iptables如何借助连续内存块通过xt_table结构管理流量规则
1、iptables 分为两部分:
- 用户空间的 iptables 命令向用户提供访问内核 iptables 模块的管理界面。
- 内核空间的 iptables 模块在内存中维护规则表,实现表的创建及注册。
2、iptables如何管理众多流量规则
iptables通过使用一块连续内存,并将其组织成xt_table结构来管理众多流量规则
xt_table 的初始化:
在内核网络栈中,iptables 通过 xt_table 结构对众多的数据包处理规则进行有序管理,一个 xt_table 对应一个规则表,对应的用户空间概念为 table。
不同的规则表有以下特征:
- 对不同的 netfilter hooks 生效。
- 在同一 hook 中检查不同规则表的优先级不同
基于规则的最终目的,iptables 默认初始化了 4 个不同的规则表,分别是 raw、 filter、nat 和 mangle。以 filter 为例介绍 xt_table的初始化和调用过程:
filter table 的定义如下:
#define FILTER_VALID_HOOKS ((1 << NF_INET_LOCAL_IN) | \
(1 << NF_INET_FORWARD) | \
(1 << NF_INET_LOCAL_OUT))
static const struct xt_table packet_filter = {
.name = "filter",
.valid_hooks = FILTER_VALID_HOOKS,
.me = THIS_MODULE,
.af = NFPROTO_IPV4,
.priority = NF_IP_PRI_FILTER,
};
(net/ipv4/netfilter/iptable_filter.c)
在 iptable_filter.c 模块的初始化函数 iptable_filter_init中,调用xt_hook_link 对 xt_table 结构 packet_filter 执行如下初始化过程:
- 通过 .valid_hooks 属性迭代 xt_table 将生效的每一个 hook,对于 filter 来说是 NF_INET_LOCAL_IN,NF_INET_FORWARD 和 NF_INET_LOCAL_OUT 这3个hook。
- 对每一个 hook,使用 xt_table 的 priority 属性向 hook 注册一个回调函数。
不同 table 的 priority 值如下:
enum nf_ip_hook_priorities {
NF_IP_PRI_RAW = -300,
NF_IP_PRI_MANGLE = -150,
NF_IP_PRI_NAT_DST = -100,
NF_IP_PRI_FILTER = 0,
NF_IP_PRI_SECURITY = 50,
NF_IP_PRI_NAT_SRC = 100,
};
当数据包到达某一 hook 触发点时,会依次执行不同 table 在该 hook 上注册的所有回调函数,这些回调函数总是根据上文的 priority 值以固定的相对顺序执行:
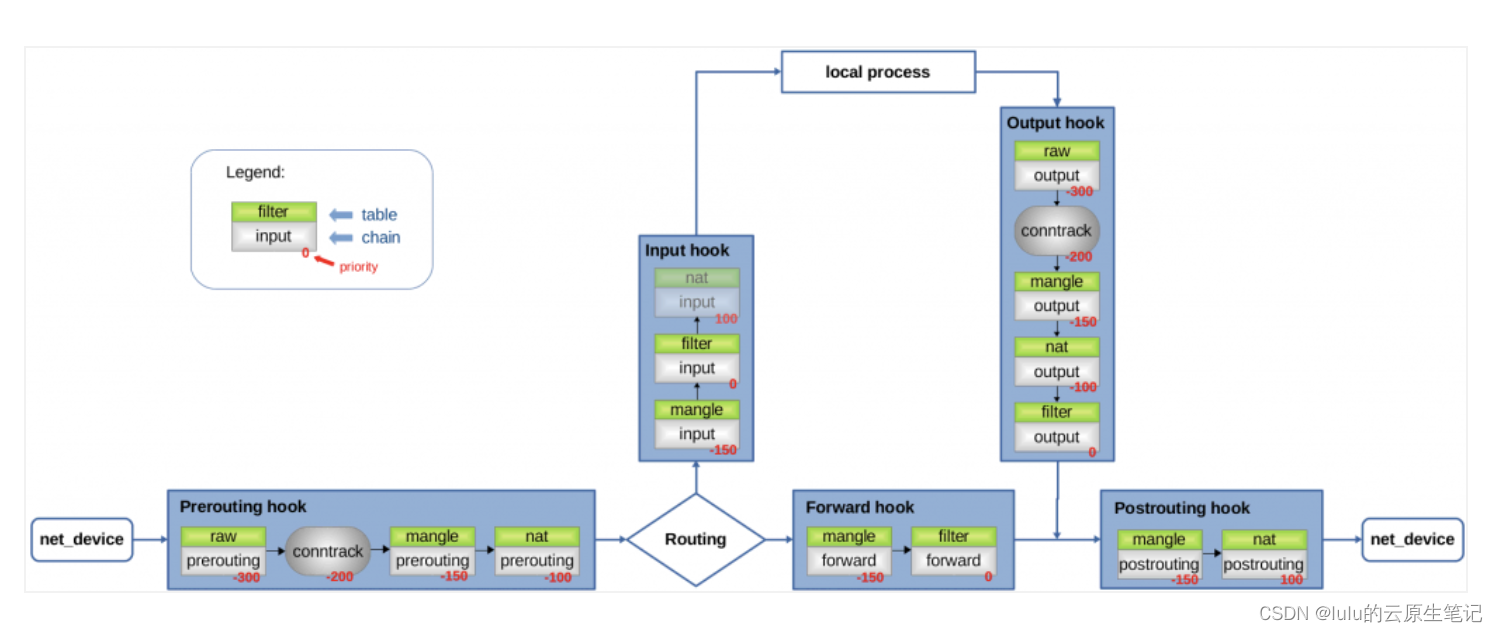
如何执行规则: ipt_do_table()
filter 注册的 hook 回调函数 iptable_filter_hook 将对 xt_table 结构执行公共的规则检查函数 ipt_do_table。ipt_do_table 接收 skb、hook 和 xt_table作为参数,对 skb 执行后两个参数所确定的规则集,返回 netfilter 向量作为回调函数的返回值。
先了解规则集如何在内存中表示。每一条规则由 3 部分组成:
- 1个 ipt_entry 结构体。通过 .next_offset 指向下一个 ipt_entry 的内存偏移地址。
- 0 个或多个 ipt_entry_match 结构体,每个结构体可以动态的添加额外数据。
- 1 个 ipt_entry_target 结构体, 结构体可以动态的添加额外数据。
ipt_entry 结构体定义如下:
struct ipt_entry {
struct ipt_ip ip;
unsigned int nfcache;
/* ipt_entry + matches 在内存中的大小*/
u_int16_t target_offset;
/* ipt_entry + matches + target 在内存中的大小 */
u_int16_t next_offset;
/* 跳转后指向前一规则 */
unsigned int comefrom;
/* 数据包计数器 */
struct xt_counters counters;
/* 长度为0数组的特殊用法,作为 match 的内存地址 */
unsigned char elems[0];
};
ipt_do_table 首先根据 hook 类型以及 xt_table.private.entries 属性跳转到对应的规则集内存区域,执行如下过程:
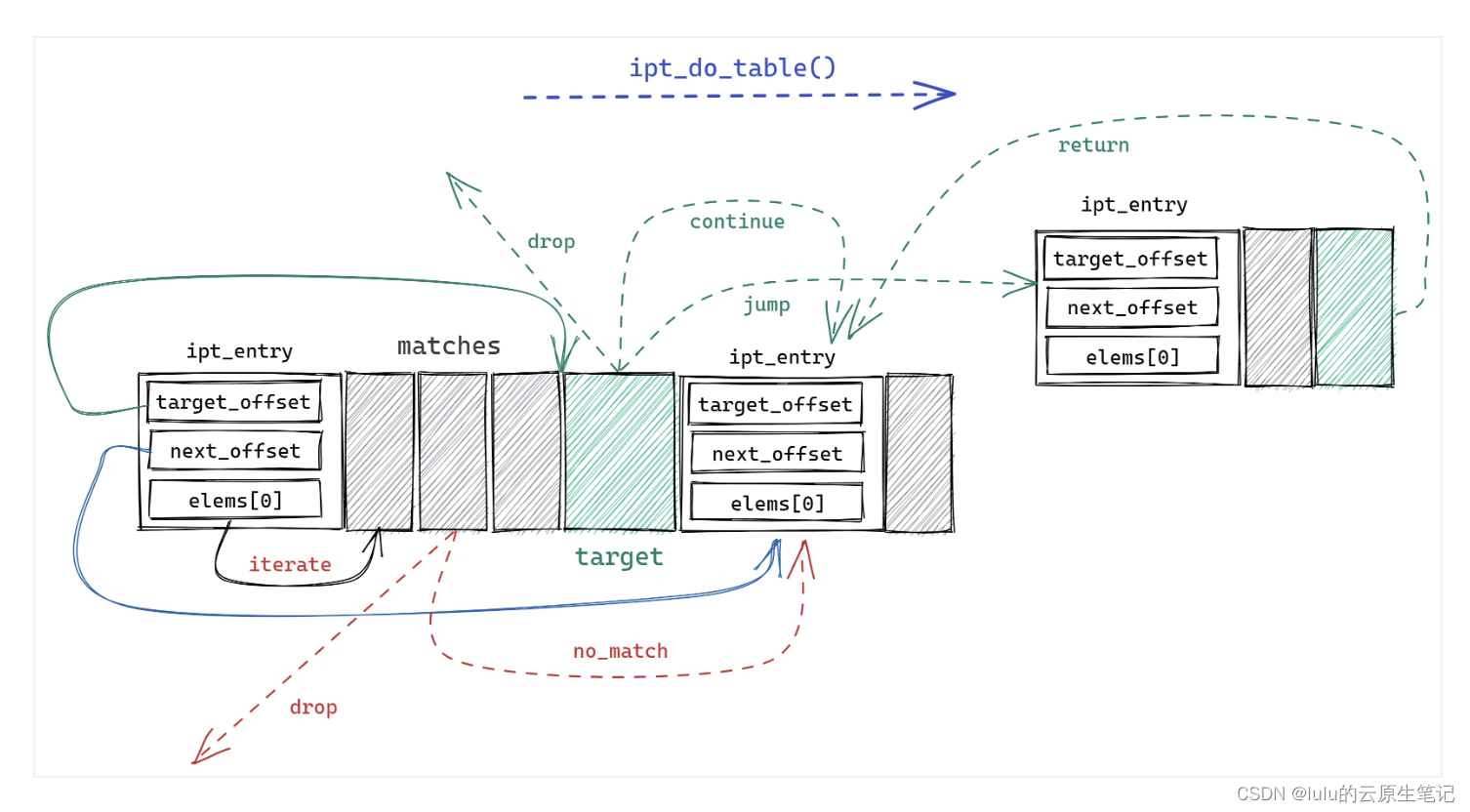
图例解析:
- hook的规则通过ipt_entry结构来连续存放,每个结构代表一条iptables规则,里面的target指向的是本规则要执行的动作,matches是用于匹配流量,next_offset是用于指向下一条规则的偏移量
执行过程:
- 首先检查数据包的 IP 首部与第一条规则 ipt_entry 的 .ipt_ip 属性是否一致,如不匹配根据 next_offset 属性跳转到下一条规则。
- 若IP 首部匹配 ,则开始依次检查该规则所定义的所有 ipt_entry_match 对象,与对象关联的匹配函数将被调用,根据调用返回值有返回到回调函数(以及是否丢弃数据包)、跳转到下一规则或继续检查等结果。
- 所有检查通过后读取 ipt_entry_target,根据其属性返回 netfilter 向量到回调函数、继续下一规则或跳转到指定内存地址的其他规则,非标准 ipt_entry_target 还会调用被绑定的函数,但只能返回向量值不能跳转其他规则。
3、这种管理方式的优缺点
优点:
以上数据结构与执行方式为 iptables 提供了强大的扩展能力,我们可以灵活地自定义每条规则的匹配条件并根据结果执行不同行为,甚至还能在额外的规则集之间栈式跳转。
缺点:
由于每条规则长度不等、内部结构复杂,且同一规则集位于连续的内存空间,iptables 使用全量替换的方式来更新规则,这使得我们能够从用户空间以原子操作来添加/删除规则,但非增量式的规则更新会在规则数量级较大时带来严重的性能问题:假如在一个大规模 Kubernetes 集群中使用 iptables 方式实现 Service,当 service 数量较多时,哪怕更新一个 service 也会整体修改 iptables 规则表。全量提交的过程会 kernel lock 进行保护,因此会有很大的更新时延。