这篇文章采用预训练的DenseNet121模型并使用自定义的数据集类和自定义的类似正态分布的标签平滑策略来训练了一个人脸年龄分类模型,最后基于这个模型用tk实现了一个娱乐向的小系统。
数据集展示:
两个文件夹,分别是训练集和测试集,每个文件夹中有70个子文件夹,子文件夹名字是年龄,里面是该年龄的图片,RGB224*224,从某个比赛搞来的。这个数据集不太好,0~3岁低龄的挺多,建议换一个自己的数据集。顺便改用自己的数据集类读取。




数据集的读取
使用自定义的数据集类进行读取,并采用transform预处理。
我训练使用的是笔记本上的RTX 2060,显存6GB,所以训练批次32,测试批次16刚好不爆显存。你们训练以数据集不爆显存为好。
from torch.utils.data import DataLoader, Dataset
class CustomDataset(Dataset): # 自定义的数据集类
def __init__(self, root_dir, transform=None):
self.transform = transform
self.images_path = [] # 图片路径
self.labels = [] # 标签
# 遍历文件夹获取图片和标签
for label in os.listdir(root_dir):
label_dir = os.path.join(root_dir, label) # root_dir, label拼接成完整路径
if os.path.isdir(label_dir): # 是不是目录
for img_name in os.listdir(label_dir): # 从目录中得到所有图片名
img_path = os.path.join(label_dir, img_name) # 拼接成完整路径
self.images_path.append(img_path) # 图片路径添加
self.labels.append(int(label) - 1) # 标签添加
def __len__(self):
return len(self.images_path)
def __getitem__(self, idx): # 根据idx返回数据和标签
label = self.labels[idx]
img_path = self.images_path[idx]
image = Image.open(img_path).convert('RGB') # pil打开图片转为RGB
if self.transform: # 图片预处理存在就应用
image = self.transform(image)
return image, label
batch_size = 16
# 定义一个transform,将图片调整到模型需要的尺寸(224x224)
train_transform = transforms.Compose([
transforms.Resize((224, 224)), # DenseNet需要224x224的图片
# 应用随机宽度和高度偏移
transforms.RandomAffine(
degrees=10, # 应用随机旋转,10°
translate=(0.1, 0.1), # 宽度和高度的最大绝对偏移比例(相对于图片尺寸)
scale=(0.8, 1.2), # 随机缩放,
shear=None, # 不应用剪切变换
fillcolor=0), # 填充颜色,对于像素值为0的位置进行填充
transforms.RandomHorizontalFlip(p=0.5), # 以0.5的概率进行水平翻转
transforms.ToTensor(), # 将PIL图片或NumPy ndarray转换为tensor,并归一化
transforms.Normalize(mean=[0.6377, 0.4879, 0.4189],
std=[0.2119, 0.1905, 0.1831]), ]) # 归一化到[-1, 1]范围,使用ImageNet的均值和标准差
# mean = tensor([0.6377, 0.4879, 0.4189]) std = tensor([0.2119, 0.1905, 0.1831])
test_transform = transforms.Compose([
transforms.Resize((224, 224)), # DenseNet需要224x224的图片
# 将PIL图片或NumPy ndarray转换为tensor,并归一化
transforms.ToTensor(),
# 归一化到[-1, 1]范围,使用ImageNet的均值和标准差
transforms.Normalize(mean=[0.6377, 0.4879, 0.4189],
std=[0.2119, 0.1905, 0.1831]), ])
train_dataset = CustomDataset(root_dir='你的训练集位置(建议用绝对路径)',
transform=train_transform) # 替换为你的数据集类
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) # 加载数据集,批次batch_size,随机打乱
test_dataset = CustomDataset(root_dir='你的测试集位置(建议用绝对路径',
transform=test_transform) # 替换为你的数据集类
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False) # 加载数据集,批次batch_size模型训练及测试
模型采用预训练的DenseNet121模型,它的特点是每一层都复用前面所有层的输出,简称特征复用。它参数量大概是ResNet50的三分之一,比较好训练。因为只是一个简单的70类分类问题,放置过拟合加入标签平滑策略,简单说就是平常的训练是独热编码,现在将独热编码里面的1减去一个小于1的数,并将减去的值均分到其他类上,可以放置过拟合。
这里将训练和测试分开了,训练后通过加载模型来测试,分两次运行,记着看看代码。
训练时注意,训练轮数指的是每个学习率的训练轮数,这里填了4个学习率,所以总训练轮数是10*4轮,训练过程会输出到日志中。
import time
import numpy as np
import torch
import torch.nn as nn
import torchvision.models as models
import torchvision as tv
import torchvision.transforms as transforms
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader, Dataset
from PIL import Image
import os
class CustomDataset(Dataset): # 自定义的数据集类
def __init__(self, root_dir, transform=None):
self.transform = transform
self.images_path = [] # 图片路径
self.labels = [] # 标签
# 遍历文件夹获取图片和标签
for label in os.listdir(root_dir):
label_dir = os.path.join(root_dir, label) # root_dir, label拼接成完整路径
if os.path.isdir(label_dir): # 是不是目录
for img_name in os.listdir(label_dir): # 从目录中得到所有图片名
img_path = os.path.join(label_dir, img_name) # 拼接成完整路径
self.images_path.append(img_path) # 图片路径添加
self.labels.append(int(label) - 1) # 标签添加
def __len__(self):
return len(self.images_path)
def __getitem__(self, idx): # 根据idx返回数据和标签
label = self.labels[idx]
img_path = self.images_path[idx]
image = Image.open(img_path).convert('RGB') # pil打开图片转为RGB
if self.transform: # 图片预处理存在就应用
image = self.transform(image)
return image, label
# 实现label smoothing
class LabelSmoothing(nn.Module):
def __init__(self, eps=0.1, num_classes=10):
super(LabelSmoothing, self).__init__()
self.eps = eps
self.num_classes = num_classes
self.log_softmax = nn.LogSoftmax(dim=1)
def forward(self, inputs, targets):
log_probs = self.log_softmax(inputs)
targets = torch.zeros_like(log_probs).scatter(1, targets.unsqueeze(1), 1)
targets = (1 - self.eps) * targets + self.eps / self.num_classes
loss = (-targets * log_probs).mean(0).sum()
return loss
# 设置label smoothing参数
# 加载预训练的DenseNet121模型
densenet = models.densenet121(pretrained=True)
# 调整模型的最后一层以适应70个类别
num_ftrs = densenet.classifier.in_features
densenet.classifier = nn.Sequential(
nn.Linear(num_ftrs, 70),
nn.LogSoftmax(dim=1)
)
# densenet.load_state_dict(torch.load("./cnn/cnn_1713708689.5869677_2e-05.pth")) # 加载模型
# densenet.load_state_dict(torch.load("./cnn/cnn_l_0.8_1713716586.3752456_2e-05.pth"))
# densenet.load_state_dict(torch.load("./cnn/cnn_l_0.655_1713724008.75501_2e-05.pth"))
# densenet.load_state_dict(torch.load("./cnn/cnn_l_0.448_1713742487.387269_2e-05.pth"))
# densenet.load_state_dict(torch.load("./cnn/cnn_l_gs_1713783963.7627246_2e-05.pth"))
xunlian = False # 不训练
batch_size = 16
wenjian = False # 不训练是否保存输出到文件中
# wenjian = True
# xunlian = True # 训练
# batch_size = 32 # 测试调16,不然爆显存,32批次2min一轮 15-4 = 11,473s
now_time = time.time()
alpha = 0.448 # LabelSmoothing参数
num_classes = 70 # 分类数目
num_epochs = 10 # 训练轮数
out_num = 50 # 每多少批次输出一次
lrs = [1e-3, 1e-4, 5e-5, 2e-5]
# criterion = nn.CrossEntropyLoss() # 对于多分类问题,通常使用交叉熵损失
criterion = LabelSmoothing(eps=alpha, num_classes=num_classes) # label smooth策略
# 4. 准备数据
# 定义一个transform,将图片调整到模型需要的尺寸(224x224)
train_transform = transforms.Compose([
transforms.Resize((224, 224)), # DenseNet需要224x224的图片
# 应用随机宽度和高度偏移
transforms.RandomAffine(
degrees=10, # 应用随机旋转,10°
translate=(0.1, 0.1), # 宽度和高度的最大绝对偏移比例(相对于图片尺寸)
scale=(0.8, 1.2), # 随机缩放,
shear=None, # 不应用剪切变换
fillcolor=0), # 填充颜色,对于像素值为0的位置进行填充
transforms.RandomHorizontalFlip(p=0.5), # 以0.5的概率进行水平翻转
transforms.ToTensor(), # 将PIL图片或NumPy ndarray转换为tensor,并归一化
transforms.Normalize(mean=[0.6377, 0.4879, 0.4189],
std=[0.2119, 0.1905, 0.1831]), ]) # 归一化到[-1, 1]范围,使用ImageNet的均值和标准差
# mean = tensor([0.6377, 0.4879, 0.4189]) std = tensor([0.2119, 0.1905, 0.1831])
test_transform = transforms.Compose([
transforms.Resize((224, 224)), # DenseNet需要224x224的图片
# 将PIL图片或NumPy ndarray转换为tensor,并归一化
transforms.ToTensor(),
# 归一化到[-1, 1]范围,使用ImageNet的均值和标准差
transforms.Normalize(mean=[0.6377, 0.4879, 0.4189],
std=[0.2119, 0.1905, 0.1831]), ])
if xunlian:
train_dataset = CustomDataset(root_dir='C:\\Users\\86135\\PycharmProjects\\pythonProject\\1\\data\\train',
transform=train_transform) # 替换为你的数据集类
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) # 加载数据集,批次batch_size,随机打乱
else:
train_dataset = CustomDataset(root_dir='C:\\Users\\86135\\PycharmProjects\\pythonProject\\1\\data\\train',
transform=test_transform) # 替换为你的数据集类
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=False) # 加载数据集,批次batch_size,随机打乱
test_dataset = CustomDataset(root_dir='C:\\Users\\86135\\PycharmProjects\\pythonProject\\1\\data\\val',
transform=test_transform) # 替换为你的数据集类
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False) # 加载数据集,批次batch_size
# 5. 进行训练和/或评估
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
densenet = densenet.to(device)
optimizer = torch.optim.Adam(densenet.parameters(), lr=1e-2)
i = 0 # 绘图用
if xunlian:
with open(f'./out/output_{now_time}.txt', 'w', encoding='utf-8') as file:
def Print_two(out):
out = str(out)
print(out)
file.write(out + "\n")
Print_two("开始训练===================================================")
lentrain = len(train_dataloader)
process = []
for lr in lrs:
for param_group in optimizer.param_groups:
param_group['lr'] = lr
Print_two(f"学习率更改为{lr}")
file.flush() # 确保数据被写入磁盘
for epoch in range(num_epochs):
running_loss = 0.0 # 训练误差
Print_two(time.time())
for i, [inputs, labels] in enumerate(train_dataloader):
inputs, labels = inputs.to(device), labels.to(device)
# 前向传播
outputs = densenet(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 打印log信息
running_loss += loss.item() # 1000个batch的误差和
if i % out_num == out_num - 1: # 每100个batch打印一次训练状态
Print_two(
f"第{epoch + 1:2d}/{num_epochs:2d}轮循环,{i + 1:4d}/{lentrain:4d}组,平均误差为:{running_loss / out_num:.4f}")
process.append(running_loss)
running_loss = 0.0 # 误差归零
# 模型保存==========================================
seat = f'./cnn_l_0.448_{time.time()}_{lr}.pth'
Print_two(f"保存模型至{seat}======================================")
torch.save(densenet.state_dict(), seat)
Print_two("保存完毕")
print("Finished Training")
# 绘制训练过程
i = i + 1
plt.figure(i)
plt.plot(list(range(len(process))), process, 'g:', label='loss')
plt.legend(loc='lower right') # 显示上面的label
plt.xlabel('time') # x_label
plt.ylabel('loss') # y_label
plt.title('loss about time') # 标题
plt.show() # 显示=========
else:
def save_out(f, data, ):
data = np.array(data.data.to("cpu"))
for i in data:
for j in i:
f.write(str(j) + ";")
f.write("\n")
def save_l(f, data, ):
data = np.array(data.data.to("cpu"))
for i in data:
f.write(str(i) + "\n")
if wenjian: # 用来保存模型输出,如果后续想进行模型融合,可以启用
# file_train = open(f'./out/test1_train.txt', 'w', encoding='utf-8')
# file_test = open(f'./out/test1_test.txt', 'w', encoding='utf-8')
# file_y_train = open(f'/y_train.txt', 'w', encoding='utf-8')
# file_y_test = open(f'/y_test.txt', 'w', encoding='utf-8')
pass
# 模型测试==========================================
densenet.eval()
print("开始测试===================================================")
# 在训练集上测试====================================
correct = 0 # 预测正确图片数
total = 0 # 总图片数
for images, labels in train_dataloader:
images = images.to(device)
labels = labels.to(device)
outputs = densenet(images)
if wenjian:
# save_out(file_train, outputs)
# save_l(file_y_train, labels)
pass
# 返回得分最高的索引(一组 4 个)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print("训练集中的准确率为:%d %%" % (100 * correct / total))
# 在测试集上测试====================================
correct = 0 # 预测正确图片数
total = 0 # 总图片数
for images, labels in test_dataloader:
images = images.to(device)
labels = labels.to(device)
outputs = densenet(images)
if wenjian:
# for out_i in range(len(outputs)):
# save_out(file_test, outputs)
# save_l(file_y_test, labels)
pass
# 返回得分最高的索引(一组 4 个)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print("测试集中的准确率为:%d %%" % (100 * correct / total))
if wenjian:
# file_train.close()
# file_test.close()
# file_y_train.close()
# file_y_test.close()
pass
# 输出在测试集上一组(4个)的数据和预测结果===================
dataiter = iter(test_dataloader) # 生成测试集的可迭代对象
images, labels = dataiter.next() # 得到一组数据
# 绘图====================
i = i + 1
plt.figure(i)
npimg = (tv.utils.make_grid(images / 2 + 0.5)).numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
print("实际标签:", " ".join("%08s" % labels))
show = transforms.ToPILImage() # 把tensor转为image
images = images.to(device)
labels = labels.to(device)
outputs = densenet(images) # 计算图片在每个类别上的分数
# 返回得分最高的索引
_, predicted = torch.max(outputs.data, 1) # 第一个数是具体值,不需要
# 一组 4 张图,所以找每行的最大值
print("预测结果:", " ".join("%08s" % predicted))
plt.show() # 显示=========
基础的标签平滑太没意思了,在训练时,我想到这东西是个年龄,各个年龄之间有相邻关系,所以我考虑用正态分布(高斯分布)的形状来修改标签平滑。
所以最后的训练测试代码是这样的:
import time
from scipy.stats import norm
import numpy as np
import torch
import torch.nn as nn
import torchvision.models as models
import torchvision as tv
import torchvision.transforms as transforms
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader, Dataset
from PIL import Image
import os
class CustomDataset(Dataset): # 自定义的数据集类
def __init__(self, root_dir, transform=None):
self.transform = transform
self.images_path = [] # 图片路径
self.labels = [] # 标签
# 遍历文件夹获取图片和标签
for label in os.listdir(root_dir):
label_dir = os.path.join(root_dir, label) # root_dir, label拼接成完整路径
if os.path.isdir(label_dir): # 是不是目录
for img_name in os.listdir(label_dir): # 从目录中得到所有图片名
img_path = os.path.join(label_dir, img_name) # 拼接成完整路径
self.images_path.append(img_path) # 图片路径添加
self.labels.append(int(label) - 1) # 标签添加
def __len__(self):
return len(self.images_path)
def __getitem__(self, idx): # 根据idx返回数据和标签
label = self.labels[idx]
img_path = self.images_path[idx]
image = Image.open(img_path).convert('RGB') # pil打开图片转为RGB
if self.transform: # 图片预处理存在就应用
image = self.transform(image)
return image, label
# 实现label smoothing
class CustomLabelSmoothing(nn.Module):
def __init__(self, eps=0.1, num_classes=10):
super(CustomLabelSmoothing, self).__init__()
self.eps = eps
self.num_classes = num_classes
self.log_softmax = nn.LogSoftmax(dim=1)
# 预先计算正态分布的概率值,以提高效率
self.middle = num_classes // 2
self.normal_probs = self._calculate_normal_probs(num_classes, 0.65) # std = 0.8
def _calculate_normal_probs(self, num_classes, std_dev):
# 创建正态分布的概率分布表
peak_index = num_classes // 2 # 假设标签是从0到num_classes-1均匀分布的,peak在中间
normal_probs = np.zeros((num_classes,))
for i in range(num_classes):
diff = i - peak_index
normal_probs[i] = np.exp(-0.5 * (diff / std_dev) ** 2)
normal_probs /= normal_probs.sum() # 归一化概率
return torch.from_numpy(normal_probs).float()
def forward(self, inputs, targets):
log_probs = self.log_softmax(inputs)
targets = targets.long() # 确保targets是长整型
# 初始化平滑后的目标分布
smoothed_targets = torch.zeros_like(log_probs)
# 对每个样本应用标签平滑
for i, target in enumerate(targets):
# 找到正确标签的索引
peak_index = target
# 找到左右各两个标签的索引范围
left_bound = max(0, peak_index - 2)
right_bound = min(self.num_classes - 1, peak_index + 2)
# 应用正态分布概率值到平滑目标上
for j in range(peak_index - left_bound + 1):
smoothed_targets[i][peak_index - j] = self.normal_probs[self.middle - j]
for j in range(1, right_bound - peak_index + 1):
smoothed_targets[i][peak_index + j] = self.normal_probs[self.middle + j]
# 如果标签的边界超出了范围,用均匀分布的概率填充剩余部分
# 应用剩余的eps到所有类别上,确保总和为1
smoothed_targets += (1 - smoothed_targets.sum(dim=1, keepdim=True)) / self.num_classes
# 计算损失
loss = (-smoothed_targets * log_probs).mean(0).sum()
return loss
# 加载预训练的DenseNet121模型
densenet = models.densenet121(pretrained=True)
# 调整模型的最后一层以适应70个类别
num_ftrs = densenet.classifier.in_features
densenet.classifier = nn.Sequential(
nn.Linear(num_ftrs, 70),
nn.LogSoftmax(dim=1)
)
# densenet.load_state_dict(torch.load("./cnn/cnn_1713708689.5869677_2e-05.pth")) # 加载模型
# densenet.load_state_dict(torch.load("./cnn/cnn_l_0.8_1713716586.3752456_2e-05.pth"))
# densenet.load_state_dict(torch.load("./cnn/cnn_l_0.655_1713724008.75501_2e-05.pth"))
# densenet.load_state_dict(torch.load("./cnn/cnn_l_0.448_1713742487.387269_2e-05.pth"))
densenet.load_state_dict(torch.load("./cnn/cnn_l_gs_1713783963.7627246_2e-05.pth"))
xunlian = False # 不训练
batch_size = 16
wenjian = False # 不训练是否保存输出到文件中
# wenjian = True
# xunlian = True # 训练
# batch_size = 32 # 测试调16,不然爆显存,32批次2min一轮 15-4 = 11,473s
now_time = time.time()
eps = 0.8
num_classes = 70 # 分类数目
num_epochs = 10 # 训练轮数
out_num = 50 # 每多少批次输出一次
lrs = [1e-3, 1e-4, 5e-5, 2e-5]
# criterion = nn.CrossEntropyLoss() # 对于多分类问题,通常使用交叉熵损失
criterion = CustomLabelSmoothing(eps=eps, num_classes=num_classes) # label smooth策略
# 4. 准备数据
# 定义一个transform,将图片调整到模型需要的尺寸(224x224)
train_transform = transforms.Compose([
transforms.Resize((224, 224)), # DenseNet需要224x224的图片
# 应用随机宽度和高度偏移
transforms.RandomAffine(
degrees=10, # 应用随机旋转,10°
translate=(0.1, 0.1), # 宽度和高度的最大绝对偏移比例(相对于图片尺寸)
scale=(0.8, 1.2), # 随机缩放,
shear=None, # 不应用剪切变换
fillcolor=0), # 填充颜色,对于像素值为0的位置进行填充
transforms.RandomHorizontalFlip(p=0.5), # 以0.5的概率进行水平翻转
transforms.ToTensor(), # 将PIL图片或NumPy ndarray转换为tensor,并归一化
transforms.Normalize(mean=[0.6377, 0.4879, 0.4189],
std=[0.2119, 0.1905, 0.1831]), ]) # 归一化到[-1, 1]范围,使用ImageNet的均值和标准差
# mean = tensor([0.6377, 0.4879, 0.4189]) std = tensor([0.2119, 0.1905, 0.1831])
test_transform = transforms.Compose([
transforms.Resize((224, 224)), # DenseNet需要224x224的图片
# 将PIL图片或NumPy ndarray转换为tensor,并归一化
transforms.ToTensor(),
# 归一化到[-1, 1]范围,使用ImageNet的均值和标准差
transforms.Normalize(mean=[0.6377, 0.4879, 0.4189],
std=[0.2119, 0.1905, 0.1831]), ])
if xunlian:
train_dataset = CustomDataset(root_dir='C:\\Users\\86135\\PycharmProjects\\pythonProject\\1\\data\\train',
transform=train_transform) # 替换为你的数据集类
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) # 加载数据集,批次batch_size,随机打乱
else:
train_dataset = CustomDataset(root_dir='C:\\Users\\86135\\PycharmProjects\\pythonProject\\1\\data\\train',
transform=test_transform) # 替换为你的数据集类
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=False) # 加载数据集,批次batch_size,随机打乱
test_dataset = CustomDataset(root_dir='C:\\Users\\86135\\PycharmProjects\\pythonProject\\1\\data\\val',
transform=test_transform) # 替换为你的数据集类
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False) # 加载数据集,批次batch_size
# 5. 进行训练和/或评估
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# device = torch.device("cpu")
densenet = densenet.to(device)
optimizer = torch.optim.Adam(densenet.parameters(), lr=1e-2)
i = 0 # 绘图用
if xunlian:
with open(f'./out/output_{now_time}.txt', 'w', encoding='utf-8') as file:
def Print_two(out):
out = str(out)
print(out)
file.write(out + "\n")
Print_two("开始训练===================================================")
lentrain = len(train_dataloader)
process = []
for lr in lrs:
for param_group in optimizer.param_groups:
param_group['lr'] = lr
Print_two(f"学习率更改为{lr}")
file.flush() # 确保数据被写入磁盘
for epoch in range(num_epochs):
running_loss = 0.0 # 训练误差
Print_two(time.time())
for i, [inputs, labels] in enumerate(train_dataloader):
inputs, labels = inputs.to(device), labels.to(device)
# 前向传播
outputs = densenet(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 打印log信息
running_loss += loss.item() # 1000个batch的误差和
if i % out_num == out_num - 1: # 每100个batch打印一次训练状态
Print_two(
f"第{epoch + 1:2d}/{num_epochs:2d}轮循环,{i + 1:4d}/{lentrain:4d}组,平均误差为:{running_loss / out_num:.4f}")
process.append(running_loss)
running_loss = 0.0 # 误差归零
# 模型保存==========================================
seat = f'./cnn_l_gs_{time.time()}_{lr}.pth'
Print_two(f"保存模型至{seat}======================================")
torch.save(densenet.state_dict(), seat)
Print_two("保存完毕")
print("Finished Training")
# 绘制训练过程
i = i + 1
plt.figure(i)
plt.plot(list(range(len(process))), process, 'g:', label='loss')
plt.legend(loc='lower right') # 显示上面的label
plt.xlabel('time') # x_label
plt.ylabel('loss') # y_label
plt.title('loss about time') # 标题
plt.show() # 显示=========
else:
def save_out(f, data, ):
data = np.array(data.data.to("cpu"))
for i in data:
for j in i:
f.write(str(j) + ";")
f.write("\n")
def save_l(f, data, ):
data = np.array(data.data.to("cpu"))
for i in data:
f.write(str(i) + "\n")
if wenjian:
file_train = open(f'test1_train.txt', 'w', encoding='utf-8')
file_test = open(f'test1_test.txt', 'w', encoding='utf-8')
# file_y_train = open(f'y_train.txt', 'w', encoding='utf-8')
# file_y_test = open(f'y_test.txt', 'w', encoding='utf-8')
# 模型测试==========================================
print("开始测试===================================================")
# 在训练集上测试====================================
correct = 0 # 预测正确图片数
total = 0 # 总图片数
for images, labels in train_dataloader:
images = images.to(device)
labels = labels.to(device)
outputs = densenet(images)
if wenjian:
save_out(file_train, outputs)
# save_l(file_y_train, labels)
# 返回得分最高的索引(一组 4 个)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
# for i in range(len(labels)):
# if abs(predicted[i] - int(labels[i])) < 3:
# correct += 1
print("训练集中的准确率为:%d %%" % (100 * correct / total))
# 在测试集上测试====================================
correct = 0 # 预测正确图片数
total = 0 # 总图片数
for images, labels in test_dataloader:
images = images.to(device)
labels = labels.to(device)
outputs = densenet(images)
if wenjian:
for out_i in range(len(outputs)):
save_out(file_test, outputs)
# save_l(file_y_test, labels)
# 返回得分最高的索引(一组 4 个)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
# for i in range(len(labels)):
# if abs(predicted[i] - int(labels[i])) < 3:
# correct += 1
print("测试集中的准确率为:%d %%" % (100 * correct / total))
if wenjian:
file_train.close()
file_test.close()
# file_y_train.close()
# file_y_test.close()
# 输出在测试集上一组(4个)的数据和预测结果===================
dataiter = iter(test_dataloader) # 生成测试集的可迭代对象
images, labels = dataiter.next() # 得到一组数据
# 绘图====================
i = i + 1
plt.figure(i)
npimg = (tv.utils.make_grid(images / 2 + 0.5)).numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
print("实际标签:", " ".join("%08s" % labels))
show = transforms.ToPILImage() # 把tensor转为image
images = images.to(device)
labels = labels.to(device)
outputs = densenet(images) # 计算图片在每个类别上的分数
# 返回得分最高的索引
_, predicted = torch.max(outputs.data, 1) # 第一个数是具体值,不需要
# 一组 4 张图,所以找每行的最大值
print("预测结果:", " ".join("%08s" % predicted))
plt.show() # 显示=========
这里放一下训练好模型的压缩包。这段时间我考虑把东西扔到github上,有时间在搞吧。在测试集上准确率98,但数据集种亚洲面孔不多,而且没化妆。所以还是建议用自己的数据集训练一下。
图形界面
总体长这样:
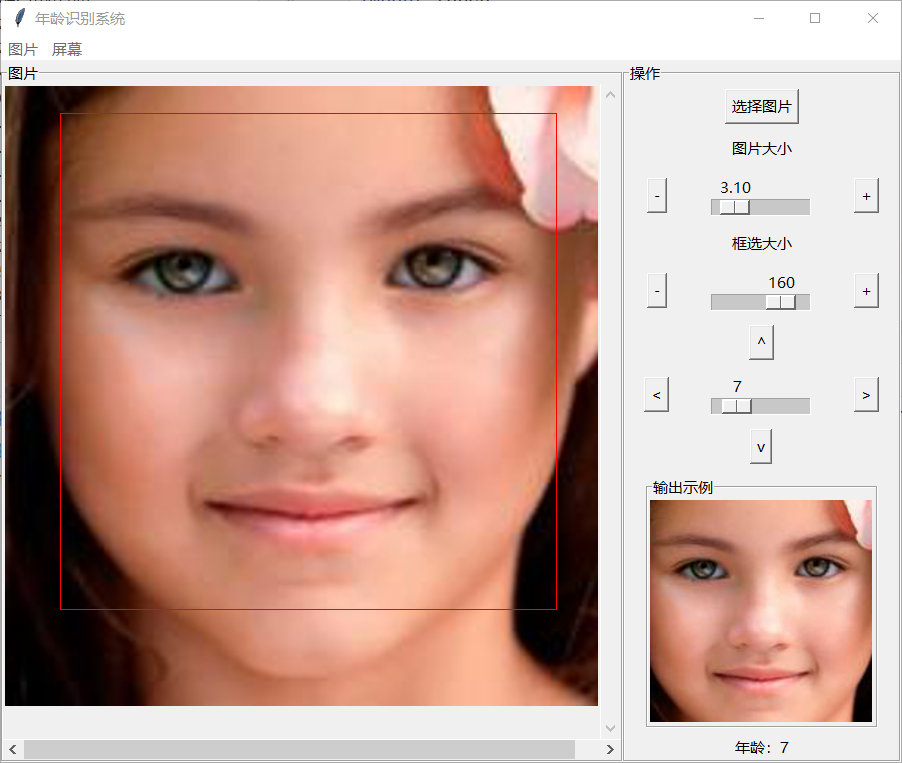
图片功能点右边选择图片按钮,选完之后左键在现实的图片上框选需要的范围,右边有点按钮能微调选中的范围。


屏幕功能会最小化之前的窗口并创建一个新窗口,点一下中间空白的地方就可以开始识别了,这时窗口中心会变透明,是真的透明,能穿过他点后面的物体。可以改变大小,但会自动调整为正方形。右键上面的白色部分可以取消透明,变为橙色。这种透明有个问题,不正常的缩放会导致无法选中上面的标题栏。所以我建议你只使用右下角缩放。其他几种缩放我设置的不允许。也好解决,就是删除默认标题栏,自己写一个。即使使用CPU也能0.2秒内完成识别。在下面是GUI代码:
import time
import tkinter as tk # gui用
import tkinter.messagebox # 弹出来的对话框
import torch
import torchvision.models as models
import torchvision.transforms as transforms
import tkinter.filedialog # 文件相关窗口
from torch import nn
from threading import Thread # 进程
import numpy as np
from PIL import Image, ImageTk
from mss import mss
class MainWindow(tk.Tk):
def __init__(self):
super().__init__()
self.default_path = [] # 默认模型位置,型配置位置和文件保存位置
self.title("年龄识别系统") # 给主窗口起一个名字
self.geometry("900x700+200+100") # 大小
self.config(menu=self.Generate_Menu()) # 生成菜单栏,窗口与菜单关联
self.now_num = -1 # 当前选择的功能
# 图片========================================================
self.image_ui = {}
self.image_ui["图片框架"] = tk.LabelFrame(self, text="图片") # 图片显示
self.image_ui["滚动条x"] = tk.Scrollbar(self.image_ui["图片框架"], orient=tk.HORIZONTAL) # 滚动条x
self.image_ui["滚动条y"] = tk.Scrollbar(self.image_ui["图片框架"], orient=tk.VERTICAL) # 滚动条y
self.image_ui["画布"] = tk.Canvas(self.image_ui["图片框架"],
xscrollcommand=self.image_ui["滚动条x"].set,
yscrollcommand=self.image_ui["滚动条y"].set)
self.image_ui["图片路径"] = ""
self.image_ui["当前图片"] = Image.new('RGB', (0, 0))
self.image_ui["显示的图片"] = ImageTk.PhotoImage(self.image_ui["当前图片"])
self.image_ui["图片索引"] = self.image_ui["画布"].create_image(0, 0, anchor="nw",
image=self.image_ui["显示的图片"]) # 先不放图片
self.image_ui["画布"].configure(scrollregion=(0, 0, 0, 0)) # 更新Canvas的滚动区域
self.image_ui["画布"].update() # 更新canvas以显示新图片
self.image_ui["滚动条x"].pack(side=tk.BOTTOM, fill=tk.X) # 靠下,拉满x
self.image_ui["滚动条x"].config(command=self.image_ui["画布"].xview)
self.image_ui["滚动条y"].pack(side=tk.RIGHT, fill=tk.Y) # 靠右,拉满y
self.image_ui["滚动条y"].config(command=self.image_ui["画布"].yview)
self.image_ui["画布"].pack(fill=tk.BOTH, expand=True) # 中间,且不扩充父框架大小
self.image_ui["图片框架"].grid(row=0, column=0, sticky="wesn")
self.image_ui["画布"].bind('<Button-1>', self.Image_Click) # 绑定鼠标左键点击事件
self.image_ui["画布"].bind('<B1-Motion>', self.Image_Loosen) # 绑定鼠标左键点击移动事件
self.image_ui["画布"].bind('<ButtonRelease-1>', self.Image_Movex) # 绑定鼠标左键点击释放事件
self.image_ui["操作框架"] = tk.LabelFrame(self, text="操作") # 操作
self.image_ui["选择图片按钮"] = tk.Button(self.image_ui["操作框架"], text="选择图片", command=self.Select_Image)
self.image_ui["图片大小标签"] = tk.Label(self.image_ui["操作框架"], text="图片大小")
self.image_ui["图片大小滑条"] = tk.Scale(self.image_ui["操作框架"], from_=0.01, to=1, resolution=0.05,
orient='horizontal', )
self.image_ui["图片大小滑条"].bind('<ButtonRelease-1>', self.Scale_Image) # 松开才执行
def Image_Change_Scale(c_num):
self.image_ui["图片大小滑条"].set(self.image_ui["图片大小滑条"].get() + c_num)
self.Scale_Image()
self.image_ui["图片大小+"] = tk.Button(self.image_ui["操作框架"], text="+",
command=lambda c_num=0.05: Image_Change_Scale(c_num))
self.image_ui["图片大小-"] = tk.Button(self.image_ui["操作框架"], text="-",
command=lambda c_num=-0.05: Image_Change_Scale(c_num))
self.image_ui["显示的框选范围"] = [0, 0, 0]
self.image_ui["真实的框选范围"] = [0, 0, 0]
self.image_ui["框选大小标签"] = tk.Label(self.image_ui["操作框架"], text="框选大小")
self.image_ui["框选大小滑条"] = tk.Scale(self.image_ui["操作框架"], from_=0, to=0, resolution=1,
orient='horizontal', ) # 最大图片
def Image_Change_Selection_Box(event):
if self.image_ui["框选大小滑条"].get() == self.image_ui["真实的框选范围"][2]:
return
else:
self.image_ui["真实的框选范围"][2] = self.image_ui["框选大小滑条"].get()
self.Show_Selection_Box()
self.Update_Display()
def Image_Change_Box_small(c_num=None, direction=None):
if not c_num == None:
self.image_ui["框选大小滑条"].set(self.image_ui["框选大小滑条"].get() + c_num)
Image_Change_Selection_Box(None)
elif not direction == None: # 8246,上下左右
num = self.image_ui["微调大小滑条"].get()
if direction == 8:
self.image_ui["真实的框选范围"][1] -= num
if direction == 2:
self.image_ui["真实的框选范围"][1] += num
if direction == 4:
self.image_ui["真实的框选范围"][0] -= num
if direction == 6:
self.image_ui["真实的框选范围"][0] += num
self.Show_Selection_Box()
self.Update_Display()
self.image_ui["微调大小滑条"] = tk.Scale(self.image_ui["操作框架"], from_=1, to=100, resolution=1,
orient='horizontal', )
self.image_ui["框选大小滑条"].bind('<ButtonRelease-1>', Image_Change_Selection_Box) # 松开才执行
self.image_ui["框选大小+"] = tk.Button(self.image_ui["操作框架"], text="+",
command=lambda c_num=1: Image_Change_Box_small(c_num=c_num))
self.image_ui["框选大小-"] = tk.Button(self.image_ui["操作框架"], text="-",
command=lambda c_num=-1: Image_Change_Box_small(c_num=c_num))
self.image_ui["微调上"] = tk.Button(self.image_ui["操作框架"], text="^",
command=lambda: Image_Change_Box_small(direction=8))
self.image_ui["微调下"] = tk.Button(self.image_ui["操作框架"], text="v",
command=lambda: Image_Change_Box_small(direction=2))
self.image_ui["微调左"] = tk.Button(self.image_ui["操作框架"], text="<",
command=lambda: Image_Change_Box_small(direction=4))
self.image_ui["微调右"] = tk.Button(self.image_ui["操作框架"], text=">",
command=lambda: Image_Change_Box_small(direction=6))
self.image_ui["示例图片框架"] = tk.LabelFrame(self.image_ui["操作框架"], text="输出示例")
self.image_ui["示例图片画布"] = tk.Canvas(self.image_ui["示例图片框架"], width=224, height=224)
self.image_ui["示例图片"] = Image.new('RGB', (224, 224))
self.image_ui["显示的示例图片"] = ImageTk.PhotoImage(self.image_ui["当前图片"])
self.image_ui["示例图片索引"] = self.image_ui["示例图片画布"].create_image(0, 0, anchor="nw",
image=self.image_ui["显示的示例图片"])
self.image_ui["输出结果关联变量"] = tk.StringVar()
self.image_ui["输出结果关联变量"].set("年龄:空")
self.image_ui["输出结果"] = tk.Label(self.image_ui["操作框架"], textvariable=self.image_ui["输出结果关联变量"])
self.image_ui["修改标记"] = False
self.image_ui["选择图片按钮"].grid(row=0, column=0, columnspan=3)
self.image_ui["图片大小标签"].grid(row=1, column=0, columnspan=3)
self.image_ui["图片大小滑条"].grid(row=2, column=1, )
self.image_ui["图片大小+"].grid(row=2, column=2, )
self.image_ui["图片大小-"].grid(row=2, column=0, )
self.image_ui["框选大小标签"].grid(row=3, column=0, columnspan=3)
self.image_ui["框选大小滑条"].grid(row=4, column=1, )
self.image_ui["框选大小+"].grid(row=4, column=2, )
self.image_ui["框选大小-"].grid(row=4, column=0, )
self.image_ui["微调上"].grid(row=5, column=1, )
self.image_ui["微调下"].grid(row=7, column=1, )
self.image_ui["微调左"].grid(row=6, column=0, )
self.image_ui["微调右"].grid(row=6, column=2, )
self.image_ui["微调大小滑条"].grid(row=6, column=1, )
self.image_ui["示例图片框架"].grid(row=8, column=0, columnspan=3)
self.image_ui["示例图片画布"].grid(row=0, column=0) # 中间
self.image_ui["输出结果"].grid(row=9, column=0, columnspan=3)
self.image_ui["操作框架"].grid(row=0, column=1, sticky="wesn")
self.image_ui["示例图片框架"].columnconfigure(0, weight=1)
self.image_ui["示例图片框架"].rowconfigure(0, weight=1)
for i in range(3):
self.image_ui["操作框架"].columnconfigure(i, weight=1)
for i in range(9):
self.image_ui["操作框架"].rowconfigure(i, weight=1)
# self.image_ui["操作框架"].rowconfigure(8, weight=3)
self.rowconfigure(0, weight=1)
self.columnconfigure(0, weight=3)
self.columnconfigure(1, weight=1)
# 加载DenseNet121模型
self.model = models.densenet121()
# 调整模型的最后一层以适应70个类别
num_ftrs = self.model.classifier.in_features
self.model.classifier = nn.Sequential(
nn.Linear(num_ftrs, 70),
nn.LogSoftmax(dim=1)
)
self.model.load_state_dict(torch.load("./cnn/cnn_l_gs_1713783963.7627246_2e-05.pth")) # 加载权重
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# self.device = torch.device("cpu")
self.model = self.model.to(self.device)
self.model.eval() # 开启评估模式
self.transform = transforms.Compose([
transforms.Resize((224, 224)), # DenseNet需要224x224的图片
transforms.ToTensor(), # 将PIL图片或NumPy ndarray转换为tensor,并归一化
transforms.Normalize(mean=[0.6377, 0.4879, 0.4189], # 归一化到[-1, 1]范围,使用ImageNet的均值和标准差
std=[0.2119, 0.1905, 0.1831]), ])
self.image_ui["识别进程"] = Thread(target=self.Recognition_Img)
self.image_ui["识别进程"].start()
self.s_w = None
# 创建菜单栏,选择功能,分为图片,屏幕,摄像头三种输入
# 不做摄像头了
def Generate_Menu(self):
def To_S_W():
self.s_w = ScreenRecognitionWindow(self)
menubar = tk.Menu(self) # 菜单栏
menubar.add_command(label='图片', )
menubar.add_command(label='屏幕', command=To_S_W)
# menubar.add_command(label='摄像头', )
return menubar
def Select_Image(self): # 选择图片按钮的回调
file_path = tk.filedialog.askopenfilename(filetypes=[("图片文件", '*.jpeg;*.jpg;*.png')], ) # 文件选择对话框
if file_path.strip() != '': # 是空的时候,往往没有选择,直接关闭窗口
try:
self.image_ui["图片路径"] = file_path
self.image_ui["当前图片"] = Image.open(file_path) # 读取图片
img_size_max = max(self.image_ui["当前图片"].size)
img_size_min = min(self.image_ui["当前图片"].size)
scale_factor = round((min(self.image_ui["图片框架"].winfo_width(), self.image_ui[
"图片框架"].winfo_height()) / img_size_max) / 0.05) * 0.05 # 初始缩放系数,让图片正正好显示
scale_factor_scope = [scale_factor, scale_factor * 6]
if scale_factor_scope[0] > 1: # 缩放比范围微调
scale_factor_scope[0] = 1
if scale_factor_scope[1] < 1:
scale_factor_scope[1] = 1
self.image_ui["图片大小滑条"].config(from_=scale_factor_scope[0], to=scale_factor_scope[1])
self.image_ui["图片大小滑条"].set(scale_factor) # 设置初始值
self.image_ui["框选大小滑条"].config(from_=1, to=img_size_min)
self.image_ui["微调大小滑条"].config(from_=1, to=img_size_min // 5)
self.image_ui["框选大小滑条"].set(0)
self.image_ui["显示的框选范围"] = [0, 0, 0]
self.image_ui["真实的框选范围"] = [0, 0, 0]
self.Scale_Image()
except:
tk.messagebox.showwarning(title='警告!', message='图片文件错误,无法读取图片文件')
def Scale_Image(self, event=None): # 根据缩放系数显示图片以及框
if self.image_ui["图片路径"] == "":
return
current_value = self.image_ui["图片大小滑条"].get()
width, height = self.image_ui["当前图片"].size
new_size = [int(width * current_value), int(height * current_value)]
self.image_ui["显示的图片"] = ImageTk.PhotoImage(self.image_ui["当前图片"].resize((new_size))) # 缩放图片大小并显示
self.image_ui["画布"].itemconfig(self.image_ui["图片索引"], image=self.image_ui["显示的图片"])
self.image_ui["画布"].configure(
scrollregion=(0, 0, self.image_ui["显示的图片"].width(), self.image_ui["显示的图片"].height())) # 更新Canvas的滚动区域
self.Show_Selection_Box() # 显示选择框
self.image_ui["画布"].update() # 更新canvas以显示新图片
def Show_Selection_Box(self): # 显示选择框
width, height = self.image_ui["当前图片"].size # 将真实框选范围定到图像内
change = False
if self.image_ui["真实的框选范围"][0] < 0:
self.image_ui["真实的框选范围"][0] = 0
change = True
if self.image_ui["真实的框选范围"][0] > width:
self.image_ui["真实的框选范围"][0] = width
change = True
if self.image_ui["真实的框选范围"][1] < 0:
self.image_ui["真实的框选范围"][1] = 0
change = True
if self.image_ui["真实的框选范围"][1] > height:
self.image_ui["真实的框选范围"][1] = height
change = True
w_max = self.image_ui["真实的框选范围"][0] + self.image_ui["真实的框选范围"][2]
if w_max >= width:
self.image_ui["真实的框选范围"][2] -= w_max - width + 1
change = True
h_max = self.image_ui["真实的框选范围"][1] + self.image_ui["真实的框选范围"][2]
if h_max >= height:
self.image_ui["真实的框选范围"][2] -= h_max - height + 1
change = True
current_value = self.image_ui["图片大小滑条"].get()
self.image_ui["画布"].delete("Select") # 删除之前的选择框
self.image_ui["显示的框选范围"] = [int(i * current_value) for i in self.image_ui["真实的框选范围"]]
self.image_ui["画布"].create_rectangle(self.image_ui["显示的框选范围"][0], self.image_ui["显示的框选范围"][1],
self.image_ui["显示的框选范围"][0] + self.image_ui["显示的框选范围"][2],
self.image_ui["显示的框选范围"][1] + self.image_ui["显示的框选范围"][2],
outline="red", fill=None, tag="Select") # 绘制选择框
if change:
self.Update_Display()
def Update_Display(self): # 更新显示的示例图片
self.image_ui["修改标记"] = True
self.image_ui["框选大小滑条"].set(self.image_ui["真实的框选范围"][2])
extent = [self.image_ui["真实的框选范围"][0], self.image_ui["真实的框选范围"][1], # 得到框选范围
self.image_ui["真实的框选范围"][0] + self.image_ui["真实的框选范围"][2],
self.image_ui["真实的框选范围"][1] + self.image_ui["真实的框选范围"][2]]
self.image_ui["示例图片"] = self.image_ui["当前图片"].crop(extent).resize((224, 224))
self.image_ui["显示的示例图片"] = ImageTk.PhotoImage(self.image_ui["示例图片"])
self.image_ui["示例图片画布"].itemconfig(self.image_ui["示例图片索引"], image=self.image_ui["显示的示例图片"])
def Image_Click(self, event): # 鼠标左键点击
self.image_ui["显示的框选范围"][0], self.image_ui["显示的框选范围"][1] = [event.x, event.y]
def Image_Loosen(self, event): # 鼠标左键移动
self.image_ui["画布"].delete("Select") # 删除之前的选择框
if abs(self.image_ui["显示的框选范围"][0] - event.x) > abs(self.image_ui["显示的框选范围"][1] - event.y):
t = abs(self.image_ui["显示的框选范围"][0] - event.x)
else:
t = abs(self.image_ui["显示的框选范围"][1] - event.y)
if self.image_ui["显示的框选范围"][0] < event.x:
x = self.image_ui["显示的框选范围"][0]
else:
x = self.image_ui["显示的框选范围"][0] - t
if self.image_ui["显示的框选范围"][1] < event.y:
y = self.image_ui["显示的框选范围"][1]
else:
y = self.image_ui["显示的框选范围"][1] - t
self.image_ui["画布"].create_rectangle(x, y, x + t, y + t,
outline="red", fill=None, tag="Select") # 绘制选择框
def Image_Movex(self, event): # 鼠标左键释放
if abs(self.image_ui["显示的框选范围"][0] - event.x) > abs(self.image_ui["显示的框选范围"][1] - event.y):
t = abs(self.image_ui["显示的框选范围"][0] - event.x)
else:
t = abs(self.image_ui["显示的框选范围"][1] - event.y)
if self.image_ui["显示的框选范围"][0] < event.x:
x = self.image_ui["显示的框选范围"][0]
else:
x = self.image_ui["显示的框选范围"][0] - t
if self.image_ui["显示的框选范围"][1] < event.y:
y = self.image_ui["显示的框选范围"][1]
else:
y = self.image_ui["显示的框选范围"][1] - t
self.image_ui["显示的框选范围"] = [x, y, t, ]
current_value = self.image_ui["图片大小滑条"].get()
self.image_ui["真实的框选范围"] = [int(i / current_value) for i in self.image_ui["显示的框选范围"]]
self.Show_Selection_Box() # 重新画框
self.Update_Display() # 显示示例图片
def Recognition_Img(self): # 识别示例图片并输出年龄更改标签关联变量,
# 修改标记为Ture才会进行识别
try:
while True:
if not self.winfo_exists(): # 窗口是否关闭
break
if self.image_ui["修改标记"]:
img = self.transform(self.image_ui["示例图片"]).unsqueeze(0).to(self.device)
outputs = self.model(img)
_, predicted = torch.max(outputs.data, 1)
self.image_ui["输出结果关联变量"].set(f'年龄:{int(predicted)}')
self.image_ui["修改标记"] = False
else:
time.sleep(0.05)
except:
print("已结束")
return
class ScreenRecognitionWindow(tk.Toplevel): # 屏幕识别窗口
def __init__(self, master, ):
super().__init__(master) # 父类调用,
self.master = master
self.grab_set() # 独占焦点
self.title("") # 给窗口起一个名字
self.master.iconify() # 父窗口最小化
# self.master.deiconify()
self.geometry("224x224+100+100")
self.wm_attributes("-topmost", True) # 设置窗口始终置于顶部
self.wm_attributes('-transparentcolor', "orange") # 设置透明色
self.attributes("-toolwindow", 2) # 去掉窗口最大化最小化按钮,只保留关闭
self.monitor = {'top': 100, 'left': 100, 'width': 224, 'height': 224}
self.canvas = tk.Canvas(self, width=224, height=224)
self.start_up = False # 正在运行
self.bind('<Button-1>', self.Button_Click) # 绑定鼠标左键点击事件
self.bind("<Configure>", self.On_Resize) # 绑定窗口大小改变事件
self.bind('<Button-3>', self.Button_Click_3) # 绑定鼠标右键点击事件
self.transparentcolor = True
self.age_text = self.canvas.create_text(0, 0, text=self.master.image_ui["输出结果关联变量"].get(), anchor="nw",
font=("Arial", 10), fill="black")
self.canvas.grid(row=0, column=0, sticky="wesn")
self.rowconfigure(0, weight=1)
self.columnconfigure(0, weight=1)
def On_Resize(self, event): # 缩放窗口保持正方形
# 计算新的宽度和高度,保持正方形
new_width = event.width
new_height = event.height
new_x = self.winfo_x()
new_y = self.winfo_y()
if new_x < 0:
new_x = 0
if new_y < 0:
new_y = 0
proportion = max(new_width, new_height)
if proportion > min(self.winfo_screenwidth(), self.winfo_screenheight()): # 太大了,踢回去
self.geometry(
f"{self.monitor['width']}x{self.monitor['height']}+{self.monitor['left']}+{self.monitor['top']}")
return
if new_width != self.monitor['width'] or new_height != self.monitor['height']: # 缩放了
if new_y > self.monitor['top'] or new_x > self.monitor['left']: # 左上角点向右下去了
self.geometry(
f"{self.monitor['width']}x{self.monitor['height']}+{self.monitor['left']}+{self.monitor['top']}")
return # 阻止变化,恢复原样
# 缩放而且左上角点向左上角去了,或者不变,保持正方形即可
self.geometry(f"{proportion}x{proportion}+{new_x}+{new_y}")
self.monitor = {'top': new_y, 'left': new_x, 'width': proportion, 'height': proportion}
self.Button_Click()
return
else: # 没有缩放,只是移动 赋值走人
self.monitor = {'top': new_y, 'left': new_x, 'width': proportion, 'height': proportion}
return # 只是移动位置
def Button_Click(self, event=None): # 鼠标左键点击执行
self.wm_state(tk.NORMAL)
self.canvas.delete("Select") # 删除之前的透明框
self.canvas.create_rectangle(-20, -100, self.monitor["width"] + 40, self.monitor['height'] + 200, fill="white",
tag="Select")
self.canvas.create_rectangle(3, 20, self.monitor["width"] - 6, self.monitor['height'] - 4, fill="orange",
outline="blue", tag="Select")
# 绘制矩形,因为现在是透明色,所以绘制了透明矩形
if self.start_up:
return
else:
self.start_up = True
self.Handle()
def Button_Click_3(self, event=None): # 右键点击,取消橙色透明之后重新透明
if self.transparentcolor:
self.wm_attributes('-transparentcolor', "red") # 设置透明色
self.transparentcolor = False
else:
self.wm_attributes('-transparentcolor', "orange") # 设置透明色
self.transparentcolor = True
def Handle(self): # 开始处理
sct = mss() # 创建一个屏幕捕获对象
while True:
monitor = {'top': self.monitor["top"]+60, 'left': self.monitor["left"]+10,
'width': self.monitor["width"]-10,'height': self.monitor["height"]-30}
screenshot = np.uint8(sct.grab(monitor))[:, :, :3][:, :, ::-1]
self.master.image_ui["示例图片"] = Image.fromarray(screenshot, "RGB").resize((224, 224)) # 捕获屏幕截图
self.master.image_ui["修改标记"] = True
self.master.image_ui["显示的示例图片"] = ImageTk.PhotoImage(self.master.image_ui["示例图片"])
self.master.image_ui["示例图片画布"].itemconfig(self.master.image_ui["示例图片索引"],
image=self.master.image_ui["显示的示例图片"]) # 这里不是很必要
# 那边开着进程呢,修改标记改了之后一会就会修改年龄
self.canvas.delete(self.age_text) # 删除之前的文字
self.age_text = self.canvas.create_text(2, 2, text=self.master.image_ui["输出结果关联变量"].get(), anchor="nw",
font=("Arial", 10), fill="black")
self.canvas.update() # 更新canvas以显示新图片
if not self.winfo_exists(): # 窗口是否关闭
self.start_up = False
break
if __name__ == "__main__":
main_window = MainWindow() # 创建主窗口
main_window.mainloop() # 开启主循环,让窗口处于显示状态