xml篇—提取VOC格式的坐标,并按照cameraID进行排序(二)
import os
import xml.etree.ElementTree as ET
def parse_xml(xml_file):
tree = ET.parse(xml_file)
root = tree.getroot()
objects = {}
for obj in root.findall('object'):
name = obj.find('name').text
bbox = obj.find('bndbox')
xmin = int(bbox.find('xmin').text)
ymin = int(bbox.find('ymin').text)
xmax = int(bbox.find('xmax').text)
ymax = int(bbox.find('ymax').text)
if name not in objects:
objects[name] = []
objects[name].append((xmin, ymin, xmax, ymax))
return objects
def get_camera_id(filename):
# 从文件中提取摄像头ID
return filename.split('-')[0]
def main():
folder_path = '/app/yyq/dataset/profile_materials/camera_point/jiuting_picture/xml' # 修改为你的XML文件夹路径
xml_files = [f for f in os.listdir(folder_path) if f.endswith('.xml')]
# 根据摄像头ID排序文件列表
xml_files_sorted = sorted(xml_files, key=lambda x: get_camera_id(x))
cameraid_dict = {}
links = []
for xml_file in xml_files_sorted:
xml_path = os.path.join(folder_path, xml_file)
objects = parse_xml(xml_path)
camera_id = xml_file.split('-')[0]
if "1" in objects:
cameraid_dict[camera_id] = objects["1"][0] if objects["1"] else None
if "2" in objects:
links.append({
"name": camera_id,
"box": objects["2"]
})
print("CAMERAID_DICT = {")
for camera_id, bbox in cameraid_dict.items():
print(f' "{camera_id}": {bbox},')
print("}")
print("\nLINKS = [")
for link in links:
print(" {")
print(f' "name": "{link["name"]}",')
print(f' "box": {link["box"]}')
print(" },")
print("]")
if __name__ == '__main__':
main()
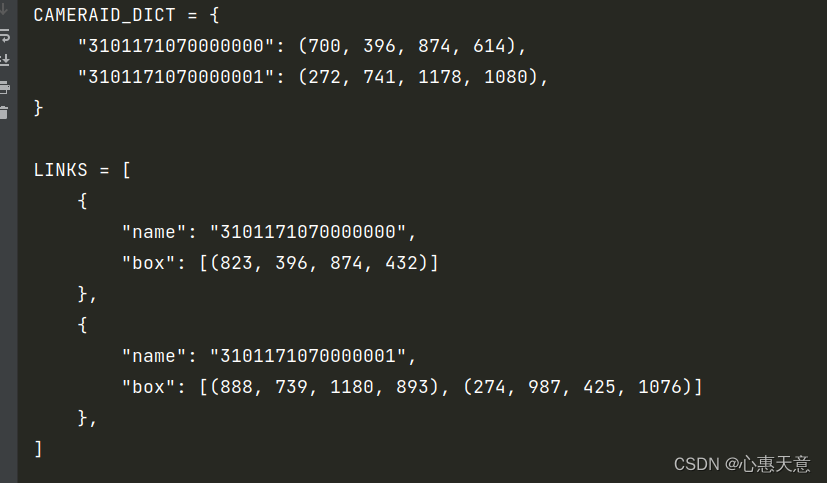
结果如下:
CAMERAID_DICT = {
"3101171070000000": (700, 396, 874, 614),
"3101171070000001": (272, 741, 1178, 1080),
}
LINKS = [
{
"name": "3101171070000000",
"box": [(823, 396, 874, 432)]
},
{
"name": "3101171070000001",
"box": [(888, 739, 1180, 893), (274, 987, 425, 1076)]
},
]