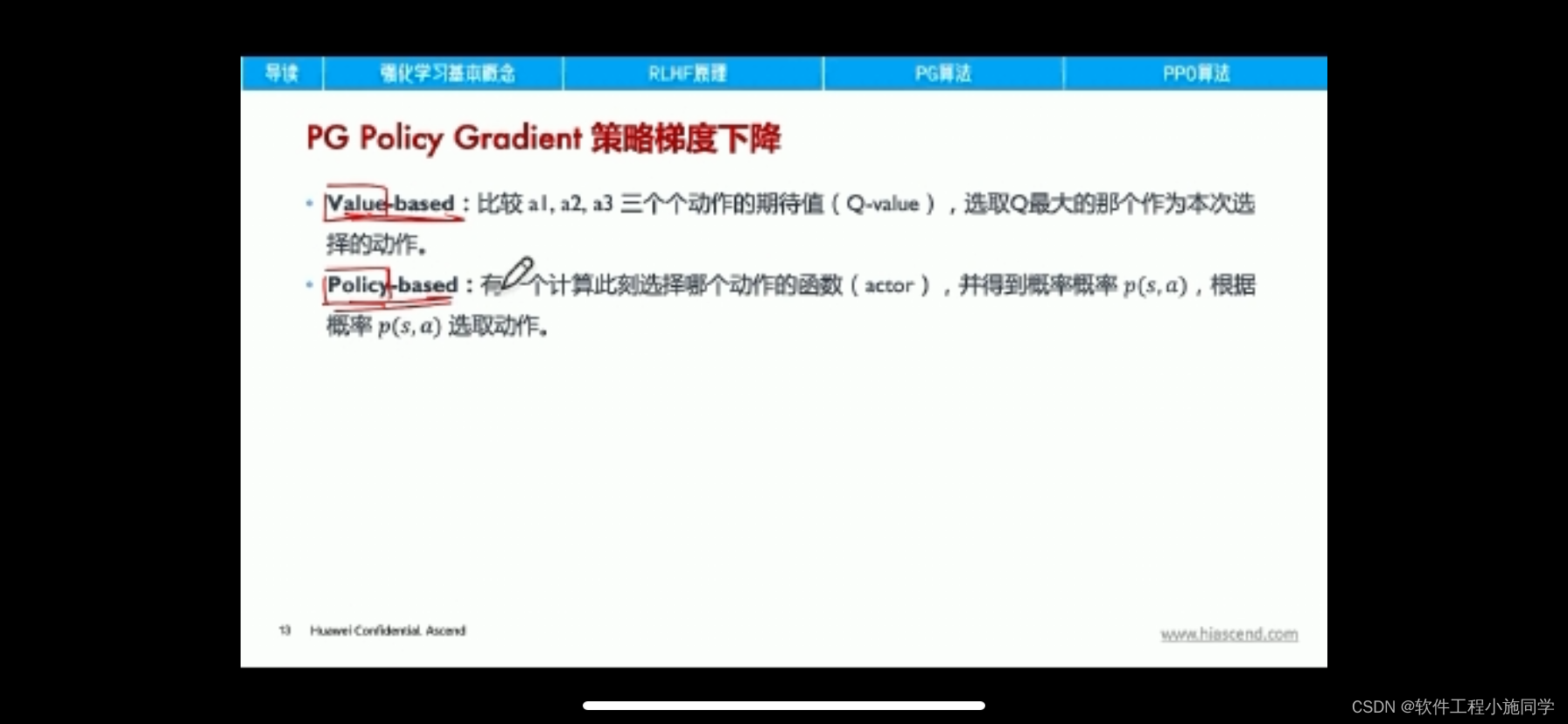
将策略(Policy Based)和价值(Value Based)相结合的方法:Actor-Critic算法,在强化学习领域最受欢迎的A3C算法,DDPG算法,PPO算法等都是AC框架。
一、Actor-Critic算法简介
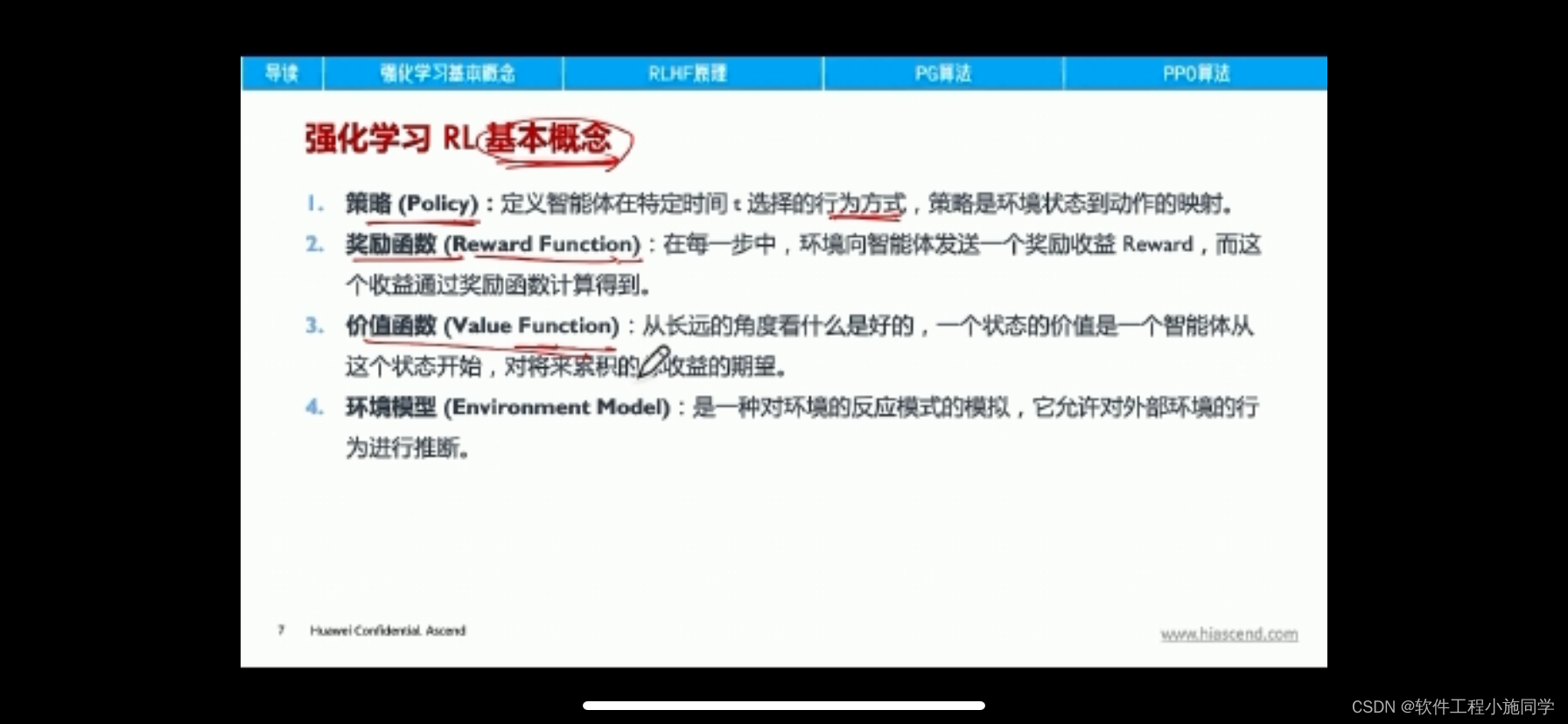
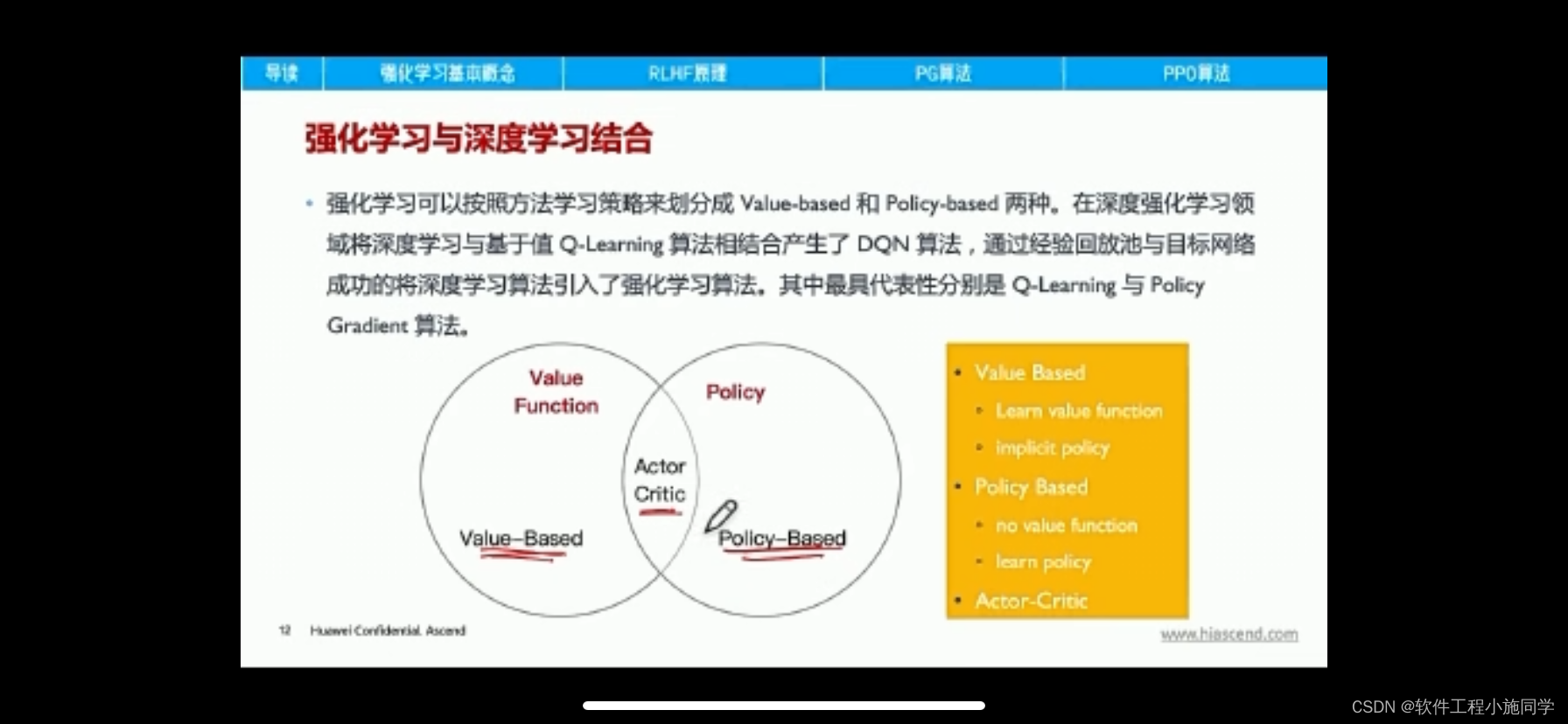
Actor-Critic从名字上看包括两部分,演员(Actor)和评价家(Critic)。其中Actor使用的是策略函数,负责生成动作(Action)并和环境交互。而Critic使用的是价值函数,负责评估Actor的表现,并指导Actor下一阶段的动作。



import gym
import itertools
import matplotlib
import numpy as np
import sys
import tensorflow as tf
import collections
if "../" not in sys.path:
sys.path.append("../")
from Lib.envs.cliff_walking import CliffWalkingEnv
from Lib import plotting
matplotlib.style.use('ggplot')
env = CliffWalkingEnv()
class PolicyEstimator():
"""
策略函数逼近
"""
def __init__(self, learning_rate=0.01, scope="policy_estimator"):
with tf.variable_scope(scope):
self.state = tf.placeholder(tf.int32, [], "state")
self.action = tf.placeholder(dtype=tf.int32, name="action")
self.target = tf.placeholder(dtype=tf.float32, name="target")
# This is just table lookup estimator
state_one_hot = tf.one_hot(self.state, int(env.observation_space.n))
self.output_layer = tf.contrib.layers.fully_connected(
inputs=tf.expand_dims(state_one_hot, 0),
num_outputs=env.action_space.n,
activation_fn=None,
weights_initializer=tf.zeros_initializer)
self.action_probs = tf.squeeze(tf.nn.softmax(self.output_layer))
self.picked_action_prob = tf.gather(self.action_probs, self.action)
self.loss = -tf.log(self.picked_action_prob) * self.target
self.optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
self.train_op = self.optimizer.minimize(
self.loss, global_step=tf.contrib.framework.get_global_step())
def predict(self, state, sess=None):
sess = sess or tf.get_default_session()
return sess.run(self.action_probs, {self.state: state})
def update(self, state, target, action, sess=None):
sess = sess or tf.get_default_session()
feed_dict = {self.state: state, self.target: target, self.action: action}
_, loss = sess.run([self.train_op, self.loss], feed_dict)
return loss
class ValueEstimator():
"""
值函数逼近器
"""
def __init__(self, learning_rate=0.1, scope="value_estimator"):
with tf.variable_scope(scope):
self.state = tf.placeholder(tf.int32, [], "state")
self.target = tf.placeholder(dtype=tf.float32, name="target")
# This is just table lookup estimator
state_one_hot = tf.one_hot(self.state, int(env.observation_space.n))
self.output_layer = tf.contrib.layers.fully_connected(
inputs=tf.expand_dims(state_one_hot, 0),
num_outputs=1,
activation_fn=None,
weights_initializer=tf.zeros_initializer)
self.value_estimate = tf.squeeze(self.output_layer)
self.loss = tf.squared_difference(self.value_estimate, self.target)
self.optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
self.train_op = self.optimizer.minimize(
self.loss, global_step=tf.contrib.framework.get_global_step())
def predict(self, state, sess=None):
sess = sess or tf.get_default_session()
return sess.run(self.value_estimate, {self.state: state})
def update(self, state, target, sess=None):
sess = sess or tf.get_default_session()
feed_dict = {self.state: state, self.target: target}
_, loss = sess.run([self.train_op, self.loss], feed_dict)
return loss
def actor_critic(env, estimator_policy, estimator_value, num_episodes, discount_factor=1.0):
"""
Actor Critic 算法.通过策略梯度优化策略函数逼近器
参数:
env: OpenAI环境.
estimator_policy: 待优化的策略函数
estimator_value: 值函数逼近器,用作评论家
num_episodes: 回合数
discount_factor: 折扣因子
返回值:
EpisodeStats对象,包含两个numpy数组,分别存储片段长度和片段奖励
"""
# Keeps track of useful statistics
stats = plotting.EpisodeStats(
episode_lengths=np.zeros(num_episodes),
episode_rewards=np.zeros(num_episodes))
Transition = collections.namedtuple("Transition", ["state", "action", "reward", "next_state", "done"])
for i_episode in range(num_episodes):
state = env.reset()
episode = []
for t in itertools.count():
action_probs = estimator_policy.predict(state)
action = np.random.choice(np.arange(len(action_probs)), p=action_probs)
next_state, reward, done, _ = env.step(action)
episode.append(Transition(
state=state, action=action, reward=reward, next_state=next_state, done=done))
stats.episode_rewards[i_episode] += reward
stats.episode_lengths[i_episode] = t
# 计算TD目标
value_next = estimator_value.predict(next_state)
td_target = reward + discount_factor * value_next
td_error = td_target - estimator_value.predict(state)
# 更新值函数逼近
estimator_value.update(state, td_target)
# 更新策略逼近
# 使用TD误差作为优势估计
estimator_policy.update(state, td_error, action)
print("\rStep {} @ Episode {}/{} ({})".format(
t, i_episode + 1, num_episodes, stats.episode_rewards[i_episode - 1]), end="")
if done:
break
state = next_state
return stats
tf.reset_default_graph()
global_step = tf.Variable(0, name="global_step", trainable=False)
policy_estimator = PolicyEstimator()
value_estimator = ValueEstimator()
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
stats = actor_critic(env, policy_estimator, value_estimator, 300)
plotting.plot_episode_stats(stats, smoothing_window=10)
二、邻近策略优化(Proximal Policy Optimization,PPO)
邻近策略优化(Proximal Policy Optimization,PPO)算法解决的问题是离散动作空间和连续动作空间的强化学习问题,是on-policy的强化学习算法。
算法主要思想:策略pi接受状态s,
输出动作概率分布,在动作概率分布中采样动作,执行动作,得到回报,跳到下一个状态。在这样的步骤下,我们可以使用策略pi收集一批样本,然后使用梯度下降算法学习这些样本,但是当策略pi的参数更新后,这些样本不能继续被使用,还要重新使用策略pi与环境互动收集数据,真的非常耗时。因此采用重要性采样,使这些样本可以被重复使用。
1. 模型结构

PPO是基于Actor-Critic架构的,这个架构的优势是解决了连续动作空间的问题。
- actor网络的输入为状态,输出为动作概率(对于离散动作空间而言)或者动作概率分布参数(对于连续动作空间而言);
- critic网络的输入为状态,输出为状态的价值。
actor网络输出的动作使优势越大越好,critic网络输出的状态价值越准确越好。
2. 产生experience的过程
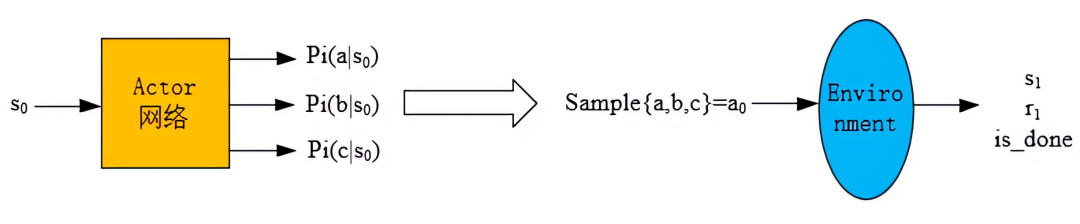
已知一个状态s0,
- 通过 actor网络 得到所有动作的概率(图中以三个动作:a,b,c为例),
- 然后依概率采样得到动作a0,
- 然后将a0输入到环境中得到s1和r1,
状态价值v(s0)通过critic网络输出得到,这样就得到一个experience: (s0,a0,r1,v(s0,logP(a0|s0)),然后将experience放入经验池中。
以上是离散动作的情况,如果是连续动作,就输出概率分布的参数(比如高斯分布的均值和方差),然后按照概率分布去采样得到动作a0。
经验池的意义是为了更方便的计算一条轨迹上状态的累积折扣回报v(st)以及优势A(st,at),而不是消除experience的相关性。
3. 网络更新
3.1 actor网络的更新流程
优势函数A的定义为:
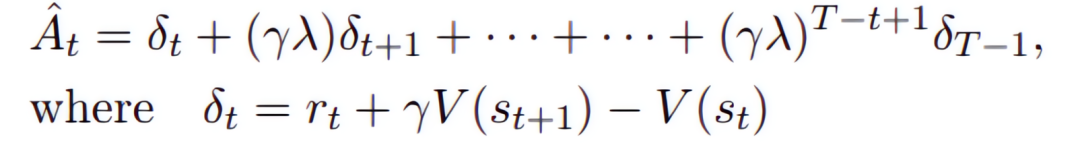
因为Actor网络需要输出的动作优势尽可能地大,所以它的训练需要用以下表达式作为Loss函数:
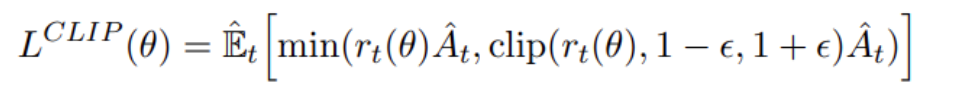
其中
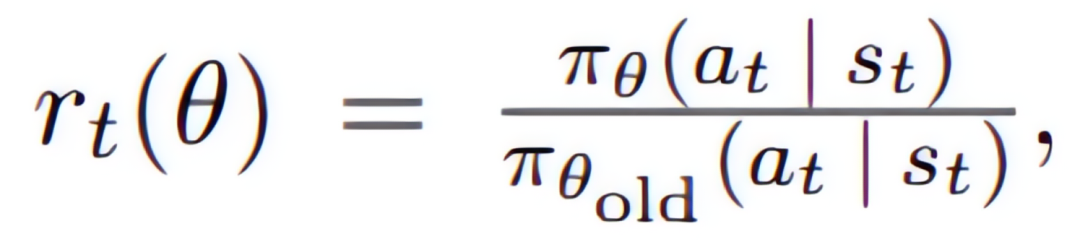
反映了新旧策略差异的程度。
对于上式等价于如下形式:
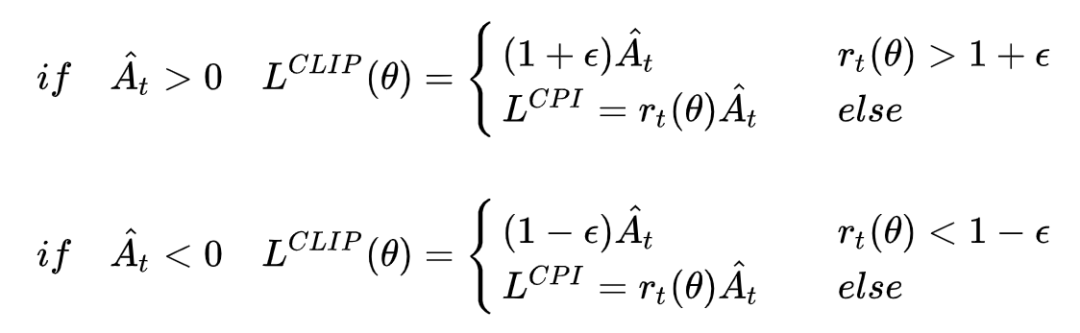
A大于0表示此时策略更好,要加大优化力度。目标函数取最大,那么就会尽量取大的r值,但如果更新力度过大,新旧策略差异就会太大,即
![]()
,那么clip操作和min操作会进行限制,防止了过度优化。
PPO算法使用多步TD,因此它需要跑完一条轨迹后,才开始计算各个状态的累积回报和动作的优势。具体而言,状态价值是通过critic网络输出得到的,动作优势是通过先计算
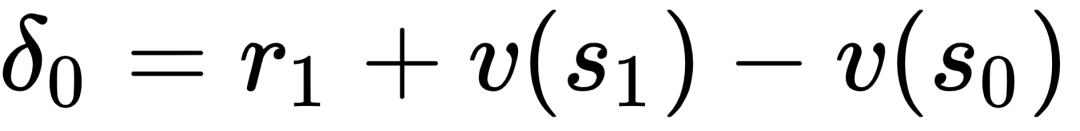
,然后用
![]()
作为折扣因子去计算动作优势,公式如下:
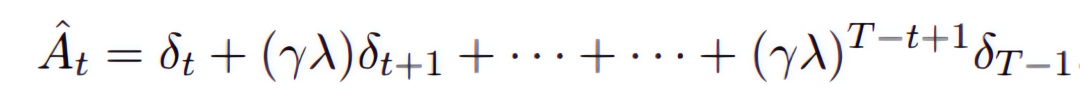
3.2 Critic网络的更新流程
Actor网络更新后,接着拿从经验池buffer中采出的数据进行Critic网络的更新(数据已经计算了状态价值,折扣回报Gt的计算是基于多步TD的方法,从那个状态开始,用每一步环境返回的奖励R与折扣因子相乘后累加,即:
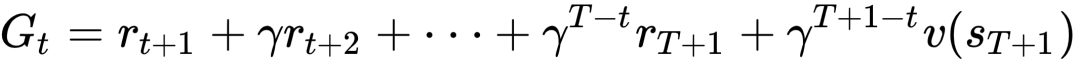
其中
![]()
为网络的估计值,更新方式为:计算好的折扣回报与Critic网络预测当前状态价值做差,用MSEloss作为Loss函数,对神经网络进行训练。
算法流程如下:

参考链接:强化学习PPO算法介绍PPO算法解决的问题是离散动作空间和连续动作空间的强化学习问题,是on-policy的强化学习算法。![]() https://mp.weixin.qq.com/s/pG9UzN1NjfBy4ZvgnNVRwQ
https://mp.weixin.qq.com/s/pG9UzN1NjfBy4ZvgnNVRwQ
第十二章 深度强化学习-Actor-Critic演员评论家第十二章 Actor-Critic演员评论家我们在上一章中介绍了策略梯度(Policy Gradient)方![]() https://mp.weixin.qq.com/s?__biz=MzU1OTkwNzk4NQ==&mid=2247485611&idx=1&sn=5bf388ead8a1edc0051665d7b6f7825b&chksm=fc115d55cb66d4434d701ce86138e0345dffb909657abdad1e8f0da3eb700bccc1a4b86c52b4&scene=21#wechat_redirect
https://mp.weixin.qq.com/s?__biz=MzU1OTkwNzk4NQ==&mid=2247485611&idx=1&sn=5bf388ead8a1edc0051665d7b6f7825b&chksm=fc115d55cb66d4434d701ce86138e0345dffb909657abdad1e8f0da3eb700bccc1a4b86c52b4&scene=21#wechat_redirect