门控循环单元(GatedRecurrentUnit,GRU)网络,也是一种基于门控的循环神经网络,但是名气不如LSTM大,GRU是对LSTM的一种改版,可以理解为是LSTM的简化版。LSTM有三个门,输入门,遗忘门,输出门,而GRU仅有两个门,分别为更新门和重置门。GRU的目的和LSTM是一样的,也是为了解决循环神经网络的长期依赖问题,即随时间反向传播算法当序列长度太长后产生的梯度爆炸和梯度消失问题。GRU将LSTM中的输入门和遗忘门合并成了一个更新门,同时,GRU也不引入额外的记忆单元(LSTM中引入了额外的记忆单元C),直接在当前状态ht和历史状态ht-1之间引入线性依赖关系。
GRU网络的隐状态ht的更新方式为:
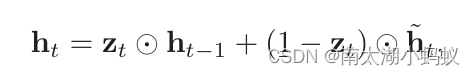
其中zt在[0,1]之间,称为更新门,用来控制当前状态需要从历史状态中保留多少信息,以及需要从候选状态中接受多少新信息。
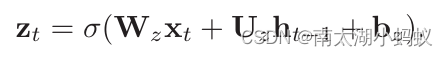
这里的W,U,b都是可以学习的权重参数。
其中ht~称为当前时刻的候选状态,计算方法如下:
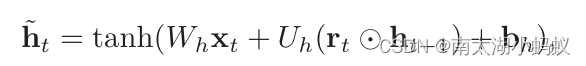
rt就是GRU的另一个门,重置门,用来控制候选状态ht~的计算是否依赖上一时刻的状态ht-1。
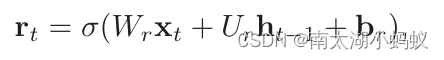
当rt=0时,候选状态就只和当前输入xt有关,而与历史状态ht-1无关了,当rt=1时,候选状态就又和当前输入xt有关,也和历史状态ht-1有关,就和简单循环神经网络RNN一样了。
当更新门zt=0时,那么ht就等于ht~,也就是说ht和ht-1就是一个非线性函数;如果zt=0且rt=1,GRU就是简单循环神经网络RNN;如果zt=0且rt=0,那么zt=tanh(Wh*xt+bh),ht就只和当前输入xt有关了;当zt=1时,ht=ht-1,也就是说ht直接是上一个时刻的隐状态ht-1,而与候选状态无关,也就是和当前输入xt无关了。当然,大多数时候,GRU的隐状态既和上一个时刻的隐状态有关,又和当前输入xt有关。可以这么说,重置门有助于捕获序列中的短期依赖关系,更新门有助于捕获序列中的长期依赖关系。GRU网络结构如下图:
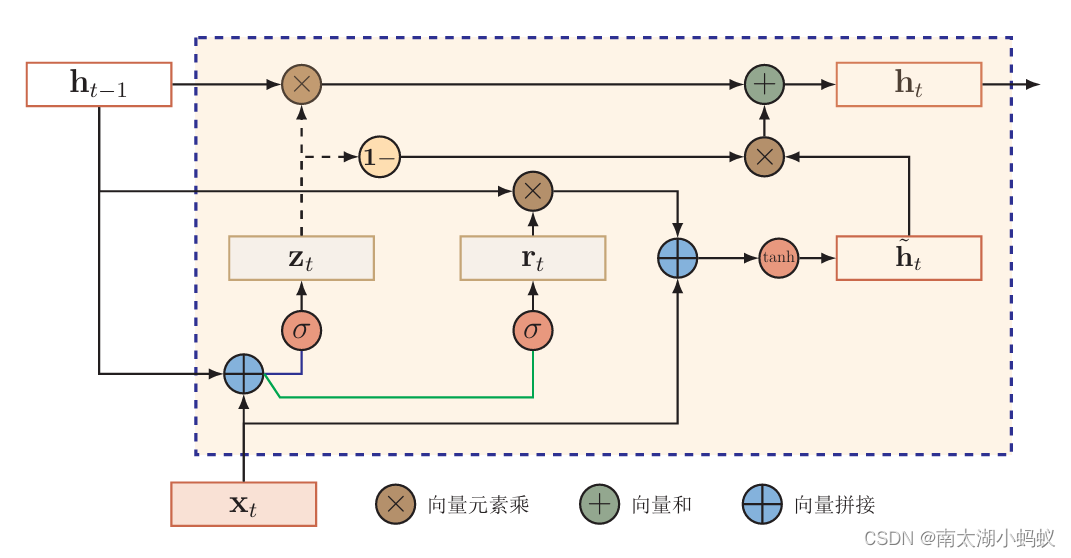
下面我们来实现一下GRU网络。
class GRU(nn.Module):
def __init__(self, input_size, num_hiddens, batch_first=True):
super(GRU,self).__init__()
def normal(shape):
return torch.randn(size = shape)*0.01
def three():
wx = normal((input_size, num_hiddens))
wh = normal((num_hiddens, num_hiddens))
b = torch.zeros(num_hiddens)
return (wx,wh,b)
W_xz, W_hz, b_z = three() # 更新门参数
W_xr, W_hr, b_r = three() # 重置门参数
W_xh, W_hh, b_h = three() # 候选隐藏状态参数
# 输出层参数
W_hq = normal((num_hiddens, num_hiddens))
b_q = torch.zeros(num_hiddens)
self.params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
self.batch_first = batch_first
self.num_hiddens = num_hiddens
def forward(self,inputs):
[W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q] = self.params
if self.batch_first:
batch_size = inputs.shape[0]
seq_len = inputs.shape[1] # 序列长度
else:
batch_size = inputs.shape[1]
seq_len = inputs.shape[0] # 序列长度
self.h = torch.zeros((seq_len, self.num_hiddens))
H = self.h
outputs = []
for X in inputs:
Z = torch.sigmoid((X@W_xz) + (H@W_hz) + b_z)
R = torch.sigmoid((X@W_xr) + (H@W_hr) + b_r)
H_tilda = torch.tanh((X@W_xh) + ((R*H)@W_hh) + b_h)
H = Z*H + (1-Z)*H_tilda
Y = H@W_hq + b_q
outputs.append(Y)
out = torch.cat(outputs, dim=0)
out = out.reshape(batch_size,seq_len,self.num_hiddens)
return out,(H)可以看到,我们首先初始化了更新门,重置门,候选隐藏状态,以及输出层的参数。输入的第一个维度默认是batch_size,第二个维度是序列长度seq_len,由于我们这里只是定义了一个GRU模块,所以输出的维度和隐藏层一致。实际应用中,需要在GRU的输出结果后,加上全连接层,得到最终的输出。这里X遍历了整个inputs,最后按第0维(也就是第一个维度)拼接,得到GRU输出结果,其实就是把一个batch拆分开计算,再将得到结果,在batch_size维度上进行合并。我们可以看一下输出大小示例:
net = GRU(input_size=1, num_hiddens=20, batch_first=True)
data = torch.zeros(8,10,1)
out,ht = net(data)
print(out.shape)
# 输出:
torch.Size([8, 10, 20])可以看到,输入batch_size=8,序列长度10,输入大小是1维的数字,输出第一个维度是8,也就是batch_size,第二个维度10,是序列长度,第三个维度20,是隐藏层的大小。我们可以看一下pytorch官方提供的GRU函数,得到的结果大小。
input_size = 1
num_hiddens = 20
gru=nn.GRU(
input_size=input_size, #输入特征维度,维度为1
hidden_size=num_hiddens, #隐藏层神经元个数,或者也叫输出的维度
num_layers=1,
batch_first=True
)
data = torch.zeros(8, 10, 1)
out,ht = gru(data)
print(out.shape)
print(out[:,-1,:].shape)
# 输出:
torch.Size([8, 10, 20])
torch.Size([8, 20])可以看到pytorch官方的GRU函数和我们自己实现的输出格式是一致的,都是[8,10,20]。下面,我们根据我们自己定义的GRU模块,来实现一个完整的GRU网络:
class model(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(model, self).__init__()
self.hidden_size = hidden_size
self.gru = GRU(input_size, hidden_size, batch_first=True) # 自定义的GRU
#self.gru = nn.GRU(input_size, hidden_size, batch_first=True) # Pytorch提供的GRU
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.gru(x)
out = self.fc(out[:, -1, :])
return outnet = model(1, 20, 1)
data = torch.zeros(8, 4, 1)
out = net(data)
print(out.shape)
# 输出:
torch.Size([8, 1])完整的模型中,我在得到GRU的结果后又加上了全连接模块,得到了最终的输出。我这里输入了batch_size=8,序列长度为4,输入维度为1的序列数据,最终输出结果是batch_size=8,输出维度是1的数据,符合我们的要求。下面我们用这个模型,在之前用过的正弦数据上模拟一下。
import matplotlib.pyplot as plt
# 画出sin函数作为序列函数
y = []
for i in range(1000):
y.append(np.sin(0.01*i)+np.random.normal(0,0.2)) # 给sin函数增加一个微小的扰动
x = [i for i in range(1000)]
plt.plot(x, y)
plt.show()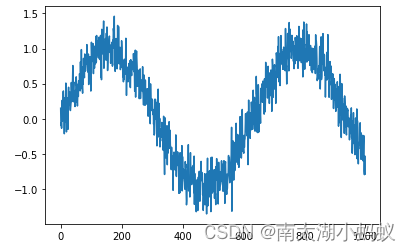
根据正弦函数并加上一个随机扰动生成序列数据,我们的目的是希望根据四个输入数据输出下一个数据。下面构造训练数据。
# 用前600个数字作为训练集,后400个作为测试集
class myDataset(Dataset):
def __init__(self, tau=4, total=600, transform=None):
data = [i for i in range(total)]
y = []
for i in range(total):
y.append(np.sin(0.01*i)+np.random.normal(0,0.2)) # 给sin函数增加一个微小的扰动
# tau代表用多少个数字来作为输入,默认为4
self.features = np.zeros((total-tau, tau)) # 构建了996行4列的输入序列,代表了996个训练样本,每个样本有4个数字构成
for i in range(tau):
self.features[:,i] = y[i: total-tau+i] # 给特征向量赋值
self.data = data
self.transform = transform
self.labels = y[tau:]
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
return self.features[idx], self.labels[idx]transform = transforms.Compose([transforms.ToTensor()])
trainDataset = myDataset(transform=transform)
train_loader = DataLoader(dataset=trainDataset, batch_size=32, shuffle=False) 训练函数:
def train(epochs=10):
net = model(1, 20, 1)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)
for epoch in range(epochs):
total_loss = 0.0
for i, (x, y) in enumerate(train_loader):
x = Variable(x)
x = x.to(torch.float32)
x = x.unsqueeze(2)
y = Variable(y)
y = y.to(torch.float32)
y = y.unsqueeze(1)
optimizer.zero_grad()
outputs = net(x)
loss = criterion(outputs, y)
total_loss += loss.sum() # 因为标签值和输出都是一个张量,所以损失值要求和
loss.sum().backward()
optimizer.step()
if (epoch+1)%50==0:
print('Epoch {}, Loss: {:.4f}'.format(epoch+1, total_loss/len(trainDataset)))
torch.save(net, 'gru.pt')train(epochs=1000)
# 输出
Epoch 50, Loss: 0.0164
Epoch 100, Loss: 0.0149
Epoch 150, Loss: 0.0135
Epoch 200, Loss: 0.0122
Epoch 250, Loss: 0.0109
Epoch 300, Loss: 0.0098
Epoch 350, Loss: 0.0087
Epoch 400, Loss: 0.0077
Epoch 450, Loss: 0.0068
Epoch 500, Loss: 0.0060
Epoch 550, Loss: 0.0053
Epoch 600, Loss: 0.0046
Epoch 650, Loss: 0.0040
Epoch 700, Loss: 0.0035
Epoch 750, Loss: 0.0031
Epoch 800, Loss: 0.0027
Epoch 850, Loss: 0.0024
Epoch 900, Loss: 0.0022
Epoch 950, Loss: 0.0020
Epoch 1000, Loss: 0.0019下面根据训练后的模型进行预测:
# 预测
net = torch.load('gru.pt')
features = torch.from_numpy(features)
features = features.float()
features = features.unsqueeze(2)
y_pred = net(features)
# 画出sin函数作为序列函数
y = []
for i in range(996):
# 给sin函数增加一个微小的扰动
y.append(np.sin(0.01*i)+np.random.normal(0,0.2))
x = [i for i in range(996)]
fig, ax = plt.subplots()
ax.plot(x, y)
ax.plot(x, y_pred.detach().numpy(), color="y")
plt.show()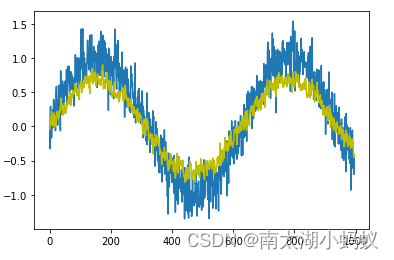
可以看到,训练结果符合正弦函数的图形特征。下一篇文章,我们看一下如何利用循环神经网络预测股价。





![[JDK工具-5] jinfo jvm配置信息工具](https://img-blog.csdnimg.cn/direct/c821a67cd234429a805ba3976bb529e5.png)