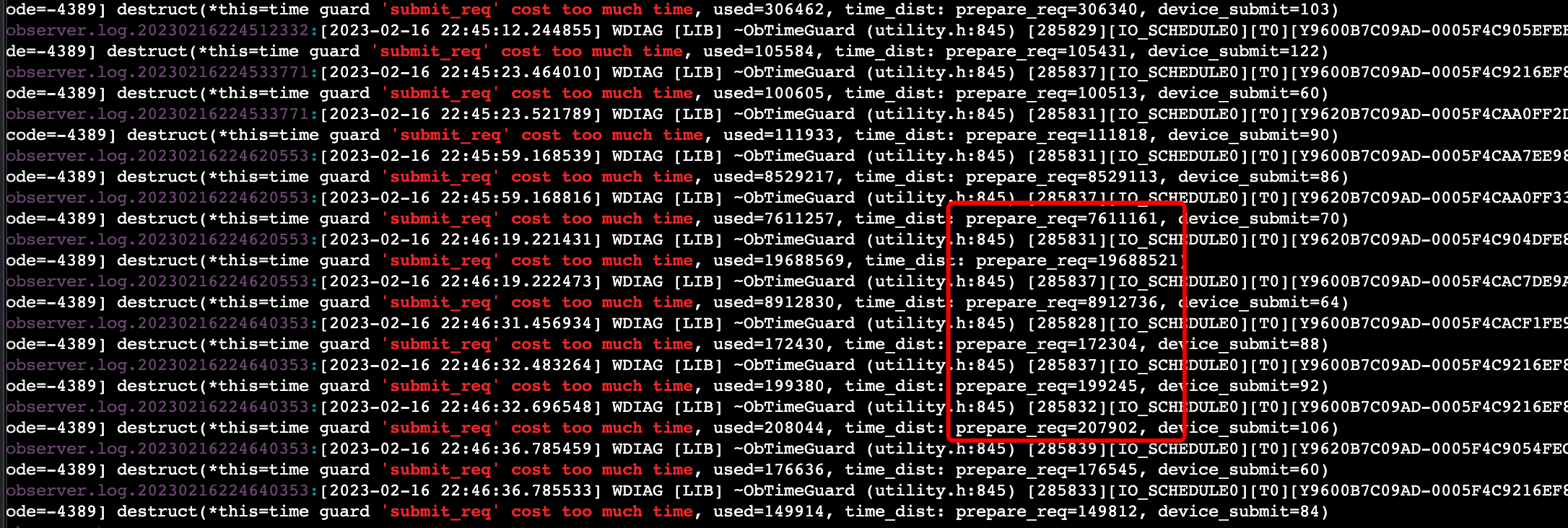
首先需要你对排序算法的评价维度和一个理想排序算法应该是什么样的有一个基本的认知:
《Hello算法之排序算法》
主要内容来自:Hello算法11.4 插入排序
插入排序的整个过程与手动整理一副牌非常相似。
我们在未排序区间选择一个基准元素,将该元素base,与其左侧已排序区间的元素逐一比较大小,并将该元素插入到正确的位置,并且在这个过程中,为了留出空位,我们需要从目标索引到base之间的所有元素向后移动以为,然后将base赋值给目标索引。

文章目录
- 算法流程
- 算法特性
- 插入排序的优势
- std::sort
- 与冒泡和选择排序的比较
算法流程
- 初始状态下,数组的第一个元素已完成排序;
- 选取数组的第2个元素作为
base,将其插入到正确位置后,数组的前2个元素已排序。 - 选取第3个元素作为
base,将其插入到正确位置后,数组的前 3 个元素已排序。 - 以此类推,在最后一轮中,选取最后一个元素作为 base ,将其插入到正确位置后,所有元素均已排序。

void insertionSort(vector<int> &nums) {
// 外循环:已排序区间为 [0, i-1]
for (int i = 1; i < nums.size(); i++) {
int base = nums[i], j = i - 1;
// 内循环:将 base 插入到已排序区间 [0, i-1] 中的正确位置
while (j >= 0 && nums[j] > base) {
nums[j + 1] = nums[j]; // 将 nums[j] 向右移动一位
j--;
}
nums[j + 1] = base; // 将 base 赋值到正确位置
}
}
算法特性
- 时间复杂度为 O ( n 2 ) O(n^2) O(n2)、自适应排序:最差情况下,每次插入操作分别需要 n − 1 、 n − 2 、 . . . 、 2 、 1 n-1 、n-2、...、2、1 n−1、n−2、...、2、1,总和为 ( n − 1 ) n 2 \frac{(n-1)n}{2} 2(n−1)n。在遇到有序数据时,插入操作会提前终止。当输入数组完全有序时,插入排序达到最佳时间复杂度 O ( n ) O(n) O(n)
- 空间复杂度为 O ( 1 ) O(1) O(1)、原地排序
- 稳定排序:在插入操作过程中,我们会将元素插入到相等元素的右侧,不会改变它们的顺序。
插入排序的优势
std::sort
当数据量较小的情况下,插入排序通常更快。
因为在数据量较少时 n 2 n^2 n2和 n l o g ( n ) nlog(n) nlog(n)数值比较接近,而由于快排等这类 O ( n l o g n ) O(nlogn) O(nlogn)等算法属于分治策略的排序算法,往往包含更多的单元计算操作。
许多编程语言(例如 Java)的内置排序函数采用了插入排序,大致思路为:对于长数组,采用基于分治策略的排序算法,例如快速排序;对于短数组,直接使用插入排序。
当然了,也少不了我们C++的std::sort,它基于一种称为三路快速排序(introsort)的算法实现,它的“神奇”之处在于根据输入数组的不同特点自适应地选择合适的排序方法,从而优化性能。
std::sort:
- step1:快速排序(Quicksort):初始阶段使用快速排序进行分区;选择一个枢纽元,将数组分成小于、等于和大于枢纽元的三部分;对两边继续递归。
- step2:切换到堆排序(Heapsort):当递归深度超过某个阈值(通常是 2*log(n)),为了避免快速排序在最坏情况下退化成O(n^2)复杂度,切换到堆排序;堆排序的最坏情况时间复杂度是 O(n log n)。
- step3:插入排序(Insertion Sort):当分区后的子数组长度小于一定阈值(如 16),切换到插入排序;插入排序在小数组上的性能通常优于快速排序。
与冒泡和选择排序的比较
在实际情况中,插入排序的使用频率显著高于冒泡排序和选择排序,主要有以下原因。
- 冒泡排序基于元素交换实现,需要借助一个临时变量,共涉及 3 个单元操作;插入排序基于元素赋值实现,仅需 1 个单元操作。因此,冒泡排序的计算开销通常比插入排序更高。
- 选择排序在任何情况下的时间复杂度都为 O ( n 2 ) O(n^2) O(n2)。如果给定一组部分有序的数据,插入排序通常比选择排序效率更高。
- 选择排序不稳定,无法应用于多级排序。

![YOLOv8_pose预测流程-原理解析[关键点检测理论篇]](https://img-blog.csdnimg.cn/direct/cacfa4e706b447d28226011291193c71.png)