文章目录
- 一、分布式id介绍
- 1、什么是分布式id
- 2、分布式id的特点
- 二、UUid生成算法
- 1、JDK UUID
- 2、Snowflake 雪花算法
- 3、PearFlower 梨花算法
- 4、Mist 薄雾算法
- 三、常见发号器服务
- 1、数据库
- 1)自增
- 2)号段模式
- 2、NoSQL
- 四、常见框架
- 1、百度UIDGenerator
- 2、美团Leaf
- 2.1、Leaf-Segment 数据库号段
- 2.2、Leaf-Snowflake 雪花
- 3、滴滴TinyId
- 五、Java实战
一、分布式id介绍
1、什么是分布式id
业务需求中需要对各种数据使用id进行唯一标识。
分布式ID是在分布式系统下使用的唯一标识,它用于保证数据的一致性和唯一性。
在传统的单机环境下,可以使用自增主键或UUID来生成唯一的ID,但在分布式环境下,由于多个节点同时生成ID,可能会出现重复的情况。
因此,需要一种能够生成全局唯一ID的解决方案,这就是分布式ID。
2、分布式id的特点
- 全局唯一:在分布式环境下无论是在哪个节点生成的ID,都必须是全局唯一的,不能出现重复的情况
- 趋势递增:生成的分布式ID通常要求能够近似有序递增,有助于后续业务需求使用id记性排序。ID 的有序性可以提升数据库写入速度,如在数据库中使用B+Tree数据结构时,自增顺序写入的数据能够保持B+Tree的结构稳定,从而提高存取效率
- 高可用性:分布式ID生成系统需要保证在任何时候都能正确生成ID,即使在某些节点故障的情况下,整个系统仍能保持正常运行
- 高性能性:在分布式环境下,特别是在高并发场景下,分布式ID生成系统需要能够迅速、高效地生成ID,且对服务本身的本地资源消耗小,以满足业务需求。
- 信息安全:分布式ID的生成过程需要保证安全,不能被恶意用户推测出下一个ID,以防止可能的攻击,比如获取订单号,获取下载链接等
二、UUid生成算法
1、JDK UUID
JDK提供了现成的UUID生成方式,如下代码所示,包含了32个16进制的数字,以-分为五段,8-4-4-4-12
UUID uuid = UUID.randomUUID();
//输出示例:5c89a67d-4541-42d1-85e9-807bd93f065b
System.out.println(uuid);
JDK的版本不同,生成UUID的规则也不同,实现方式参考文档:
从源码角度分析UUID的实现原理
- 版本 1 : UUID 是根据时间和节点 ID(通常是 MAC 地址)生成;
- 版本 2 : UUID 是根据标识符(通常是组或用户 ID)、时间和节点 ID 生成;
- 版本 3、版本 5 : 通过散列(hashing)名字空间(namespace)标识符和名称生成;
- 版本 4 : UUID 使用随机性open in new window或伪随机性open in new window生成
优点:生成速度快,简单易用,一行代码搞定,本地生成,没有网络损耗
缺点:
- 存储空间消耗大: UUID 是一个 128 位的字符串,相比于传统的 32 位或 64 位整数 ID,它占用了更多的存储空间。这可能会增加数据库和存储系统的负担
- 可读性差: UUID 的格式通常是一长串的字符,可读性差
- 无序: 基于时间的 UUID 虽然具有一定的有序性,但由于其包含了时间戳、机器 MAC 地址和随机数等多个部分,因此并不完全按照时间顺序排列。这可能对于某些需要按时间顺序处理数据的场景造成不便
2、Snowflake 雪花算法

Snowflake算法描述:指定机器 & 同一时刻 & 某一并发序列,是唯一的。据此可生成一个64 bits的唯一ID(long)。默认采用上图字节分配方式,除了sign:1bit序号位不可调整外,其他的标识都可以根据实际情况做些调整。
- sign(1bit):固定1bit符号标识,表示正式,业务中常用于标识生成的UID为正数
- timestamp(41bit):用于表示时间戳,相对于某个时间基点的增量值,单位是毫秒,可以支持 (1L<<41)/1000L360024*365 ≈ 69年
- datacenter id + worker id (10bit):在分布式IDC环境下,一般用前5位标识机房id/大区id,后五位表示机器id,用来区分不同的集群/机房的节点,这样可以表示32个IDC,每个IDC下面可以有32个机器
- sequence(12bit):用来表示每毫秒下的并发序列,序列号为自增值,12个bit代表单台机器每毫秒能够生成2^12=4096个ID,理论上snowflake方案的QPS约为409.6w/s
- 可支持单业务单大区重启 2^17-1=131071次
优点:生成速度比较快,毫秒数在高位,自增序列号在低位,整体ID是趋势递增的,业务需要时可以加上业务ID
缺点:强依赖机器时钟,如果机器上时钟回拨(即服务器上的时间突然倒退回之前的时间),进而导致发号重复或者服务会处于不可用状态
3、PearFlower 梨花算法
雪花算法的改进方法,目标:解决雪花算法的时间回拨问题,秒级时间戳回避毫秒级时间回拨问题;随机段号降低相同机器ID造成的影响
原理
- 符号位:1位
- 时间:31位,精确到秒级,可以用68年
- 段号(批次号):3位 每秒可分为8个段
- 机器号:10位 最多支持1024台机器
- sequence:19位 可表示:0–524287
优化点
- 经过调整,时间只对秒灵敏,成功回避了服务器间几百毫秒的时间误差引起的时间回拨问题;
- 若第59秒的8个段号没有用完,则当润秒来临时,还可继续使用
- 可设置一定的秒数(如3秒)内提前消费。比如第10秒的号码,在800毫秒用完了,可以继续使用第11秒的号码。这样,下1秒用的号码不是很多时,就可以借给上1秒使用。
参考:分布式全局唯一ID生成算法(改进的雪花算法——解决时钟回拨问题) https://blog.csdn.net/abckingaa/article/details/106460583
4、Mist 薄雾算法

原理
- 第一段为最高位,占 1 位,保持为 0,使得值永远为正数;
- 第二段放置自增数,占 47 位,自增数在高位能保证结果值呈递增态势,遂低位可以为所欲为;
- 第三段放置随机因子一,占 8 位,上限数值 255,使结果值不可预测;
- 第四段放置随机因子二,占 8 位,上限数值 255,使结果值不可预测;
优点:递增态势、不依赖数据库、高性能;不受时间回拨的影响
缺点:程序重启会造成按序递增数值回到初始值,要借助存储在程序重启时恢复自增序列。
三、常见发号器服务
1、数据库
1)自增
原理:利用给字段设置auto_increment_increment和auto_increment_offset来保证ID自增
- 建表:
CREATE TABLE `sequence_id` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`stub` char(10) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
UNIQUE KEY `stub` (`stub`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
创建一张序号表,stub字段无实际意义,只是为了占位,便于我们插入或者修改数据。并且,给 stub 字段创建了唯一索引,保证其唯一性。
- SQL
BEGIN;
REPLACE INTO sequence_id (stub) VALUES ('stub');
SELECT LAST_INSERT_ID();
COMMIT;
DELETE FROM sequence_id WHERE id = LAST_INSERT_ID();
第一步:尝试把数据插入表中
第二步:如果主键或唯一索引的字段因出现重复数据而插入失败时,先从表中删除含有重复关键字的冲突行,然后再次尝试把数据插入表中。
优点
- 非常简单,利用现有数据库系统的功能实现,成本小,存储空间消耗小,有DBA专业维护
- ID号单调自增,可以实现一些对ID有特殊要求的业务
缺点
- 支持的并发量不大, 强依赖DB,当DB异常时整个系统不可用,属于致命问题,配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证,主从切换时的不一致可能会导致重复发号。
- 存在数据库单点问题,ID发号性能瓶颈限制在单台MySQL的读写性能 ,可以用数据库集群解决,不过增加了系统复杂度。如在分布式系统中每台机器设置不同的id初始值,且步长和机器数相等,不过系统维护困难,系统水平扩展比较困难,比如定义好了步长和机器台数之后,不容易扩展
- 数据库压力大,每次获取ID都得读写一次数据库,只能靠堆机器来提高性能
- ID没有具体的业务含义,而且存在安全问题,自增的订单ID存在规律,可以推测出业务数据,比如每天订单量等
2)号段模式
原理:
从数据库批量的获取自增ID,每次从数据库取出一个号段范围,例如 (1,1000] 代表1000个ID,具体的业务服务将使用本号段,生成1~1000的自增ID并加载到内存,从内存获取速度很快
- 建表
CREATE TABLE `sequence_id_generator` (
`id` int(10) NOT NULL,
`current_max_id` bigint(20) NOT NULL COMMENT '当前最大id',
`step` int(10) NOT NULL COMMENT '号段的长度',
`version` int(20) NOT NULL COMMENT '版本号',
`biz_type` int(20) NOT NULL COMMENT '业务类型',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
biz_type :代表不同业务类型
current_max_id:当前最大的可用id
step :代表号段的长度
version :是一个乐观锁,每次都更新version,保证并发时数据的正确性
current_max_id 字段和step字段主要用于获取批量 ID,获取的批量 id 为:current_max_id ~ current_max_id+step。
- 先新增一行数据
INSERT INTO `sequence_id_generator` (`id`, `current_max_id`, `step`, `version`, `biz_type`)
VALUES
(1, 0, 100, 0, 101);
- 通过 SELECT 获取指定业务下的批量唯一 ID
UPDATE sequence_id_generator SET current_max_id = current_max_id +step, version=version+1 WHERE version = 0 AND `biz_type` = 101
SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `biz_type` = 101
结果:id current_max_id step version biz_type
1 100 100 1 101
- update current_max_id = current_max_id + step,update成功则说明新号段获取成功,新的号段范围是(current_max_id ,max_id +step]
- update id_generator set max_id = #{max_id+step}, version = version + 1 where version = # {version} and biz_type = XXX
- 由于多业务端可能同时操作,所以采用版本号version乐观锁方式更新,这种分布式ID生成方式不强依赖于数据库,不会频繁的访问数据库,对数据库的压力小很多
- 不够用的话,更新之后重新 SELECT 即可。
等这批号段ID用完,再次向数据库申请新号段,对current_max_id 字段做一次update操作
优点:比于数据库主键自增的方式,数据库的号段模式对于数据库的访问次数更少,数据库压力更小,存储消耗空间更小
缺点:跟自增模式类型,同样存在数据库单点问题、ID 没有具体业务含义、安全问题、
2、NoSQL
以使用Redis为主,原理就是利用redis的 incr命令实现ID的原子性自增。
127.0.0.1:6379> set seq_id 1 // 初始化自增ID为1
OK
127.0.0.1:6379> incr seq_id // 增加1,并返回递增后的数值
(integer) 2
要考虑到redis持久化的问题,避免重启机器或者机器故障后数据丢失。redis有两种持久化方式RDB和AOF。
- RDB会定时打一个快照进行持久化,假如连续自增但redis没及时持久化,而这会Redis挂掉了,重启Redis后会出现ID重复的情况。
- AOF会对每条写命令进行持久化,即使Redis挂掉了也不会出现ID重复的情况,但由于incr命令的特殊性,会导致Redis重启恢复的数据时间过长。
优点:通过Redis的INCR/INCRBY自增原子操作命令,能保证生成的ID肯定是唯一有序的,本质上实现方式与数据库一致,整体吞吐量比数据库要高
缺点:跟数据库自增模式的缺点类型,因为强依赖存储,Redis实例或集群宕机后服务依然不可用。
四、常见框架
1、百度UIDGenerator

百度的框架是基于雪花算法的,官方文档:UidGenerator 的官方介绍
- sign(1bit):固定1bit符号标识,即生成的UID为正数。
- delta seconds (28 bits):当前时间,相对于时间基点"2016-05-20"的增量值,单位:秒,最多可支持约8.7年
- worker id (22 bits):机器id,最多可支持约420w次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略。
-sequence (13 bits):每秒下的并发序列,13 bits可支持每秒8192个并发。
2、美团Leaf
官方文档:Leaf——美团点评分布式ID生成系统
提供了 号段模式 和 Snowflake(雪花算法) 这两种模式来生成分布式 ID。
2.1、Leaf-Segment 数据库号段
原理如上述发号器服务模式的 数据库号段模式类似。在使用原有数据库号段的方案上,做了一些改变,各个业务不同的发号需求用biz_tag字段来区分,每个biz-tag的ID获取相互隔离,互不影响
如果以后有性能需求需要对数据库扩容,不需要上述描述的复杂的扩容操作,只需要对biz_tag分库分表就行。
优点
- Leaf服务可以很方便的线性扩展,性能完全能够支撑大多数业务场景
- ID号码是趋势递增的8byte的64位数字,满足上述数据库存储的主键要求
- 容灾性高:Leaf服务内部有号段缓存,即使DB宕机,短时间内Leaf仍能正常对外提供服务
- 可以自定义max_id的大小,非常方便业务从原有的ID方式上迁移过来
缺点
- ID号码不够随机,能够泄露发号数量的信息,不太安全
- TP999数据波动大,当号段使用完之后还是会hang在更新数据库的I/O上,tg999数据会出现偶尔的尖刺
- DB宕机会造成整个系统不可用
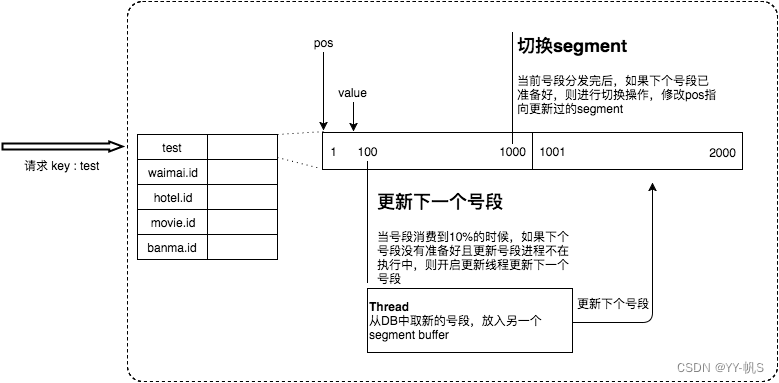
双buffer优化
对于第二个缺点,Leaf服务作出了双buffer优化方案,服务内部有两个号段缓存区segment。当前号段已下发10%时,如果下一个号段未更新,则另启一个更新线程去更新下一个号段。避免获取 DB 在获取号段的时候阻塞请求获取 ID 的线程。简单来说,就是我一个号段还没用完之前,我自己就主动提前去获取下一个号段
当前号段全部下发完后,如果下个号段准备好了则切换到下个号段为当前segment接着下发,循环往复
每个biz-tag都有消费速度监控,通常推荐segment长度设置为服务高峰期发号QPS的600倍(10分钟),这样即使DB宕机,Leaf仍能持续发号10-20分钟不受影响
每次请求来临时都会判断下个号段的状态,从而更新此号段,所以偶尔的网络抖动不会影响下个号段的更新
2.2、Leaf-Snowflake 雪花
完全沿用雪花算法的bit位设计“1+41+10+12”组装ID号。
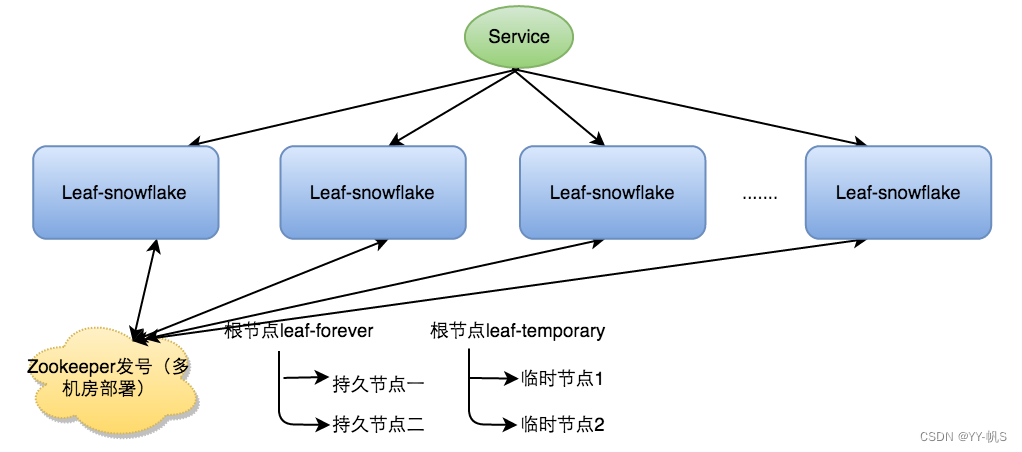
对于workerID的分配,当服务集群数量较小的情况下,完全可以手动配置;服务规模较大,使用Zookeeper持久顺序节点的特性自动对snowflake节点配置wokerID。
启动方案
- 启动Leaf-snowflake服务,连接Zookeeper,在leaf_forever父节点下检查自己是否已经注册过(是否有该顺序子节点)
- 如果有注册过直接取回自己的workerID(zk顺序节点生成的int类型ID号),启动服务
- 如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的workerID号,启动服务
弱依赖ZooKeeper
除了每次会去ZK拿数据以外,也会在本机文件系统上缓存一个workerID文件。当ZooKeeper出现问题,恰好机器出现问题需要重启时,能保证服务能够正常启动。这样做到了对三方组件的弱依赖。一定程度上提高了SLA
解决时钟问题
服务启动时首先检查自己是否写过ZooKeeper leaf_forever节点
- 若写过,则用自身系统时间与leaf_forever/${self}节点记录时间做比较,若小于leaf_forever/${self}时间则认为机器时间发生了大步长回拨,服务启动失败并报警
- 若未写过,证明是新服务节点,直接创建持久节点leaf_forever/${self}并写入自身系统时间,接下来综合对比其余Leaf节点的系统时间来判断自身系统时间是否准确,具体做法是取leaf_temporary下的所有临时节点(所有运行中的Leaf-snowflake节点)的服务IP:Port,然后通过RPC请求得到所有节点的系统时间,计算sum(time)/nodeSize。
- 若abs( 系统时间-sum(time)/nodeSize ) < 阈值,认为当前系统时间准确,正常启动服务,同时写临时节点leaf_temporary/${self} 维持租约
- 否则认为本机系统时间发生大步长偏移,启动失败并报警
- 每隔一段时间(3s)上报自身系统时间写入leaf_forever/${self}
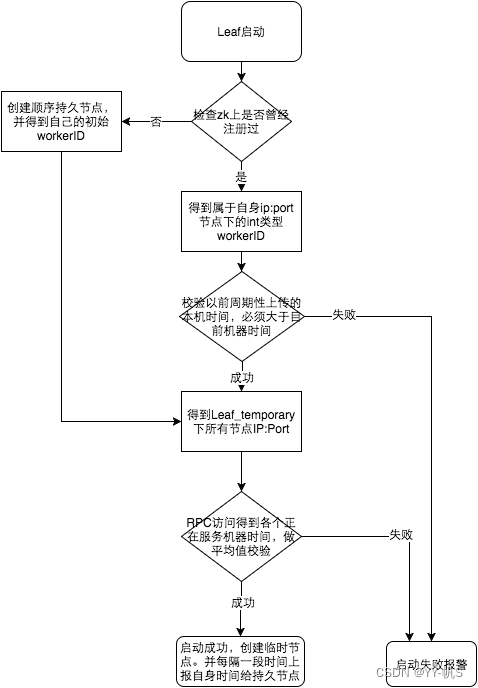
由于强依赖时钟,对时间的要求比较敏感,在机器工作时NTP同步也会造成秒级别的回退,建议可以直接关闭NTP同步。要么在时钟回拨的时候直接不提供服务直接返回ERROR_CODE,等时钟追上即可。或者做一层重试,然后上报报警系统,更或者是发现有时钟回拨之后自动摘除本身节点并报警
3、滴滴TinyId
滴滴开源的一款基于数据库号段模式的ID生成器,方案也类似Leaf-Segment,具体文档参考:tinyid官方原理介绍
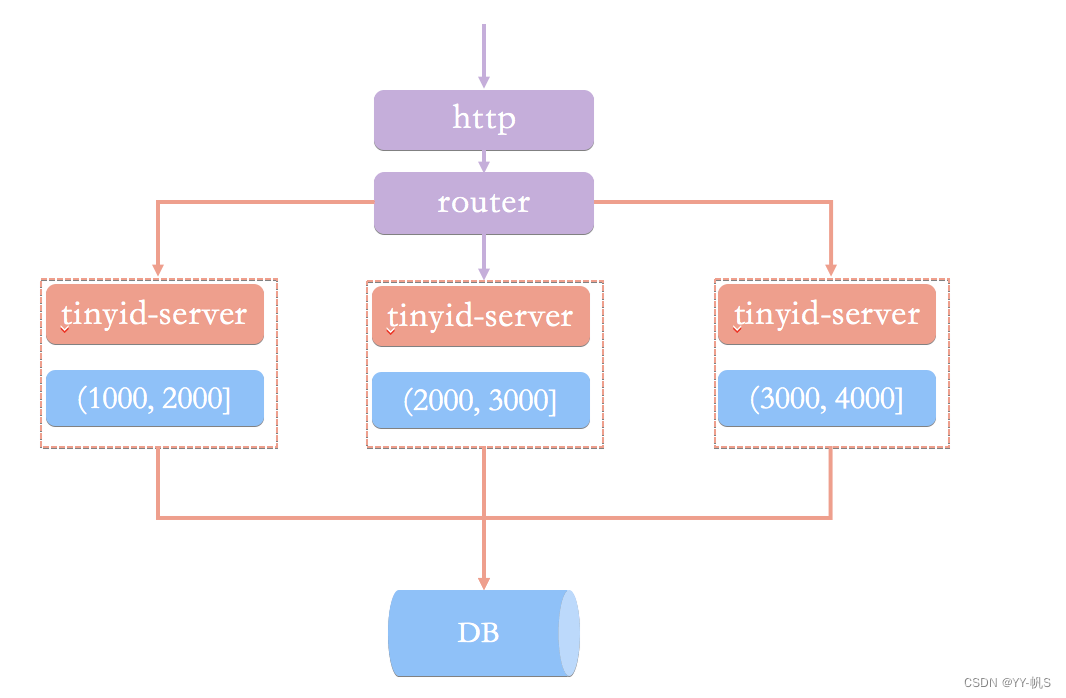
通过 HTTP 请求向发号器服务申请唯一 ID。负载均衡 router 会把我们的请求送往其中的一台 tinyid-server
相比于基于数据库号段模式的简单架构方案,Tinyid 方案主要做了下面这些优化:
- 双号段缓存:为了避免在获取新号段的情况下,程序获取唯一 ID 的速度比较慢。 Tinyid 中的号段在用到一定程度的时候,就会去异步加载下一个号段,保证内存中始终有可用号段。
- 增加多 db 支持:支持多个 DB,并且,每个 DB 都能生成唯一 ID,提高了可用性。
- 增加 tinyid-client:纯本地操作,无 HTTP 请求消耗,性能和可用性都有很大提升。
五、Java实战
模拟Leaf-Snowflake,改为利用redis分配workId
- sign(1bit):固定1bit符号标识,即生成的UID为正数。
- delta seconds (31 bits):当前时间,相对于时间基点的增量值,单位:秒,可用2^31-1=2147483647/86400/365=68.1年
- region id(2 bit):大区id ,区分欧美亚三个大区
- worker id (17 bits):机器id ,可支持单业务单大区重启 2^17-1=131071次
- sequence (13 bits):每秒下的并发序列,13 bits可支持每秒8192个并发。
优化点:
- 使用更加常用的redis分配workid,服务更加轻量级
- 自定义起始时间,理论上服务没有使用年限限制
- 服务内部判断时间回拨,判断序列号使用完,若使用完则等待至下一秒,使用下一秒的序列号
示例代码
1、分配workerId
@Slf4j
public class RedisWorkerIdAssigner implements WorkerIdAssigner {
private RedisTemplate<String, String> redis;
@Autowired
private Environment environment;
public RedisWorkerIdAssigner(RedisTemplate<String, String> redis) {
this.redis = redis;
}
@Override
public long assignWorkerId(WorkerIdAssignerProperties workerIdAssignerParam) {
String ip = NetUtils.getLocalAddress();
String port = environment.getProperty("server.port");
log.info("ip:{},port:{}", ip, port);
WorkerNodeInfo workerNodeInfo = WorkerNodeInfo.builder()
.ip(ip)
.port(port)
.build();
log.info("workerNodeInfo:{}", workerNodeInfo);
long machineId = 0;
if (null == ip || redis == null) {
log.warn("can not get localhost");
/**
* 抛异常
*/
throw new IdGenerateException("can not get localhost ip");
} else {
boolean getLock = false;
int count = 0;
// 不断尝试获取锁 最多尝试15次 30S
String idKeyLock = SpiderIdKey.getLockKey(workerNodeInfo, workerIdAssignerParam);
while (!getLock) {
getLock = redis.opsForHash().increment(idKeyLock, "LOCK", 1) == 1;
if (!getLock) {
try {
Thread.sleep(500);
} catch (Exception e) {
}
count++;
log.info("IdConfig initIdService message : try to get lock from redis... ");
if (count > 15) {
throw new IdGenerateException("can not get Lock from redis");
}
}
}
if (getLock) {
// 查询本机是否有值
String workerIdKey = SpiderIdKey.getWorkerIdKey(workerNodeInfo, workerIdAssignerParam);
String redisValue = redis.opsForValue().get(workerIdKey);
if (null == redisValue) {
// 本机无值 遍历hash value 赋予新值
Long now = redis.opsForValue().increment(SpiderIdKey.getBizWorkerIncKey(workerIdAssignerParam));
redis.opsForValue().set(workerIdKey, String.valueOf(now));
machineId = now;
} else {
// 本机有值 即可能为服务重启
machineId = Long.parseLong(redisValue);
}
if (getLock) {
expire(idKeyLock, 1L);
}
}
}
return machineId;
}
public boolean expire(String key, Long expireTime) {
return Optional.ofNullable(redis.expire("#hash:" + key, expireTime, TimeUnit.SECONDS)).orElse(false);
}
}
2、获取ID:
@Slf4j
public class WebLiveCommonDefaultIdGenerator implements IdGenerator, InitializingBean {
/**
*
*
* Bits allocate
*/
/**
* 默认可以使用68年
* 2^31-1=2147483647/86400/365=68.1
*/
protected int timeBits = 31;
protected int regionBits = 2;
/**
* 2^17=131072-1=131071;
*/
protected int workerBits = 17;
/**
* 2^13=8192
*/
protected int seqBits = 13;
protected WorkerIdAssignerProperties workerIdAssignerProperties;
/**
* Customer epoch, unit as second. For example 2016-05-20 (ms: 1463673600000)
* <p>
* 开始时间
*/
protected String epochStr = "2023-04-04";
protected long epochSeconds = TimeUnit.MILLISECONDS.toSeconds(DateUtils.parseByDayPattern(epochStr).getTime());
/**
* Stable fields after spring bean initializing
*/
protected BitsAllocator bitsAllocator;
protected long workerId;
protected long regionId;
/**
* Volatile fields caused by nextId()
*/
protected long sequence = 0L;
protected long lastSecond = -1L;
protected WorkerIdAssigner workerIdAssigner;
private WebLiveCommonAlarmService webLiveCommonAlarmService;
@Override
public void afterPropertiesSet() throws Exception {
// initialize bits allocator
bitsAllocator = new BitsAllocator(timeBits, regionBits, workerBits, seqBits);
String bizTag = workerIdAssignerProperties.getBizTag();
if (StringUtils.isBlank(bizTag)) {
throw new IdGenerateException("bizTag is null");
}
//bizTag 长度不超过40
if (bizTag.length() > 40) {
throw new IdGenerateException("bizTag is too long");
}
// bizTag正则表达式校验,字母数字下划线中划线 ^[a-zA-Z0-9_-]+$
if (!bizTag.matches("^[a-zA-Z0-9_-]+$")) {
throw new IdGenerateException("bizTag is not match regex ^[a-zA-Z0-9_-]+$");
}
if (Objects.nonNull(workerIdAssignerProperties.getRegionId())) {
regionId = workerIdAssignerProperties.getRegionId();
}
if (Objects.nonNull(workerIdAssignerProperties.getWorkerBits())) {
workerBits = workerIdAssignerProperties.getWorkerBits();
}
if (Objects.nonNull(workerIdAssignerProperties.getSeqBits())) {
seqBits = workerIdAssignerProperties.getSeqBits();
}
if (Objects.nonNull(workerIdAssignerProperties.getTimeBits())) {
timeBits = workerIdAssignerProperties.getTimeBits();
}
if (Objects.nonNull(workerIdAssignerProperties.getRegionBits())) {
regionBits = workerIdAssignerProperties.getRegionBits();
}
if (regionId < 0 || workerBits < 0 || seqBits < 0 || timeBits < 0 || regionBits < 0) {
throw new IdGenerateException("regionId,workerBits,seqBits,timeBits,regionBits must be positive");
}
if (StringUtils.isNotBlank(workerIdAssignerProperties.getEpochStr())) {
epochStr = workerIdAssignerProperties.getEpochStr();
epochSeconds = TimeUnit.MILLISECONDS.toSeconds(DateUtils.parseByDayPattern(epochStr).getTime());
//校验epochSeconds不能大于当前时间 epochSeconds<当前时间
if (epochSeconds > TimeUnit.MILLISECONDS.toSeconds(new Date().getTime())) {
throw new IdGenerateException("epochSeconds is bigger than current time");
}
}
if (regionId == 0) {
regionId = ServerInfoUtil.getRegionCode();
}
workerIdAssignerProperties.setRegionId(regionId);
workerId = workerIdAssigner.assignWorkerId(workerIdAssignerProperties);
if (workerId > bitsAllocator.getMaxWorkerId()) {
// 告警一下吧 然后重新分配
webLiveCommonAlarmService.errorMultiAlarm(60, 1001, "bitsAllocator",
"bitsAllocator over max worker id,workId:{},bizTag:{}", workerId, bizTag);
log.warn("bitsAllocator over max worker id,workId:{},bizTag:{}", workerId, bizTag);
workerId = workerId % bitsAllocator.getMaxWorkerId();
}
log.info("Initialized bits(1,{}, {}, {}, {}) for workerID:{}", timeBits, regionBits, workerBits, seqBits, workerId);
}
/**
* Setters for spring property
*/
public void setWorkerIdAssigner(WorkerIdAssigner workerIdAssigner) {
this.workerIdAssigner = workerIdAssigner;
}
public void setWebLiveCommonAlarmService(WebLiveCommonAlarmService webLiveCommonAlarmService) {
this.webLiveCommonAlarmService = webLiveCommonAlarmService;
}
public long getNextId() throws IdGenerateException {
try {
return nextId();
} catch (Exception e) {
throw new IdGenerateException(e);
}
}
/**
* Get UID
*
* @return UID
* @throws IdGenerateException in the case: Clock moved backwards; Exceeds the max timestamp
*/
protected synchronized long nextId() {
long currentSecond = getCurrentSecond();
// Clock moved backwards, refuse to generate uid
if (currentSecond < lastSecond) {
long refusedSeconds = lastSecond - currentSecond;
throw new IdGenerateException("Clock moved backwards. Refusing for %d seconds", refusedSeconds);
}
// At the same second, increase sequence
if (currentSecond == lastSecond) {
sequence = (sequence + 1) & bitsAllocator.getMaxSequence();
// Exceed the max sequence, we wait the next second to generate uid
if (sequence == 0) {
currentSecond = getNextSecond(lastSecond);
}
// At the different second, sequence restart from zero
} else {
sequence = 0L;
}
lastSecond = currentSecond;
// Allocate bits for UID
return bitsAllocator.allocate(currentSecond - epochSeconds, regionId, workerId, sequence);
}
/**
* Get next millisecond
*/
private long getNextSecond(long lastTimestamp) {
long timestamp = getCurrentSecond();
while (timestamp <= lastTimestamp) {
timestamp = getCurrentSecond();
}
return timestamp;
}
/**
* Get current second
*/
private long getCurrentSecond() {
long currentSecond = TimeUnit.MILLISECONDS.toSeconds(System.currentTimeMillis());
if (currentSecond - epochSeconds > bitsAllocator.getMaxDeltaSeconds()) {
throw new IdGenerateException("Timestamp bits is exhausted. Refusing UID generate. Now: " + currentSecond);
}
return currentSecond;
}
public void setWorkerIdAssignerProperties(WorkerIdAssignerProperties workerIdAssignerProperties) {
this.workerIdAssignerProperties = workerIdAssignerProperties;
}
@Override
public String parseID(long id) {
long totalBits = BitsAllocator.TOTAL_BITS;
long signBits = bitsAllocator.getSignBits();
long timestampBits = bitsAllocator.getTimestampBits();
long regionIdBits = bitsAllocator.getRegionIdBits();
long workerIdBits = bitsAllocator.getWorkerIdBits();
long sequenceBits = bitsAllocator.getSequenceBits();
// parse UID
long sequence = (id << (totalBits - sequenceBits)) >>> (totalBits - sequenceBits);
long workerId = (id << (timestampBits + signBits + regionIdBits)) >>> (totalBits - workerIdBits);
long regionId = (id << (timestampBits + signBits)) >>> (totalBits - regionIdBits);
long deltaSeconds = id >>> (workerIdBits + regionIdBits + sequenceBits);
Date thatTime = new Date(TimeUnit.SECONDS.toMillis(epochSeconds + deltaSeconds));
String thatTimeStr = DateUtils.formatByDateTimePattern(thatTime);
// format as string
return String.format("{\"WebLiveCommonId\":\"%d\",\"timestamp\":\"%s\",\"regionId\":\"%d\",\"workerId\":\"%d\",\"sequence\":\"%d\"}",
id, thatTimeStr, regionId, workerId, sequence);
}
}
public class BitsAllocator {
/**
* Total 64 bits
*/
public static final int TOTAL_BITS = 1 << 6;
/**
* Bits for [sign-> second-> workId-> sequence]
*/
private int signBits = 1;
private final int timestampBits;
private final int regionIdBits;
private final int workerIdBits;
private final int sequenceBits;
/**
* Max value for workId & sequence
*/
private final long maxDeltaSeconds;
private final long maxWorkerId;
private final long maxSequence;
/**
* Shift for timestamp & workerId
*/
private final int timestampShift;
private final int regionIdShift;
private final int workerIdShift;
/**
* Constructor with timestampBits, workerIdBits, sequenceBits<br>
* The highest bit used for sign, so <code>63</code> bits for timestampBits, workerIdBits, sequenceBits
*/
public BitsAllocator(int timestampBits, int regionIdBits, int workerIdBits, int sequenceBits) {
// make sure allocated 64 bits
int allocateTotalBits = signBits + timestampBits + regionIdBits + workerIdBits + sequenceBits;
Assert.isTrue(allocateTotalBits == TOTAL_BITS, "allocate not enough 64 bits");
// initialize bits
this.timestampBits = timestampBits;
this.regionIdBits = regionIdBits;
this.workerIdBits = workerIdBits;
this.sequenceBits = sequenceBits;
// initialize max value
this.maxDeltaSeconds = ~(-1L << timestampBits);
this.maxWorkerId = ~(-1L << workerIdBits);
this.maxSequence = ~(-1L << sequenceBits);
// initialize shift
this.timestampShift = workerIdBits + sequenceBits + regionIdBits;
this.regionIdShift = workerIdBits + sequenceBits;
this.workerIdShift = sequenceBits;
}
/**
* Allocate bits for UID according to delta seconds & workerId & sequence<br>
* <b>Note that: </b>The highest bit will always be 0 for sign
*
* @param deltaSeconds
* @param workerId
* @param sequence
* @return
*/
public long allocate(long deltaSeconds, long regionId, long workerId, long sequence) {
return (deltaSeconds << timestampShift) | (regionId << regionIdShift) | (workerId << workerIdShift) | sequence;
}
/**
* Getters
*/
public int getSignBits() {
return signBits;
}
public int getTimestampBits() {
return timestampBits;
}
public int getWorkerIdBits() {
return workerIdBits;
}
public int getSequenceBits() {
return sequenceBits;
}
public int getRegionIdBits() {
return regionIdBits;
}
public long getMaxDeltaSeconds() {
return maxDeltaSeconds;
}
public long getMaxWorkerId() {
return maxWorkerId;
}
public long getMaxSequence() {
return maxSequence;
}
public int getTimestampShift() {
return timestampShift;
}
public int getWorkerIdShift() {
return workerIdShift;
}
public int getRegionIdShift() {
return regionIdShift;
}
@Override
public String toString() {
return ToStringBuilder.reflectionToString(this, ToStringStyle.SHORT_PREFIX_STYLE);
}
}