前言
当我们谈论关于APP用户分析与电子商务之间的联系时,机器学习在这两个领域的应用变得至关重要。App用户分析和电子商务之间存在着密切的关联,因为用户行为和偏好的深入理解对于提高用户体验、增加销售以及优化产品功能至关重要。故本文基于K-近邻模型、贝叶斯模型和自适应提升模型对:基于已爬取的APP数据(例如:APP类型、APP安装人数、APP评论内容等等)的分析来预测该APP是否为一个好的APP。
数据介绍与预处理
从前,手机app少,但经典,现在,app多了,但混杂(多仿品),有很多因素影响用户去下载app,评分就是很重要的参考。那么问题来了:在无法参透某平台app评分算法的奥义之前,能否预测一下app的评分呢(简化之,app好评是1,差评为0)?
train.csv:训练集,7728 rows × 10 columns, 列属性包含:App, Category, Reviews, Size, Installs(安装量), Type, Price, ContentRating(评论的人员), Last Updated(上次更新的日期), Y(是否为好评,1为好评,0为非好评), 行为7728个APP样本。
首先导入数据分析必要的包:



随后通过发现有的特征数据格式或者单位没有统一,特征变量全部为object,故要做进一步处理。
针对“Size”变量的单位不统一的原因,故定义一个条件判断函数,将其单位统一:

观察变量,继续进行预处理:

处理完成之后再次查看数据情况:

随后进行描述性统计分析

从上图中可以看出,对于训练集的和测试集描述性统计,对各个特征变量的计数、均值、标准差、最大最小值,以及分位数均进行了展示。
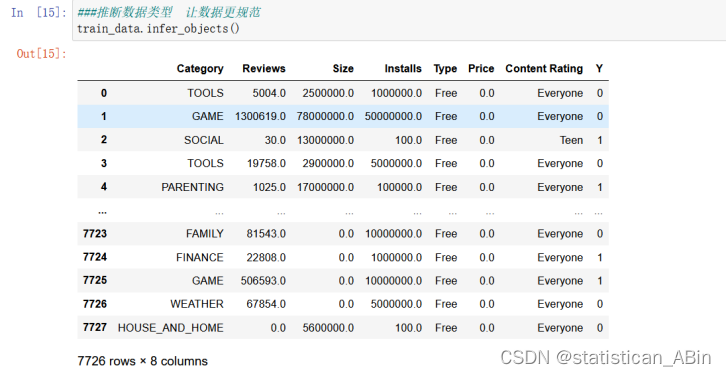
随后推断数据类型,让数据更规范以及查看数据的基础信息,结果如下(仍是以训练数据集为例),这一步是为了对特征分析和模型建立作准备。
接下来对数据缺失值进行确认,首先导入缺失值可视化missingno包,该包可以很直观的看出每个特征的缺失程度,故可以很好的对特征进行筛选,可视化结果如下,在每个特征中白色越多就表明数据越缺失。由于在上文中在进行了数据缺失值的处理,故在下面的可视化中只是更直观的确认一下训练集和测试集(测试集在此不作展示)中是否还有缺失值的存在。

然后需要对数据进一步细化处理,要把数据分为数值型和其他类型来看。分布进行处理,例如对于分类型变量,则通过独热编码进行处理。
首先查看数值型变量数据:

 填充缺失值,缺失值有很多填充方式,可以用中位数,均值,众数。也可以就采用那一行前面一个或者后面一个有效值去填充空的。
填充缺失值,缺失值有很多填充方式,可以用中位数,均值,众数。也可以就采用那一行前面一个或者后面一个有效值去填充空的。
 通过探索性数据分析,我们对字符类型特征值与数字类型特征值与Y的关系有了较深的了解,同时观察到投资收入与投资损失的数据特征,因此在进行模型构造前,首先需要对特征值进行一定的处理以实现机器学习算法的高效利用。
通过探索性数据分析,我们对字符类型特征值与数字类型特征值与Y的关系有了较深的了解,同时观察到投资收入与投资损失的数据特征,因此在进行模型构造前,首先需要对特征值进行一定的处理以实现机器学习算法的高效利用。
在处理完特征变量之后,对响应变量的分布也要考察,若存在异常值的情况也会对模型的泛化能力有影响,在此画出响应变量的箱线图、直方图和和核密度图,如下图:

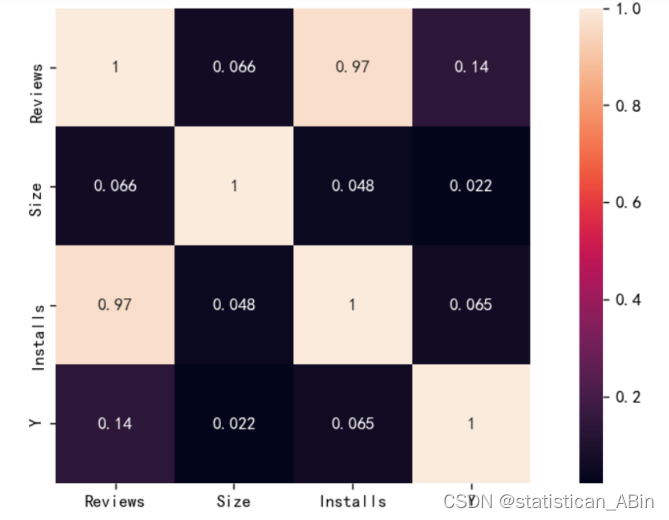
随后对特征变量进行相关系数的计算以及热力图的展示,如下图:
机器学习预测

选取数据集的80%为训练集,20%为测试集进行下一步的预测与检验,为了保证程序每次运行都分割一样的训练集和测试集,设置random_state为0。


结论
本文基于探索性数据分析对APP评分的预测问题进行数据加载、数据清洗以及数据可视化操作。其中预处理包括处理数据的格式问题,以及统一数据的单位,填充数据的缺失值问题,通过数据预处理工作之后,整体数据变为较为整洁。上述数据分析完成了机器学习中的数据预处理部分,数据分析所得结论具有应用意义。....
部分代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['KaiTi'] #中文
plt.rcParams['axes.unicode_minus'] = False #负号
df=pd.read_csv('train.csv')
df.head()
df.info()
df=df.fillna(method='pad') #前一个有效值进行填充
df.loc[df[df['Type']=='0'].index,'Type']=df['Type'].mode() #异常值使用众数填充
def check(x):
if "M" in str(x):
x = float(str(x).replace("M", "")) * 1000000
elif "K" in str(x):
x = float(str(x).replace("K", "")) * 1000
elif "k" in str(x):
x = float(str(x).replace("k", "")) * 1000
elif "Varies with device" in str(x):
x = 0
else:
return float(x)
return x/1000
y.value_counts(normalize=True)
# 查看y的分布
#分类问题
plt.figure(figsize=(4,2),dpi=128)
plt.subplot(1,2,1)
y.value_counts().plot.bar(title='响应变量柱状图图')
plt.subplot(1,2,2)
y.value_counts().plot.pie(title='响应变量饼图')
plt.tight_layout()
plt.show()
#查看特征变量的箱线图分布
dis_cols = 3 #一行几个
dis_rows = 2
plt.figure(figsize=(3*dis_cols, 2*dis_rows),dpi=128)
for i in range(5):
plt.subplot(dis_rows,dis_cols,i+1)
sns.kdeplot(X[X.columns[i]], color="tomato" ,shade=True)
#plt.xlabel((y.unique().tolist()),fontsize=12)
plt.ylabel(df.columns[i], fontsize=18)
plt.tight_layout()
plt.show()
#贝叶斯
model1 = BernoulliNB(alpha=1)
#K近邻
model2 = DecisionTreeClassifier()
#自适应提升Adaboost
model3 = RandomForestClassifier(n_estimators=1000, max_features='sqrt',random_state=123)
model_list=[model1,model2,model3]
model_name=['二项朴素贝叶斯(伯努利)','决策树','随机森林']
数据和代码
数据代码和分析报告
创作不易,希望大家多多点赞收藏和评论!