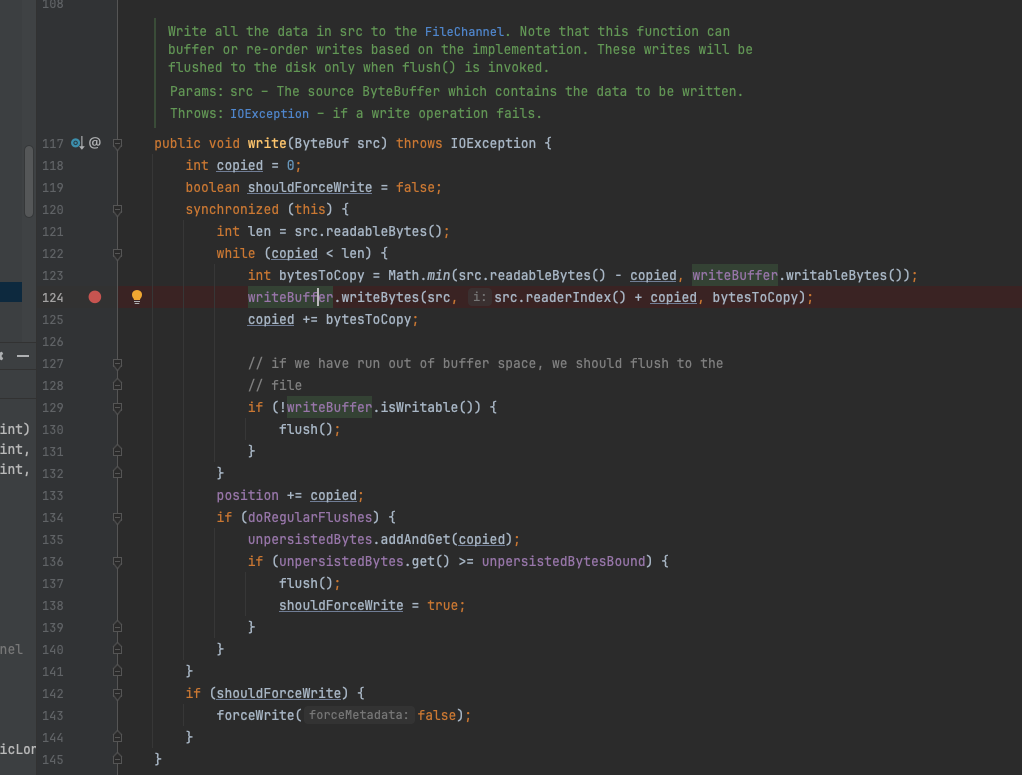
BufferedLogChannel#write
flush方法内容很简单,调用底层的fileChannel将writeBuffer中的数据写入底层的文件系统,但是flush并不保证一定落盘,而是最后一行代码forceWrite方法保证。forceWrite 会调用fileChannel.force(forceMetadata)将数据同步到磁盘上。
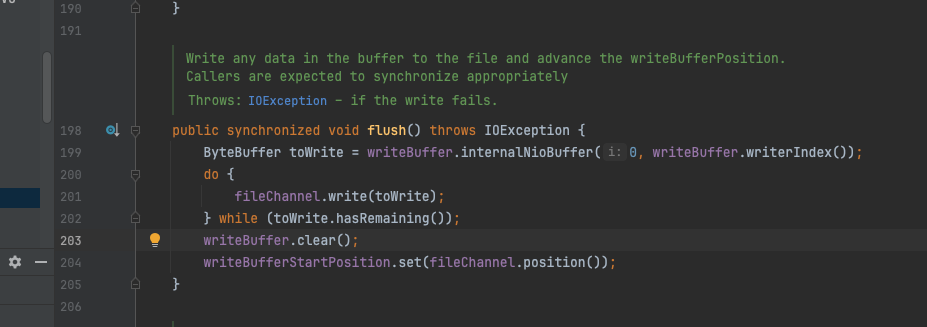
BufferedChannel#flush
为了保证数据的务必落盘,在SingleDirectoryDbLedgerStorage#checkpoint方法中,addEntry方法之后,又单独调用了entryLogger.flush();和ledgerIndex.flush();对entryLogger.flush()进一步拆分,发现底层调用了EntryLogManagerBase#flush方法,二者两个方法在base类中是abstract类型,具体实现又落到了 EntryLogManagerForSingleEntryLog中,最终任务还是落在了 BufferedChannel#flushAndForceWrite 上。
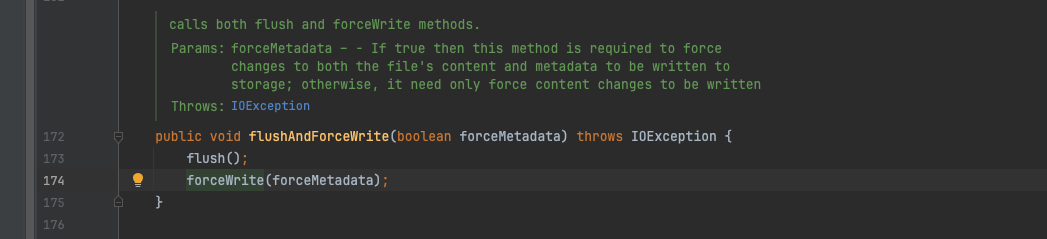
BufferedChannel#flushAndForceWrite
2
SortedLedgerStorage->InterleavedLedgerStorage
在SortedLedgerStorage类中,持有了InterleavedLedgerStorage类型,大部分的接口实现都委托给了InterleavedLedgerStorage的相关方法调用,SortedLedgerStorage的最大特点是,每次数据写入时都会进行排序,其内部使用了跳表。
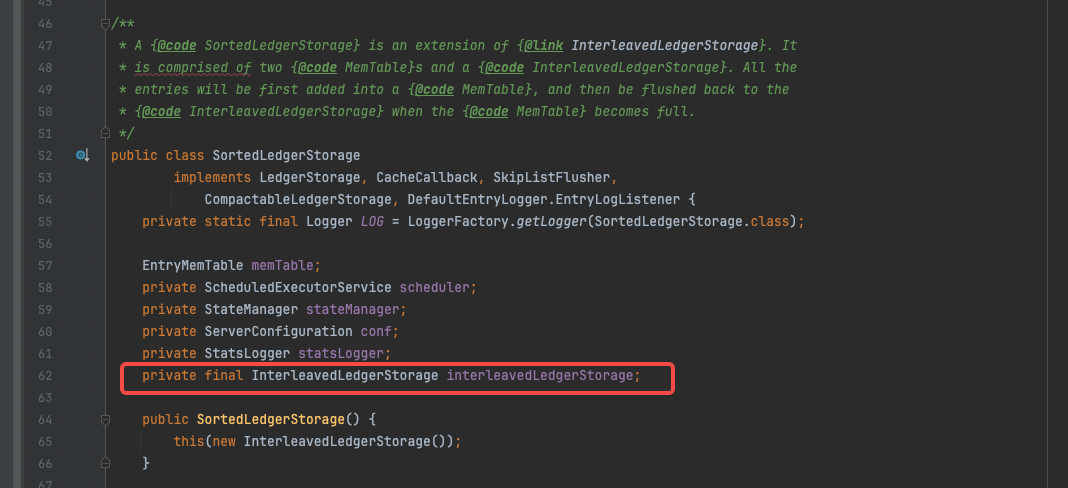
EntryMemTable写入
addEntry方法的逻辑非常简单,将数据add到memtTable后,更新下LAC即结束;
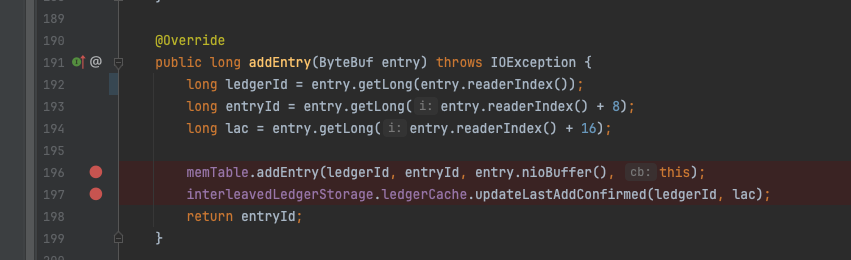
SortedLedgerStorage#addEntry
继续研究EntryMemTable的addEntry方法之前先了解下EntryMemTable的结构,这个组件是一个纯内存的数据保存结构,kvmap和snapshot 负责实际数据保存,二者类型皆是 EntrySkipList ,这个类简单封装了ConcurrentSkipListMap,实际使用时KV值相同,因为需要保证有序,所以重写了排序规则,主要比较LedgerId和entryId。
kvmap和snapshot工作机制是,当写满kvmap时,会将数据交换给snapshot,kvmap重新构建一个新的指定大小的结构,后台线程负责将snpshot中的数据刷盘保存,因此只要后台刷盘的速度不是特别垮,可以提供持续不间断的写入。单个kvmap有大小限制,默认64M大小,结合前面的swap机制,最多可以兜住128M的写入缓存。
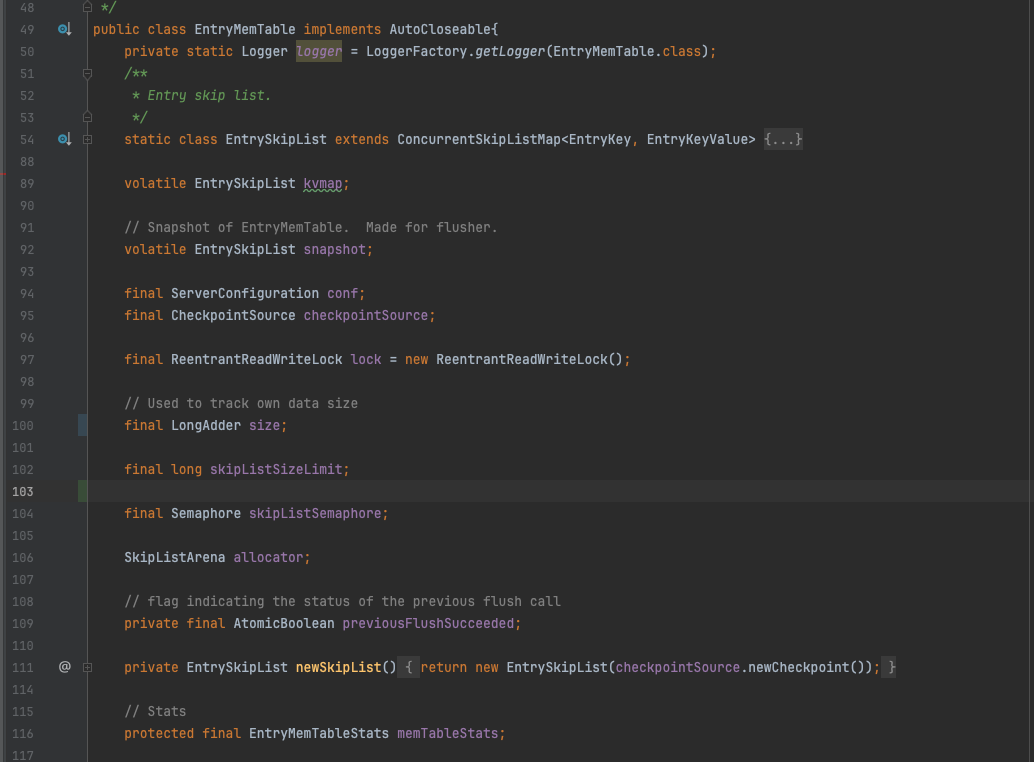
EntryMemTable
addEntry 写入之前先获取读锁,(没错,写入用的是读锁!!!)然后将数据put进入kvmap结构中,internalAdd方法内容很简单,就是一个对kvmap的putIfAbsent 调用,看到这里可以理解为什么用的是读锁了。因为这里kvmap的并发安全控制根本不依赖这个读写锁。
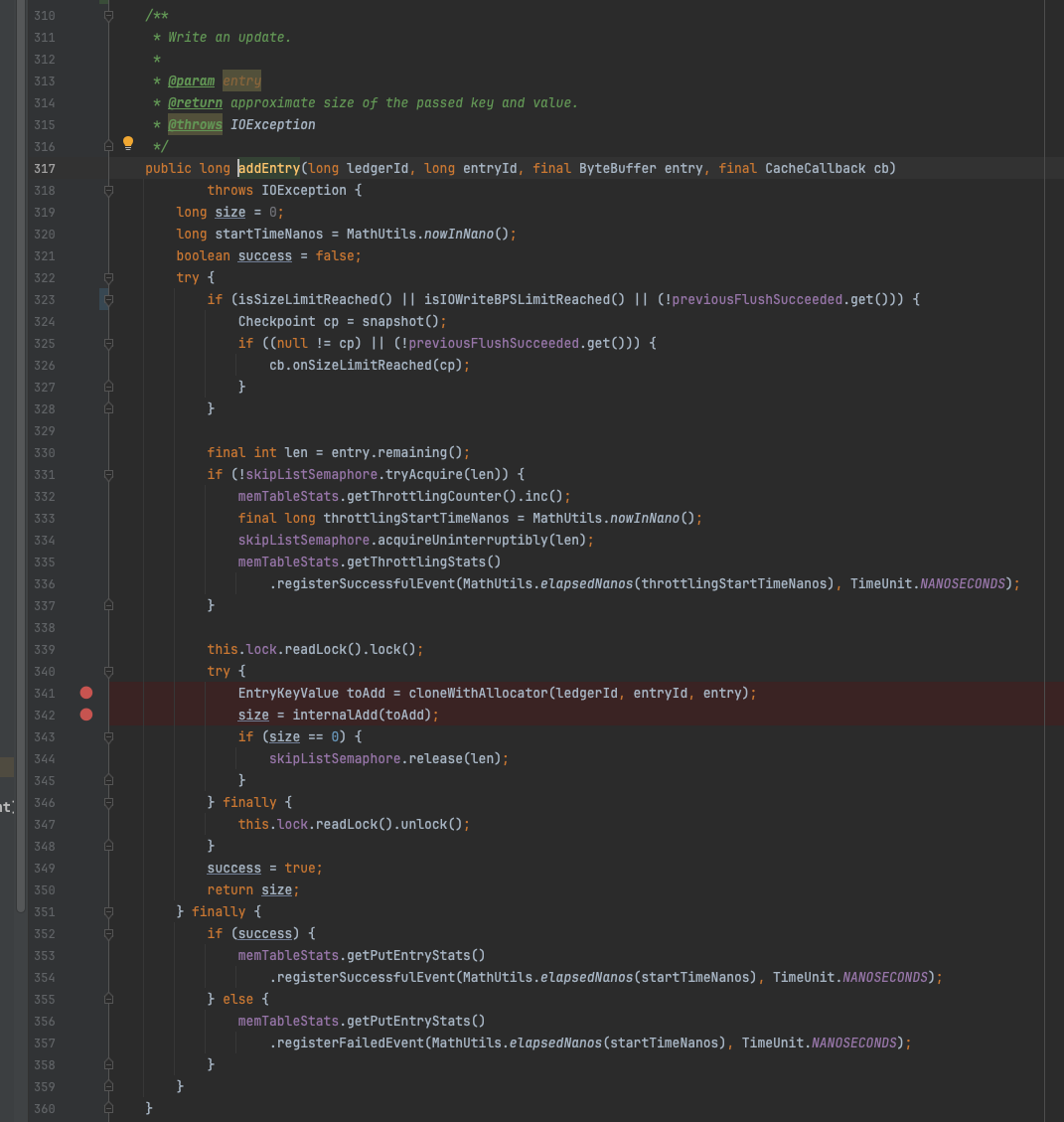
EntryMemTable#addEntry
EntryMemTable刷盘
读写锁的主要作用是,在swap kvmap和snapshot瞬间加上写锁控制以及读取数据时加上读锁控制。

ReentrantReadWriteLock使用场景
每次刷盘之前会先创建个一个snapshot快照,用以保证此快照之前的数据在此次的刷盘范围内;创建snapshot时,会交换kvmap与snapshot两个字段,因为快照的创建是刷盘行为触发的,而刷盘动作一般都是有个单独的线程在执行,所以这里需要控制并发逻辑,保证在swap的瞬间,不能有addEntry操作,同样的在刷盘结束后需要清理snapshot的数据,也加上了写锁来控制。
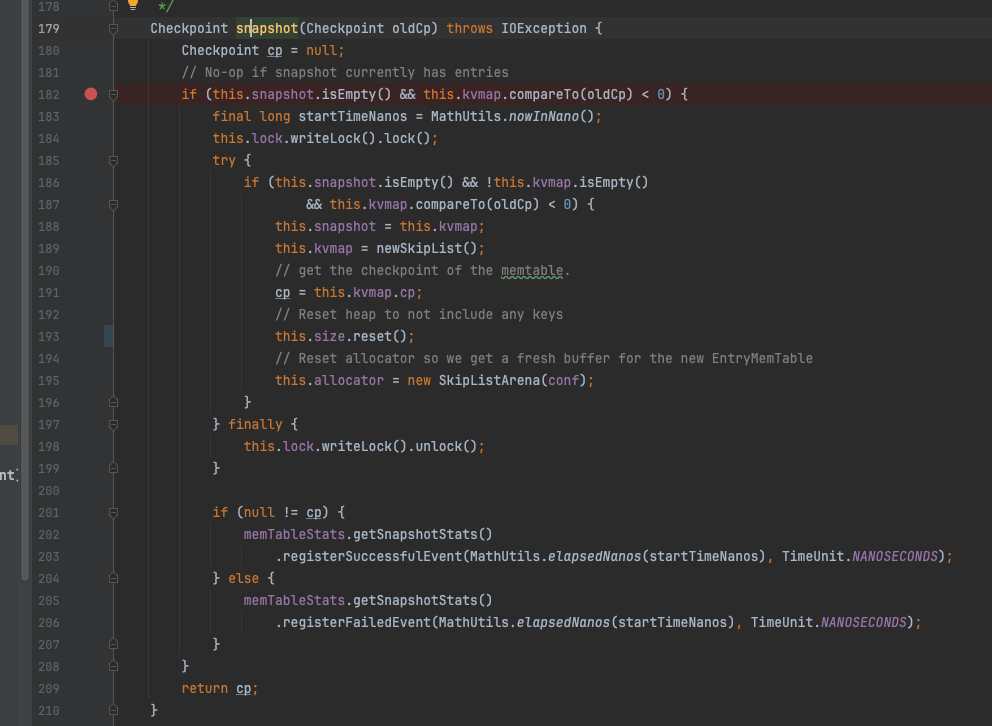
EntryMemTable#snapshot
会有一个后台的刷盘线程执行flush操作,首先会先将snapshot数据flush,然后尝试创建新的snapshot,如果创建成功说明,仍然有可刷数据,再次执行flushSnapshot的动作。
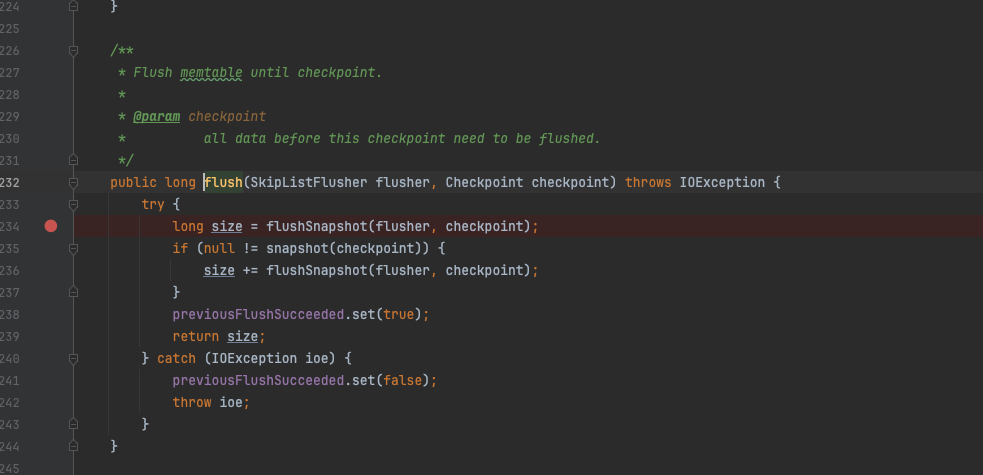
EntryMemTable#flush
在flushSnapshot 方法中,会调用flusher的process 方法,这里的flusher 其实就是 SortedLedgerStorage,在process方法内的实际调用了InterleavedLedgerStorage 的processEntry方法,这个方法并不能保证数据一定会落到磁盘文件上,因此EntryMemTable所谓的flush操作只是将其内存数据刷新到InterleavedLedgerStorage组件中。
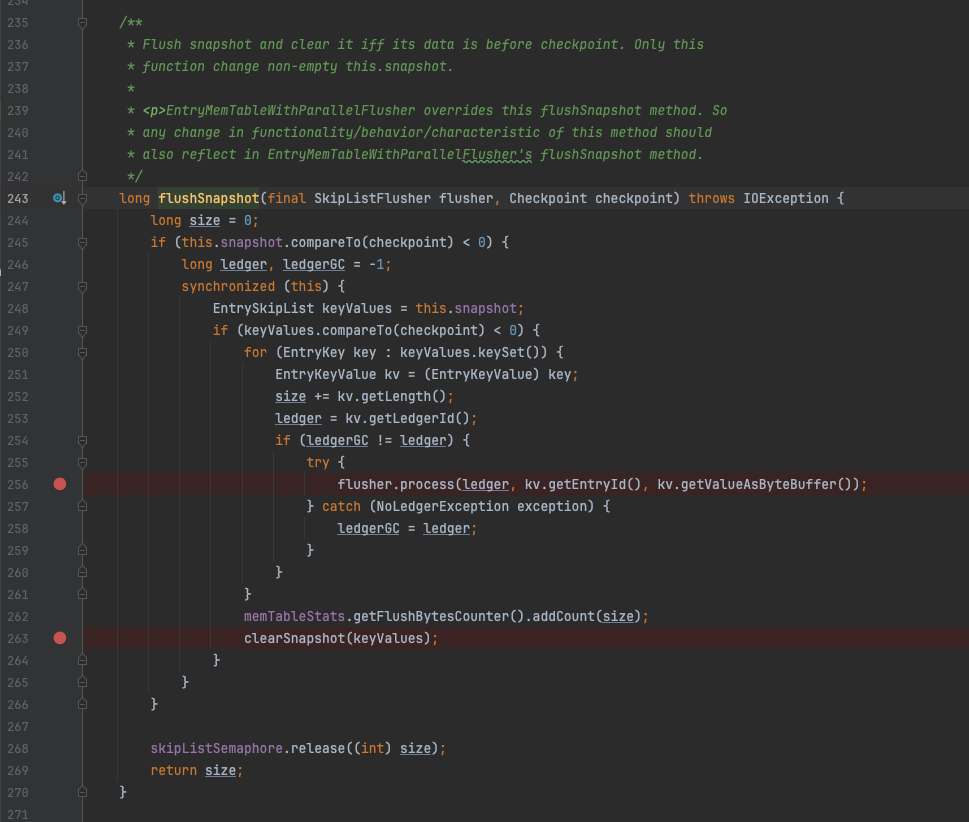
EntryMemTable#flushSnapshot

SortedLedgerStorage#process
EntryLogger
继续来看InterleavedLedgerStorage的处理逻辑,添加Entry后将对应的KV索引写入 LedgerCache 缓存后返回。查看InterleavedLedgerStorage的entryLogger字段发现,与上文的SingleDirectoryDbLedgerStorage相同,写入entry依然用的是 DefaultEntryLogger。

InterleavedLedgerStorage#processEntry

InterleavedLedgerStorage#entryLogger
EntryIndex
上文提到默认情况下Pulsar使用DbLedgerStorage来存储数据和索引信息,而索引信息默认情况下使用rocksDB来存储,rocksDB作为顶级KV引擎其性能和稳定性毋庸置疑。但是在实际的使用过程中,某些时候会选择LedgerStorage的另一个实现类:SortedLedgerStorage。SortedLedgerStorage的主要特点是是在每次写入数据的时候都会进行内部排序,内部维护一个跳表,同时其存储leggerId+entryId到location的映射关系是使用Java的引擎实现。下面对这个Java实现的KV引擎做详细分析。

ServerConfiguration关于ledgerStorageClass 的配置
仍然是先从entryLog的写入作为突破口,SortedLedgerStorage内部套了一个InterleavedLedgerStorage对象,前者复用了后者的addEntry方法,核心方法在InterleavedLedgerStorage#processEntry中。
long pos = entryLogger.addEntry(ledgerId, entry, rollLog);方法添加完entry对象后返回对象在文件的offset,内部的add逻辑与上文分析的SingleDirectoryDbLedgerStorage 一致。
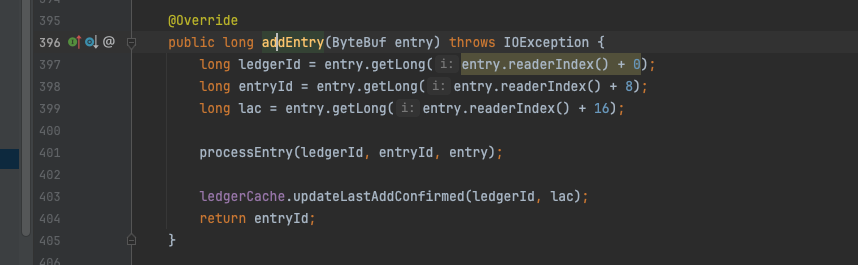
InterleavedLedgerStorage#addEntry
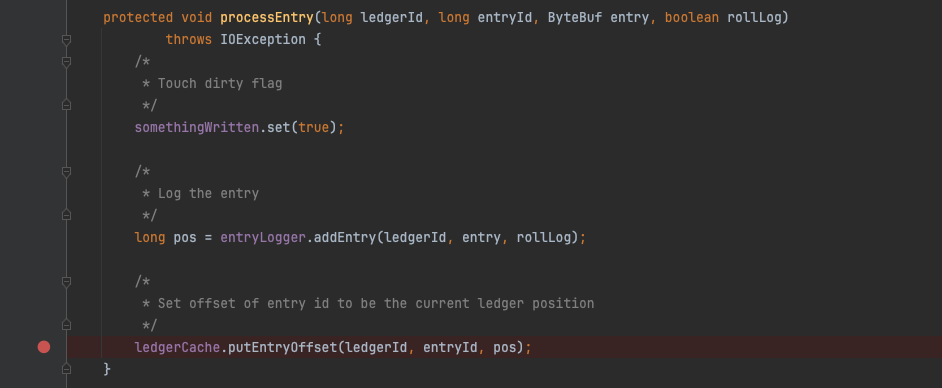
InterleavedLedgerStorage#processEntry
LedgerCache是一个接口,具体的实现只有一个LedgerCacheImpl类,后者内部有两个支撑组件,IndexInMemPageMgr和IndexPersistenceMgr,从名称可以看出前者负责数据在内存中的保持,后者负责实际的存储。按照之前的分析的源码,很容易联想到数据大概率先落入memoryPage再落盘,pageSize默认8K,entriesPerPage默认为pageSize/8= 1K。
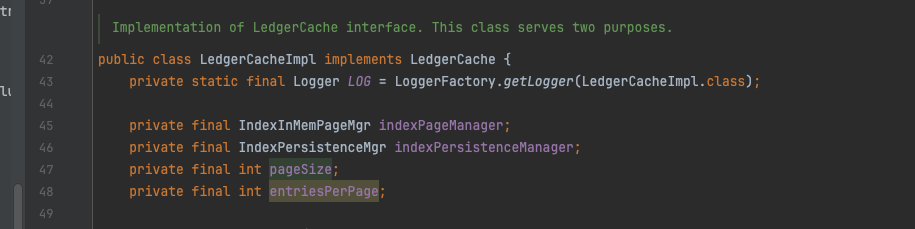
LedgerCacheImpl
putEntryOffset方法首先通过entryId模以单个page页的entry数量得到当前entryId在具体的page页中的偏移量,这里的page不是OS中的page页,是Bookeeper单独抽象出来的page概念,需要区分开。在getLedgerEntryPage方法中,首先会尝试从内存中获取LedgerEntryPage对象,如果没有则调用grabLedgerEntryPage方法从磁盘上加载,内存中缓存的对象结构为InMemPageCollection,内部是一个LRU缓存。
写入算法分析:
-
LedgerEntryPage是对单个页的抽象;
-
int offsetInPage = entry % entriesPerPage;计算出当前的entryId在单个LedgerEntryPage的逻辑偏移量;
-
long pageEntry = entry - offsetInPage; 计算出当前LedgerEntryPage中初始entryId;
-
基于 LedgerId和初始entryId查找定位到LedgerEntryPage,如果缓存中不存在,则从文件中加载;
-
按照offsetInPage计算当前的offset需要写入的真实位置,这里的offset即是 entryLogger中entry location值;
-
由于写入的数据为offset是个long类型,需要8个二进制为,实际的写入的位点为逻辑上的offsetInPage*8。

IndexInMemPageMgr#putEntryOffset
上述的算法自然也是可逆的,读取的时候同样基于LedgerId和entryId定位到具体的LedgerEntryPage。然后在计算出实际的物理偏移量,在特定位置读取到location 参数。
顺序写入的WAL日志:Journal
分析完writeCache的写入及其背后的逻辑,我们继续分析journal日志的写入流程;上文提到journal为混合写入模式,可能存在多个LedgerId的数据混编。在addEntryInternal方法的最后一行中通过LedgerId获取到真实的journal,获取的逻辑依然是个hash算法,用来保证相同LedgerId始终落到一个journal上进行处理。
logAddEntry干了三件事:
-
entry.retain()调整entry的引用计数值;
-
journalStats给内部的queueSize +1;
-
memoryLimitController内存使用限速器,如果超限时,当前线程会被置为等待状态;
-
queue.put(.......), 将待写入的数据放进队列。
结合logAddEntry源码发现又是熟悉的味道,写入方法只是将请求放入队列,那么必然存在从队列获取数据并进行刷盘的逻辑。既然有put操作,必然有take操作,我们发现takeAll和pollAll方法 ,都位于journal#run方法中,run方法这个名字如此敏感,以至于不跟Thread扯上点关系都说不过去。
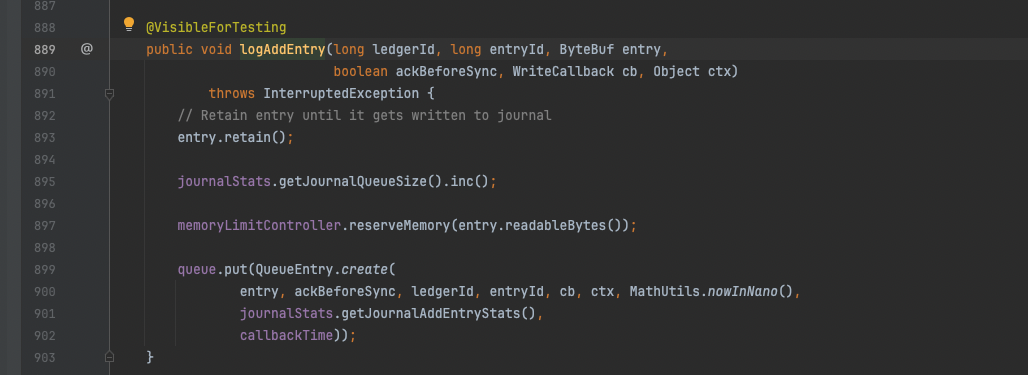
Journal#logAddEntry

queue的调用点
public class Journal extends BookieCriticalThread implements CheckpointSource 查看 journal的class签名 发现其不出所料的实现了Thread的run方法,journal既是顺序写入日志逻辑的抽象也是后台的刷盘线程的抽象;run方法的实现较为复杂,其注释表明这是一个专门负责持久化的线程方法,同时负责journal文件的滚动,当journal文件被写满时,会使用当前时间戳创建一个新的journal文件,老的文件会被定期回收。
在queue字段旁边有一个forceWriteRequests字段,这个字段在实际的刷盘逻辑中起到了重要作用。
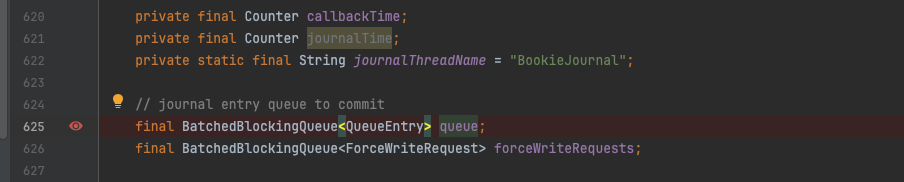
Journal部分成员变量释义:
-
maxGroupWaitInNanos组提交间隔,一般超过这个时间需要刷盘;
-
flushWhenQueueEmpty开关表示当queue为空时是否刷盘;
-
bufferedEntriesThreshold表示暂存在toFlush中的对象数量的阈值;
-
bufferedWritesThreshold表示待刷盘的字节数阈值;
-
journalPageCacheFlushIntervalMSec真实刷盘的时间间隔。
Journal#run方法成员变量释义:
-
localQueueEntries是一个复用的定长数组;
-
localQueueEntriesIdx是这个定长数组中当前处理的元素索引编号,从0开始;
-
localQueueEntriesLen代表每次从queue队列中获取的对象数量;
-
toFlush队列是个可复用的ArrayList,可以认为是个对象池;
-
numEntriesToFlush是个待刷盘对象数量的计数器,与toFlush配合使用;
-
lastFlushPosition为上次刷盘位点记录值;
-
lastFlushTimeMs为上次刷盘时间点(毫秒单位);
-
JournalChannel是单个journal文件的抽象,journal代表单个目录下的多文件抽象;
-
BufferedChannel代表一个写入缓冲区,来自于JournalChannel;
-
qe为QueueEntry类型的临时变量。
Journal#run的主要逻辑如下:
-
启动forceWriteThread线程,这是一个真正意义上的刷盘线程;
-
journal线程只是将queue中的QueueEntry对象写入相关的FileChannel 的buffer中,并不保证一定落盘;
-
实际的刷盘行为由forceWriteThread负责。
-
-
不断的从queue中获取一组QueueEntry对象,并逐一将其写入BufferedChannel缓冲区;
-
从queue中获取的QE对象放入localQueueEntries数组中;
-
entry需要符合一定的条件才会被写入二进制数据流(主要entryId和版本的识别);
-
写入调用的是BufferedChannel#write方法,只是将数据写入内部的writeBuffer中;
-
-
写入缓冲区后,将QE对象添加进入toFlush队列,同时调整numEntriesToFlush(+1);
-
继续处理localQueueEntries中的下一个元素。当localQueueEntriesIdx == localQueueEntriesLen时,表示localQueueEntries元素全部处理完成,此时临时变量qe(QueueEntry) 置为null。
-
-
在处理qe对象的过程中,会综合多方面条件判断是否需要刷盘,使用临时变量 shouldFlush 表示;
-
当numEntriesToFlush>0且符合以下条件时会触发“刷盘”逻辑;
-
当临时变量qe为空 或者当前的qe 处理的时间超过 maxGroupWaitInNanos;
-
当临时变量qe为空并且开启flushWhenQueueEmpty配置时刷盘;
-
当临时变量qe不为空,符合下面两个条件时刷盘;
-
且toFlush 中暂存的对象数量超过bufferedEntriesThreshold;
-
或距离上次刷盘的位点间隔超过bufferedWritesThreshold。
-
-
-
-
如果满足刷盘条件,调用 BufferedChannel#flush操作;
-
flush操作会将之前攒批的writeBuffer中的数据写入OS的文件系统;
-
底层作为FileChannel#write方法的入参;
-
-
将toFlush相关索引为置空,同时调整numEntriesToFlush;
-
触发entry写入的相关回调逻辑执行;
-
更新lastFlushPosition。
-
-
flush操作完成后将进一步判断是否需要向forceWriteThread提交真实的刷盘请求;
-
提交时会将toFlush列表中全部对象连同其他参数封装成一个请求对象;
-
一旦提交后将更新lastFlushTimeMs;
-
符合提交条件的情况有:
-
开启syncData ,journal级别的开启同步刷盘的开关;
-
当前需要滚动创建新的journal文件;
-
距离上次真实刷盘时间超过阈值 journalPageCacheFlushIntervalMSec。
-
-
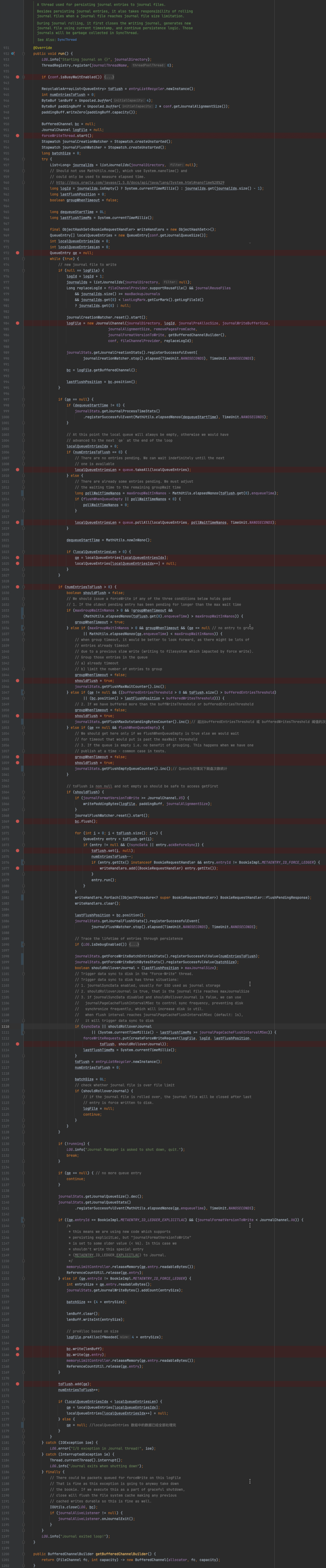
Journal#run方法
当真实刷盘请求被提交到forceWriteThread线程后,有必要进一步分析该线程的执行逻辑,相比之下ForceWriteThread#run方法的逻辑简单很多,解包收到的请求,然后调用syncJournal进行强制刷盘,同时做一些清理回收的动作,以及最后的一些回调方法的触发和统计操作。这里的localRequests 也是一个可复用的临时数组。
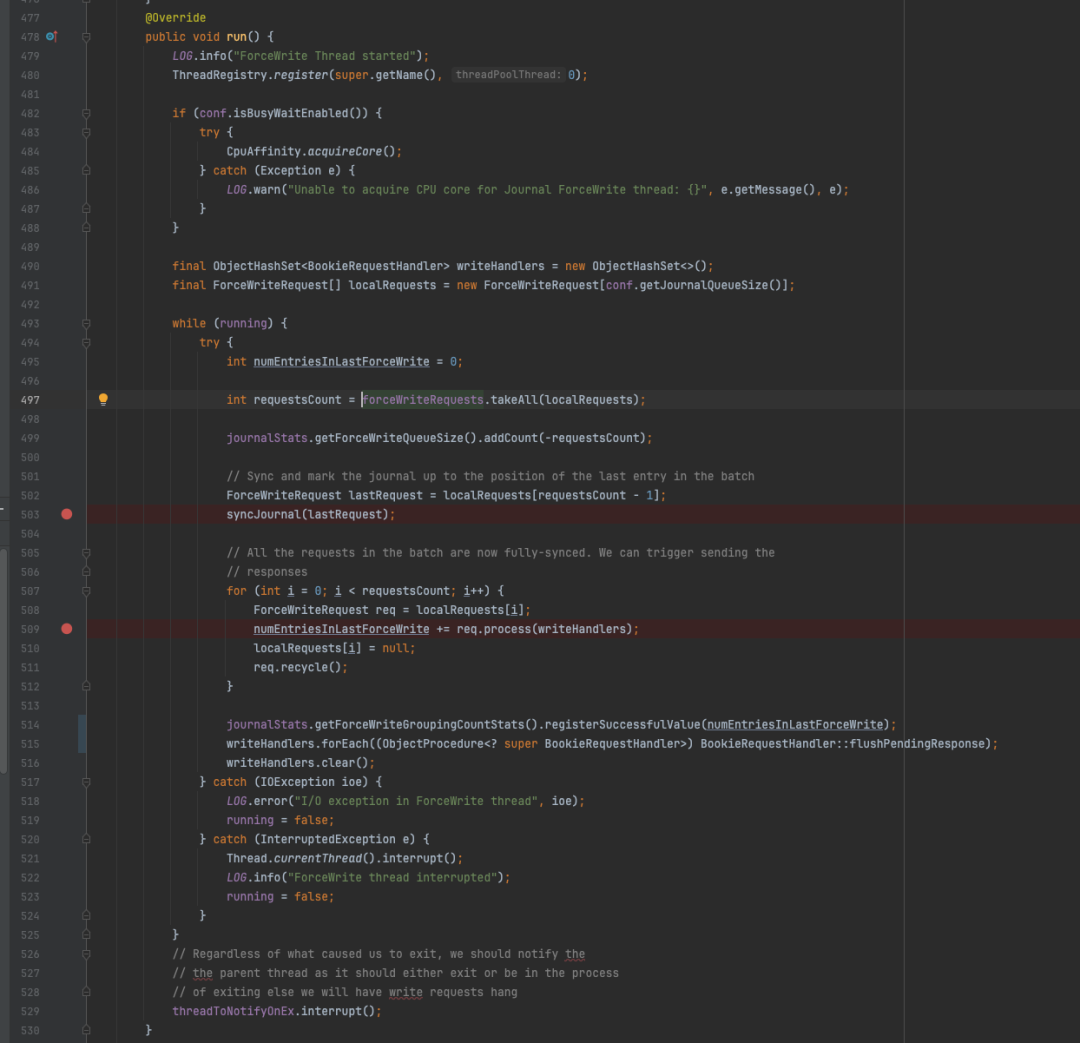
ForceWriteThread#run
Journal#syncJournal方法调用了request对象的flushFileToDisk方法,该方法内部调用了logFile.forceWrite(false); 。
logFile就是之前提到的单个journal文件的抽象,即JournalChannel,其内部封装了BufferedChannel,实际的类型为DefaultEntryLogger,与EntryLogger所使用的底层实现如出一辙。
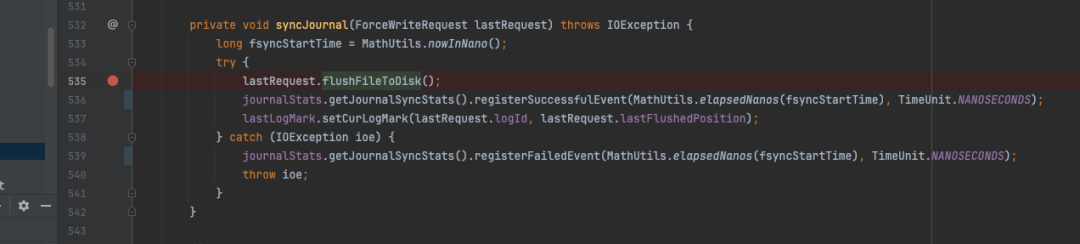
Journal#syncJournal
JournalChannel类
再论Bookie
上文提到BookieImpl中的addEntry逻辑似乎很简单,数据写入交由LedgerHander 和journal 组件,自身则是简单的封装。实则不然,查看BooikeImpl的实现,发现其中存在一个SyncThread对象,该对象是一个同步线程,其逻辑为转写journal日志的数据到entryLog和entryIndex。
BookieImpl
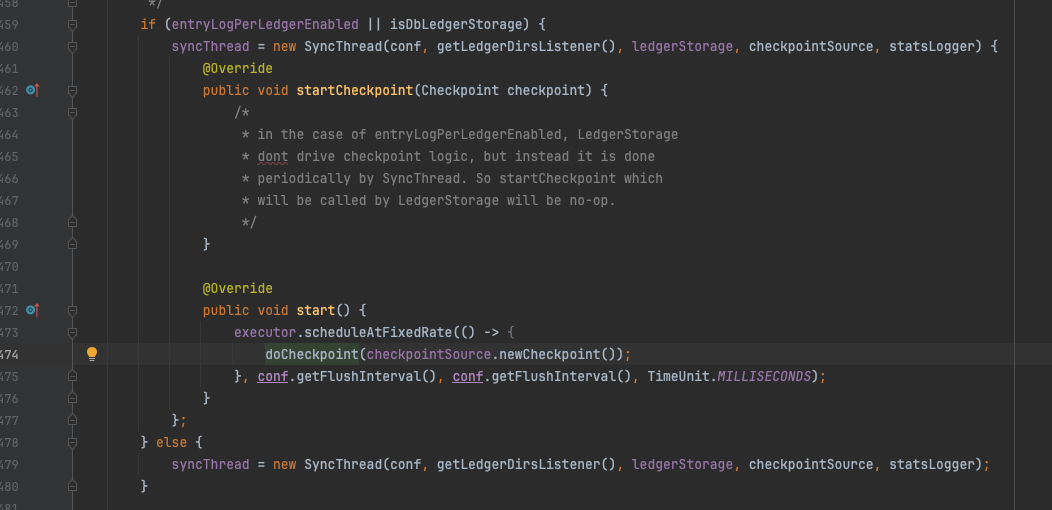
启动checkpoint定期检查
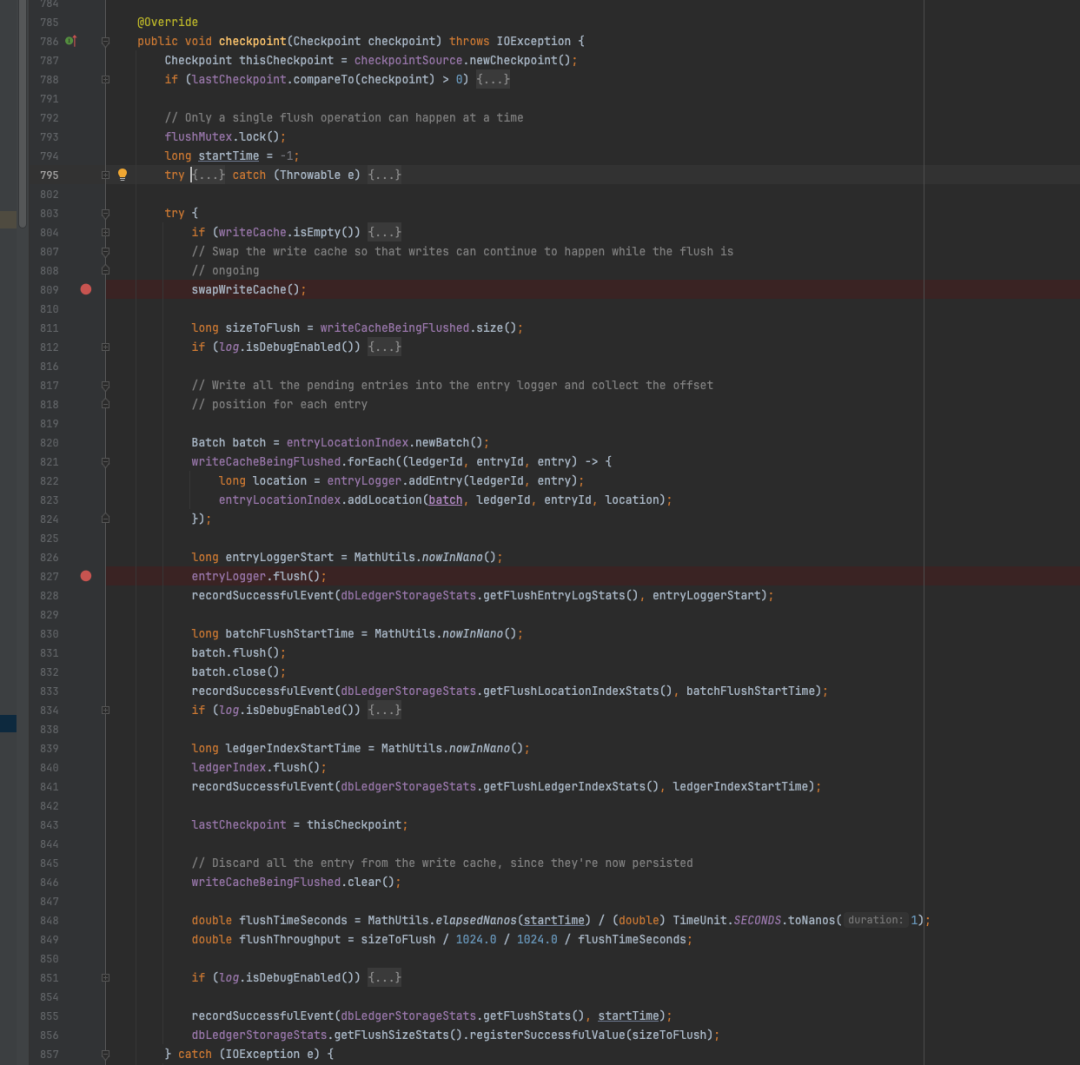
doCheckpoint在底层最终调用了LedgerStorage#checkpoint方法,与上文提到的writeCache 背后的flush殊途同归。这里存在另外一个问题:SyncThread线程是否会与triggerFlushAndAddEntry中的flush线程并发执行,以及是否存在并发刷盘带来的数据错乱问题。答案是不会,具体来看checkpoint方法内部存在一个flushMutex锁,同时在进入锁之前,首先会对当前的checkpoint做判断,如果传入的checkpoint水位线低于当前SingleDirectoryDbLedgerStorage对象持有的lastCheckpoint水位线,则不执行实际的checkpoint动作。
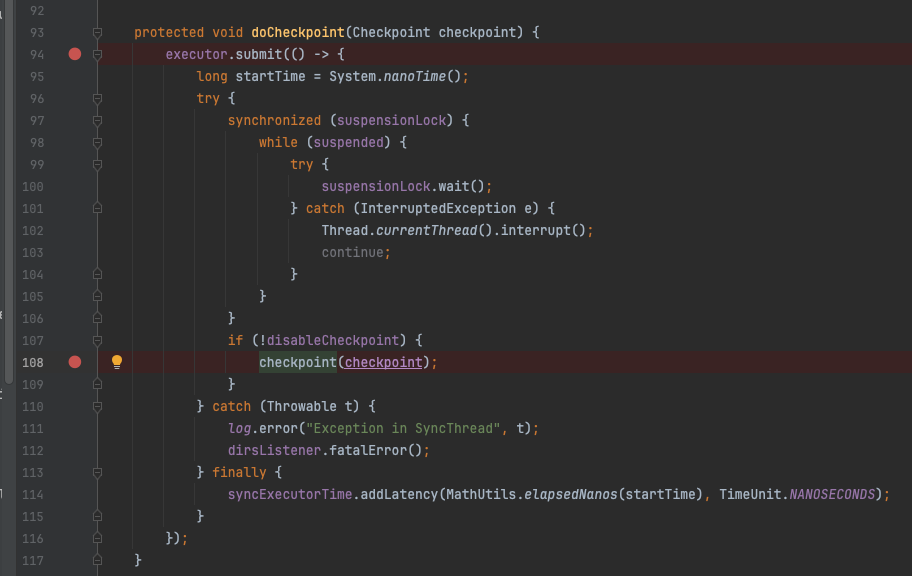
SyncThread#doCheckpoint
server端分析总结
Bookeeper的server端的架构较为复杂,分为多级写入的架构,收据流向为:
-
数据首先进入writeCache,有后台线程定期将cache数据同步到entryLog和 entryIndex;
-
writeCache 底层采用swap机制,保证写入延迟的稳定性。
-
-
调用entryLog和entryIndex 分别写入业务数据和索引数据;
-
entryIndex 使用rocksDB作为KV索引保存 LedgerId+ entryId 到 offset的映射关系。
-
-
SingleDirectoryDbLedgerStorage#flush操作和EntryLogger#flush操作不同;
-
前者只是将数据同步到entryLog和entryIndex中;
-
后者真实调用底层的文件系统进行刷盘。
-
-
journal日志的写入时可配置的,默认开启,journal日志同样存在后台的刷盘线程;
-
journal线程一直重复在干两件事;
-
将QueueEntry转化为二进制写入bufferChannel的writebuffer;
-
综合判断各种条件,定期向forceWriteThread线程 提交真实的刷盘任务。
-
-
四、Bookie的数据读取流程
server端源码分析
请求路由
回到BookieRequestProcessor#processRequest的源码截图,读取流程围绕READ_ENTRY这一opCode展开,同样在最新版本的 Bookie代码中,read processor 升级到了V3版本。
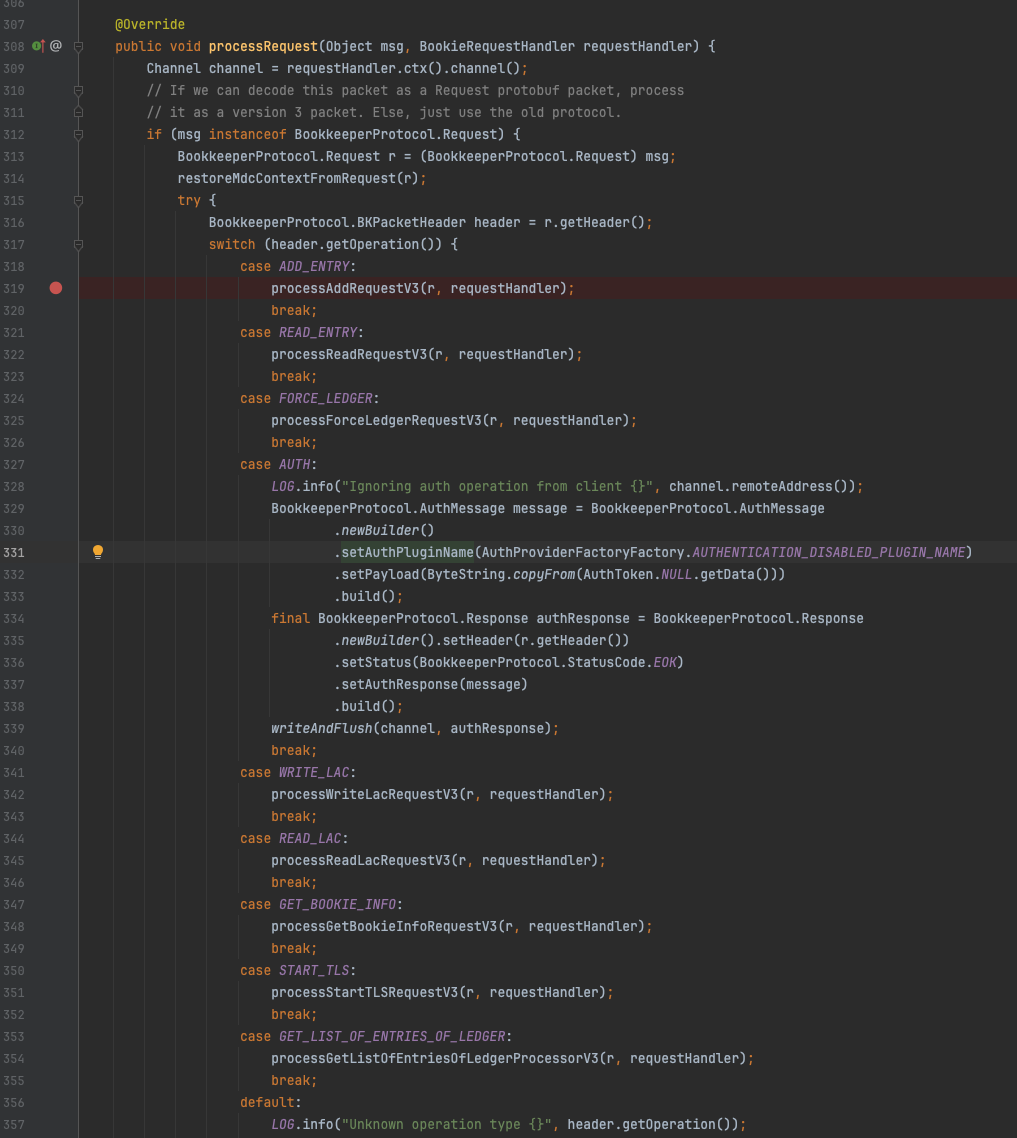
BookieRequestProcessor#processRequest
和写入一样,在读取的processReadRequestV3方法中,依然有高优先级线程池和普通线程池,不同的是还多了一个长轮询线程池,在投递任务时又出现了熟悉的操作,跟LedgerId 选择线程池中具体的线程执行操作。
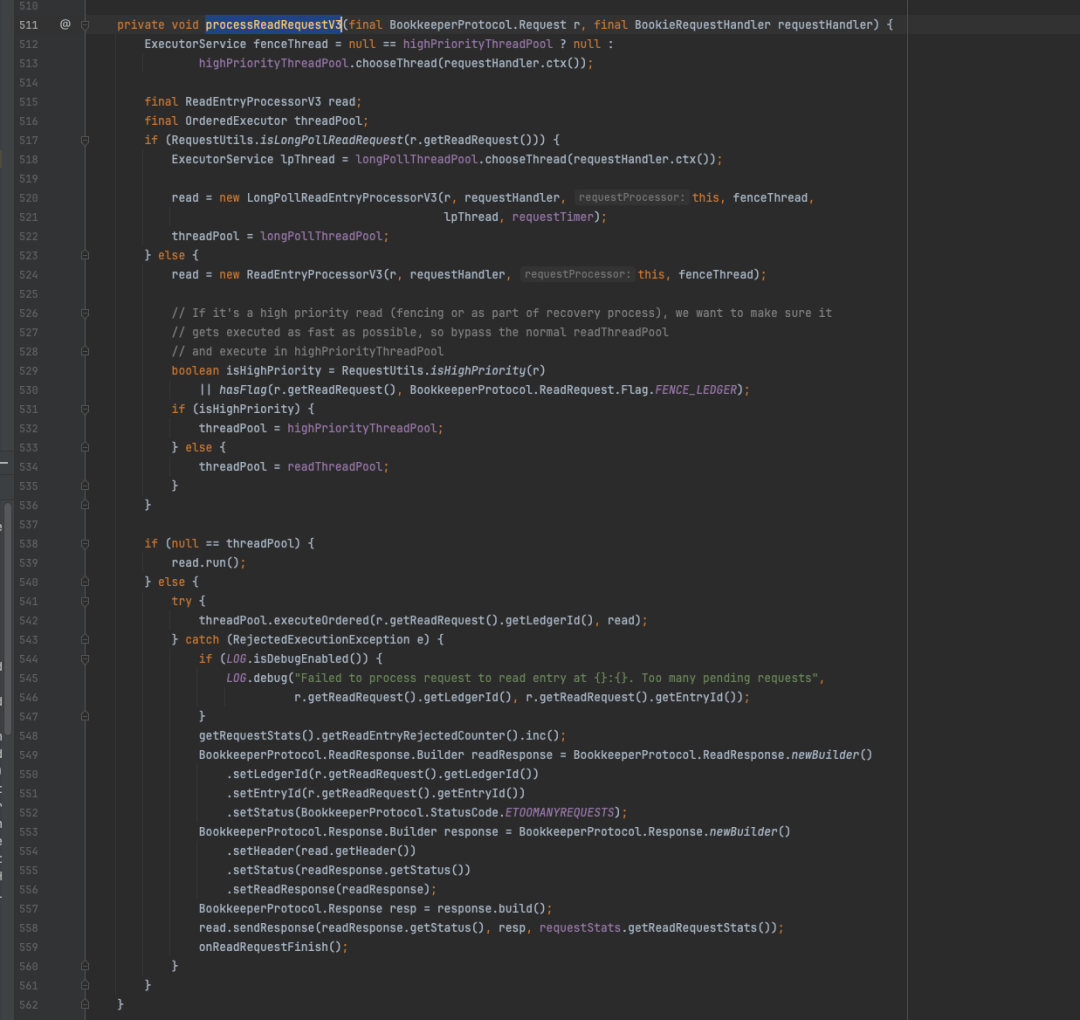
BookieRequestProcessor#processReadRequestV3
直接跳转ReadEntryProcessorV3#run方法。发现是个空壳,逻辑封装executeOp方法中。
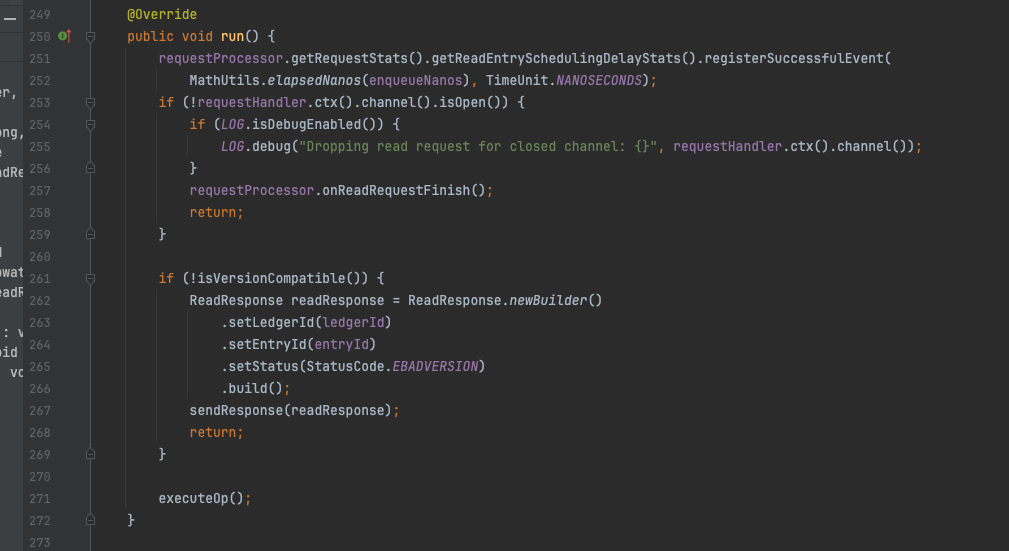
ReadEntryProcessorV3#run
BookieImpl#readEntry
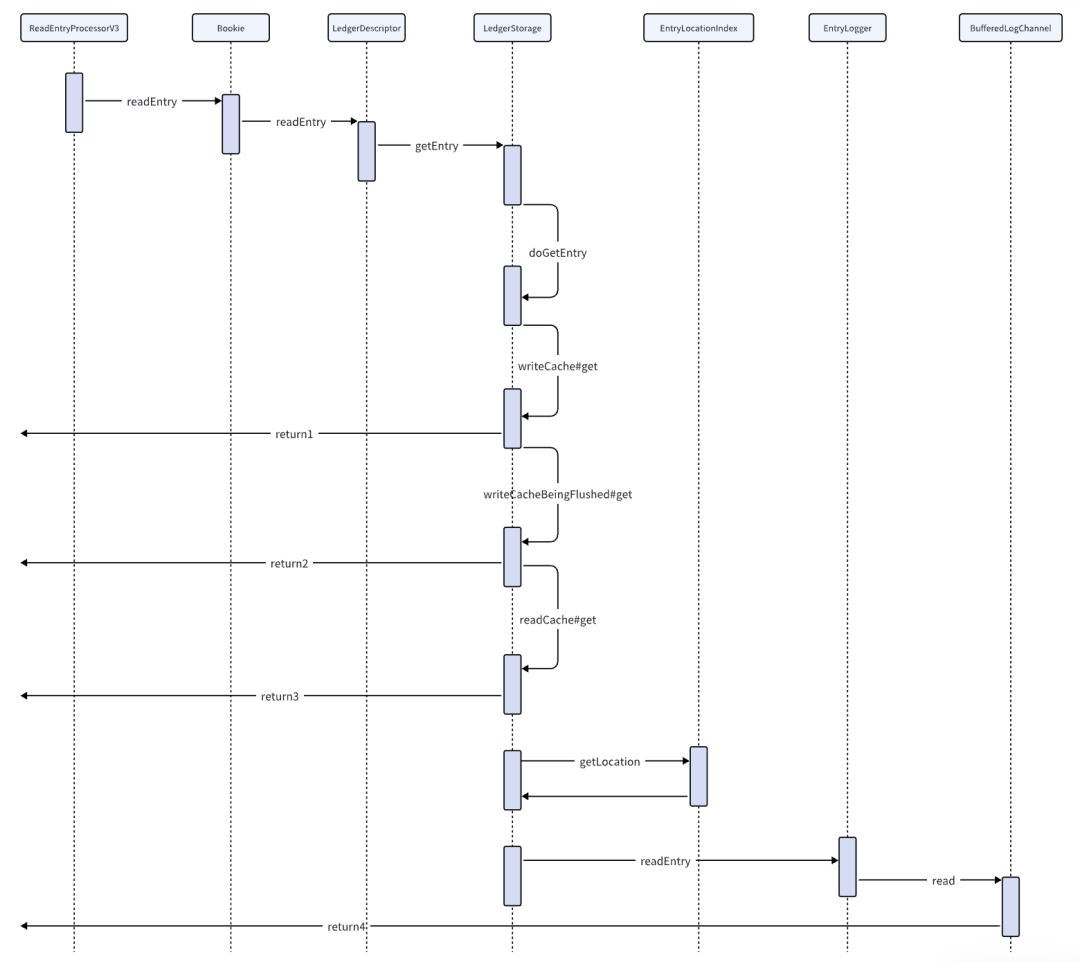
最终的读取逻辑在BookieImpl#readEntry中,该方法只是简单的封装,根据LedgerId获取到LedgerDescriptor后,读取逻辑顺利委托给了LedgerDescriptor,在LedgerDescriptor#readEntry方法内进一步套娃,又将请求转移给了LedgerStorage#getEntry,前文提到LedgerStorage 是个接口,真正干活的是 SingleDirectoryDbLedgerStorage中的doGetEntry 方法,这个类在写入请求的分析过程中同样出场过。

BookieImpl#readEntry
doGetEntry方法的逻辑整体较为简单,主要分为以下几步:
-
如果传入的entryId为-1 ,表示读取LAC ,先从Ledger中获取实际的LAC的entryId,在进行读取;
-
默认先从writeCache中读取,如果读取不到则去writeCacheBeingFlushed中读取,命中则直接返回;
-
如果2级缓存中均不存在,则去readCache中据需读取;
-
如果readCache也不存在,那么就要触发磁盘读,先去entryLocationIndex获取entryLogger中的物理偏移量;
-
随后调用entry = entryLogger.readEntry(ledgerId, entryId, entryLocation); 获取真实数据;
-
数据获取到后会放入readCache中;
-
在方法结束时,会触发一次预读,读取紧挨着当前entry的下一个entry并放入readCache中。
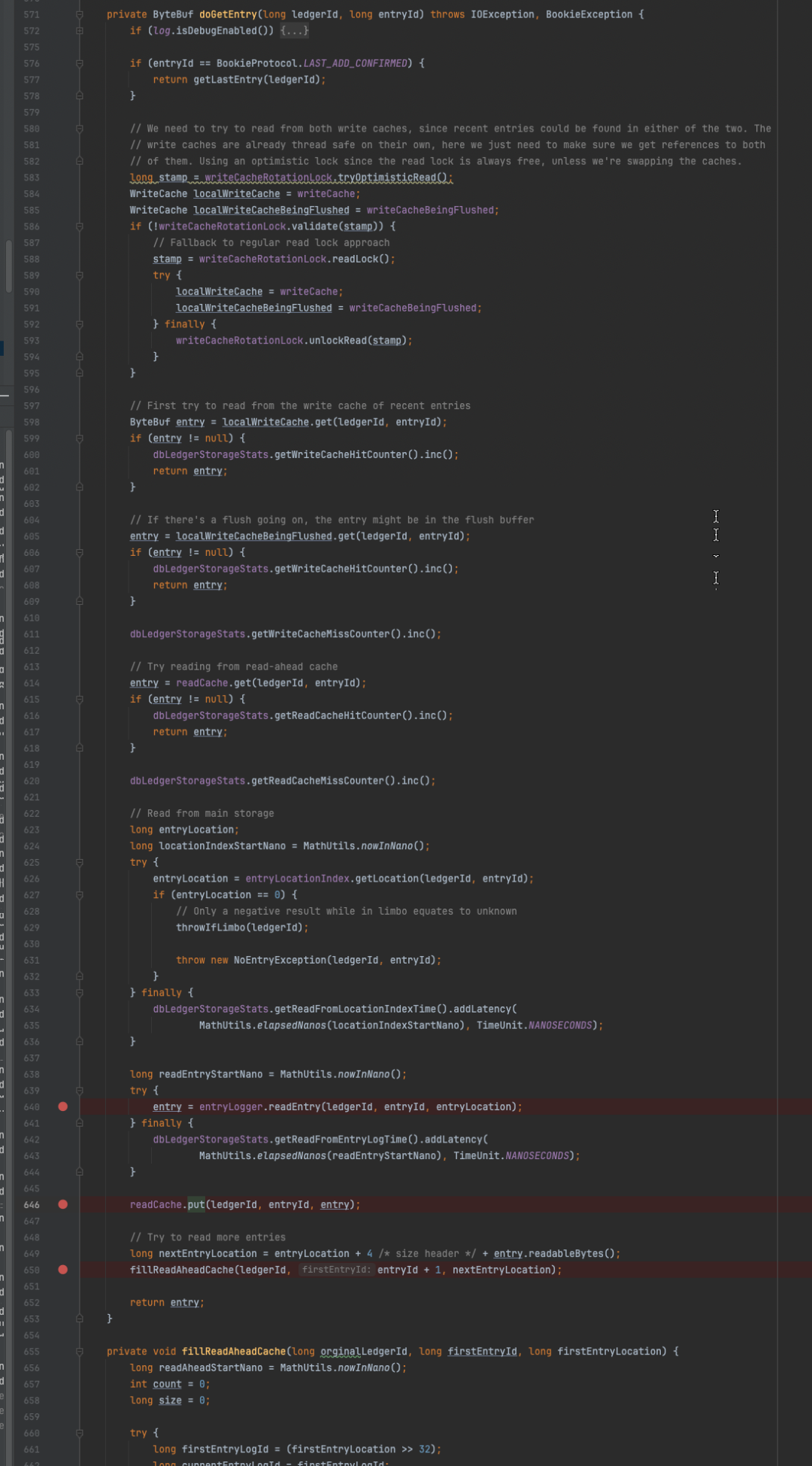
SingleDirectoryDbLedgerStorage#doGetEntry
DefaultEntryLogger如何读取entry
entry的读取在上图的640行,最终调用方法为 DefaultEntryLogger#internalReadEntry方法。逻辑如下:
-
将location参数转化为buffer中的position位点;
-
获取到FileChannel(856行);
-
从 pos-4 位置开始读取20个字节并解析,sizeBuf值为entry的整体长度(4+8+8);
-
然后分配一个 sizeBuf大小的buffer用于装载即将要读取的entry。
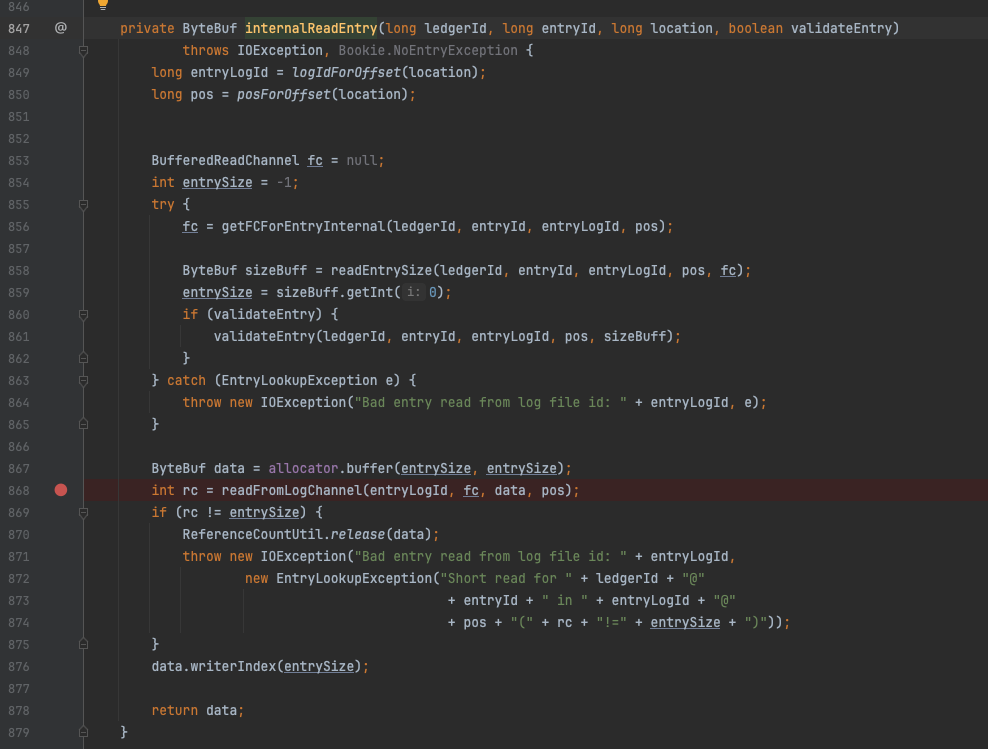
DefaultEntryLogger#internalReadEntry
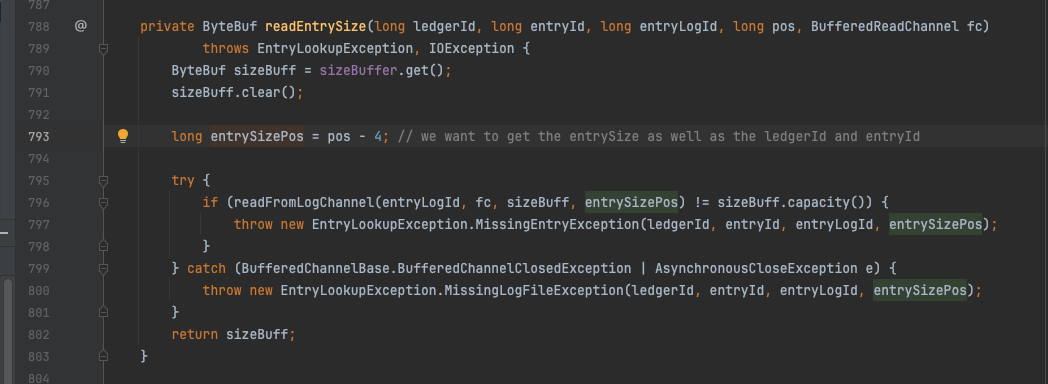
DefaultEntryLogger#readEntrySize
在存量数据足够的情况下readFromLogChannel方法会尽可能将入参中的buffer填满,在BufferedReadChannel中存在一个readBuffer,默认大小512字节,read方法仍然有可能命中该缓存。
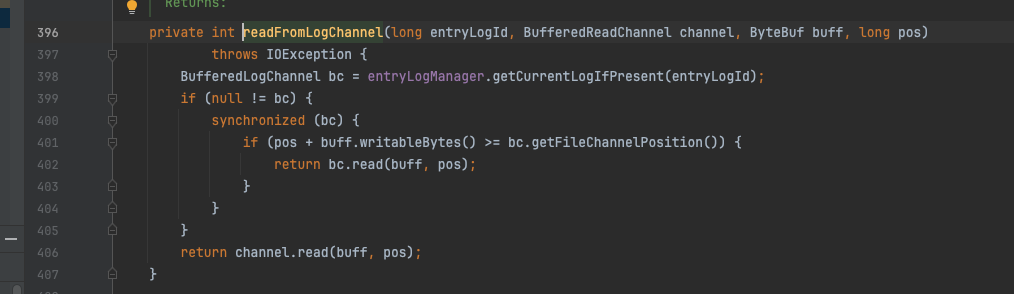
DefaultEntryLogger#readFromLogChannel
server端分析总结
数据的查询内容比较简单,从大的架构上来看整个读取过程存在三级缓存,都不命中的话才会读取磁盘。
实际上在上层的broker组件里还有一层缓存存在。消息获取流程如下图所示:
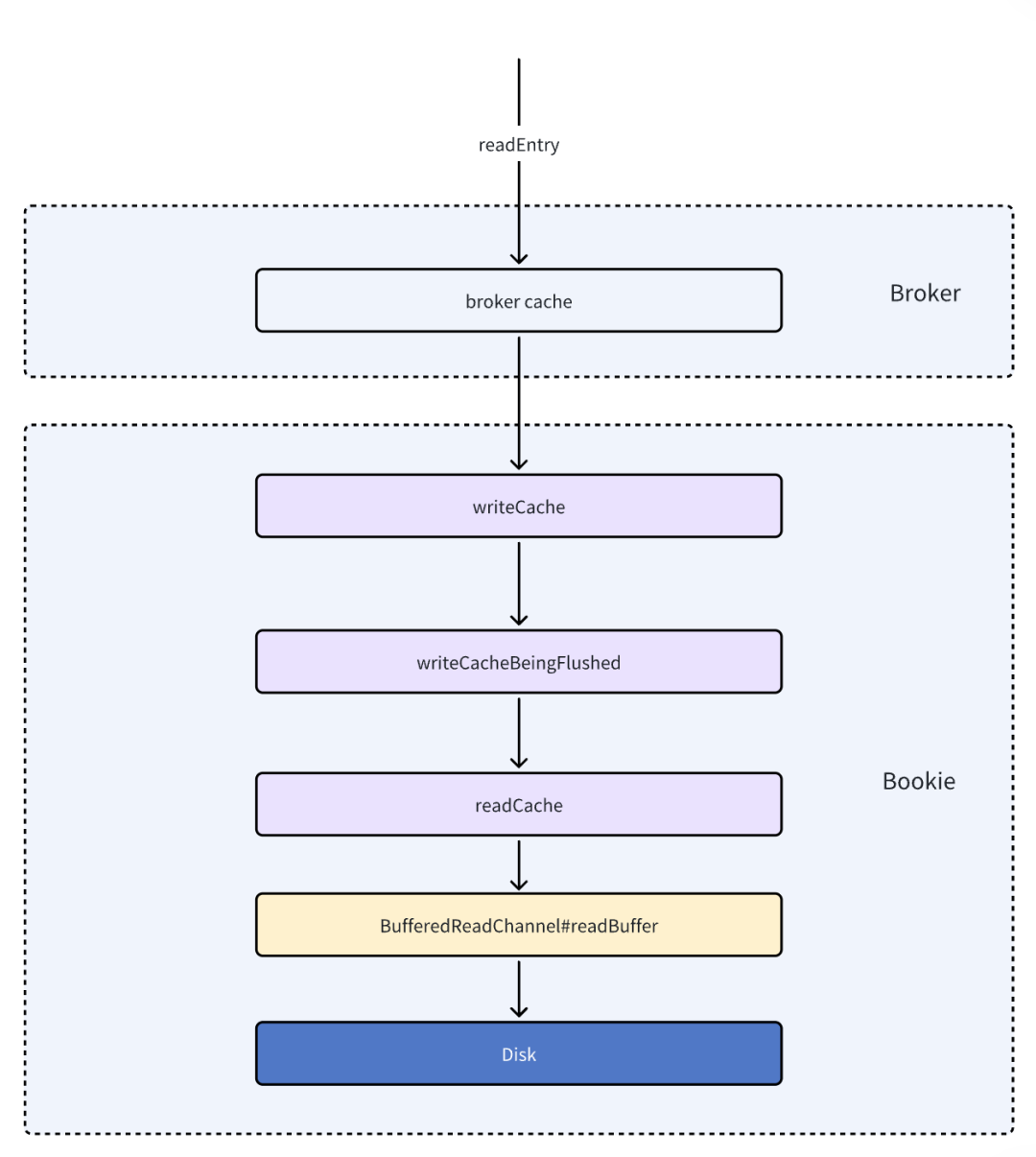
五、读写调用链分析
组件模块分析
BufferedChannel
其派生关系如下图所示,还有一个SlowBufferedChannel继承BufferedChannel类,但是该类为测试使用。BufferedReadChannel是读场景下的主要支撑类,内部有512字节的读缓冲。

EntryLogger
默认使用DefaultEntryLogger,主要用于存储实际的entry对象数据,DefaultEntryLogger 和DirectEntryLogger的区别在于一个使用JDK的RandomAccessFile ,另一个直接使用DIO(单独依赖特定C库)。

DefaultEntryLogger
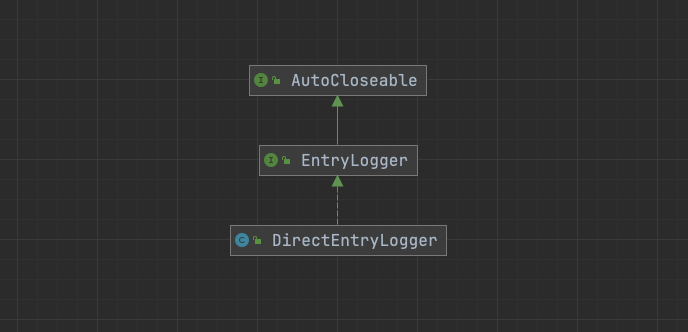
DirectEntryLogger
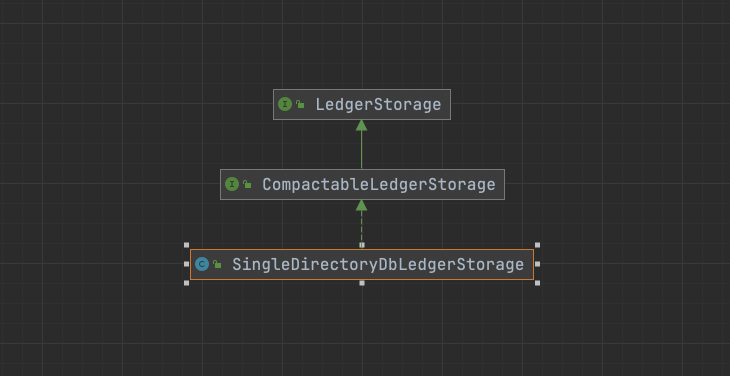
LedgerStorage
基于EntryLogger的上层抽象,主要实现有InterleavedLedgerStorage和 SingleDirectoryDbLedgerStorage, 还有一个SortedLedgerStorage,内部封装了InterleavedLedgerStorage,复用了大部分的InterleavedLedgerStorage的方法。SortedLedgerStorage每次写入时对内部的数据进行排序,使用自带的KV引擎存储 LedgerId+entryId-->location映射关系。SingleDirectoryDbLedgerStorage每次刷盘时才会对缓存的数据进行排序,使用rocksDB存储KV关系。
SingleDirectoryDbLedgerStorage
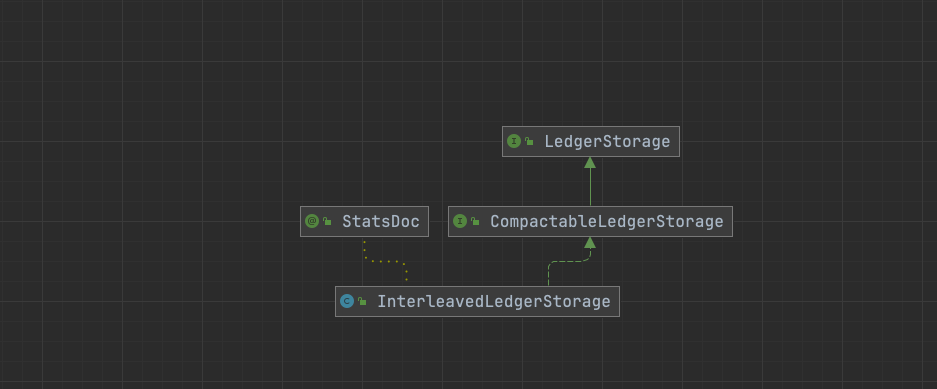
InterleavedLedgerStorage
LedgerDescriptor
包装类,大部分逻辑委托给ledgerStorage实现。内部持有ledgerId,每个ledgerId 对应一个LedgerDescriptor对象。
Bookie
Bookie节点级存储抽象,内部封装了多个journal抽象组成的journalList,ledgerStorage,syncThread线程。
syncThread线程主要负责将journal中的appendLog转写为entryLog和enrtyIndex,checkpoint之前的数据在执行GC(数据清理工作,非JVM中的GC)时可被回收删除。
ReadEntryProcessorV3,WriteEntryProcessorV3
负责读写指令的路由和转化。
写入流程调用时序
WriteEntryProcessorV3
--> Bookie
-->LedgerDescriptor
-->LedgerStorage
-->EntryLogger
-->BufferedLogChannel

读取流程调用时序
ReadEntryProcessorV3
--> Bookie
-->LedgerDescriptor
-->LedgerStorage
-->EntryLogger
-->BufferedReadChannel
六、架构总结
Bookie的存储架构主要分为三大块,首先是代表WAL日志的journal文件写入,以顺序混写的方式提升写入性能,保证低延迟,通常以独立盘隔离挂载,典型的消息场景下journal日志写完后即可返回。由于是不同topic的混合写入,journal日志无法很好的支撑单个topic的消息的顺序读,回溯等场景,会存在读放大问题。
由此就衍生出了entryLog的二次转储,为了尽可能利用顺序读,单个entryLog内部的数据在写入时会根据ledgerId+entryId排序,这样同一个ledgerId的数据会紧密的收敛在局部,能够一定程度上提升读性能;entryLog写入后会获取到消息实际存储的位点信息offset,由于该offset不可被自定义,很难表述出这条消息在topic写入序列上为第几条信息,这一点很重要,因为消费的时候是基于这样的序列来消费的,同时在消费位点管理时也需要这样的信息。
entryId的作为一个传入参数,其作用恰恰如此,是一个面向用户的更易于管理的唯一Id。当用户基于ledgerId+entryId来查找数据时,显然并不知道这个这条数据实际存储offset信息。这就诞生了一个额外的 KV 结构,用来保存ledgerId+entryId到 offset的映射关系。Bookie 内嵌了rocksDB的KV引擎,同时也自行实现了一套,Pulsar默认使用rocksDB方式保存 KV 关系。
bookie在整个写入和读取过程中利用了大量的用户态缓存机制,相比于mmap的 pageCache机制更为灵活可控,同时也很大程度上降低了读写的抖动,尤其是在容器环境下不同 POD 互相干扰的情况。
*文/簌语
本文属得物技术原创,更多精彩文章请看:得物技术官网
未经得物技术许可严禁转载,否则依法追究法律责任!