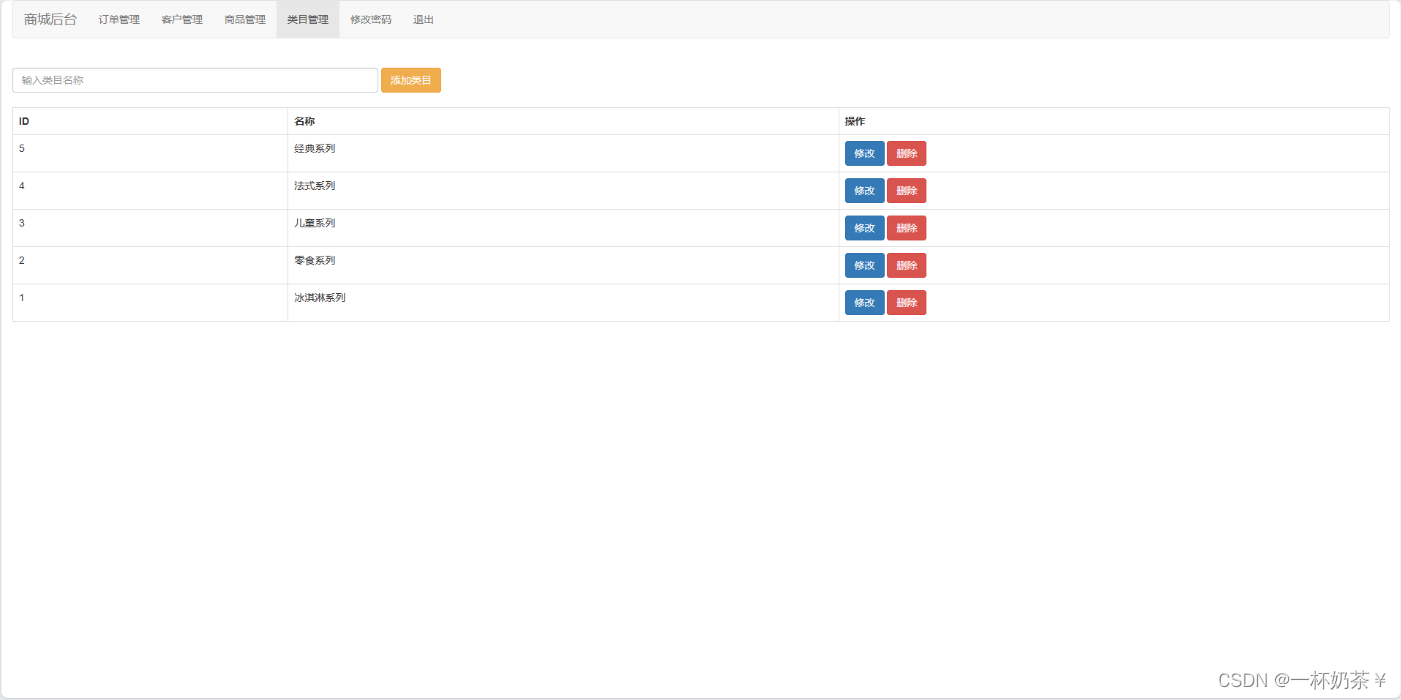
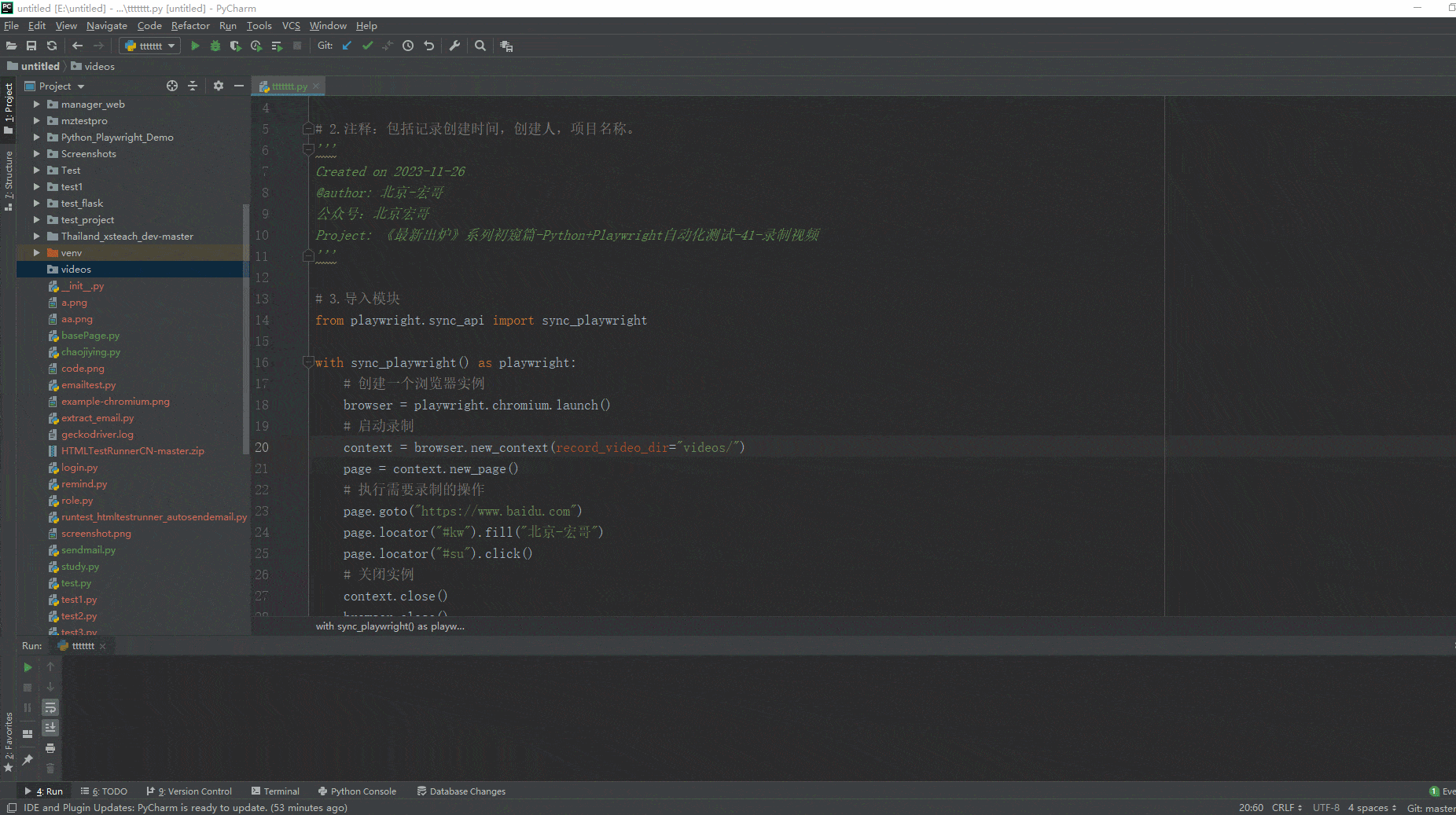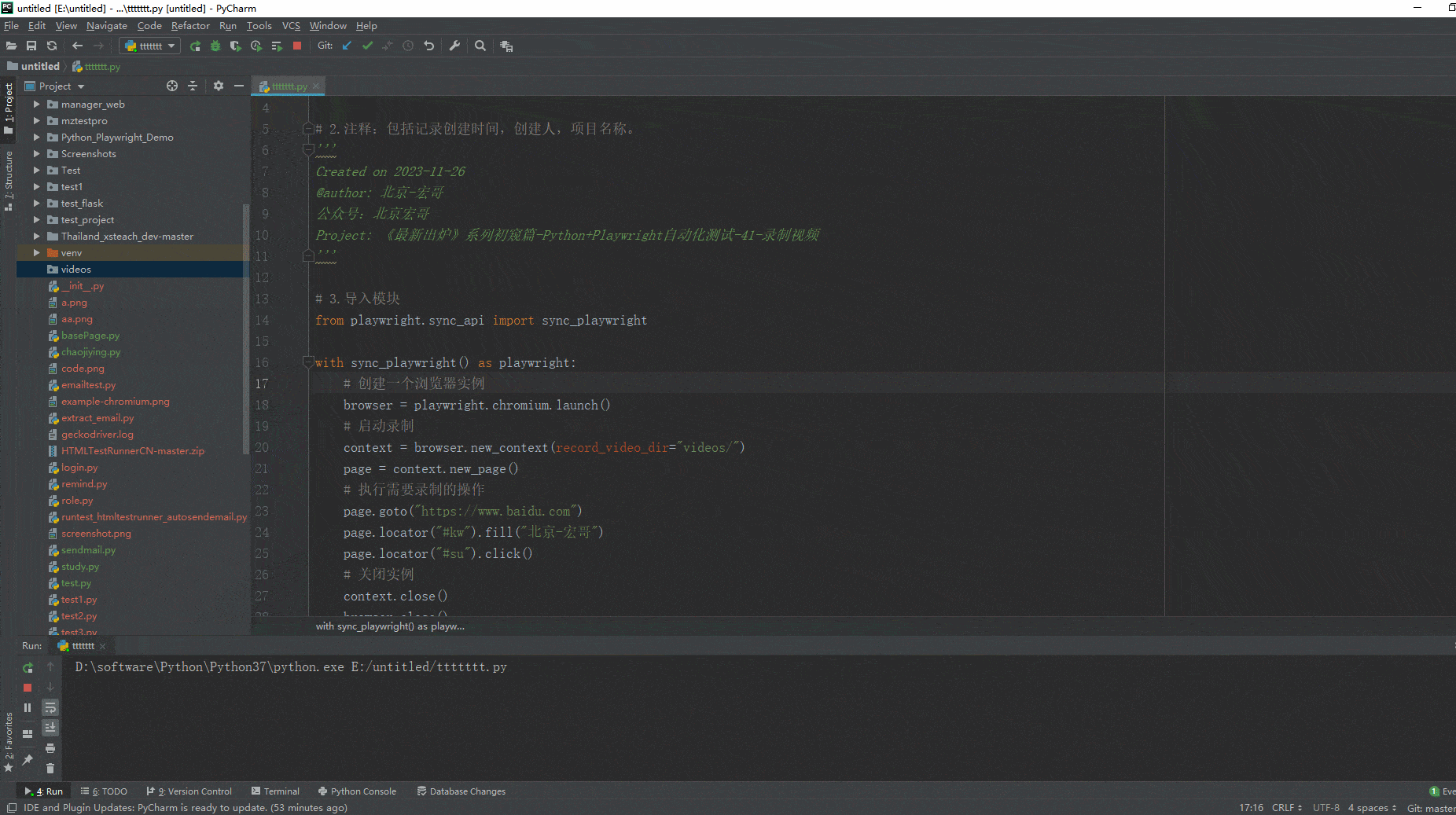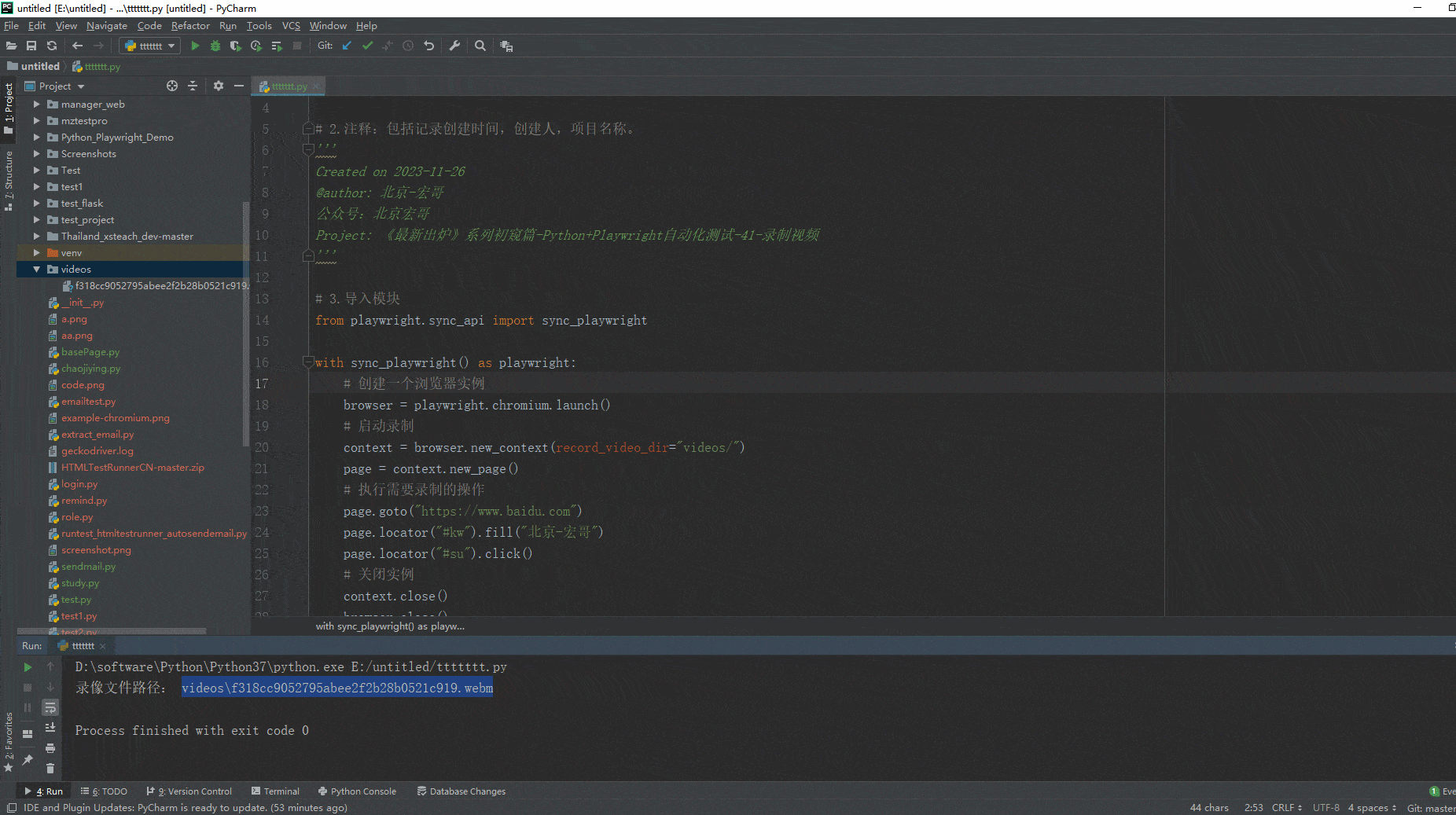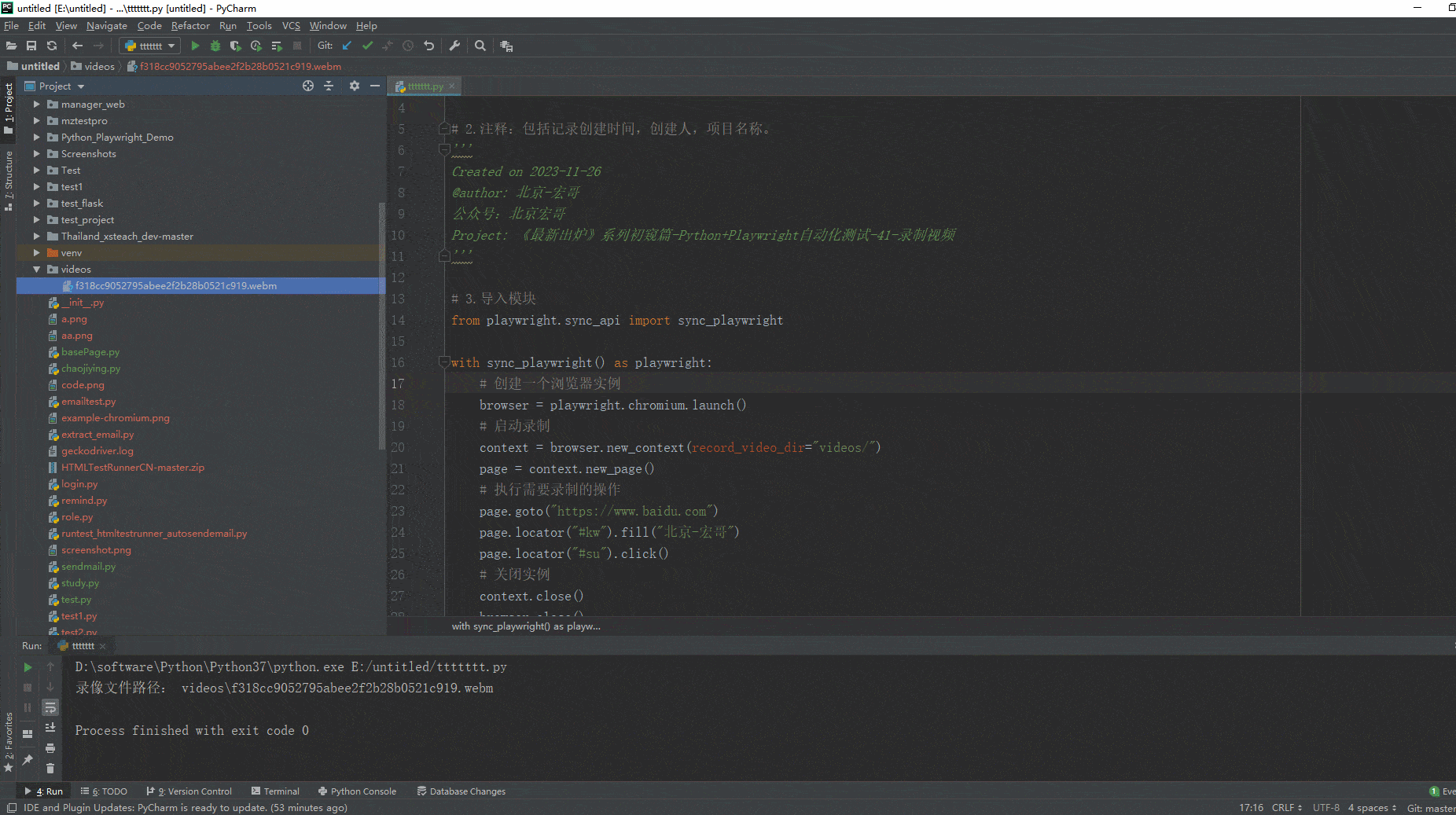
如何使用hadoop客户端
public class testCreate {
public static void main(String[] args) throws IOException {
System.setProperty("HADOOP_USER_NAME", "hdfs");
String pathStr = "/home/hdp/shanshajia";
Path path = new Path(pathStr);
Configuration configuration = new HdfsConfiguration();
FileSystem fs = path.getFileSystem(configuration);
}
}一般我们会这么使用,那么问题来了,FileSystem是个抽象类,我们到底用哪一个呢?或者说jvm怎么知道我们要加载哪些FileSystem的实现类呢?
Java SPI机制
SPI 全称 Service Provider Interface ,是 Java 提供的一套用来被第三方实现或者扩展的 API,它可以用来启用框架扩展和替换组件。

Java SPI 实际上是 基于接口的编程+策略模式+配置文件 组合实现的动态加载机制。
Java SPI 就是提供这样的一个机制:为某个接口寻找服务实现的机制。
将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要。
所以 SPI 的核心思想就是解耦
Hadoop 客户端 SPI
当我们第一次视图创建一个FileSystem,会调用createFileSystem
private static FileSystem createFileSystem(URI uri, Configuration conf
) throws IOException {
Tracer tracer = FsTracer.get(conf);
TraceScope scope = null;
if (tracer != null) {
scope = tracer.newScope("FileSystem#createFileSystem");
scope.addKVAnnotation("scheme", uri.getScheme());
}
try {
Class<?> clazz = getFileSystemClass(uri.getScheme(), conf);
if (clazz == null) {
throw new IOException("No FileSystem for scheme: " + uri.getScheme());
}
FileSystem fs = (FileSystem)ReflectionUtils.newInstance(clazz, conf);
fs.tracer = tracer;
fs.initialize(uri, conf);
return fs;
} finally {
if (scope != null) scope.close();
}
} public static Class<? extends FileSystem> getFileSystemClass(String scheme,
Configuration conf) throws IOException {
if (!FILE_SYSTEMS_LOADED) {
loadFileSystems();
}
Class<? extends FileSystem> clazz = null;
if (conf != null) {
clazz = (Class<? extends FileSystem>) conf.getClass("fs." + scheme + ".impl", null);
}
if (clazz == null) {
clazz = SERVICE_FILE_SYSTEMS.get(scheme);
}
if (clazz == null) {
throw new IOException("No FileSystem for scheme: " + scheme);
}
return clazz;
}1、尝试使用配置的fs
<property>
<name>fs.hdfs.impl</name>
<value>DistributedFileSystem</value>
</property>2、如果配置里没有,这个时候用加载的
hadoop-hdfs-project/hadoop-hdfs/src/main/resources/META-INF/services,可以看到,这个目录下有一个org.apache.hadoop.fs.FileSystem文件
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
org.apache.hadoop.hdfs.DistributedFileSystem
org.apache.hadoop.hdfs.web.HftpFileSystem
org.apache.hadoop.hdfs.web.HsftpFileSystem
org.apache.hadoop.hdfs.web.WebHdfsFileSystem
org.apache.hadoop.hdfs.web.SWebHdfsFileSystem通过 loadFileSystems这个方法会加载文件中的所有类,并且根据scheme生成一个map,key是scheme,value是fs
private static void loadFileSystems() {
synchronized (FileSystem.class) {
if (!FILE_SYSTEMS_LOADED) {
ServiceLoader<FileSystem> serviceLoader = ServiceLoader.load(FileSystem.class);
Iterator<FileSystem> it = serviceLoader.iterator();
while (it.hasNext()) {
FileSystem fs = null;
try {
fs = it.next();
try {
SERVICE_FILE_SYSTEMS.put(fs.getScheme(), fs.getClass());
} catch (Exception e) {
LOG.warn("Cannot load: " + fs + " from " +
ClassUtil.findContainingJar(fs.getClass()), e);
}
} catch (ServiceConfigurationError ee) {
LOG.warn("Cannot load filesystem", ee);
}
}
FILE_SYSTEMS_LOADED = true;
}
}
}