图像处理之DBSCAN算法(C++)
文章目录
- 图像处理之DBSCAN算法(C++)
- 前言
- 一、DBSCAN算法原理
- 二、代码实现
- 总结
前言
DBSCAN聚类算法是一种无监督的数据分类方法,该算法不需要训练数据就可以实现对数据的分类。
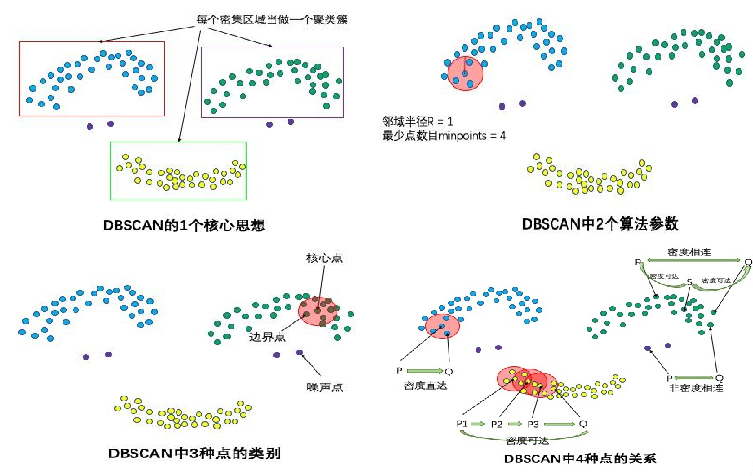
一、DBSCAN算法原理
主要概念与参数:
- ε值:样本与样本之间的距离阈值,如果样本A与样本B的距离小于该阈值,则认为样本A在样本B的邻域内,同时样本B也在样本A的邻域内
- minPts:每一个样本的邻域内样本数阈值,如果该样本邻域内的样本数大于等于该阈值,则认为该样本是核心点
- 核心点:即邻域内的样本数大于等于minPts的样本。如下图所示,如果样本A的邻域内(以A为圆心的圆内)样本数达到minPts以上,则认为A为核心点
- 样本距离:欧式距离与曼哈顿距离是两种很常见的衡量数据样本距离的指标,假设有样本A(a1,a2,…,an)和样本B(b1,b2,…,bn),那么A与B的欧式距离为

曼哈顿距离为:

- 样本的访问标记:一开始将所有样本的标记设置为-1,表示所有样本都没有被访问。算法执行过程中,会遍历一遍所有样本,经过遍历的样本则将其标记置1,表示该样本已经被访问过,不用再处理。
- 样本的类编号:设置一个初始类编号为-1,分类过程中,每新增一个类,类编号加1。每当一个样本被归类到某一个类之后,该样本的类编号则设置为当前新增的类编号。所以可以通过判断该样本的类编号是否为-1来判断其是否已经被归类。
二、代码实现
#include <opencv.hpp>
#include <iostream>
using namespace std;
using namespace cv;
/**********DBSCAN算法***************/
//数据结构
//样本点
class dbscanPoint {
public:
int col; //纵坐标
int row; //横坐标
int grayValue; //灰度值
int cluster; //簇类的类别,-1表示不属于任何簇类
int visited; //访问标志位,1--表示已访问,0--表示未访问
int pointType; //1--噪声点;2--边界点;3--核心点
int pts; //该点的领域内点的个数
dbscanPoint():cluster(-1),visited(0),pointType(1),pts(0){ }
};
//邻域内的点
class nepsPoint{
public:
dbscanPoint p; //样本点
int index; //样本点在原点集中的索引
};
//每一个邻域中的点所属于的核心点
class nepsList {
public:
int centerIndex; //该邻域中所属核心点的索引
int nearIndex; //该邻域中点的索引
};
//计算曼哈顿距离
float calcuDistance(dbscanPoint& a, dbscanPoint& b)
{
return abs(a.col - b.col) + abs(a.row - b.row) + abs(a.grayValue - b.grayValue);
}
//将图像Mat数据类型转换成dbscanPoint类型的数组
void mat2dbscanPoint(cv::Mat& src,std::vector<dbscanPoint>& dst)
{
dbscanPoint tmp;
for(int i=0;i<src.rows;i++)
for (int j = 0; j < src.cols; j++)
{
tmp.row = i;
tmp.col = j;
tmp.grayValue = src.at<uchar>(i, j);
dst.push_back(tmp);
}
}
//对每一类的像素进行可视化,赋予不同的颜色
void displayImg(std::vector<std::vector<dbscanPoint>> clusters,cv::Size size,cv::Mat& dst)
{
cv::Mat tmpImg(size, CV_8UC3);
//RNG rng = theRNG();
srand((unsigned)time(NULL));
for (int i = 0; i < clusters.size(); i++)
{
/*int r = rng.uniform(0, 255);
int b = rng.uniform(0, 255);
int g = rng.uniform(0, 255);*/
int r = rand() % (255 + 1);
int g = rand() % (255 + 1);
int b = rand() % (255 + 1);
for (int j = 0; j < clusters[i].size(); j++)
{
int row = clusters[i][j].row;
int col = clusters[i][j].col;
tmpImg.at<cv::Vec3b>(row, col)[0] = b;
tmpImg.at<cv::Vec3b>(row, col)[1] = g;
tmpImg.at<cv::Vec3b>(row, col)[2] = r;
}
}
tmpImg.copyTo(dst);
}
/*
* @param std::vector<dbscanPoint> p 样本点集合(输入)
* @param float eps 样本与样本点之间的距离阈值,即半径
* @param int minPts 集合中点的最小数量
* @param std::vector<std::vector<dbscanPoint>> clusters 分类后的集合(输出)
* @breif DBSCAN算法实现
*/
void DBSCAN(std::vector<dbscanPoint>& p, float eps, int minPts, std::vector<std::vector<dbscanPoint>>& clusters)
{
// 计算每一个点的邻域点集
std::vector<std::vector<nepsList>> centerPoints(p.size());
for(int i=0;i<p.size();i++)
for (int j = i; j < p.size(); j++)
{
if (calcuDistance(p[i], p[j]) < eps)
{
p[i].pts++; //计数每一个点的邻域点集的个数
nepsList tmpEpsList;
tmpEpsList.centerIndex = i;
tmpEpsList.nearIndex = j;
centerPoints[i].push_back(tmpEpsList); //将点j加入到点i的邻域点集中
if (i != j)
{
p[j].pts++;
tmpEpsList.centerIndex = j;
tmpEpsList.nearIndex = i;
centerPoints[j].push_back(tmpEpsList); //将点j加入到点i的邻域点集中v
}
}
}
//判断是否是核心点,判断的标准是:邻域内点的个数是否达到minPts
for (int i = 0; i < p.size(); i++)
{
if (p[i].pts >= minPts)
{
p[i].pointType = 3; //标记核心点
}
}
int cluster_num = -1; //簇号初始化为-1
for (int i = 0; i < p.size(); i++)
{
if (p[i].visited == 1) //如果当前点已经被访问,则跳过
continue;
p[i].visited = 1; //如果当前点未被访问,则标记为已访问
if (p[i].pointType == 3) //如果当前点为核心点
{
cluster_num++; //簇编号+1
std::vector<dbscanPoint> cluster; //新建一个簇
cluster.push_back(p[i]); //将当前的核心点加入到新建的簇中
p[i].cluster = cluster_num; //将当前的簇序号赋值给当前点的所属簇编号
//求当前核心点的邻域点集
std::vector<nepsPoint> currentPoints;
for (int k = 0; k < centerPoints[i].size(); k++)
{
nepsPoint tmpEpsPoint;
tmpEpsPoint.p = p[centerPoints[i][k].nearIndex];
tmpEpsPoint.index = centerPoints[i][k].nearIndex;
currentPoints.push_back(tmpEpsPoint);
}
//遍历当前核心点的所有邻域点集
for (int j = 0; j < currentPoints.size(); j++)
{
if (p[currentPoints[j].index].visited == 0) //通过index访问当前核心点在原点集中的邻域点,如果未被访问则继续,已被访问则跳过
{
p[currentPoints[j].index].visited = 1; //邻域点在原点集未被访问,则标记为已访问
currentPoints[j].p.visited = 1; //邻域点未被访问,则标记为已访问
if (p[currentPoints[j].index].pointType == 3)
{
for (int m = 0; m < centerPoints[currentPoints[j].index].size(); m++)
{
nepsPoint tmpEpsPoint;
tmpEpsPoint.p = p[centerPoints[currentPoints[j].index][m].nearIndex];
tmpEpsPoint.index = centerPoints[currentPoints[j].index][m].nearIndex;
currentPoints.push_back(tmpEpsPoint);
}
}
if (p[currentPoints[j].index].cluster == -1) //如果当前遍历点未加入任何簇
{
cluster.push_back(p[currentPoints[j].index]); //将该点加入新建的簇中
p[currentPoints[j].index].cluster = cluster_num; //将当前的核心点加入到新建的簇中
currentPoints[j].p.cluster = cluster_num; //将当前的簇序号赋值给当前遍历点的所属簇编号
}
}
}
clusters.push_back(cluster);
}
}
}
int main()
{
// 读取图片
string filepath = "F://work_study//algorithm_demo//dbscan (3).jpg";
cv::Mat src = cv::imread(filepath,cv::IMREAD_GRAYSCALE);
if (src.empty())
{
return -1;
}
std::vector<dbscanPoint> points;
mat2dbscanPoint(src, points);
std::vector<std::vector<dbscanPoint>> clusters;
DBSCAN(points, 15, 25, clusters);
cv::Mat dst;
displayImg(clusters, src.size(), dst);
cv::imwrite("dst.jpg", dst);
cv::waitKey(0);
return 0;
}
原图:

结果图:

总结
本文主要介绍了DBSCAN算法的原理以及使用opencv、C++对灰度图的算法实现,大家可以根据自己的需求结合DBSCAN算法使用。
参考资料:
DBSCAN聚类算法的理解与应用