大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于构建生产级别架构则可以关注AI架构设计专栏。技术宅麻烦死磕LLM背后的基础模型。
关于机器人学习,标准做法是使用针对特定机器人和手头工作量身定制的数据集来训练策略。以这种方式从头开始需要为每项活动收集大量数据,并且生成的策略通常表现出很少的通用性。的确针对机器人和工作中收集的数据是最靠谱的解决方案,针对各种控制场景训练模型可以增强它们的泛化能力并在后续任务中表现更好。
与计算机视觉和自然语言处理中通用模型的普遍性相比,创建能够控制各种机器人的“通用机器人模型”已被证明是一项艰巨的挑战。处理具身智能、传感器配置、动作空间、任务规范、环境和计算预算是训练机器人统一控制策略时的独特问题。
一些机构通过将机器人观察结果直接转化为动作来实现通用机器人模型,在通过zero-shot或者few-shot将模型扩展到新领域和新的机器人。由于这些模型在各种活动、环境和机器人系统中的低层次视动控制的多功能性,它们通常被称为‘通用机器人策略’(Generalist Robot Policies,简称 GRPs)。
虽然在“通用机器人模型”方面已经取得了进展,但这些模型仍有很长的路要走。例如,它们无法对新领域进行有效微调;最大模型甚至不向公众开放。另一个问题是,它们将下游用户的输入(观察结果)限制性很高,例如有些仅仅支持单个摄像机流。

Octo
Octo是为构建开源的、广泛适用的通用机器人操作策略所做的持续努力。它是基于Transformer的扩散策略,采用Open X-Embodiment数据集中的 80万个机器人操作片段来进行预训练。它支持灵活的任务和观察定义,并且可以快速微调到新的观察和动作空间。即将推出两个初始版本的 Octo,分别是Octo-Small(27M参数)和Octo-Base(93M参数)。
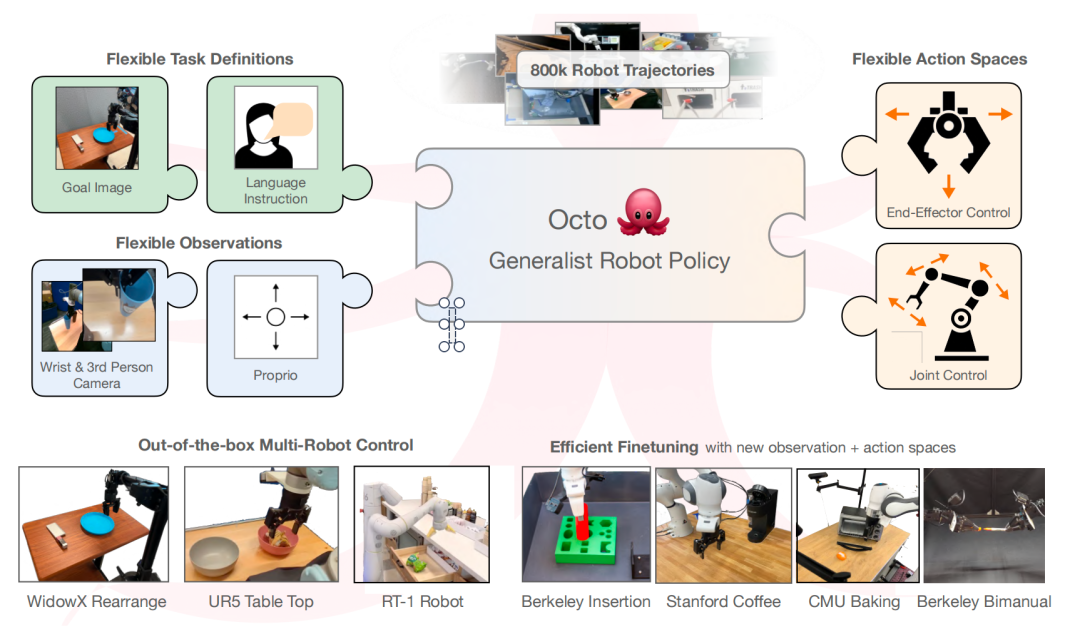
Octo模型的设计强调灵活性和可扩展性,旨在支持各种常用的机器人、传感器配置和动作,同时提供一个通用且可扩展的训练方法,可以在大量数据上进行训练。Octo 支持自然语言指令和目标图像、观察历史以及通过扩散解码实现的多模态动作分布。此外还专门设计了Octo以支持对新机器人设置的高效微调,包括具有不同动作和不同摄像头与本体感觉信息组合的机器人。这种设计旨在使 Octo 成为一个灵活且广泛适用的通用机器人策略,能够用于各种下游机器人应用和研究项目。
Open X-Embodiment 是一个大规模、开放的机器人操作数据集,专门设计用于训练和评估机器人学习模型。它涵盖了广泛的机器人操作任务和环境,旨在为研究人员和开发人员提供丰富的训练数据,以推动通用机器人策略(Generalist Robot Policies, GRPs)的发展。
Octo其实是站在巨人的肩膀上,它的设计灵感来自于机器人模仿学习和可扩展的Transformer训练的最新研究,包括使用“denoising diffusion objectives” 进行动作解码和“动作块”(未来的行为)的预测,以及采用了可扩展ViT训练的模型结构和学习率调整计划。

模型架构

Octo的核心是一个基于Transformer的策略π。它由三个关键部分组成:input tokenizers,它将语言指令 ℓ、目标 g 和观察序列 o1,...,oH 转换为标记 Tl,Tg,To 的输入标记器;处理这些标记并生成嵌入 el,eg,eo 的Transformer backbone(主干);以及产生所需输出的readout heads读取头R(e),即动作 a。
任务和观察的Tokenizer:对于不同模态的将采用特定的标记器,例如语言指令 ℓ 、目标图像 g、和观察 o(例如,机械手腕和第三方的摄像视频流)转换为通用的“标记化”格式(上图左侧):
-
语言输入经过标记化后,通过预训练的变压器,生成语言嵌入标记序列。这里采用了t5-base(111M)模型。
-
图像观察和目标通过一个浅层卷积堆栈,然后分成一系列扁平化patches。
值得一提的是这里需要将通过将可学习的位置参数嵌入到任务和观察Token上,并将它们按顺序排列进行组装,输入Transformer中。
Transformer backbone(主干):一旦输入被转换为统一的标记序列,它们就会被Transformer 处理。这与之前的工作类似,这些工作在观察和动作序列上训练基于Transformer的策略。
Octo 变压器的注意力机制是(block-wise masked)块状遮罩的:观察标记只能与相同或更早时间步 To,0:t 中的标记发生因果关系。对应于不存在观察的标记完全被屏蔽了。这种模块化设计使能够在微调过程中添加和删除观察或任务。
除了这些输入标记块外,还插入了学习的Readout Tokens(紫色)。仔细观察上图,紫色的部分会与其之前的序列中的绿色和蓝色的标记相关联,但它不会被绿色或者蓝色的关联。因此,紫色标记的作用类似于BERT中的[CLS] 标记(分隔符)。
紫色标记的输出接着一个轻量级的“action head”(由一个三层多层感知器(MLP)组成,具有256的隐藏维度、残差连接和层归一化。)实现扩散。这个“action head”预测未来一系列的连续动作合集。
Octo允许在下游微调过程中灵活添加新的输入(含任务和观察现象)或输出。当下游任务中添加新的任务、观察现象或损失函数时,完全保留Transfomer的预训练权重。
只需根据规范的更改添加新的位置嵌入、新的轻量级编码器或新头的参数。这与之前的架构不同,之前的架构要求添加或删除图像输入或更改任务规范将需要重新初始化或重新训练预训练模型的大部分组件。这种灵活性对于Octo成为真正“通用”的基础模型至关重要。
由于无法在预训练期间覆盖所有可能的机器人传感器和动作配置,因此在微调过程中能够调整Octo的输入和输出使之成为通用工具。
之前模型一般设计标准的Transformer或将视觉编码器与MLP输出头融合在一起,锁定模型所期望的输入类型和顺序。相比之下,对于Octo来说,在新的场景下,不需要从零开始训练。


训练数据
训练通用机器人策略的关键要素是机器人训练数据。与可以从网络上抓取的视觉和语言数据相比,大规模获取机器人数据具有挑战性,并且通常需要对硬件和人力进行大量投资。目前已经存在多个大型机器人导航和自动驾驶数据集,除此之外人们还做了很多努力使得数据集的规模和多样性不断增加。
这些数据集要么通过脚本化和自主策略收集,要么通过人类远程操作。Octo在Open X-Embodiment的数据集上进行了训练,Open-X 数据集包含大约150万个机器人剧集,其中选择了80万个用于Octo训练。迄今为止RT-X模型也仅仅使用了350K的受限子集。因此迄今为止,Octo使用了最大的机器人操作演示数据集进行训练。下面为训练数据集抽样权重和占比。
|
|
|



模型评估

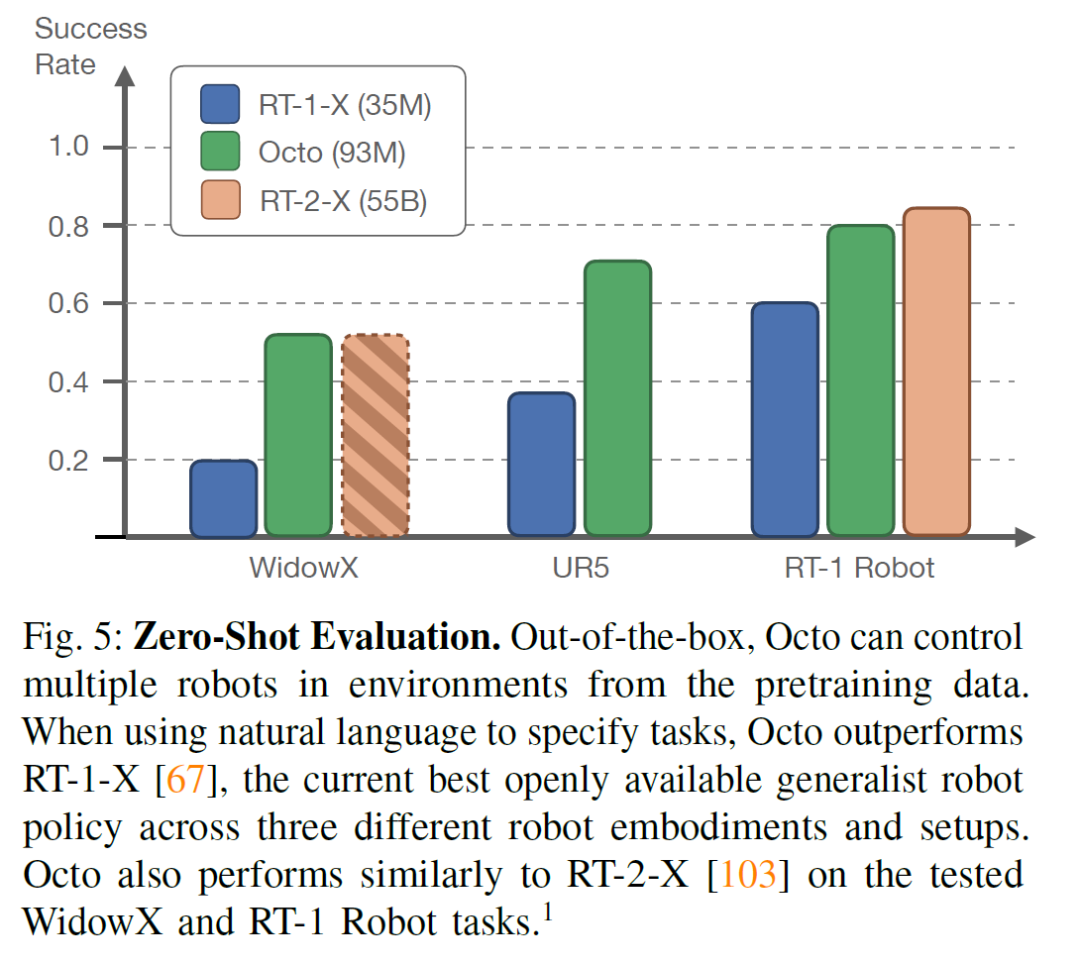
在“零提示评估”中,Octo“开箱即用”(out-of-the-box)在不同环境中控制多个机器人,预训练数据囊括了这些环境。当使用自然语言指定任务时,Octo在三种不同的机器人平台上的表现优于当前最佳的通用机器人RT-1-X。此外,在WidowX和RT-1 Robot任务上,Octo的表现与RT-2-X相当。在这里请注意三种模型的参数规模(下面左下部分)。
这表明Octo具有较强的通用性和适应性,能够在多种机器人平台上实现较高的任务成功率,展现了其在预训练数据基础上进行任务执行的能力。
|
|
![[RK3588-Android12] 关于ES8388 喇叭+PDM回采 4+2配置](https://img-blog.csdnimg.cn/direct/5cac2ca0b24c4c57a43ff5565bef2188.png)