【mysql】in和exists的区别,not in、not exists、left join的相互转换
- 【一】in介绍
- 【1】in中数据量的限制
- 【2】null值不参与in或not in,也就是说in and not in 并不是全量值,排除了null值
- 【3】in的执行逻辑
- 【二】exists介绍
- 【1】exists + not exists 是全量数据
- 【2】exists的执行逻辑
- 【三】小表驱动大表的好处
- 【四】in、not in、exists、not exists是否可以走索引(都可以)
- 【五】exists的使用案例
- 【1】在sql中使用exists
- 【2】在SQL中使用NOT EXISTS
- 【3】在SQL中使用多个NOT EXISTS
- 【4】在SQL中使用多个EXISTS
- 【5】在SQL中使用NOT EXISTS和EXISTS
- 【六】not in、 not exists、left join语句相互转换(必须在表关联时,否则并不等同)
- 【1】not in
- 【2】not exists
- 【3】left join + is null
【一】in介绍
【1】in中数据量的限制
在oracle中,int中数据集的大小超过1000会报错;
在mysql中,超过1000不会报错,但也是有数据量限制的,应该是4mb,但不建议数据集超过1000,
因为in是可以走索引的,但in中数据量过大索引就会失效
【2】null值不参与in或not in,也就是说in and not in 并不是全量值,排除了null值
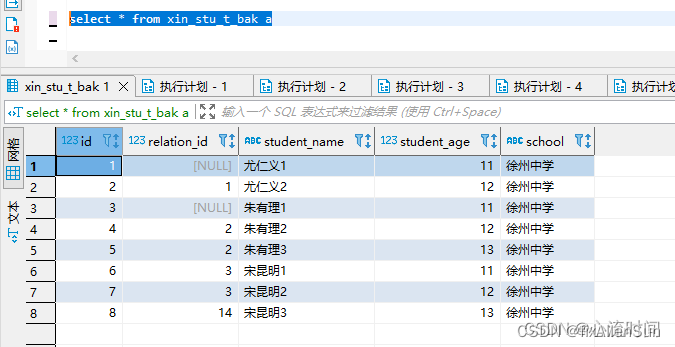
select * from xin_stu_t_bak a where a.relation_id in ( select id from xin_teach_t_bak b)
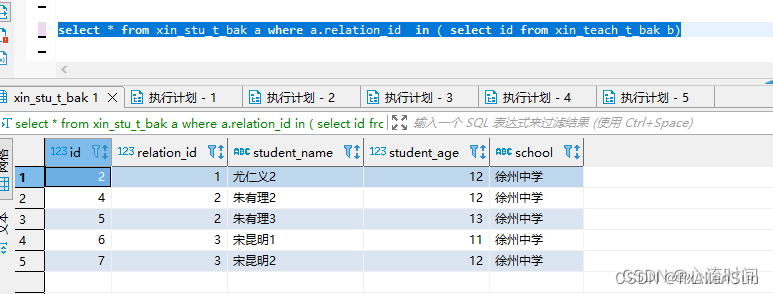
select * from xin_stu_t_bak a where a.relation_id not in ( select id from xin_teach_t_bak b)
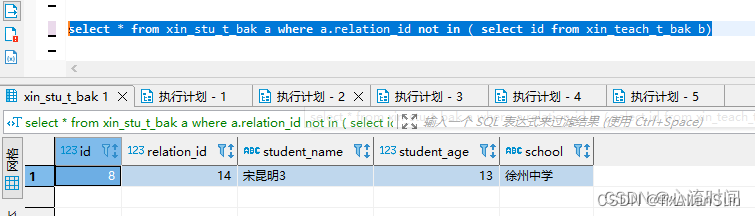
select * from xin_stu_t_bak a
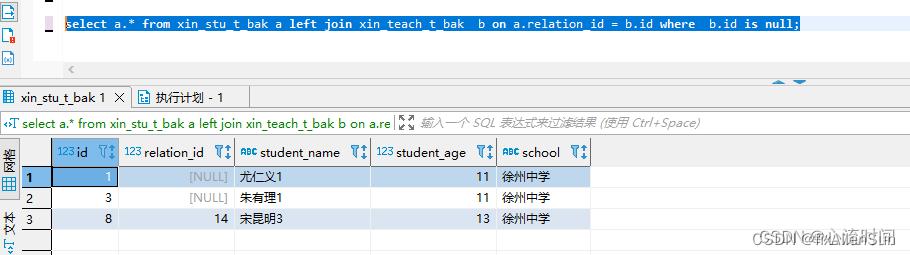
从此处可以看出,in和not in 加在一起并不是全量的值,排除了null值
【3】in的执行逻辑
(1)当前的in子查询时B表驱动A表
(2)mysql先把B表的数据一把查出来到内存中
(3)遍历B表的数据,再去查A表(每次遍历都是一次连接交互,这里会耗资源)
(4)假设B有100000条记录,A有10条记录,会交互100000次数据库;再假设B有10条记录,A有100000条记录,那么只会发生10次交互
结论: in是先进行子查询,再与外面的数据进行循环遍历,属于子查询的结果集驱动外面的结果集,
当in子查询的结果集较小时,就形成了小表驱动大表,而两张表的驱动就是一张表的行数据去循环关联另一张表,
关联次数越少越好,所以小表去查询大表,次数更少,性能更高
in()适合B表比A表数据小的情况
【二】exists介绍
【1】exists + not exists 是全量数据
select * from xin_stu_t_bak a where exists ( select 1 from xin_teach_t_bak b where a.relation_id = b.id)
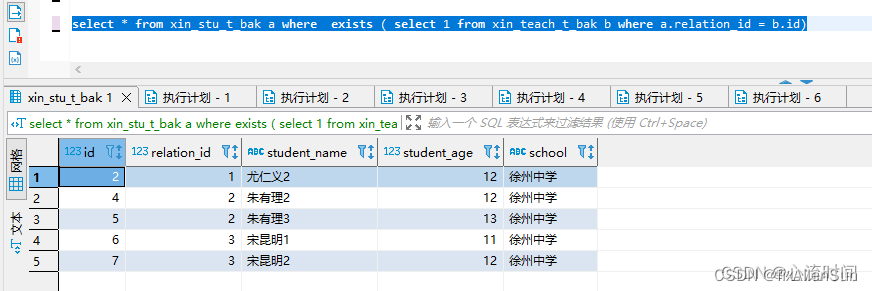
select * from xin_stu_t_bak a where not exists ( select 1 from xin_teach_t_bak b where a.relation_id = b.id)

exist + not exists 是全量数据,这点与in不同
【2】exists的执行逻辑
1-当前exists查询是A表驱动B表
2-与in不同,exists将A的纪录数查询到内存,因此A表的记录数决定了数据库的交互次数
3-假设A有10000条记录,B有10条记录,数据库交互次数为10000;假设A有10条,B有10000条,数据库交互次数为10。
结论:exists理论上就是boolean值,关联后查询到有值则是true数据留下,关联后查询没有值则是false数据舍弃;
exists适合B表数据量大,A表数据量小的情况,与in相反
【三】小表驱动大表的好处
我们来看下面两个循环:
for (int i = 0; i<10000; i++){
for(int j = 0; j<10; j++){
}
}
for (int i = 0; i<10; i++){
for(int j = 0; j<10000; j++){
}
}
在java中,我们都知道上述的两个循环的时间复杂度都是一样的;
但在数据库中则是有区别的,
首先第一层循环,数据库只做一次交互一把将数据查出到缓存中,
而第二层循环的数据库交互次数决定于第一层循环数据量的大小。
对于数据库而言,交互次数越多越耗费资源,一次交互涉及了“连接-查找-断开”这些操作,是相当耗费资源的。
使用in时,B表驱动A
使用exists时,A表驱动B
所以我们写sql时应当遵循“小表驱动大表“的原则
【四】in、not in、exists、not exists是否可以走索引(都可以)
in可以走索引,但数据量过大时就不走索引了
not in、exist、not exists也都可以走索引
【五】exists的使用案例
【1】在sql中使用exists
需求:从TEST_TB01中查询出在TEST_TB02中存在的记录,关联条件是两个表的sensor_id相等。
SELECT
aa.sensor_id,aa.part_id,aa.flag
FROM
TEST_TB01 aa
WHERE EXISTS
(SELECT 1 FROM
TEST_TB02 bb
WHERE aa.sensor_id = bb.sensor_id);
【2】在SQL中使用NOT EXISTS
需求:从TEST_TB01中查询出在TEST_TB02中不存在的记录,关联条件是两个表的sensor_id相等。
SELECT
aa.sensor_id,aa.part_id,aa.flag
FROM
TEST_TB01 aa
WHERE NOT EXISTS
(SELECT 1 FROM
TEST_TB02 bb
WHERE aa.sensor_id = bb.sensor_id);
【3】在SQL中使用多个NOT EXISTS
需求:从TEST_TB01中查询出在TEST_TB02和TEST_TB03中都不存在的记录,关联条件是表的sensor_id相等。
SELECT
aa.sensor_id,aa.part_id,aa.flag
FROM
TEST_TB01 aa
WHERE NOT EXISTS
(SELECT 1 FROM
TEST_TB02 bb
WHERE aa.sensor_id = bb.sensor_id)
AND NOT EXISTS
(SELECT 1 FROM
TEST_TB03 cc
WHERE aa.sensor_id = cc.sensor_id);
【4】在SQL中使用多个EXISTS
需求:从TEST_TB01中查询出在TEST_TB02和TEST_TB03中都存在的记录,关联条件是表的sensor_id相等。
SELECT
aa.sensor_id,aa.part_id,aa.flag
FROM
TEST_TB01 aa
WHERE EXISTS
(SELECT 1 FROM
TEST_TB02 bb
WHERE aa.sensor_id = bb.sensor_id)
AND EXISTS
(SELECT 1 FROM
TEST_TB03 cc
WHERE aa.sensor_id = cc.sensor_id);
【5】在SQL中使用NOT EXISTS和EXISTS
需求:从TEST_TB01中查询出在TEST_TB02存在但是TEST_TB03中不存在的记录,关联条件是表的sensor_id相等。
SELECT
aa.sensor_id,aa.part_id,aa.flag
FROM
TEST_TB01 aa
WHERE EXISTS
(SELECT 1 FROM
TEST_TB02 bb
WHERE aa.sensor_id = bb.sensor_id)
AND NOT EXISTS
(SELECT 1 FROM
TEST_TB03 cc
WHERE aa.sensor_id = cc.sensor_id);
【六】not in、 not exists、left join语句相互转换(必须在表关联时,否则并不等同)
【1】not in
select * from xin_stu_t_bak a where a.relation_id not in ( select id from xin_teach_t_bak b where a.relation_id = b.id)
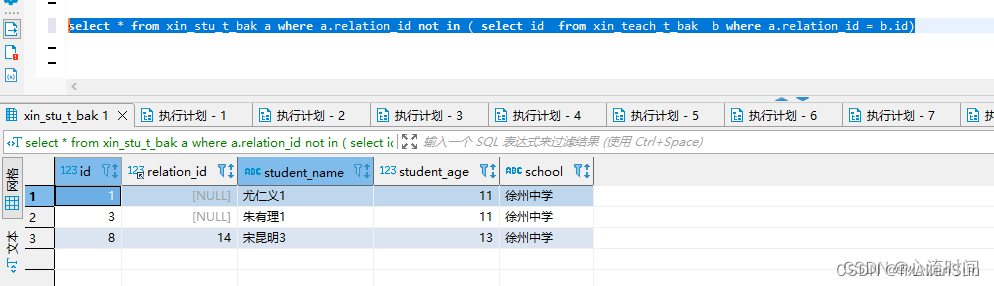
【2】not exists
select * from xin_stu_t_bak a where not exists ( select 1 from xin_teach_t_bak b where a.relation_id = b.id)
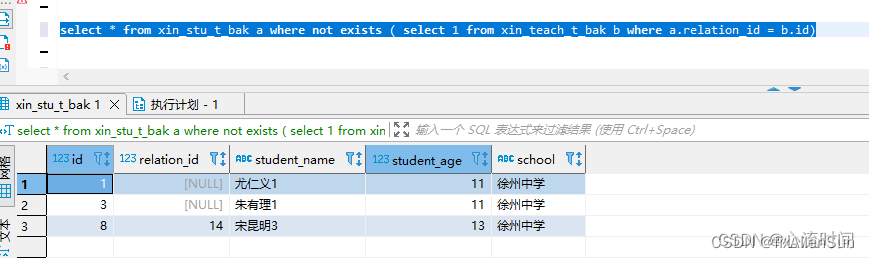
【3】left join + is null
select a.* from xin_stu_t_bak a left join xin_teach_t_bak b on a.relation_id = b.id where b.id is null;