用队列实现栈

思路
栈的特点:后进先出
队列的特点:先进先出
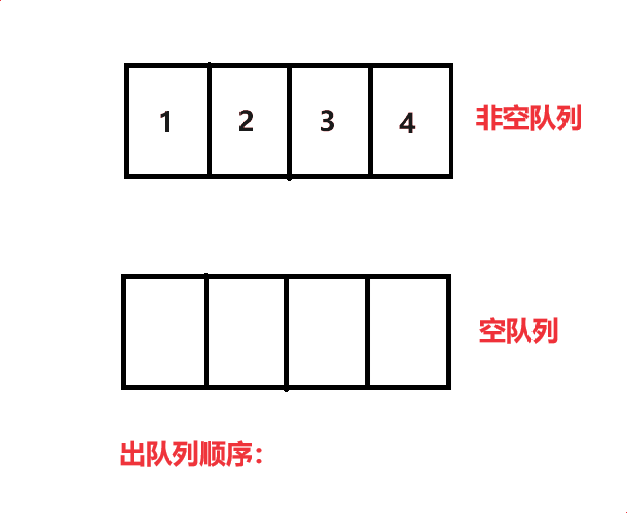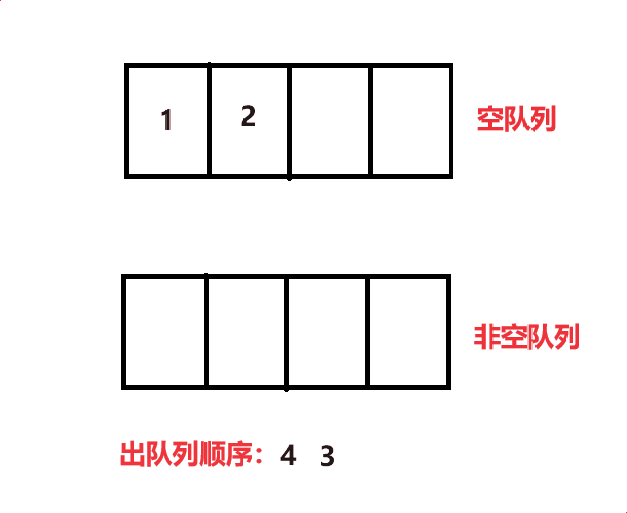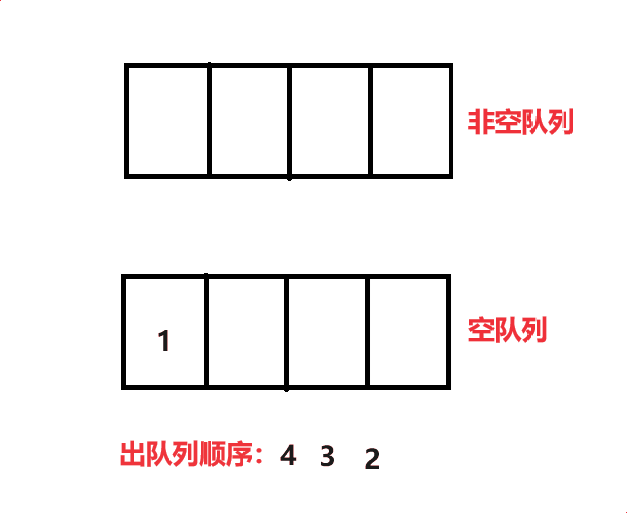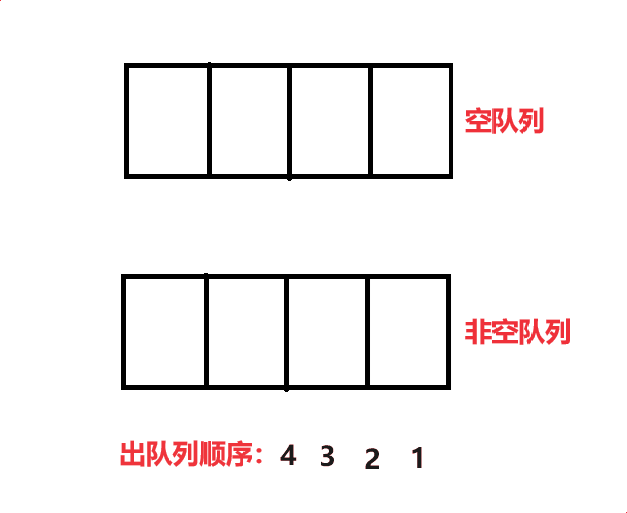
使用两个队列实现栈:
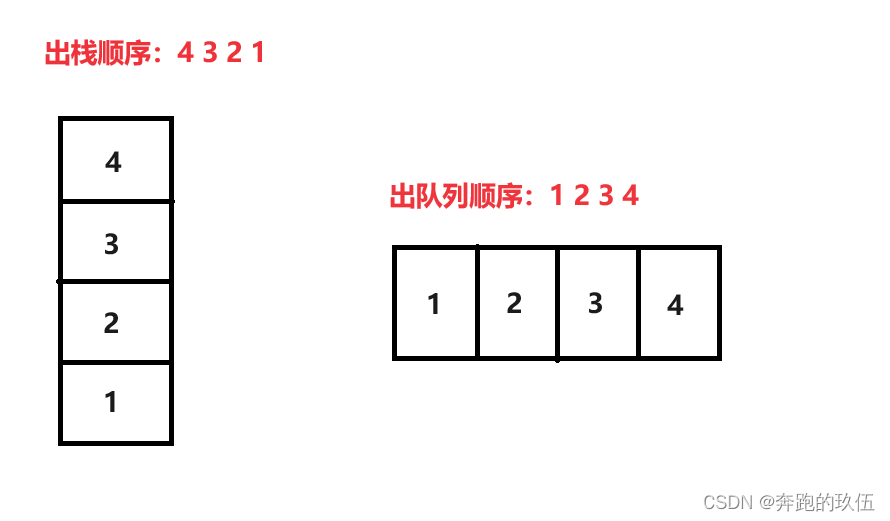
我们可以使用两个队列,一个队列为:空队列,一个队列为:非空队列
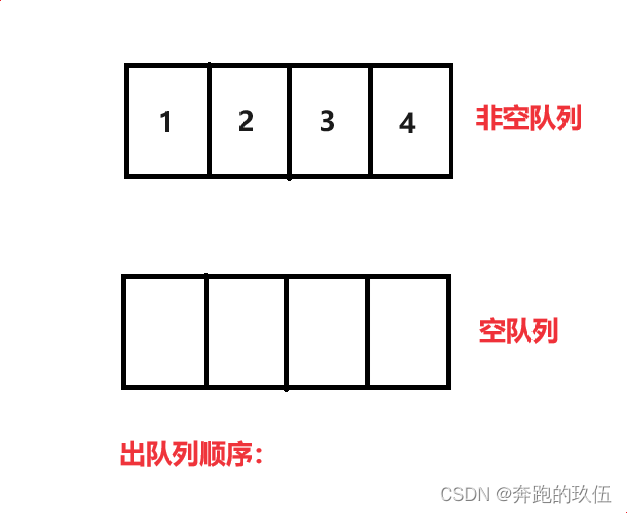
当我们要出队列时:
将 size - 1个数据移动到空队列中,再将最后一个数据出队列,如此往复就可以完成4 3 2 1的出队列顺序
代码(c语言):
队列的各种功能:
typedef int QDataType;
// 链式结构:表示队列
typedef struct QListNode
{
struct QListNode* _next;
QDataType _data;
}QNode;
// 队列的结构
typedef struct Queue
{
QNode* _front;
QNode* _rear;
int size;
}Queue;
// 初始化队列
void QueueInit(Queue* q) {
assert(q);
q->size = 0;
q->_front = NULL;
q->_rear = NULL;
}
// 队尾入队列
void QueuePush(Queue* q, QDataType data) {
assert(q);
QNode* newnode = (QNode*)malloc(sizeof(QNode));
if (newnode == NULL)
{
perror("QueuePush()::malloc()");
return;
}
newnode->_data = data;
newnode->_next = NULL;
//队列为NULL
if (q->_front == NULL)
{
q->_front = q->_rear = newnode;
}
else
{
q->_rear->_next = newnode;
q->_rear = q->_rear->_next;
}
q->size++;
}
// 队头出队列
void QueuePop(Queue* q) {
assert(q);
assert(q->size != 0);
//单个节点
if (q->_front == q->_rear)
{
free(q->_front);
q->_front = q->_rear = NULL;
}
//多个节点
else
{
QNode* next = q->_front->_next;
free(q->_front);
q->_front = next;
}
q->size--;
}
// 获取队列头部元素
QDataType QueueFront(Queue* q) {
assert(q);
assert(q->_front);//队头不能为NULL
return q->_front->_data;
}
// 获取队列队尾元素
QDataType QueueBack(Queue* q) {
assert(q);
assert(q->_rear);//队尾不能为NULL
return q->_rear->_data;
}
// 获取队列中有效元素个数
int QueueSize(Queue* q) {
return q->size;
}
// 检测队列是否为空,如果为空返回非零结果,如果非空返回0
int QueueEmpty(Queue* q) {
assert(q);
return q->size == 0;
}
// 销毁队列
void QueueDestroy(Queue* q) {
assert(q);
QNode* cur = q->_front;
while (cur)
{
QNode* next = cur->_next;
free(cur);
cur = next;
}
q->_front = q->_rear = NULL;
q->size = 0;
}具体实现:
//使用两个队列实现栈
typedef struct {
Queue q1;
Queue q2;
} MyStack;
//初始化栈
MyStack* myStackCreate() {
//创建一个栈
MyStack* newStk = (MyStack*)malloc(sizeof(MyStack));
//初始化栈(即初始化两个队列)
QueueInit(&(newStk->q1));
QueueInit(&(newStk->q2));
return newStk;
}
//入栈
void myStackPush(MyStack* obj, int x) {
//假设法找不为NULL的队列
Queue* noempty = &obj->q1;
if(QueueSize(noempty) == 0)
{
noempty = &obj->q2;
}
//往不为NULL队列中插入
QueuePush(noempty,x);
}
//出栈
int myStackPop(MyStack* obj) {
//假设法判断NULL队列,非NULL队列
Queue* empty = &obj->q1;
Queue* noempty = &obj->q2;
if(QueueSize(noempty) == 0)
{
noempty = &obj->q1;
empty = &obj->q2;
}
//将size - 1个数据移动到NULL队列中
while(QueueSize(noempty) > 1)
{
QueuePush(empty,QueueFront(noempty));
QueuePop(noempty);
}
//出栈
int pop = QueueBack(noempty);
QueuePop(noempty);
return pop;
}
//获取栈顶元素
int myStackTop(MyStack* obj) {
Queue* noempty = &obj->q1;
if(QueueSize(noempty) == 0)
{
noempty = &obj->q2;
}
//获取栈顶数据,也就是队尾的数据
return QueueBack(noempty);
}
//判NULL
bool myStackEmpty(MyStack* obj) {
return QueueEmpty(&obj->q1) && QueueEmpty(&obj->q2);
}
//销毁栈
void myStackFree(MyStack* obj) {
QueueDestroy(&obj->q1);
QueueDestroy(&obj->q2);
free(obj);
}用栈实现队列

思路
使用两个栈实现队列:
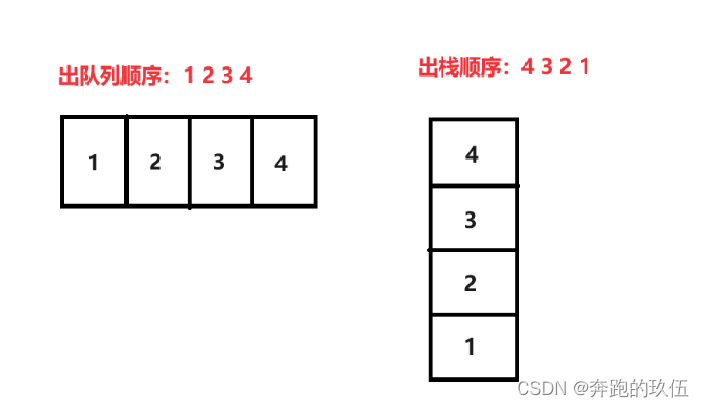
固定两个栈,1. 存数据栈(pushst) 2. 出数据栈(popst)
当我们要出数据时,把存数据栈(pushst)导入到 出数据栈(popst)中,在对栈顶取数据,如此往复就可以实现 4 3 2 1 的出栈顺序
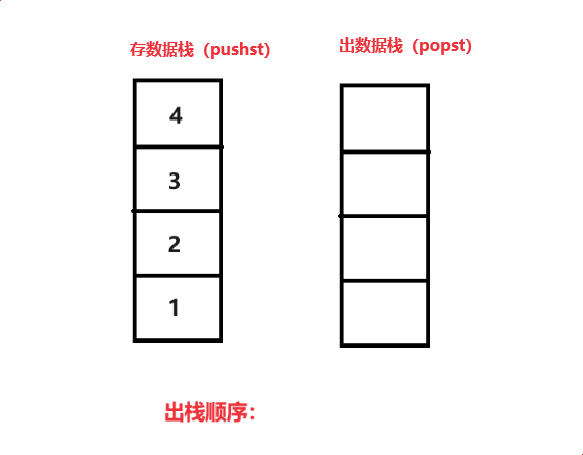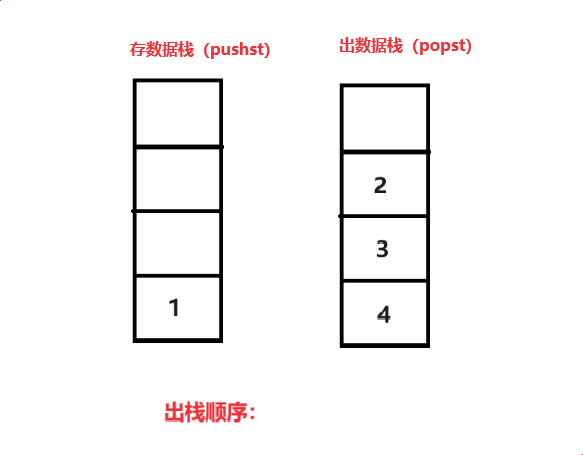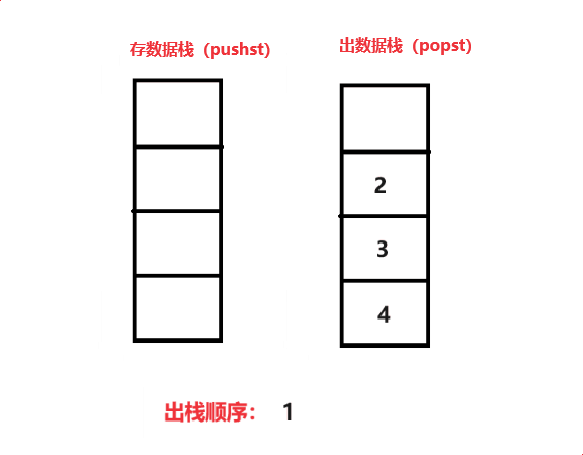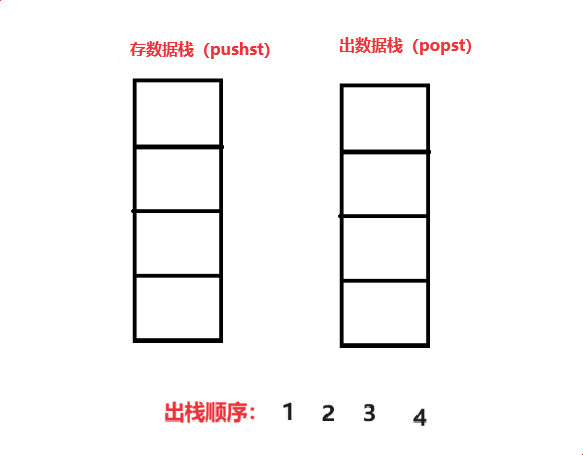
代码(c语言):
栈的各种功能:
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top;
int capacity;
}ST;
// 初始化和销毁
void STInit(ST* pst)
{
assert(pst);
pst->a = NULL;
// top指向栈顶数据的下一个位置
pst->top = 0;
// top指向栈顶数据
//pst->top = -1;
pst->capacity = 0;
}
void STDestroy(ST* pst)
{
assert(pst);
free(pst->a);
pst->a = NULL;
pst->top = pst->capacity = 0;
}
// 入栈 出栈
void STPush(ST* pst, STDataType x)
{
assert(pst);
// 扩容
if (pst->top == pst->capacity)
{
int newcapacity = pst->capacity == 0 ? 4 : pst->capacity * 2;
STDataType* tmp = (STDataType*)realloc(pst->a, newcapacity * sizeof(STDataType));
if (tmp == NULL)
{
perror("realloc fail");
return;
}
pst->a = tmp;
pst->capacity = newcapacity;
}
pst->a[pst->top] = x;
pst->top++;
}
void STPop(ST* pst)
{
assert(pst);
assert(pst->top > 0);
pst->top--;
}
// 取栈顶数据
STDataType STTop(ST* pst)
{
assert(pst);
assert(pst->top > 0);
return pst->a[pst->top - 1];
}
// 判空
bool STEmpty(ST* pst)
{
assert(pst);
return pst->top == 0;
}
// 获取数据个数
int STSize(ST* pst)
{
assert(pst);
return pst->top;
}
typedef struct {
ST pushst;//用来存储数据
ST popst;//用来导出数据
} MyQueue;具体实现
//用两个栈实现队列
MyQueue* myQueueCreate() {
MyQueue* new = (MyQueue*)malloc(sizeof(MyQueue));
STInit(&new->pushst);
STInit(&new->popst);
return new;
}
//入队列
void myQueuePush(MyQueue* obj, int x) {
STPush(&obj->pushst,x);//插入至数据栈(pushst)中
}
//查看队头元素
int myQueuePeek(MyQueue* obj) {
//查看出数据栈(popst),中是否有数据,有则直接查看栈顶数据,没有就把存数据栈(pushst)导入到 出数据栈(popst)中
if(STEmpty(&obj->popst))
{
//把pushst数据全部导入popst
while(!STEmpty(&obj->pushst))
{
STPush(&obj->popst,STTop(&obj->pushst));
STPop(&obj->pushst);
}
}
//返回出数据栈(popst)栈顶数据
return STTop(&obj->popst);
}
//出队列
int myQueuePop(MyQueue* obj) {
//它会帮我们导数据到popst中,popst栈顶的数据就是我们要删除的数据
int pop = myQueuePeek(obj);
STPop(&obj->popst);
return pop;
}
//判空
bool myQueueEmpty(MyQueue* obj) {
return STEmpty(&obj->pushst) && STEmpty(&obj->popst);//两个栈为NULL则队列为NULL
}
//销毁队列
void myQueueFree(MyQueue* obj) {
STDestroy(&obj->pushst);
STDestroy(&obj->popst);
free(obj);
}设计循环队列

思路
利用数组来创建循环队列
代码:
typedef struct {
int* a;
int head;
int rear;//指向最后一个数据的下一个空间
int k;
} MyCircularQueue;
//初始化循环队列
MyCircularQueue* myCircularQueueCreate(int k) {
MyCircularQueue* new = (MyCircularQueue*)malloc(sizeof(MyCircularQueue));
//多开一个空间,用来解决数据为满与空的矛盾问题,当然也可以在结构体多加个size解决
new->a = (int*)malloc(sizeof(int) * (k + 1));
new->head = 0;
new->rear = 0;//尾数据的下一个位置
new->k = k;
return new;
}
//插入队列
bool myCircularQueueEnQueue(MyCircularQueue* obj, int value) {
//判断循环队列满没有,满则不能继续插入
if((obj->rear + 1) % (obj->k + 1) == obj->head)//当尾数据指针 + 1 = 头指针时,队列满
return false;
obj->a[obj->rear] = value;
obj->rear++;
obj->rear %= obj->k + 1;//循环
return true;
}
bool myCircularQueueDeQueue(MyCircularQueue* obj) {
//判断队列是否为空,为空则不能继续删除
if(obj->head == obj->rear)//当尾指针 = 头指针时,队列为空
return false;
obj->head++;
obj->head %= obj->k + 1; //循环
return true;
}
//返回队列头数据
int myCircularQueueFront(MyCircularQueue* obj) {
if(obj->head == obj->rear)
return -1;
return obj->a[obj->head];
}
//返回队列尾数据,即找尾指针指向的上一个地方
int myCircularQueueRear(MyCircularQueue* obj) {
if(obj->head == obj->rear)
return -1;
return obj->a[(obj->k + obj->rear) % (obj->k + 1)];//往前绕k-1去找rear之前的一个数据
}
//判空
bool myCircularQueueIsEmpty(MyCircularQueue* obj) {
//空
return obj->head == obj->rear;
}
//判满
bool myCircularQueueIsFull(MyCircularQueue* obj) {
return (obj->rear + 1) % (obj->k + 1) == obj->head;
}
//销毁队列
void myCircularQueueFree(MyCircularQueue* obj) {
free(obj->a);
free(obj);
}






![[8] CUDA之向量点乘和矩阵乘法](https://img-blog.csdnimg.cn/direct/560e37bd0e114a929b1fd8e5c0f2cf3f.png)