前面讲了深度学习&PyTorch 之 DNN-二分类,本节讲一下DNN多分类相关的内容,这里分三步进行演示
结构化数据
我们还是以iris数据集为例,因为这个与前面的流程完全一样,只有在模型定义时有些区别
-
损失函数不一样
二分类时用的损失函数是:loss_fn = nn.BCELoss()
在多分类时需要使用: loss_fn = torch.nn.CrossEntropyLoss() -
输出类别不一样
二分类输出时,需要使用sigmoid函数进行激活,x = torch.sigmoid(self.hidden3(x))
多分类不需要使用激活函数,只需要输出全连接后的数据就可以
所以模型定义如下
class Model(nn.Module):
def __init__(self):
super().__init__()
self.linear_1 = nn.Linear(4, 120)
self.linear_2 = nn.Linear(120, 84)
self.linear_3 = nn.Linear(84, 4)
def forward(self, x):
x = x.view(x.size(0), -1)
x = torch.relu(self.linear_1(x))
x = torch.relu(self.linear_2(x))
logits = self.linear_3(x)
return logits # 未激活的输出,叫做logits
训练与之前一样,就不写了
重点讲非结构化数据,图片
图片多分类 - Minst
原理部分
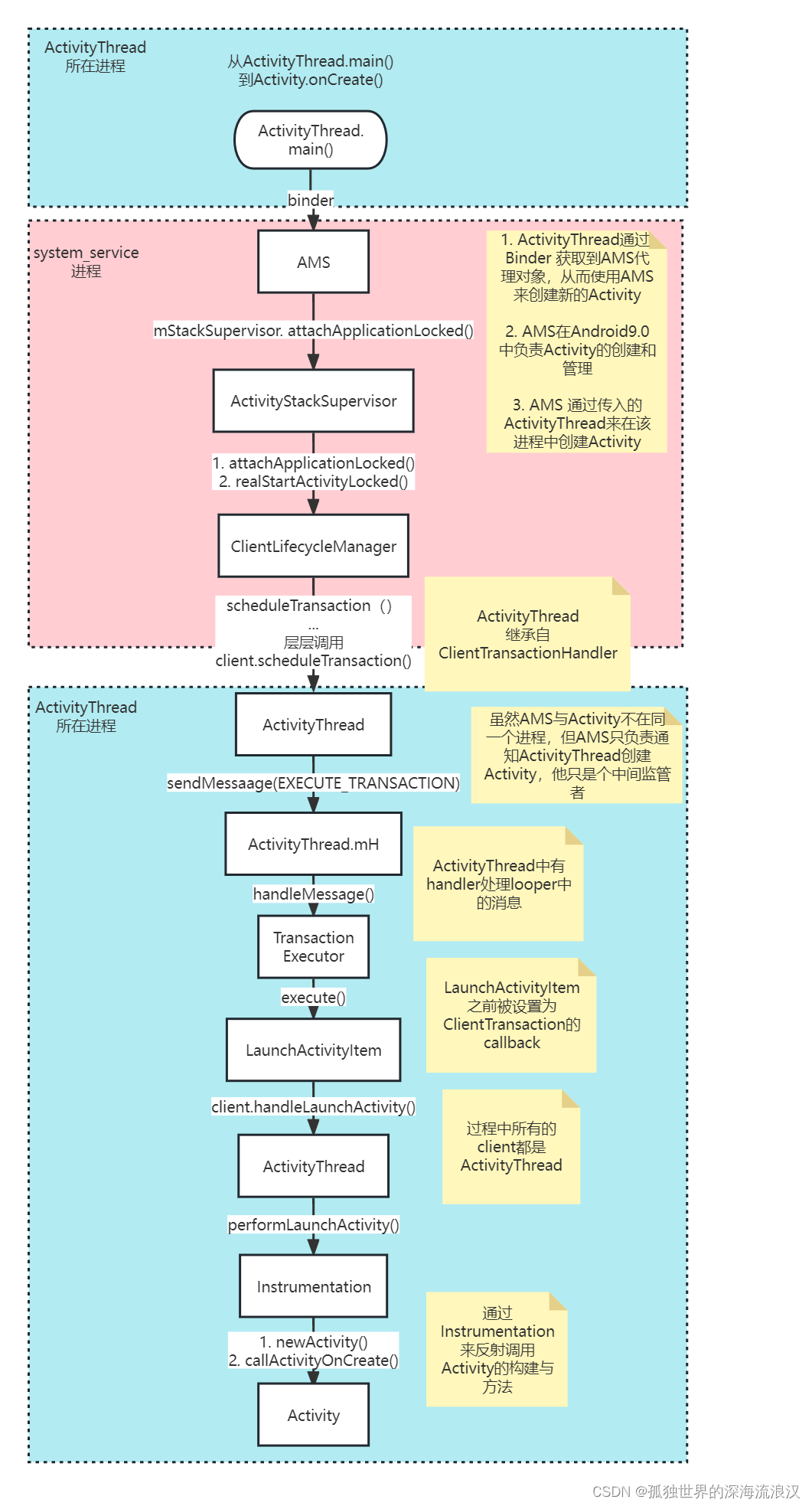
MNIST数据集是由0〜9手写数字图片和数字标签所组成的,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片,如下

我们其实就是识别图片中的数字,没一个数字图片其实是有一个一个像素组成的,
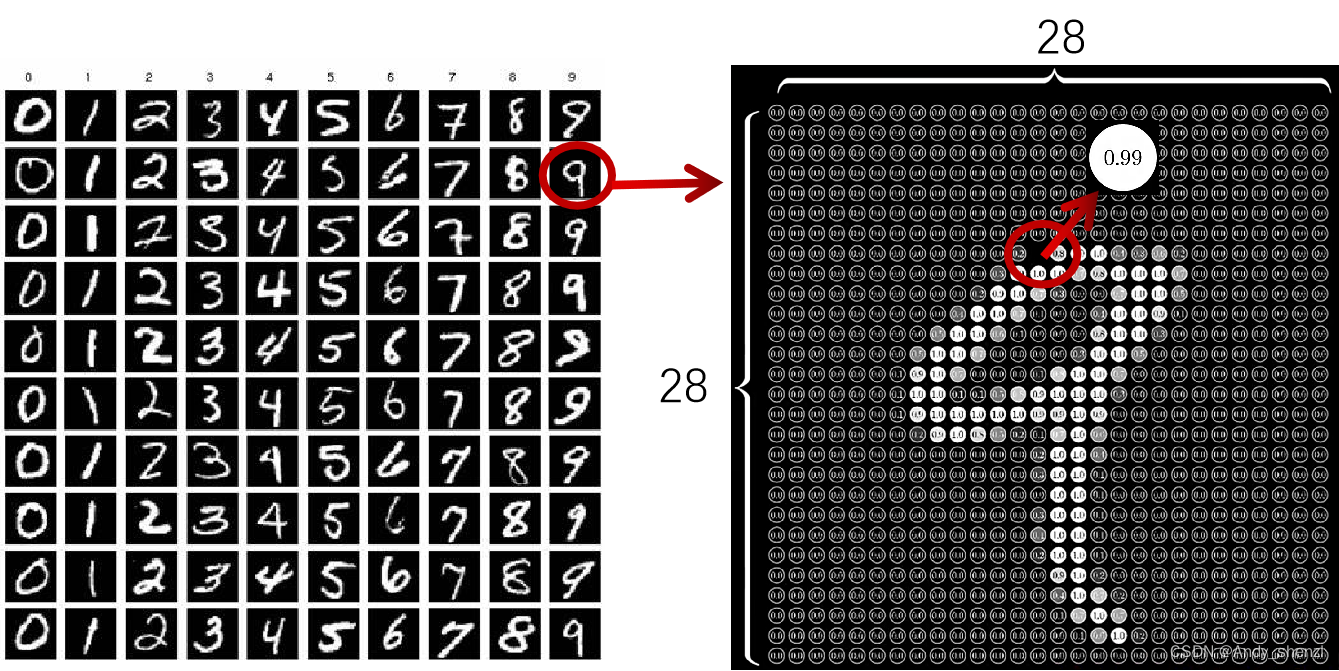
神经元装着数字代表对应像素的灰度值,0代表纯黑色,1代表纯白像素
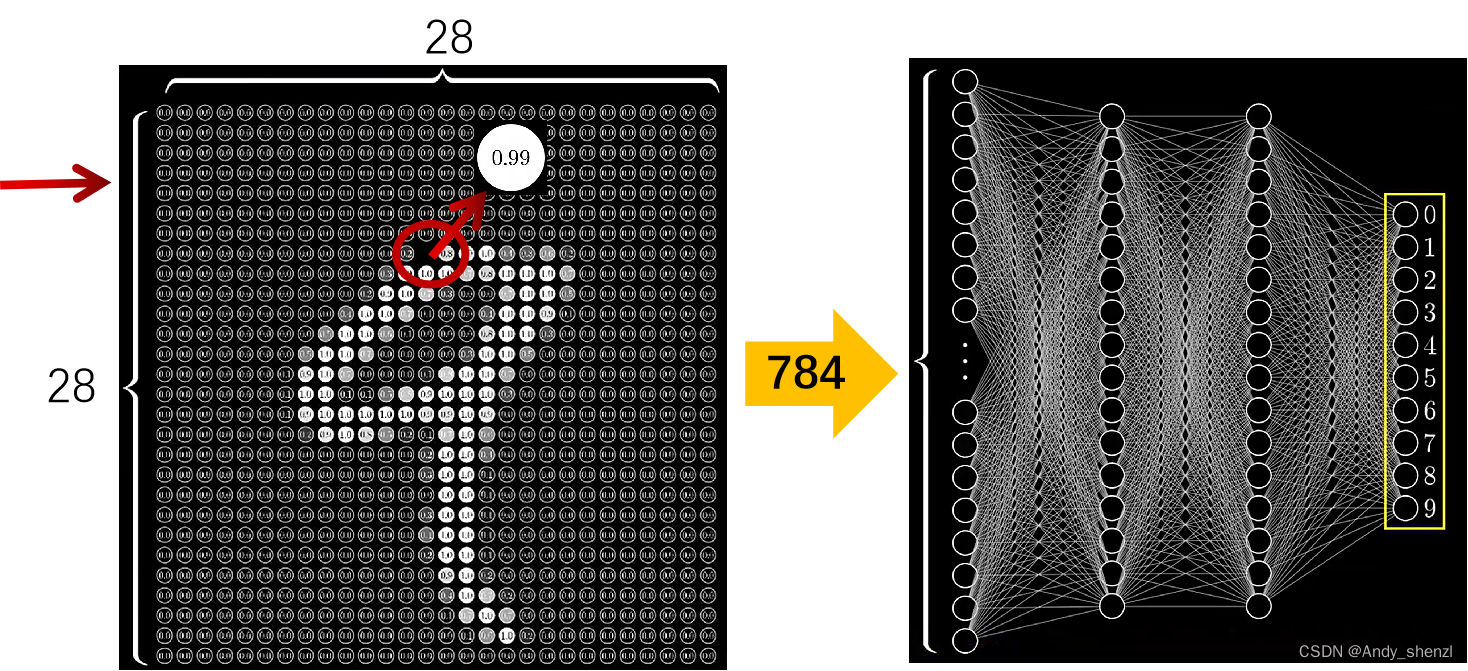
我们要想训练这些像素点,需要将像素进行重组,就是将这些像素重新排列,将每一行的像素首尾相连,最终连接成一个长串,因为一行有28个像素点,一共28行,即最终有28*28个特征
将这些转换好的数据带入到模型中进行训练。
代码部分
1.数据准备
数据准备直接包含了数据导入+数据拆分+ToTensor
- 导入有两种方式,一种是使用下载到本地的数据集,另一种是使用
torchvision直接在线下载,速度还是比较快的 - 训练和测试数据分别导入
- 在导入时,可以设置transform=ToTensor(),进行转换
train_ds_m = torchvision.datasets.MNIST('data',
train=True,
transform=ToTensor(),
download=True)
test_ds_m = torchvision.datasets.MNIST('data',
train=False,
transform=ToTensor(),
download=True)
2. 数据重构
这里与之前一直,不多说
train_dl_m = torch.utils.data.DataLoader(train_ds_m,
batch_size=64,
shuffle=True)
test_dl_m = torch.utils.data.DataLoader(test_ds_m,
batch_size=64)
3. 数据查看
因为是图片数据,我们加一步数据查看,看一下导入的数据格式,加深我们的理解
idx_to_class = dict((v, k) for k, v in train_ds_m.class_to_idx.items())
idx_to_class
#label格式
{0: '0 - zero',
1: '1 - one',
2: '2 - two',
3: '3 - three',
4: '4 - four',
5: '5 - five',
6: '6 - six',
7: '7 - seven',
8: '8 - eight',
9: '9 - nine'}
dataloader本质上是一个可迭代对象,可以使用iter()进行访问,采用iter(dataloader)返回的是一个迭代器,然后可以使用next()访问。
imgs, labels = next(iter(train_dl_m))
imgs.shape
#torch.Size([64, 1, 28, 28])
我们可以看到,ims的数据格式是64,1,28,27
- 64是我们定义的batch_size = 64
- 1是指通道数,这里是黑白图片,所以通道数是1;如果是彩色图片通道数应该是3,即RGB三个通道
- 28*28,就是图片的大小,我们前面原理部分说过了
图片展示一下
plt.figure(figsize=(16, 6))
for i,(img, label) in enumerate(zip(imgs[:16],labels[:16])):
img = (img.permute(1,2,0).numpy() + 1)/2
plt.subplot(2, 8, i+1)
plt.title(idx_to_class.get(label.item()))
plt.imshow(img)
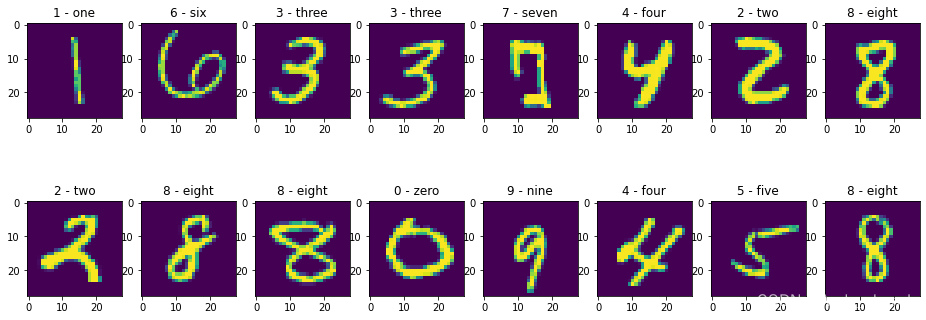
4. 定义模型
class Model(nn.Module):
def __init__(self):
super().__init__()
self.linear_1 = nn.Linear(28*28, 120)
self.linear_2 = nn.Linear(120, 84)
self.linear_3 = nn.Linear(84, 10)
def forward(self, x):
x = x.view(x.size(0), -1)
x = torch.relu(self.linear_1(x))
x = torch.relu(self.linear_2(x))
logits = self.linear_3(x)
return logits # 未激活的输出,叫做logits
这个跟之前一致,只是需要注意两点
- x.view(x.size(0), -1),将数据拉平,就是将图片连城一个长串,28*28的格式
- 最终输出的种类需要与我们预测的label类别数一致
model = Model()
loss_fn = torch.nn.CrossEntropyLoss()
opt = torch.optim.SGD(model.parameters(), lr=0.001)
model
Model(
(linear_1): Linear(in_features=784, out_features=120, bias=True)
(linear_2): Linear(in_features=120, out_features=84, bias=True)
(linear_3): Linear(in_features=84, out_features=10, bias=True)
)
5. 训练及查看
epochs = 100
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
epoch_acc, epoch_loss = train(train_dl_m, model, loss_fn, opt)
epoch_test_acc, epoch_test_loss = test(test_dl_m, model, loss_fn)
if epoch%10==0:
train_acc.append(epoch_acc)
train_loss.append(epoch_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
template = ("epoch:{:2d}, 训练损失:{:.5f}, 训练准确率:{:.1f},验证损失:{:.5f}, 验证准确率:{:.1f}")
print(template.format(epoch, epoch_loss, epoch_acc*100, epoch_test_loss, epoch_test_acc*100))
print('Done')
训练函数和测试函数与之前一致
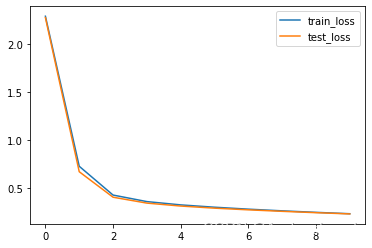
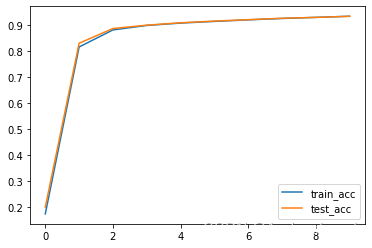
epoch: 0, 训练损失:2.28837, 训练准确率:17.5,验证损失:2.27378, 验证准确率:20.1
epoch:10, 训练损失:0.72655, 训练准确率:81.6,验证损失:0.66988, 验证准确率:83.0
epoch:20, 训练损失:0.42698, 训练准确率:88.2,验证损失:0.40460, 验证准确率:88.7
epoch:30, 训练损失:0.35895, 训练准确率:89.9,验证损失:0.34320, 验证准确率:90.0
epoch:40, 训练损失:0.32467, 训练准确率:90.8,验证损失:0.31260, 验证准确率:90.9
epoch:50, 训练损失:0.30045, 训练准确率:91.4,验证损失:0.29069, 验证准确率:91.5
epoch:60, 训练损失:0.28021, 训练准确率:92.0,验证损失:0.27321, 验证准确率:92.1
epoch:70, 训练损失:0.26272, 训练准确率:92.6,验证损失:0.25764, 验证准确率:92.6
epoch:80, 训练损失:0.24705, 训练准确率:93.0,验证损失:0.24356, 验证准确率:93.0
epoch:90, 训练损失:0.23274, 训练准确率:93.4,验证损失:0.23069, 验证准确率:93.4
Done
查看损失值和准确率的变化
import matplotlib.pyplot as plt
plt.plot(range(len(train_loss)), train_loss, label='train_loss')
plt.plot(range(len(test_loss)), test_loss, label='test_loss')
plt.legend()
plt.plot(range(len(train_acc)), train_acc, label='train_acc')
plt.plot(range(len(test_acc)), test_acc, label='test_acc')
plt.legend()