Spark概述

SparkStreaming概述
Spark Streaming 是 Apache Spark 生态系统中的一个组件,用于实时流数据处理。它允许用户通过流式计算引擎处理实时数据流,并以低延迟的方式对数据进行分析、处理和存储。
背景
- 在大数据领域,传统的批处理系统(如 Hadoop MapReduce)能够高效地处理大规模数据,但对于实时数据流的处理能力相对较弱。
- 随着互联网的快速发展和物联网设备的普及,越来越多的数据以实时流的形式产生,这就需要一种能够实时处理数据流的解决方案。
- 因此,出现了诸如 Apache Storm、Apache Flink 和 Spark Streaming 等流式处理框架。
Spark Streaming 的特点
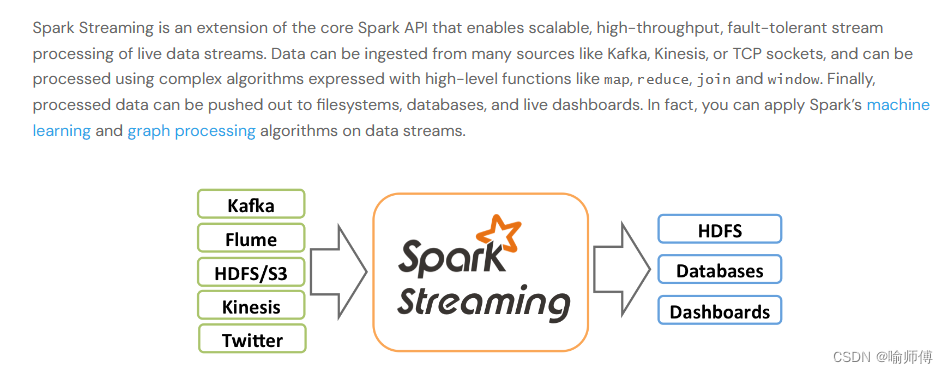
- 1.实时数据处理:Spark Streaming 可以实时处理来自各种数据源(如 Kafka、Flume、Kinesis 等)的数据流,进行实时计算和分析。
-
2.低延迟:相比传统的批处理系统,Spark Streaming 能够实现毫秒级的延迟,使得用户可以更快地获取和响应实时数据。
-
3.容错性:Spark Streaming 提供了高度的容错性,能够在节点故障时自动恢复,保证数据处理的可靠性和稳定性。

-
4.扩展性:通过 Spark 的弹性分布式计算模型,Spark Streaming 能够轻松地扩展到数千台节点,处理大规模的数据流。
-
5.易用性

-
6.易整合到Spark体系

Spark Streaming 的实现原理
-
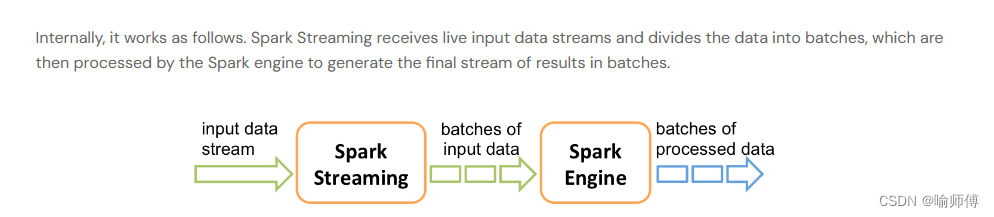
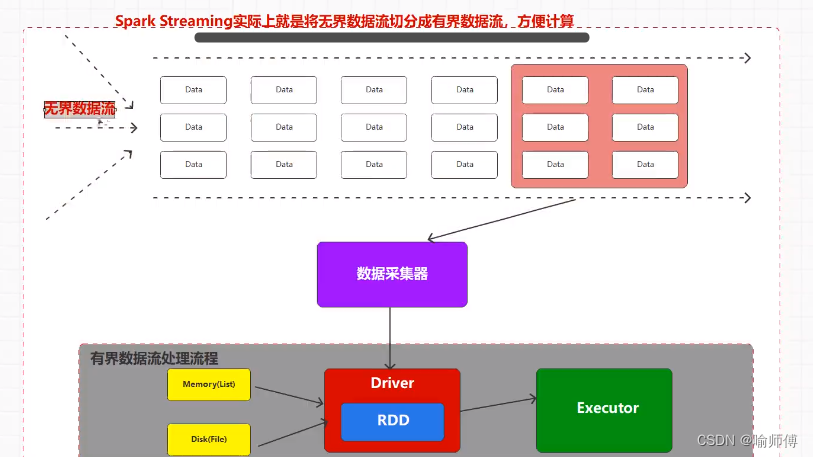
Spark Streaming 将实时数据流划分为一系列称为微批次(micro-batches)的小批量数据,在每个微批次内使用 Spark 引擎进行批处理计算。

-
这种微批次的方式使得 Spark Streaming 具有与批处理系统相似的编程模型,并且能够利用 Spark 引擎的优化和性能。


-
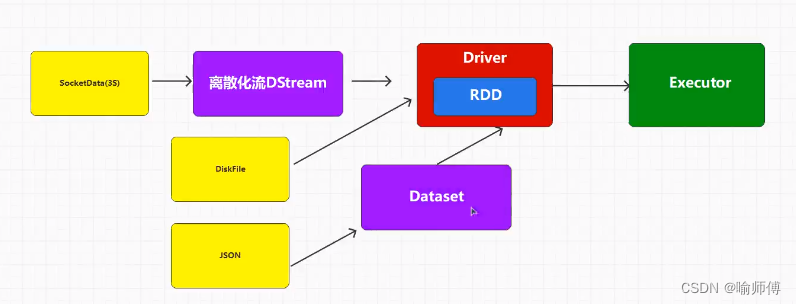
Spark Streaming 基于 DStream(Discretized Stream)抽象概念进行编程,DStream 表示连续的数据流,并提供了丰富的转换操作(如 map、reduce、join 等),使用户可以方便地对数据流进行处理。
-

官方文档
感兴趣的小伙伴可以去官网看看哦~
https://spark.apache.org/docs/latest/streaming-programming-guide.html