相信大家对于路标识别,红绿灯识别,图形识别opencv中也是一件烦人的事情,其参数是及其受到现实环境因素的影响的,那么今天我就给大家推荐一种方式,缺点是周期长,但其优点是如果训练效果好久对于环境的各种变化的适应性增强了。
目录
一、环境搭建
1.1 Python3.9
1.2 YOLOv5
1.3 labelimg
1.4 Cuda
1.4.1 安装Cuda
1.4.2 pytorch下载
1.4.3 运行
1.5可能遇到的问题
二、开始工作
2.1 训练模型
2.1.1 创建训练的数据集(图片+标记好的txt文件)
2.1.2 类别声明 以及 数据集目标指引
2.1.3 超参(根据自身需要注意改的地方即可)
2.2 预测模型
三、我们可以部署在安卓移动端 --tflite
一、环境搭建
1.1 Python3.9
我们需要使用Anaconda3创建一个Python3.9的环境,这是为了后续方便使用labelimg进行数据标记和yolov5中需要的pytorch对应需要的环境

我的环境变量的导入信息
Py3.9的包
1.2 YOLOv5
YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite![]() https://github.com/ultralytics/yolov5
https://github.com/ultralytics/yolov5
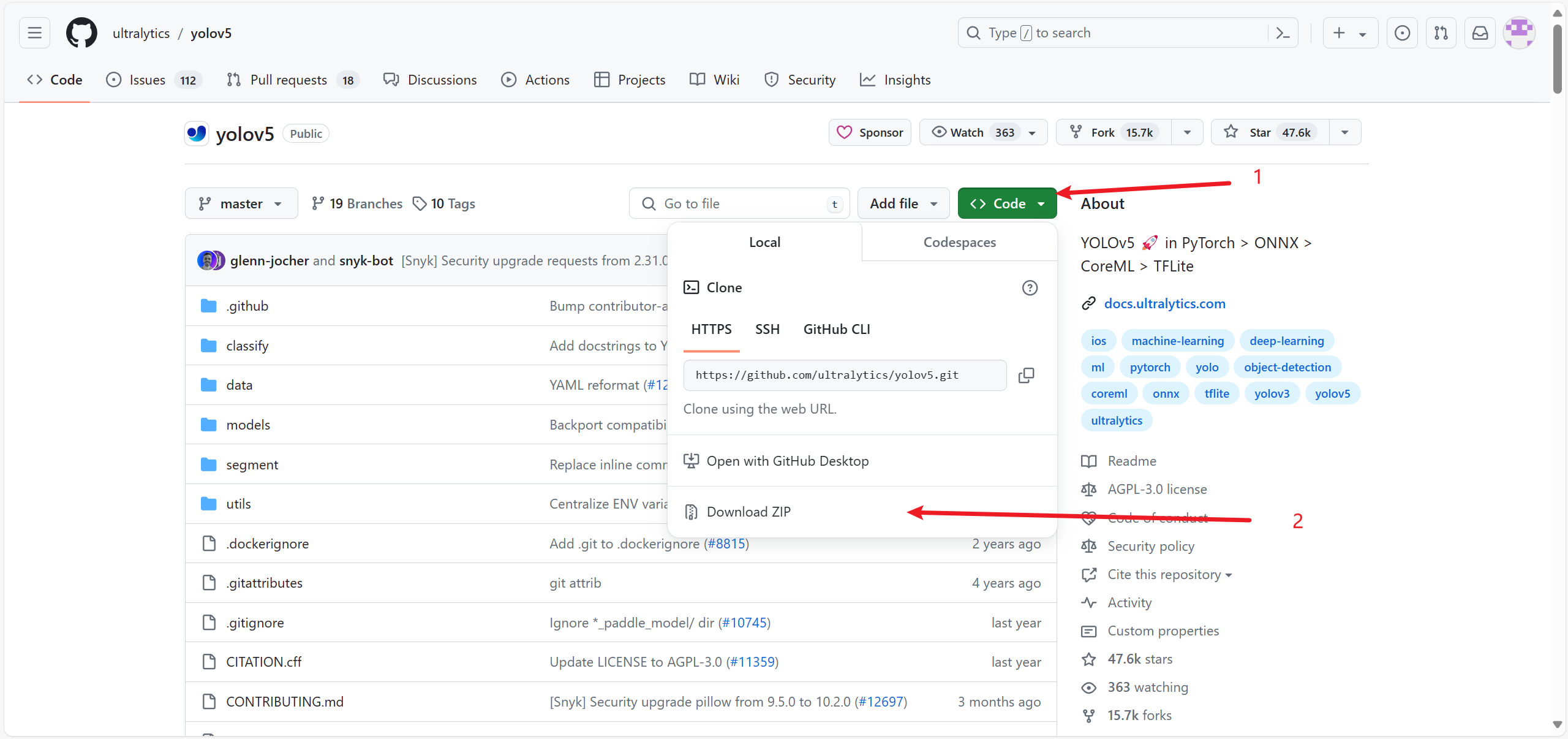
下载好后在不包含中文目录的yolov5的cmd中运行下载其中指定包的版本
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
1.3 labelimg
在cmd中或者conda的管理员的控制台下,使用pip下载labelimg即可
pip install labelimg
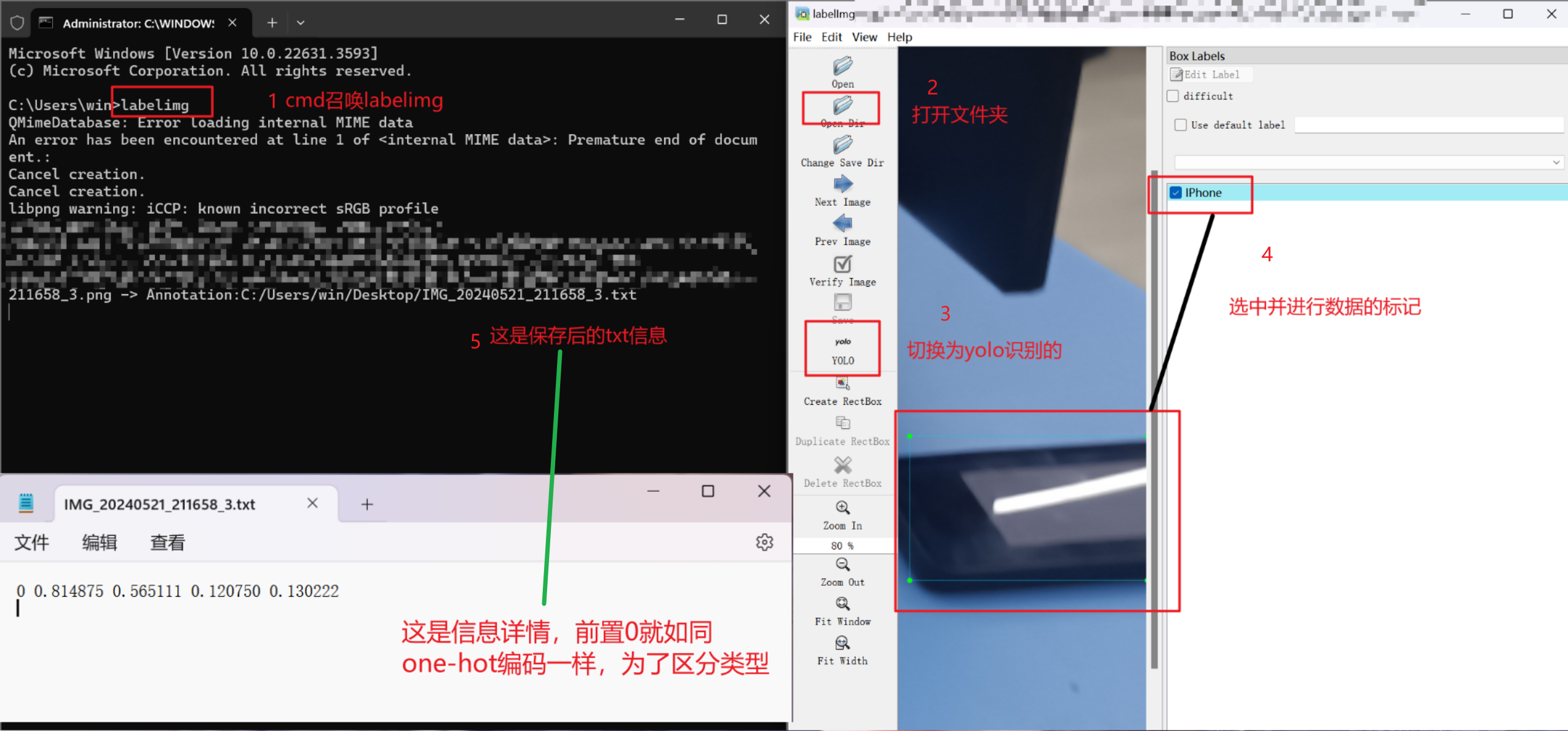
如何标记标记顺序
1.4 Cuda
使用GPU训练项目(我们需要将YOLO中的框架修改下从默认的CPU训练转变成GPU训练模式)
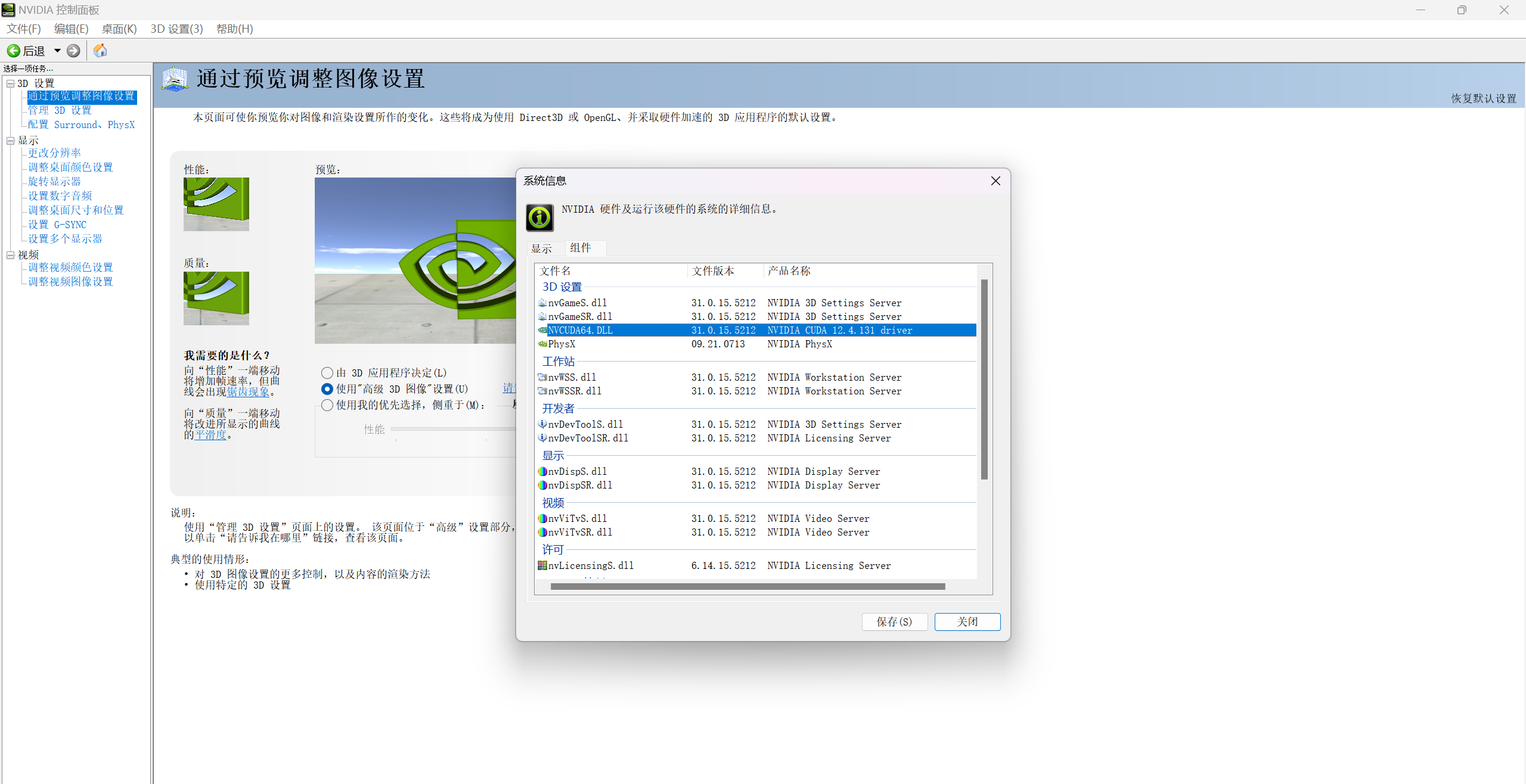
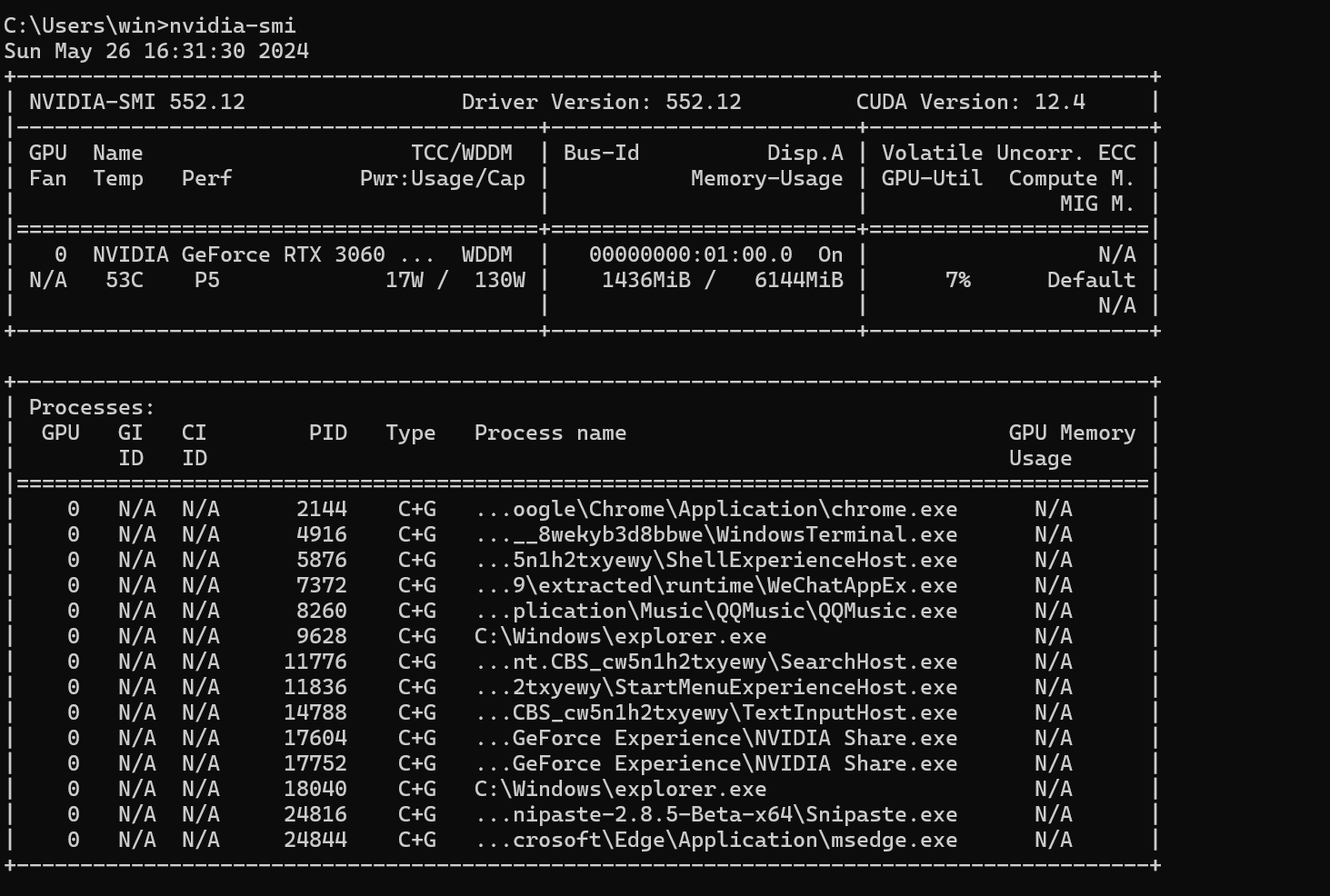
或者这样查询nvidia-smi
1.4.1 安装Cuda
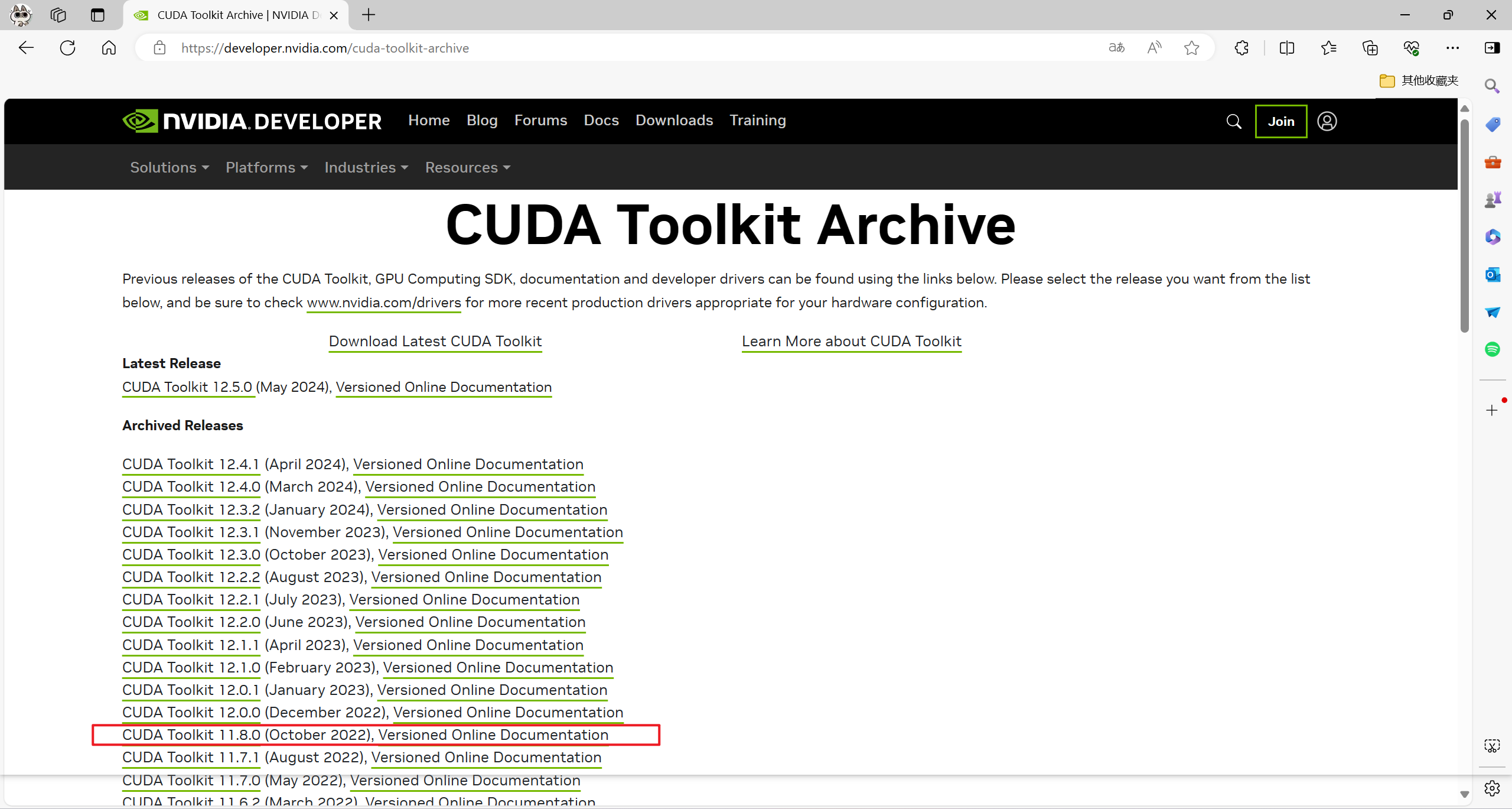
CUDA Toolkit Archive![]() https://developer.nvidia.com/cuda-toolkit-archive
https://developer.nvidia.com/cuda-toolkit-archive
为了稳定性和pytorch版本我选择的是11.8
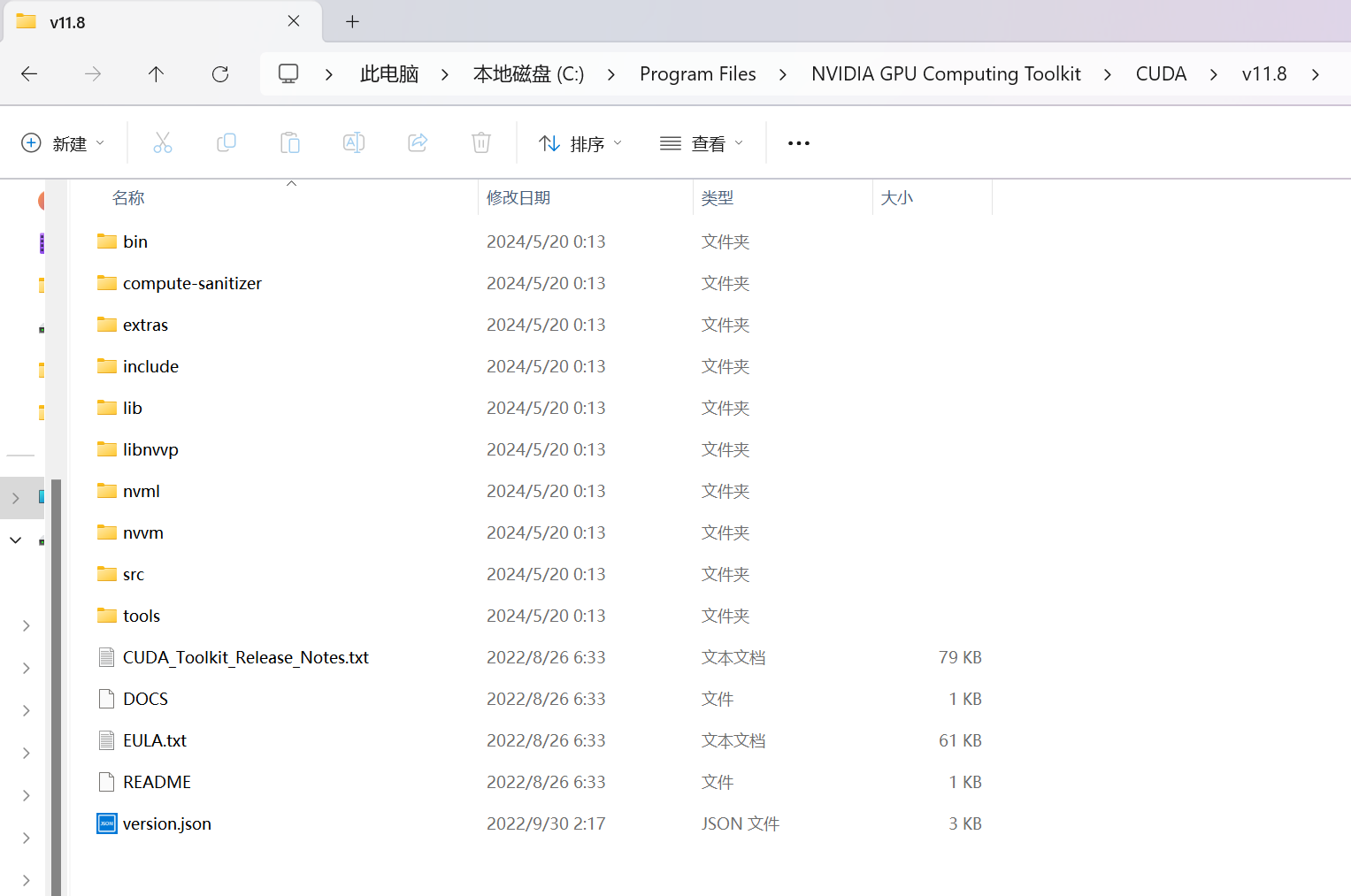
我选择的是本地local安装然后一直点就对了,最终我们在Program Files中可以找见
在环境变量中关于英伟达的信息我有以下配置
1.4.2 pytorch下载
在这里我试过也看很多地方适配的是2.1.0版本
安装这2.7GB的pytorch最好和Cuda本地安装的时候找一个良好的网络环境进行安卓
pip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu118
1.4.3 运行
代码中的需要修改使得GPU才是训练的device
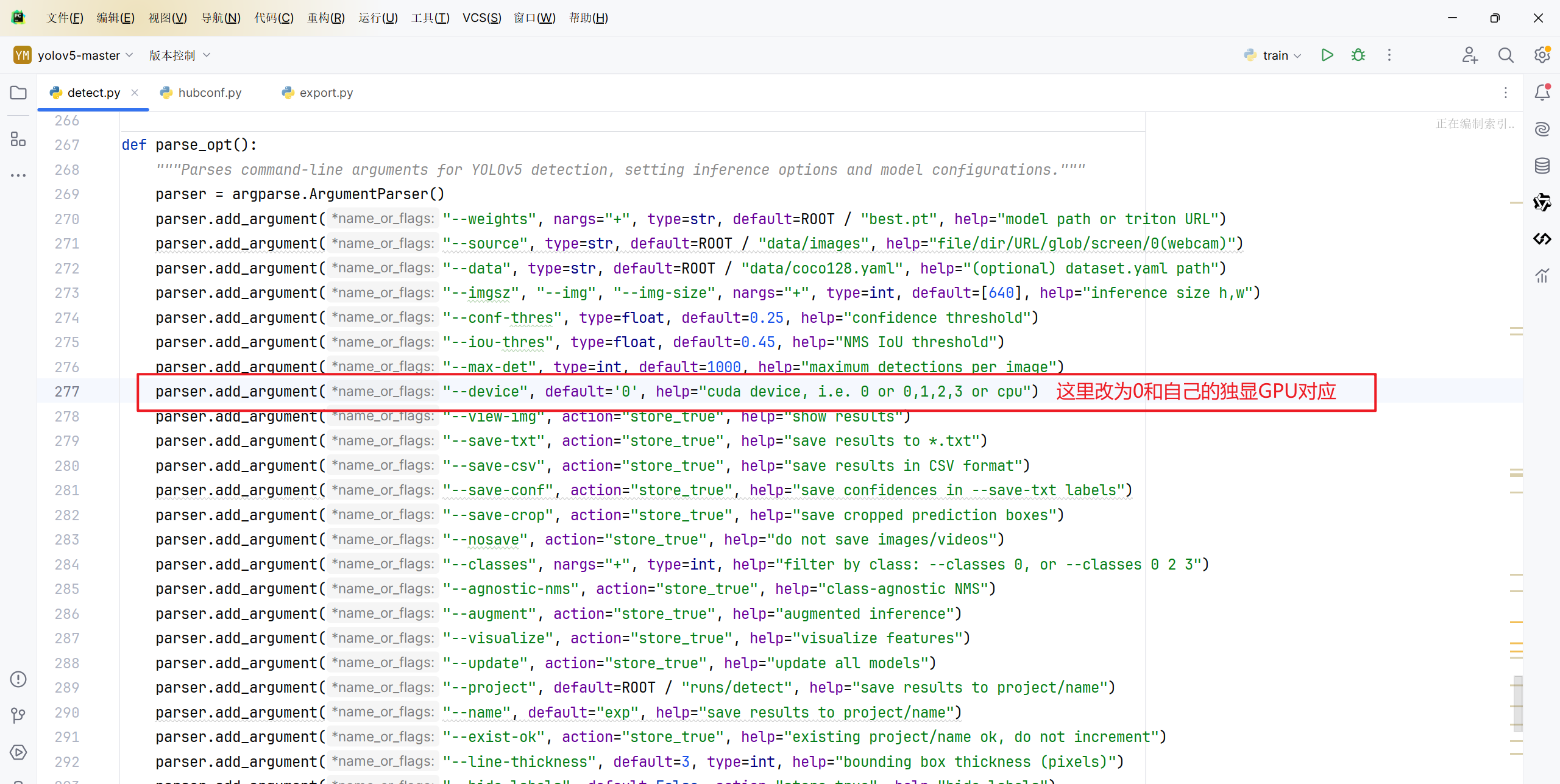
运行查看是不是已经是GPU了

1.5可能遇到的问题
Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized
在指定下载好环境的env下:删除..\Anaconda3\envs\指定下载好环境\Library\bin\libiomp5md.dll
可能存在两块GPU的情况
在网上找见对应的电脑怎么开启独显
二、开始工作
2.1 训练模型
更具上述所说过的我们需要训练一个权重模型pt
官方给的图片

2.1.1 创建训练的数据集(图片+标记好的txt文件)
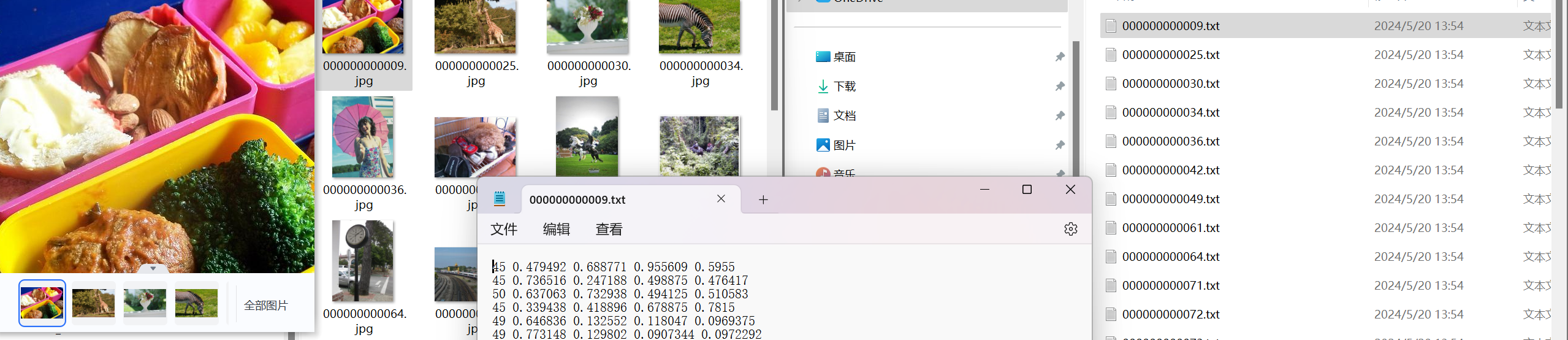
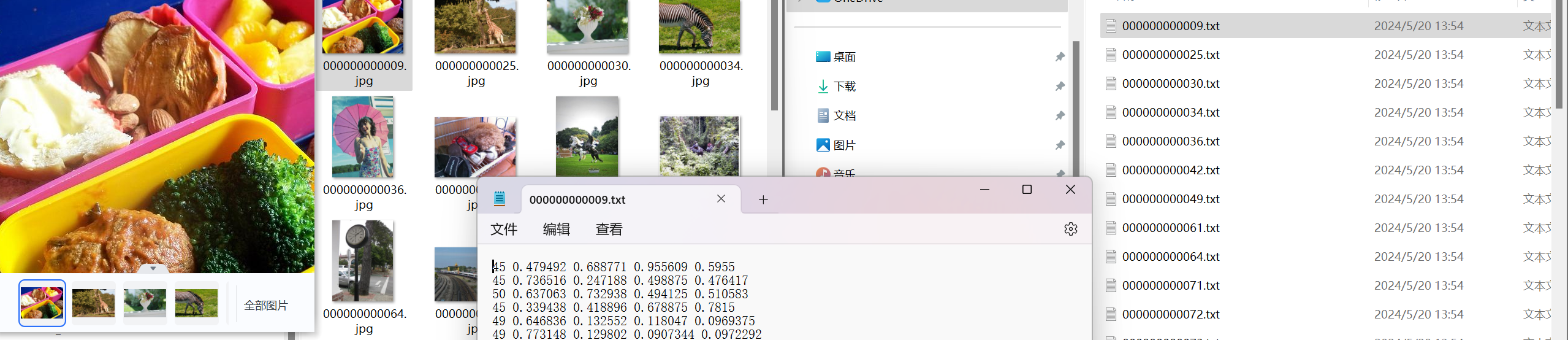
我们先将所有的信息如图下图防止在一起

在data文件夹下创建datasets文件夹其分支下在创建images和labels,在这两个新分支下均创建test和train和val文件夹用于后续存放内容
datasets
├── images
│ ├── test
│ ├── train
│ └── val
└── labels
├── test
├── train
└── val
将标记好的图片放置在images下的train和val中分别的两份;在labels下的train和val中放置txt文件
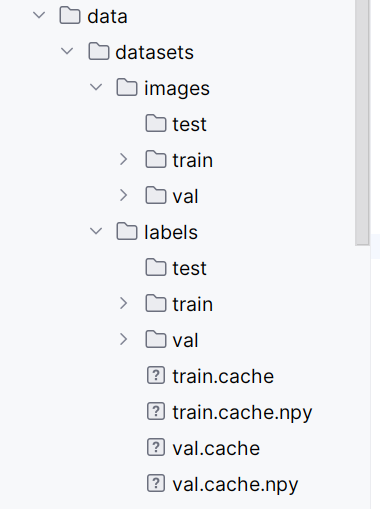
随后我们将需要预测的图片放置在data的images文件下
2.1.2 类别声明 以及 数据集目标指引
- 我们在data的test.yaml(没有就自己创建一个)中写
train: ./data/datasets/images/train # 训练集图像文件目录
val: ./data/datasets/images/val # 验证集图像文件目录
test: ./data/datasets/images/test
# Classes
nc: # 类别数
names: [
]在上述的class.txt中找到补全nc和names,names切记是字符串形式的。
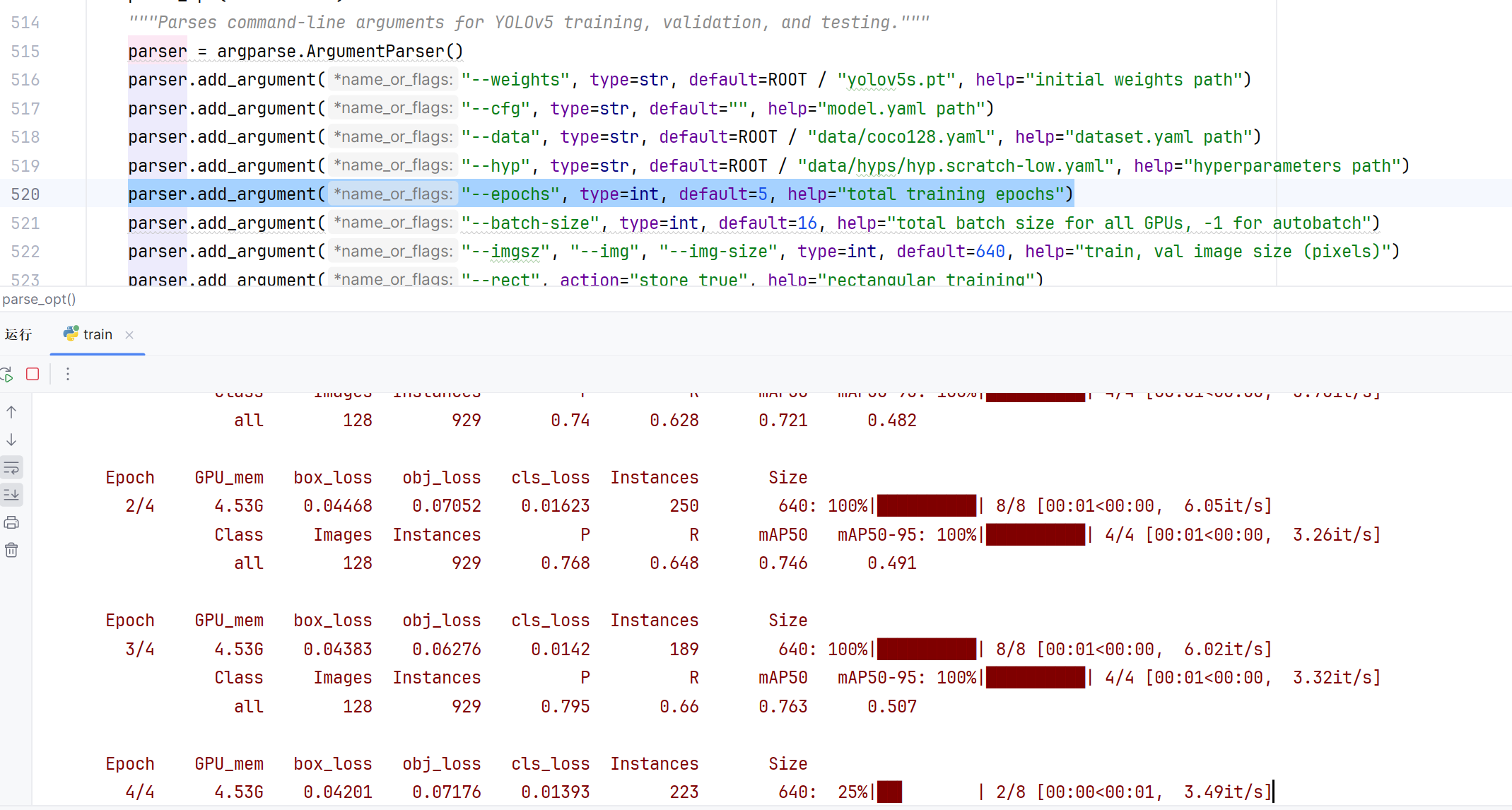
- 在train.py文件中parse_opt
parser.add_argument("--data", type=str, default=ROOT / "data/test.yaml", help="dataset.yaml path")
parser.add_argument("--hyp", type=str, default=ROOT / "data/hyps/test.yaml", help="hyperparameters path")
注意好迭代次数
parser.add_argument("--epochs", type=int, default=5, help="total training epochs")- 同样的下面预测模型detect.py文件准确度中parse_opt的时候
parser.add_argument("--source", type=str, default=ROOT / "data/images", help="file/dir/URL/glob/screen/0(webcam)")
2.1.3 超参(根据自身需要注意改的地方即可)
data文件夹下的hyps的test.yaml中写,超参设置要合理,否则就会影响概率模型。
如左右和上下翻转的参数同时存在来说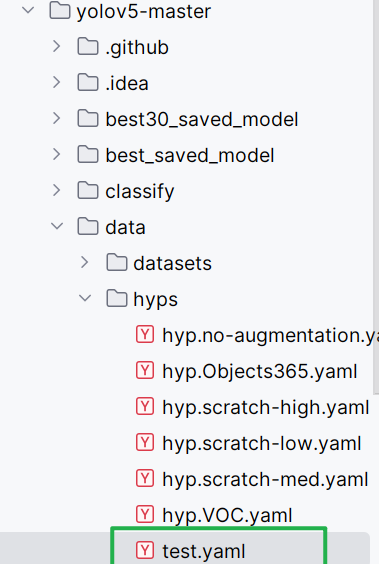
比方说:数字9和数字6在一定程度上会识别成一个东西。
lr0: 0.01 # 初始学习率 (SGD=1E-2, Adam=1E-3)
lrf: 0.2 # 循环学习率 (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1 学习率动量
weight_decay: 0.0005 # 权重衰减系数
warmup_epochs: 3.0 # 预热学习 (fractions ok)
warmup_momentum: 0.8 # 预热学习动量
warmup_bias_lr: 0.1 # 预热初始学习率
box: 0.05 # iou损失系数
cls: 0.5 # cls损失系数
cls_pw: 1.0 # cls BCELoss正样本权重
obj: 1.0 # 有无物体系数(scale with pixels)
obj_pw: 1.0 # 有无物体BCELoss正样本权重
iou_t: 0.20 # IoU训练时的阈值
anchor_t: 4.0 # anchor的长宽比(长:宽 = 4:1)
# anchors: 3 # 每个输出层的anchors数量(0 to ignore)
#以下系数是数据增强系数,包括颜色空间和图片空间
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # 色调 (fraction)
hsv_s: 0.7 # 饱和度 (fraction)
hsv_v: 0.4 # 亮度 (fraction)
degrees: 0.0 # 旋转角度 (+/- deg)
translate: 0.1 # 平移(+/- fraction)
scale: 0.5 # 图像缩放 (+/- gain)
shear: 0.0 # 图像剪切 (+/- deg)
perspective: 0.0 # 透明度 (+/- fraction), range 0-0.001
flipud: 0.5 # 进行上下翻转概率 (probability)
fliplr: 0.0 # 进行左右翻转概率 (probability)
mosaic: 1.0 # 进行Mosaic概率 (probability)
mixup: 0.0 # 进行图像混叠概率(即,多张图像重叠在一起) (probability)
copy_paste: 0.0由于数据集作为实验需要不便展示所以就以yolo官方的来
2.2 预测模型
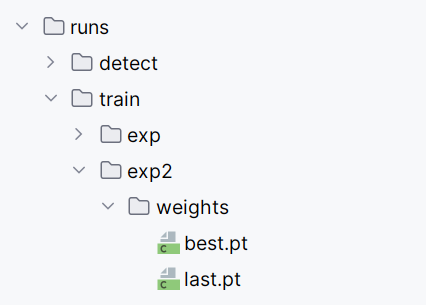
我们将上面训练好的模型取出best.pt吧,其为在迭代中遇到最好的模型了
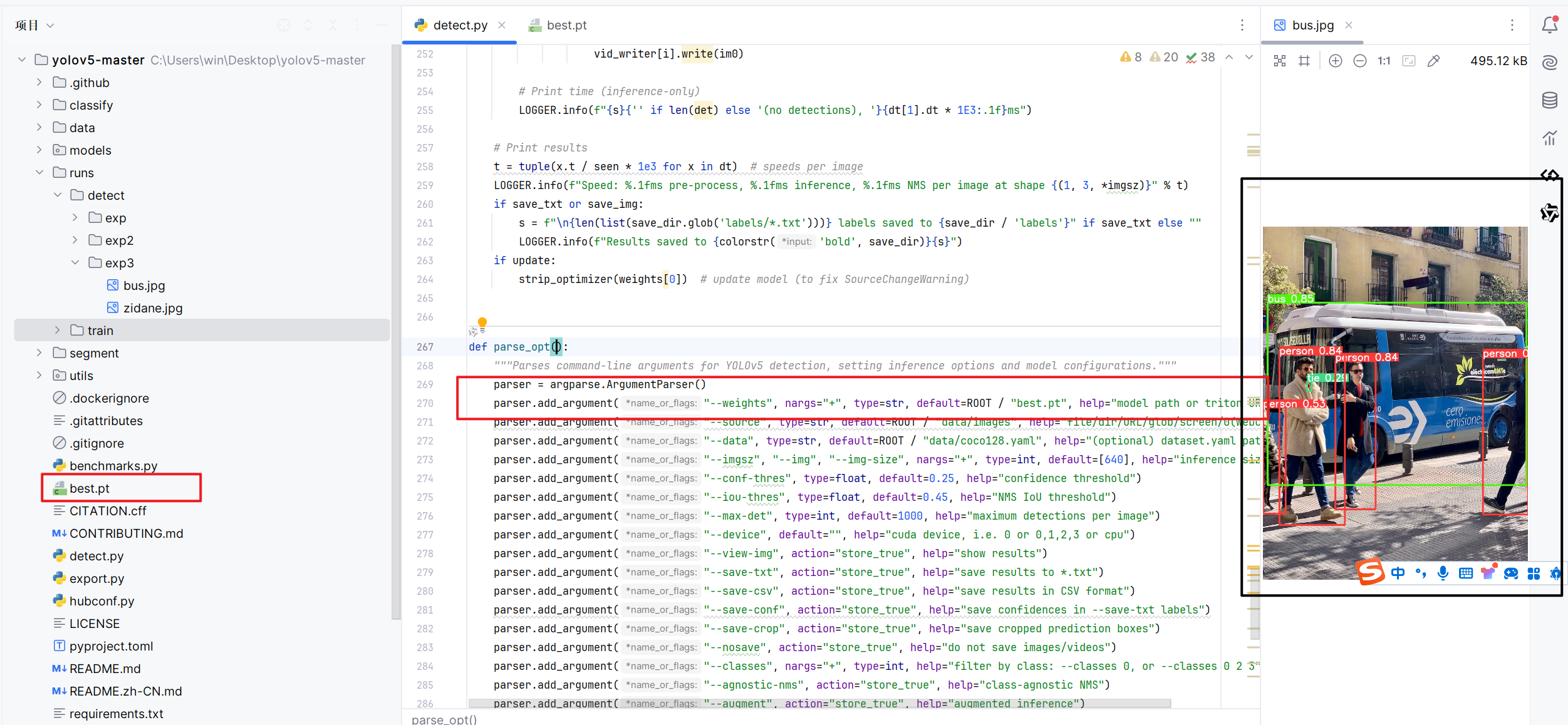
我们将模型取出放置在文件夹下,替换我们的模型
三、我们可以部署在安卓移动端 --tflite
在export.py中parse_opt改造一下
weights是需要被转化你的权重 imgsz是320才是被支持的
parser.add_argument("--data", type=str, default=ROOT / "data/coco128.yaml", help="dataset.yaml path")
parser.add_argument("--weights", nargs="+", type=str, default=ROOT / "这里是指定的模型名称.pt", help="model.pt path(s)")
parser.add_argument("--imgsz", "--img", "--img-size", nargs="+", type=int, default=[320, 320], help="image (h, w)")
parser.add_argument("--batch-size", type=int, default=1, help="batch size")
parser.add_argument("--device", default="0", help="cuda device, i.e. 0 or 0,1,2,3 or cpu")
parser.add_argument(
"--include",
nargs="+",
default=["tflite"],
help="torchscript, onnx, openvino, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle",
)同样的用官方的资源最终
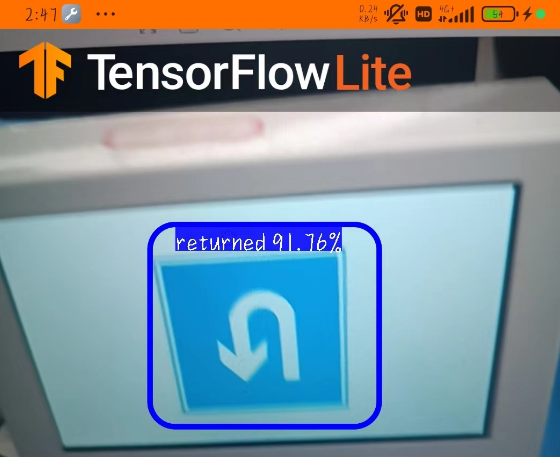
3.1 效果



![[Algorihm][简单多状态DP问题][买卖股票的最佳时机含冷冻期][买卖股票的最佳时机含手续费]详细讲解](https://img-blog.csdnimg.cn/direct/05f6e39d6ed2412f9876add4ce3e6342.png)