目录
一、问题解析
二、实例剖析
三、算法思路
四、代码实现
结果:
总结
前言
【问题】n 个作业{1, 2, …, n}要在两台机器上处理,每个作业必须先由机器 1 处理,再由机器 2 处理,机器 1 处理作业i所需时间为 ai,机器 2 处理作业 i 所需时间为 bi(1 ≤ i ≤ n),批处理作业调度问题(batch-job scheduling problem)要求确定这 n 个作业的最优处理顺序,使得从第 1 个作业在机器 1 上处理开始,到最后一个作业在机器 2 上处理结束所需时间最少。
一、问题解析
【想法】显然,批处理作业的一个最优调度应使机器 1 没有空闲时间,且机器 2的空闲时间最小。
- 存在一个最优作业调度使得在机器 1 和机器 2 上作业以相同次序完成。
- 由于是一种作业调度顺序的方案,因此该问题的解空间树是排列树。
二、实例剖析
例如,有三个作业{1, 2, 3},在机器 1 上所需的处理时间为(2, 5, 4),在机器 2上所需的处理时间为(3, 2, 1),则存在 6 种可能的调度方案:{(1, 2, 3), (1, 3, 2), (2, 1, 3), (2, 3, 1), (3, 1, 2), (3, 2, 1)},相应的完成时间为{12, 13, 12, 14, 13, 16},最佳调度方案是(1, 2, 3)和(2, 1, 3),最短完成时间为 12。
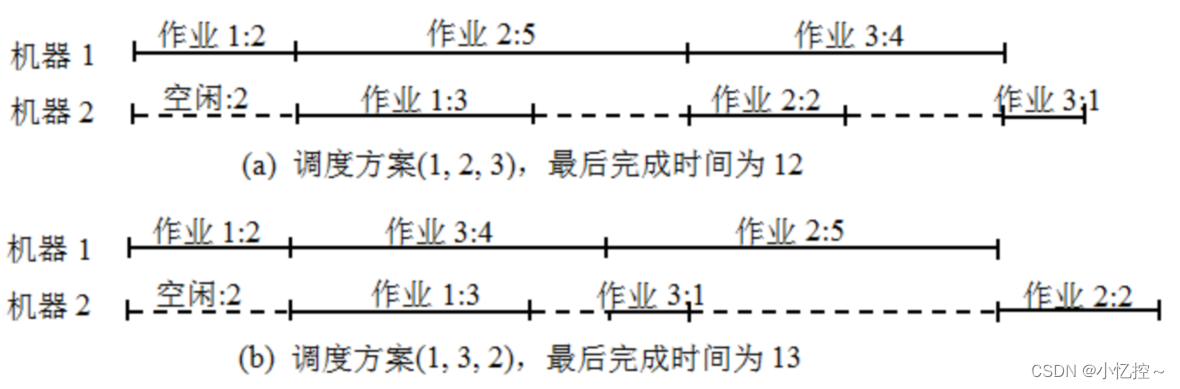
其他情况如上类似,这里就不再赘述!!
三、算法思路
【算法】设数组a[n]存储 n 个作业在机器 1 上的处理时间,b[n]存储 n 个作业在机器 2 上的处理时间。设数组x[n]表示 n 个作业批处理的一种调度方案,其中x[i]表示第 i 个处理的作业编号,sum1[n]和sum2[n]保存在调度过程中机器 1 和机器 2的当前完成时间,其中sum1[i]表示在安排第 i 个作业后机器 1 的当前完成时间,sum2[i]表示在安排第 i 个作业后机器 2 的当前完成时间,且根据下式进行更新:
关键点:
⭐sum1[i] = sum1[i-1] + a[ x[i] ]
⭐sum2[i] = max(sum1[i], sum2[i-1]) +b[ x[i] ]
算法:回溯法求解批处理调度BatchJob
输入:n 个作业在机器 1 上的处理时间 a[n],在机器 2 上的处理时间 b[n]
输出:最短完成时间bestTime,最优调度序列 x[n]
1. 初始化解向量 x[n] = {-1};最短完成时间bestTime = MAX;
2. 初始化调度方案中机器 1 和机器 2 的完成时间:
sum1[n] = sum2[n] = {0}; i = 0;
3. 当 i >= 0 时调度第 i 个作业:
3.1 依次考察每一个作业,如果作业 x[i] 尚未处理,则转步骤 3.2,
否则尝试下一个作业,即 x[i]++;
3.2 处理作业 x[i]:
3.2.1 sum1[i]=sum1[i-1]+ a[x[i]];
3.2.2 sum2[i]=max{sum1[i], sum2[i-1]}+ b[x[i]];
四、代码实现
#include <iostream>
#include <vector>
#include <climits>
using namespace std;
int bestTime = INT_MAX;
vector<int> bestSchedule;
vector<int> currentSchedule;
void backtrack(vector<int>& a, vector<int>& b, vector<bool>& processed, vector<int>& sum1, vector<int>& sum2, int index, int n) {
if (index == n) {
if (sum2[n-1] < bestTime) {
bestTime = sum2[n-1];
bestSchedule = currentSchedule;
}
return;
}
for (int i = 0; i < n; i++) {
if (!processed[i]) {
processed[i] = true;
currentSchedule[index] = i;
sum1[index] = (index > 0 ? sum1[index-1] : 0) + a[i];
sum2[index] = max(sum1[index], (index > 0 ? sum2[index-1] : 0)) + b[i];
backtrack(a, b, processed, sum1, sum2, index + 1, n);
processed[i] = false;
}
}
}
int batchJobScheduling(vector<int>& a, vector<int>& b) {
int n = a.size();
vector<bool> processed(n, false);
vector<int> sum1(n, 0);
vector<int> sum2(n, 0);
currentSchedule.resize(n);
backtrack(a, b, processed, sum1, sum2, 0, n);
return bestTime;
}
int main() {
vector<int> a = {2, 3, 1};
vector<int> b = {3, 1, 2};
int result = batchJobScheduling(a, b);
cout << "Best processing time: " << result << endl;
cout << "Best schedule: ";
for (int job : bestSchedule) {
cout << job << " ";
}
cout << endl;
return 0;
}结果:
第一行表示:所需的最短时间;第二行表示:最好的安排次序

总结
算法时间复杂度高,时间消耗太多了,在ACM上一直会超时,不如贪心法效率高。我是一个小菜鸡,欢迎各路大神批评指正!!






![[Algorihm][简单多状态DP问题][买卖股票的最佳时机含冷冻期][买卖股票的最佳时机含手续费]详细讲解](https://img-blog.csdnimg.cn/direct/05f6e39d6ed2412f9876add4ce3e6342.png)