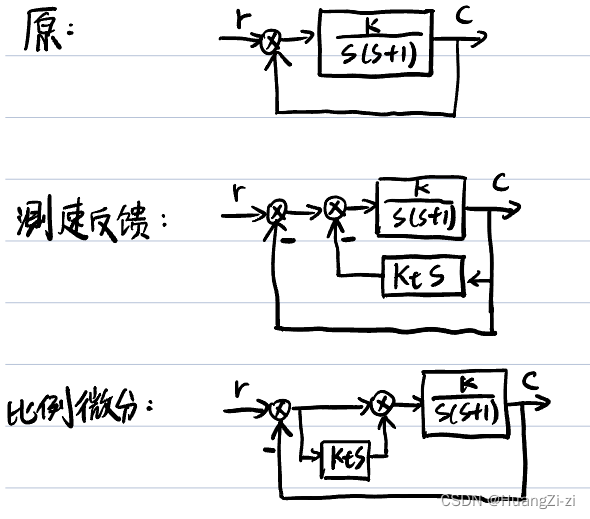
HyperLogLog和Set比较
HyperLogLog
HyperLogLog常用于大数据量的统计, 比如页面访问量统计或者用户访问量统计,作为一种概率数据结构,HyperLogLog 以完美的精度换取高效的空间利用率。Redis HyperLogLog 实现最多使用 12 KB,并提供 0.81% 的标准误差。
常用方法
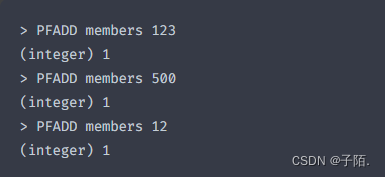
PFADD
向HyperLogLog中添加元素,如果集合中没有该元素则返回1,否则返回0
[图片]
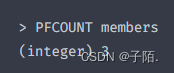
PFCOUNT
统计HyperLogLog中的数据个数
PFMERGE
将多个HyperLogLog合并为一个HyperLogLog

Set
常用方法
SADD
SISMEMBER
SINTER
SCARD
SUNION
两者之间的比较
方法比较
- HyperLogLog和Set都可以直接add数据然后对数据进行去重
- HyperLogLog和Set都可以统计集合中元素个数(HyperLogLog有标准误差)
- HyperLogLog和Set都可以让两个集合合并,Set用SUNION,HyperLogLog使用PFMERGE
- Set可以使用SISMEMBER判断集合中是否有某个数据,而HyperLogLog不可以
- Set可以使用Srem,Spop,Smove等操作集合中某个元素,而HyperLogLog不可以
- Set可以使用集合运算(差集,交集,并集),HyperLogLog只有一个(PFMERGE)并集
性能比较
- Set可以存储232的数据, HyperLogLog可以存储264的数据
- HyperLogLog存储为3bytes~12KB, Sett的存储为60bytes~512MB(每添加一个元素增加2bytes)
- HyperLogLog的add和count都是O(1), merge是O(n);Set的add,remove,SISMEMBER是O(1), scard是O(n)
- HyperLogLog就是在大数据量级的情况下能够在很小的空间中进行元素去重统计。
- 如果使用我们平常的数据结构比如set,HashMap,等,虽然也可以实现去重统计的工作,但是当数据量上升到一定级别之后,其占用的空间也是非常的大。
- 需要注意的是HyperLogLog算法的去重计数方案并不精确,当然不是特别不精确,标准误差只有0.81%当然HyperLogLog虽说占据空间小,但也不是不占空间,当数据量大时它需要占据一定12k存储空间,所以如果我们的统计量可能比较小,使用HyperLogLog可能就是大材小用了,但是如果百万级、千万级,那节省的空间就非常大了。