原理
在 Flink 中,数据源(Source)是其中一个核心组件,负责从各种来源读取数据供 Flink 程序处理。
- Flink 的数据源类型丰富,涵盖了从简单测试到生产环境使用的各种场景。
- Kafka、Socket、文件和集合是 Flink 中最常见的几种数据源类型。
- 用户还可以通过实现自定义的 SourceFunction 接口来创建符合自己需求的数据源。
- Flink 的连接器生态也在不断发展壮大,为用户提供了更多的数据源选择。
核心组件
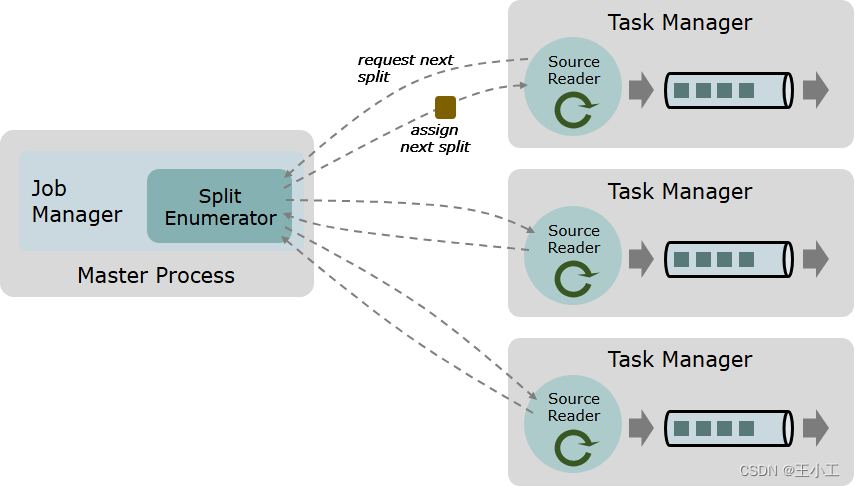
一个数据 source 包括三个核心组件:分片(Splits)、分片枚举器(SplitEnumerator) 以及 源阅读器(SourceReader)。
- 分片(Split)
- 分片是对一部分source数据的包装,如一个文件或者日志分区。
- 分片是source进行任务分配和数据并行读取的基本粒度。
- 分片枚举器(SplitEnumerator)
- 分片枚举器负责生成分片,并将它们分配给SourceReader。
- 该组件在JobManager上以单并行度运行,负责对未分配的分片进行维护,并以均衡的方式将其分配给reader。
- 源阅读器(SourceReader)
- 源阅读器会请求分片并进行处理,例如读取分片所表示的文件或日志分区。
- SourceReader在TaskManagers上的SourceOperators并行运行,并产生并行的事件流/记录流。
Source 类作为API入口,将上述三个组件结合在了一起。
流处理和批处理的统一
Data Source API 以统一的方式对无界流数据和有界批数据进行处理。
事实上,这两种情况之间的区别是非常小的:在有界/批处理情况中,枚举器生成固定数量的分片,而且每个分片都必须是有限的。但在无界流的情况下,则无需遵从限制,也就是分片大小可以不是有限的,或者枚举器将不断生成新的分片。
数据源构建
Flink中的数据源(Data Source)是Flink作业的起点,它可以从各种数据来源获取数据,例如文件系统、消息队列、数据库等。数据源可以是内置的(如基于集合、文件、Socket等),也可以是自定义的,或者是通过第三方连接器(如Kafka、RabbitMQ等)获取的。
数据读取与分配
- 数据读取
SourceReader负责读取分片中的数据。对于不同的数据源,Flink提供了不同的读取方式。例如,对于Kafka数据源,SourceReader使用KafkaConsumer读取所分配的分片(Topic Partition)。 - 数据分配
分片枚举器(SplitEnumerator)会生成分片并将它们分配给SourceReader。分配过程旨在确保数据的均衡读取,从而提高整体的处理效率。
Flink Data Source的原理主要涉及三个核心组件:分片、分片枚举器和源阅读器。数据源通过这三个组件的协作,实现了从各种数据源中读取数据,并将数据分配给相应的处理任务进行处理。通过这种方式,Flink可以高效地处理来自不同来源的大量实时数据。
API
Source API 是一个工厂模式的接口,用于创建以下组件。
- Split Enumerator
- Source Reader
- Split Serializer
- Enumerator Checkpoint Serializer
除此之外,Source 还提供了 Boundedness 的特性,从而使得 Flink 可以选择合适的模式来运行 Flink 任务。
Source 实现应该是可序列化的,因为 Source 实例会在运行时被序列化并上传到 Flink 集群。
SplitEnumerator
SplitEnumerator是数据源(Source)架构中的一个关键组件,它负责生成和管理数据分片(Splits),并将这些分片分配给SourceReader进行并行处理。以下是对SplitEnumerator的详细解释,基于参考文章的内容进行组织:
- 作用
- 生成分片:SplitEnumerator负责生成数据源的分片,这些分片是数据读取的基本单位。
- 分配分片:生成的分片会被SplitEnumerator分配给SourceReader,以便在TaskManagers上并行读取和处理数据。
- 负载均衡:SplitEnumerator负责维护等待中的分片的积压平衡,并以均衡的方式将它们分配给SourceReader,以确保数据处理的效率和公平性。
- 主要方法
参考文章提到SplitEnumerator包含以下方法:
- start():启动分片枚举器。
- handleSplitRequest(int subtaskId, @Nullable String requesterHostname):处理来自SourceReader的分片请求。
- addSplitsBack(List splits, int subtaskId):当SourceReader失败时,收回已经分配但尚未被确认的分片。
- addReader(int subtaskId):注册新的SourceReader。
- snapshotState(long checkpointId) throws Exception:在检查点(checkpoint)时保存分片枚举器的状态。
- close() throws IOException:关闭分片枚举器。
- SplitEnumerator与SourceReader的交互
- SplitEnumerator与SourceReader之间存在紧密的交互关系。SourceReader会向SplitEnumerator请求分片,并处理接收到的分片数据。
- 当SourceReader失败时,SplitEnumerator会调用addSplitsBack()方法收回已经分配但尚未被确认的分片,以便重新分配。
SourceReader
Flink的SourceReader是数据源架构中的一个关键组件,主要负责从SplitEnumerator获取分片(Split),并读取和处理这些分片中的数据。SourceReader是并行运行在Task Managers的source算子中,并且产出并行的时间流/记录流。
核心功能
- 请求分片:SourceReader向SplitEnumerator请求分片,这是数据处理的起点。
- 读取数据:一旦获得分片,SourceReader会读取分片中的数据,并准备进行后续的处理。
- 数据处理:SourceReader对读取的数据进行处理,将其转换为Flink内部可以处理的格式,如DataStream。
交互过程
- 与SplitEnumerator的交互:SourceReader通过SplitEnumerator获取分片,并在处理完一个分片后,根据需要向SplitEnumerator请求更多的分片。
- 与Task Managers的交互:SourceReader运行在Task Managers上,与Task Managers进行交互以获取计算资源和执行环境。
状态与轮询
SourceReader提供了一个拉动式(pull-based)处理接口,Flink任务会在循环中不断调用pollNext(ReaderOutput)轮询来自SourceReader的记录。pollNext(ReaderOutput)方法的返回值指示SourceReader的状态,可能包括以下几种:
- MORE_AVAILABLE:表示SourceReader有可用的记录。
- NOTHING_AVAILABLE:表示SourceReader现在没有可用的记录,但是将来可能会有记录可用。
- END_OF_INPUT:表示SourceReader已经处理完所有记录,到达数据的尾部。
优化
为了提高性能,SourceReader可以在一次pollNext()调用中返回多条记录。然而,除非有必要,SourceReader的实现应该避免在一次pollNext(ReaderOutput)的调用中发送多个记录,因为对SourceReader轮询的任务线程工作在一个事件循环(event-loop)中,且不能阻塞。
Flink的SourceReader是数据源架构中的核心组件,负责从SplitEnumerator获取分片,读取并处理这些分片中的数据。通过拉动式处理接口和与Task Managers的交互,SourceReader能够高效地处理大量实时数据,并产出并行的时间流/记录流供后续处理使用。
SplitReader API
核心的 SourceReader API 是完全异步的, 但实际上,大多数 Sources 都会使用阻塞的操作,例如客户端(如 KafkaConsumer)的 poll() 阻塞调用,或者分布式文件系统(HDFS, S3等)的阻塞I/O操作。为了使其与异步 Source API 兼容,这些阻塞(同步)操作需要在单独的线程中进行,并在之后将数据提交给 reader 的异步线程。
在 Flink 的数据源实现中,数据读取通常涉及以下组件和概念:
- SplitEnumerator:这是一个负责生成、管理和分配数据分片的组件。它运行在 JobManager 上,并与 SourceReader 交互,将分片分配给它们进行读取。
- SourceReader:这是实际执行数据读取的组件,它运行在 TaskManager 上。SourceReader 会从 SplitEnumerator 请求分片,并读取这些分片中的数据。
- SourceFunction:这是 Flink 数据源 API 的主要接口,用于定义如何从外部系统读取数据。在 SourceFunction 的实现中,开发者会处理与 SplitEnumerator 和 SourceReader 的交互逻辑。
Spl
itReader 是基于同步读取/轮询的 Source 的高级(high-level)API,例如 file source 和 Kafka source 的实现等。
核心是上面提到的 SourceReaderBase 类,其使用 SplitReader 并创建提取器(fetcher)线程来运行 SplitReader,该实现支持不同的线程处理模型。
SplitReader
SplitReader API 只有以下三个方法:
- 阻塞式的提取 fetch() 方法,返回值为 RecordsWithSplitIds 。
- 非阻塞式处理分片变动 handleSplitsChanges() 方法。
- 非阻塞式的唤醒 wakeUp() 方法,用于唤醒阻塞中的提取操作。
SplitReader 仅需要关注从外部系统读取记录,因此比 SourceReader 简单得多。 请查看这个类的 Java 文档以获得更多细节。
SourceReaderBase
常见的 SourceReader 实现方式如下:
- 有一个线程池以阻塞的方式从外部系统提取分片。
- 解决内部提取线程与其他方法调用(如 pollNext(ReaderOutput))之间的同步。
- 维护每个分片的水印(watermark)以保证水印对齐。
- 维护每个分片的状态以进行 Checkpoint。
为了减少开发新的 SourceReader 所需的工作,Flink 提供了 SourceReaderBase 类作为 SourceReader 的基本实现。 SourceReaderBase 已经实现了上述需求。要重新编写新的 SourceReader,只需要让 SourceReader 继承 SourceReaderBase,而后完善一些方法并实现 SplitReader 。
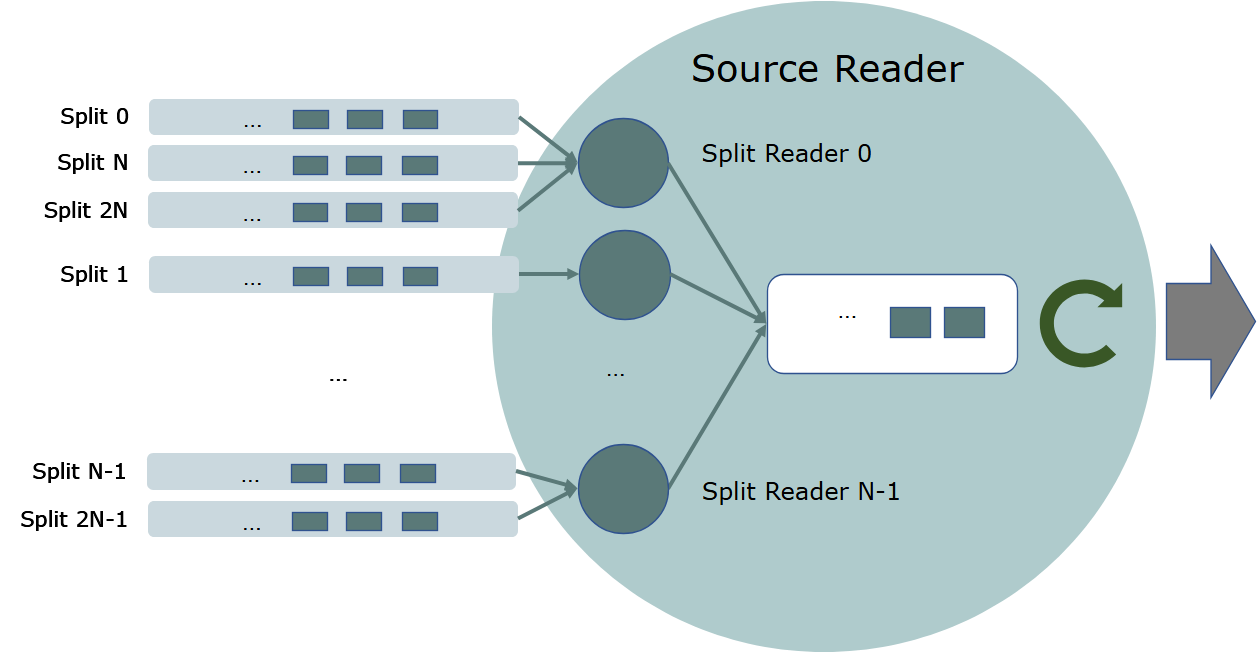
SplitFetcherManager
SourceReaderBase 支持几个开箱即用(out-of-the-box)的线程模型,取决于 SplitFetcherManager 的行为模式。 SplitFetcherManager 创建和维护一个分片提取器(SplitFetchers)池,同时每个分片提取器使用一个 SplitReader 进行提取。它还决定如何分配分片给分片提取器。
例如,如下所示,一个 SplitFetcherManager 可能有固定数量的线程,每个线程对分配给 SourceReader 的一些分片进行抓取。
示例代码(概念性)
- 定义 Split 类(代表数据的一个分片)
// 这不是 Flink API 的一部分,只是示例
class FileSplit {
private String filePath;
private long startOffset;
private long endOffset;
// 构造函数、getter 和 setter 等...
}
- 实现 SplitEnumerator(负责管理 Split 的分配)
// 这不是 Flink API 的一部分,只是示例
class FileSplitEnumerator implements SplitEnumerator<FileSplit, Void> {
// ... 省略其他实现细节 ...
@Override
public void start() {
// 启动时初始化分片,例如从文件系统中扫描文件
}
@Override
public CompletableFuture<SplitEnumeration<FileSplit>> getSplitsForSubtask(int subtaskId) {
// 根据 subtaskId 分配分片
// 这里只是一个简单的示例,实际中可能需要根据并行度等条件分配
List<FileSplit> splits = ...; // 从某处获取分片列表
return CompletableFuture.completedFuture(new ListSplitEnumeration<>(splits));
}
// ... 其他必要的方法实现 ...
}
- 实现 SourceReader(负责读取 Split)
// 这不是 Flink API 的一部分,只是示例
class FileSourceReader implements Runnable {
private final FileSplit split;
private final SourceOutput<String> sourceOutput; // 假设这是 Flink 提供的输出接口
public FileSourceReader(FileSplit split, SourceOutput<String> sourceOutput) {
this.split = split;
this.sourceOutput = sourceOutput;
}
@Override
public void run() {
try (BufferedReader reader = new BufferedReader(new FileReader(split.getFilePath()))) {
reader.skip(split.getStartOffset()); // 跳过之前的数据
String line;
while ((line = reader.readLine()) != null && reader.skipBytes(0) < split.getEndOffset()) {
// 将读取到的数据发送到 Flink 的 SourceOutput
sourceOutput.collect(line);
}
} catch (IOException e) {
// 处理异常
}
}
}
- 在 SourceFunction 中使用
// 这才是 Flink 的 API 部分
public class FileSourceFunction implements SourceFunction<String> {
private transient FileSplitEnumerator splitEnumerator;
private transient List<FileSourceReader> readers = new ArrayList<>();
@Override
public void run(SourceContext<String> ctx) throws Exception {
splitEnumerator = new FileSplitEnumerator();
splitEnumerator.start();
// 假设我们只有一个并行度,简单起见
SplitEnumeration<FileSplit> splits = splitEnumerator.getSplitsForSubtask(0).get();
for (FileSplit split : splits) {
FileSourceReader reader = new FileSourceReader(split, ctx::collect);
new Thread(reader).start(); // 注意:这里仅为示例,实际中应使用 Flink 的执行模型
readers.add(reader);
}
// 等待所有 reader 完成(这里只是概念性示例,实际中可能更复杂)
for (FileSourceReader reader : readers) {
// 假设有某种机制可以等待 reader 完成
}
// 通知 Flink 数据源已经完成
ctx.close();
}
// ... 其他必要的方法实现 ...
}
提示:上述代码只是为了解释如何在 Flink 数据源内部实现类似于 SplitReader 的逻辑。在真实的 Flink 数据源实现中,需要使用 Flink 提供的 SourceFunction API 和相关的上下文(如 SourceContext)来正确地与 Flink 运行时集成。
![[转载]同一台电脑同时使用GitHub和GitLab](https://img-blog.csdnimg.cn/direct/0f11f1c28f3e41f3865e0160d3704180.png)