移动云助力大模型,开拓创新领未来。
云计算——AI模型的推动器。
当前人工智能技术发展的现状和趋势,以及中国在人工智能领域的发展策略和成就。确实,以 ChatGPT 为代表的大型语言模型在自然语言处理、文本生成、对话系统等领域取得了显著的成果,并且正在逐步改变我们的工作和生活方式。
由于政府部门的大力支持和企业的积极投资,人工智能产业得到了迅速发展。大型模型训练和部署需要巨大的计算资源和存储空间,以及相应的技术支持,这对许多企业来说是一个挑战。云计算平台提供了解决这一问题的方案,它允许企业通过按需购买服务的方式来使用计算资源,而无需自行建设和维护昂贵的硬件基础设施。
中国移动云和九天人工智能的合作,展示了中国在人工智能领域的创新和进步。通过构建智能计算基础设施,提供高效的智能化算力服务,中国正在推动从数字化到数智化的转变,这将有助于提升国家的竞争力。
此外,中国还在人工智能的关键技术领域进行突破,比如算网大脑的构建,这将进一步提升人工智能模型的性能和应用效率。通过这些努力,中国有望在未来的人工智能领域继续保持领先地位。

架构创新,改变云计算服务供给模式
移动云通过推出COCA(Compute on chip Architecture)软硬一体片上计算架构,正在重塑云计算服务供给模式,这一架构的发布标志着移动云在算力服务模式创新方面迈出了重要一步。COCA架构的三大核心单元——GPU、DPU、HPN,结合自研可编程DPU、多元异构智能算力、高性能RDMA网络、Diskless存储架构引擎等技术,旨在构建高效的大模型算力基础设施。这种基础设施能够实现高性能算力集群的横向融合和垂直抽象,统一提供计算、存储、网络、安全、管控能力的硬件卸载加速。
通过COCA架构,移动云计划加速算力基础设施的建设,并为目标用户提供一体化的算力服务,这些服务将具有“融合、智能、无感、极简”的特点。这种服务模式不仅提供了强大的计算能力,还通过硬件卸载加速减少了资源浪费,提高了效率,使得用户能够更加专注于自己的业务需求,而不是基础的计算资源管理。这一创新有望在云计算领域引发新的变革,为企业和开发者提供更加高效、智能的算力支持。
对此感兴趣的伙伴可以尝试体验一下,下面将介绍如何在移动云上简单部署大模型。

移动云上部署大模型ChatGLM3-6b
前言
通过移动云,大语言模型可以在移动设备上得到更好的应用和发展。在部署后可以完全本地运行,后面将介绍移动云部署大模型的实际应用,介绍怎么通过移动云上在 Linux 服务器上部署 ChatGLM3 服务,并通过多种方式使用本地部署地大模型。
服务器准备
移动云服务器(试用申请网址)
-
进入官网页面后,进行实名认证,选择一个合适的云服务器。

-
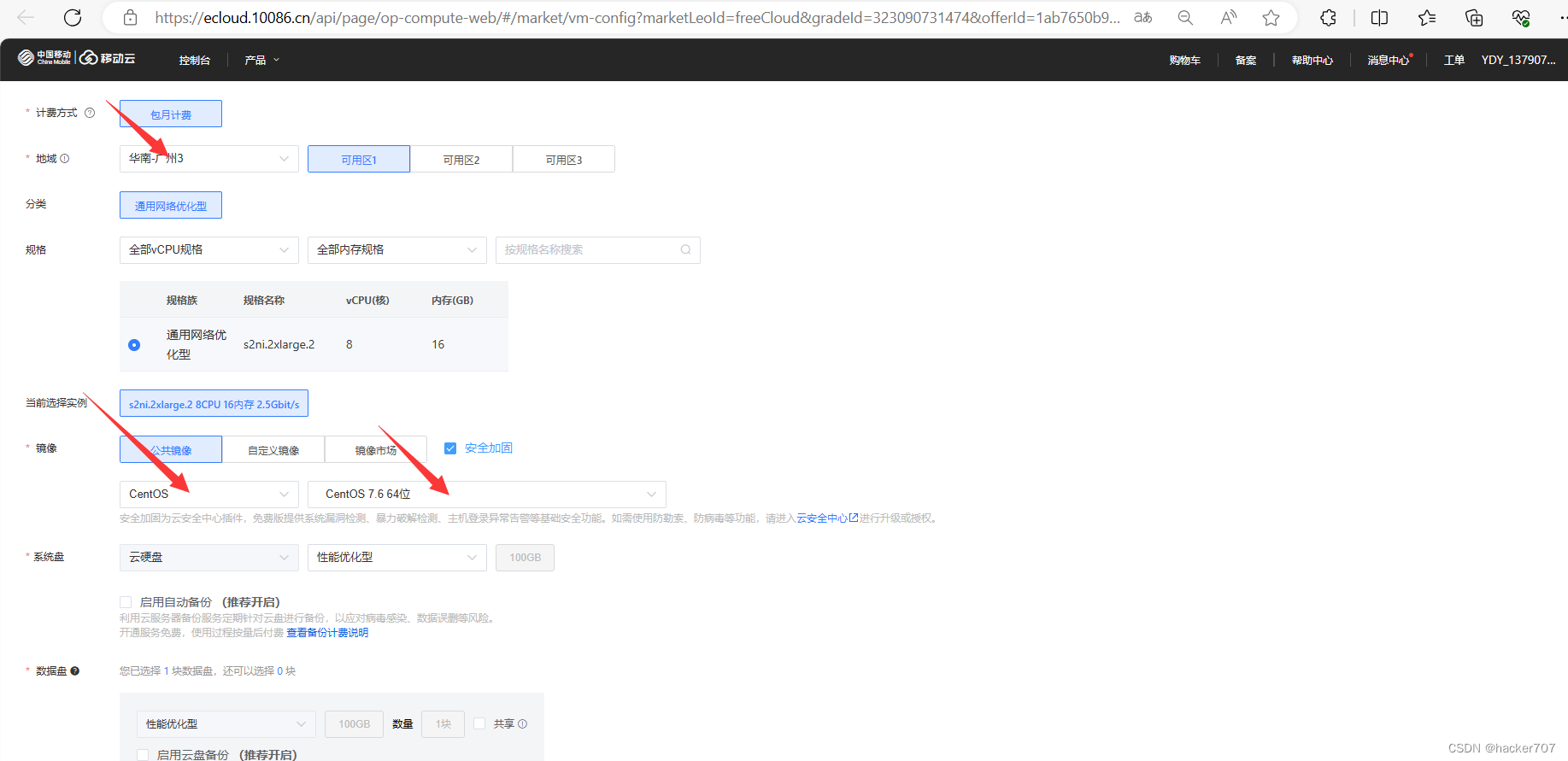
选择地区,以及服务器的型号与配置。
-
网络配置(如果自己将要将自己的网站放在公网中时,需要先进行ICP备案。)以下操作将自己的网络地址配置到自己的云主机中。

-
当前往支付完成后可以就得到一台Linux服务器。
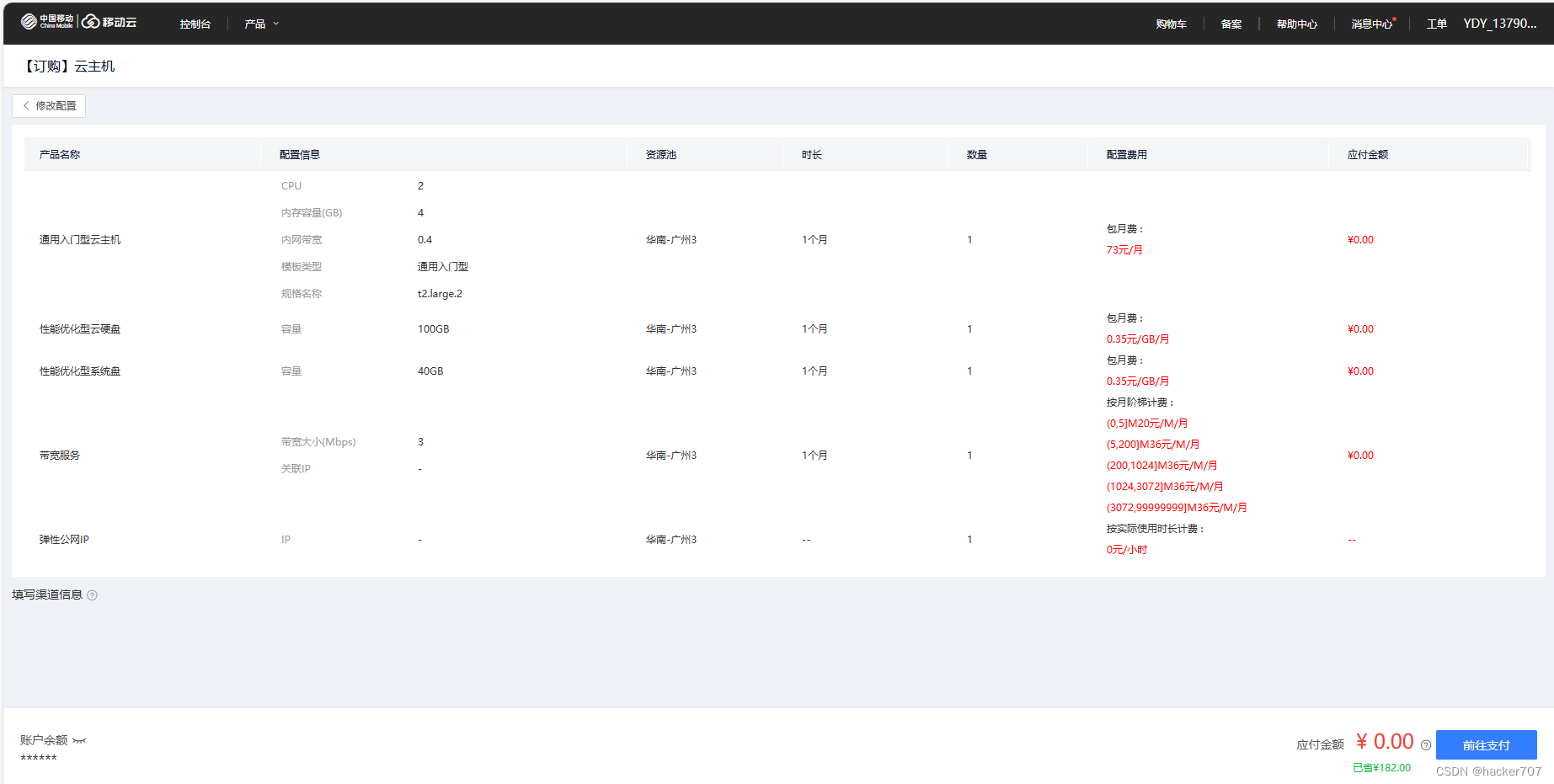
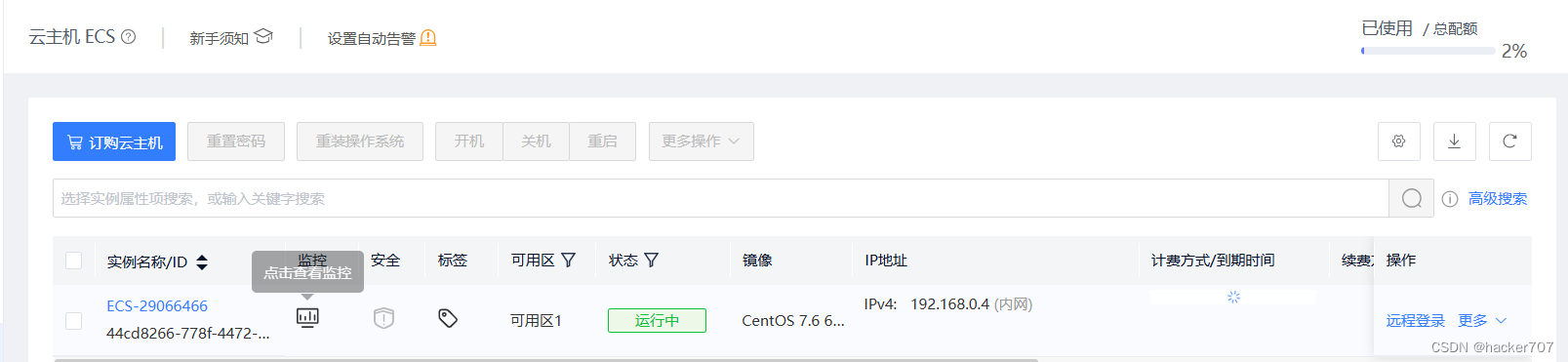
-
进行密码修改
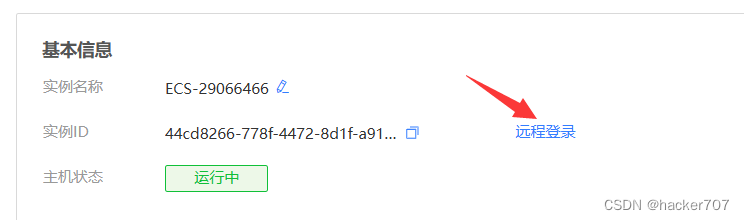
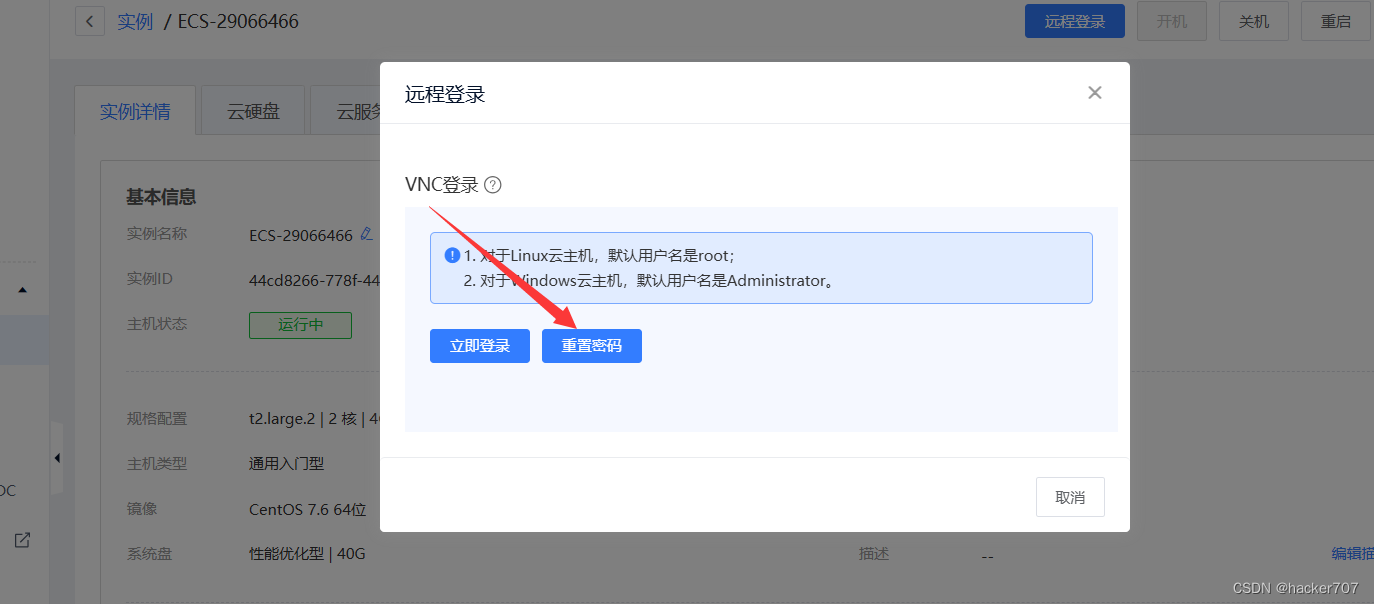
-
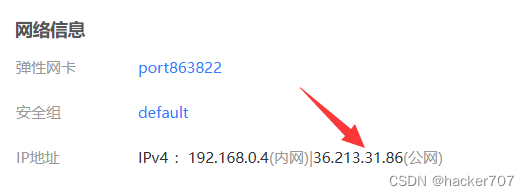
找到弹性公网IP,将系统默认给的公网IP分配给我们的云主机。
-
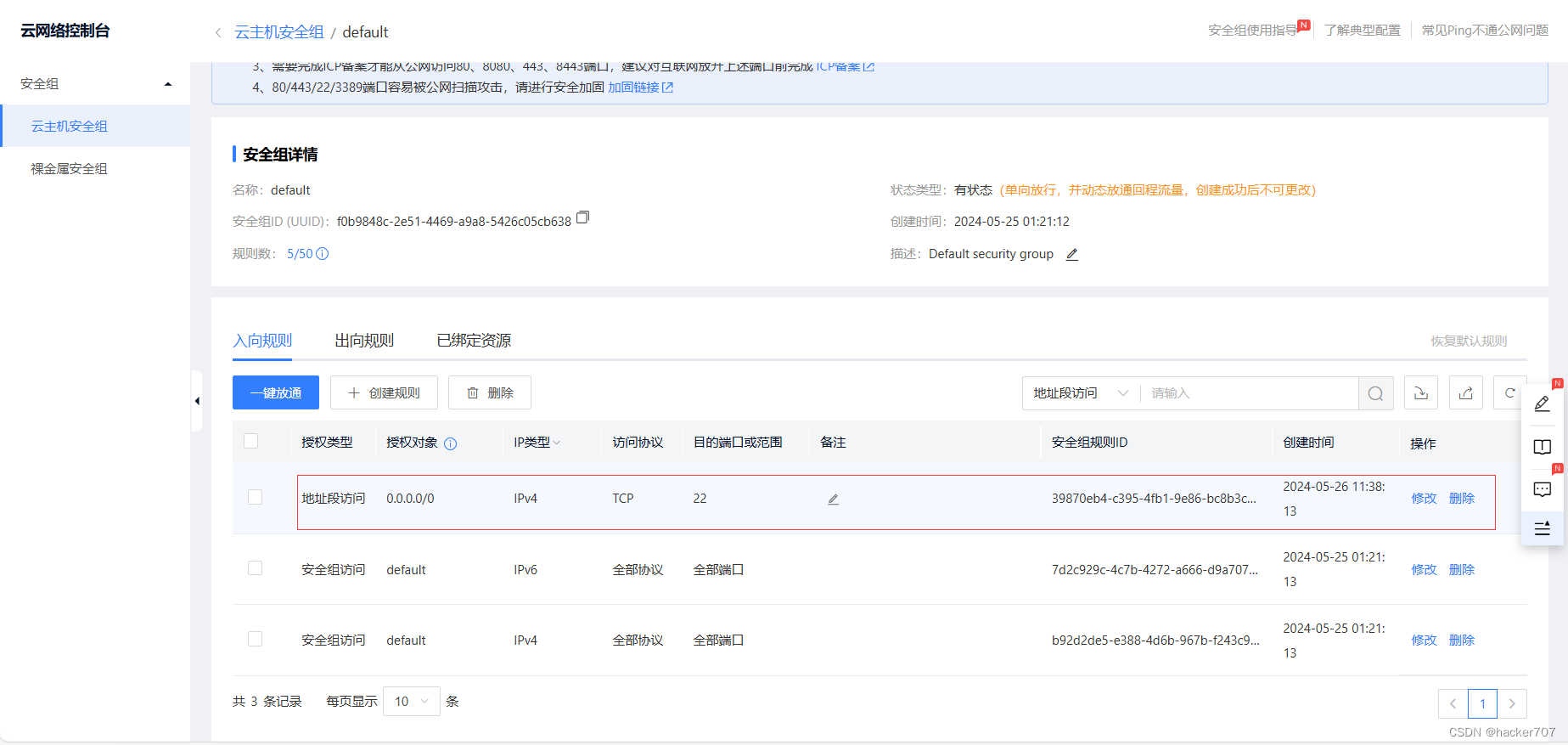
远程登陆需要开放ssh端口(22)
-
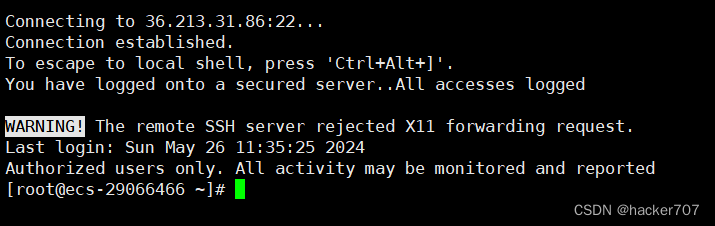
使用远程登陆软件,可以直接用vscode登陆,这里用xshell演示。
环境准备
- 安装 Python 环境
在Linux操作系统中,尽管通常会预装Python解释器,但其版本往往较低,可能不符合ChatGLM所需的最小Python版本要求(3.7及以上)。因此,在大多数情况下,用户需要部署一个符合要求的Python环境。然而,如果系统已经配备了满足条件的Python版本,则无需重复安装。
尽管可以选择从源代码下载并编译安装Python,但为了简化安装过程,确保PyTorch等库的顺利安装,并避免对系统稳定性造成影响,推荐使用Anaconda发行版来安装Python环境。
# 下载 conda 安装包
wget https://repo.anaconda.com/archive/Anaconda3-2023.03-1-Linux-x86_64.sh
# 安装 conda 注意安装过程中指定安装路径
bash Anaconda3-2023.03-1-Linux-x86_64.sh
# 配置软连接
ln -s /[your-install-path]/anaconda3/condabin/conda /usr/bin/conda
- 安装 Git LFS
为了高效地从 Hugging Face Hub 上下载 ChatGLM 模型到本地,并提高加载模型的响应效率,推荐先安装 Git LFS(Large File Storage)。Git LFS 是一种适用于 Git 仓库的工具,它能够优化大文件的管理,使得文件传输更加高效。
sudo yum install git -y
git --version
sudo yum install git-lfs -y
模型安装
- 下载 ChatGLM3
首先,请从 Github 下载 ChatGLM3 仓库,并在仓库目录下使用 pip 安装所需的依赖。
根据官方推荐,为了获得最佳的推理性能,建议使用 transformers 库的 4.30.2 版本,以及 torch 2.0 或更高版本。
git clone https://github.com/THUDM/ChatGLM3
cd ChatGLM3
# conda 创建虚拟环境
conda create -n torch python=3.10
# 激活环境 # 退出环境 conda deactivate
conda activate torch
# 下载依赖包
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
- 下载预训练模型
下面我们用 Git LFS 从 Hugging Face Hub 将模型下载到本地,从本地加载模型响应速度更快。
git lfs install
git clone https://huggingface.co/THUDM/chatglm3-6b
如果从你从 HuggingFace 下载比较慢,也可以从 ModelScope 中下载!
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
模型使用
首先,将你从 THUDM/ChatGLM3-6b 下载的预训练模型文件保存在 ChatGLM3 仓库的适当目录中。如果你是通过 ModelScope 获取的模型,请确保目录结构正确,因为加载模型时可能需要调整本地的路径设置。
ChatGLM3 支持三种使用方式:命令行界面、网页版界面和 API 接口。在运行模型之前,你需要找到对应使用方式的 Python 源代码文件,即 cli_demo.py、web_demo.py 和 openai_api.py。在这些文件中,你需要修改一行代码,使其指向你的模型文件。
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).cuda()
修改两个地方:(1)本地模型的存放路径 THUDM/chatglm3-6b;(2)根据自己的硬件环境参考 DEPLOYMENT.md 选择模型加载方式,float() CPU 部署,cuda() GPU 部署。
- 命令行版 cli_demo.py
命令行启动方式,首先找到 ChatGLM3 目录下的 cli_demo.py 文件,修改代码如下:
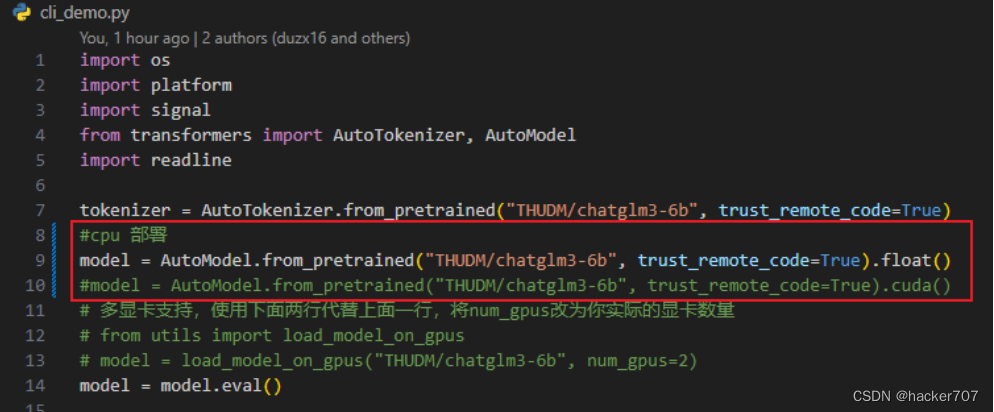
修改完成之后,到 ChatGLM3 目录下运行 python cli_demo.py 启动服务
程序会在命令行中进行交互式的对话,在命令行中通过 用户: 进行输入指示,直接输入问题回车即可生成回复,输入 clear 可以清空对话历史,输入 stop 终止程序。

2. 网页版 web_demo.py
网页版和命令行相似,但是提供了更加友好交互页面,找到 ChatGLM3 目录下的 web_demo.py 文件,做出相同的代码修改,
然后,到 ChatGLM3 目录下运行 python web_demo.py 启动服务
程序会运行一个 Web Server,并输出一个访问地址,在浏览器中打开输出的地址即可使用。
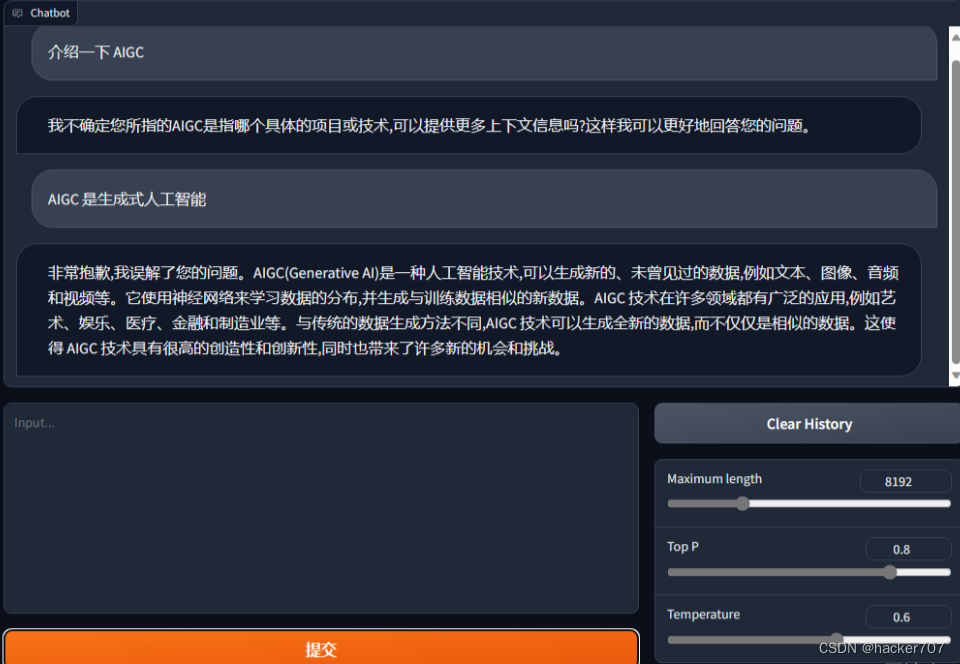
3. API 部署 openai_api.py
这个部分将结合 ChatGPT-Next-Web为例,使得ChatGLM3 实现了 OpenAI 格式的流式 API 部署,这使得ChatGLM3可以作为任意基于 ChatGPT 的应用的后端。
首先,到 https://github.com/Yidadaa/ChatGPT-Next-Web/releases 下载 ChatGPT-Next-Web,这个交互页面很轻量级。
然后,到 ChatGLM3 目录下找到 openai_api.py 源码文件,和上面方式一样,修改本地模型路径和部署方式,还有根据自己需要修改最后一行代码中定义的 Host 和 Port,这是 ChatGPT 应用的访问 URL。

接着,在仓库目录下执行 python openai_api.py 启动模型服务

然后将日志打印出的接口地址 http://localhost:8000/ 写入 ChatGPT-Next-Web 的设置中,并添加自定义模型 chatglm3
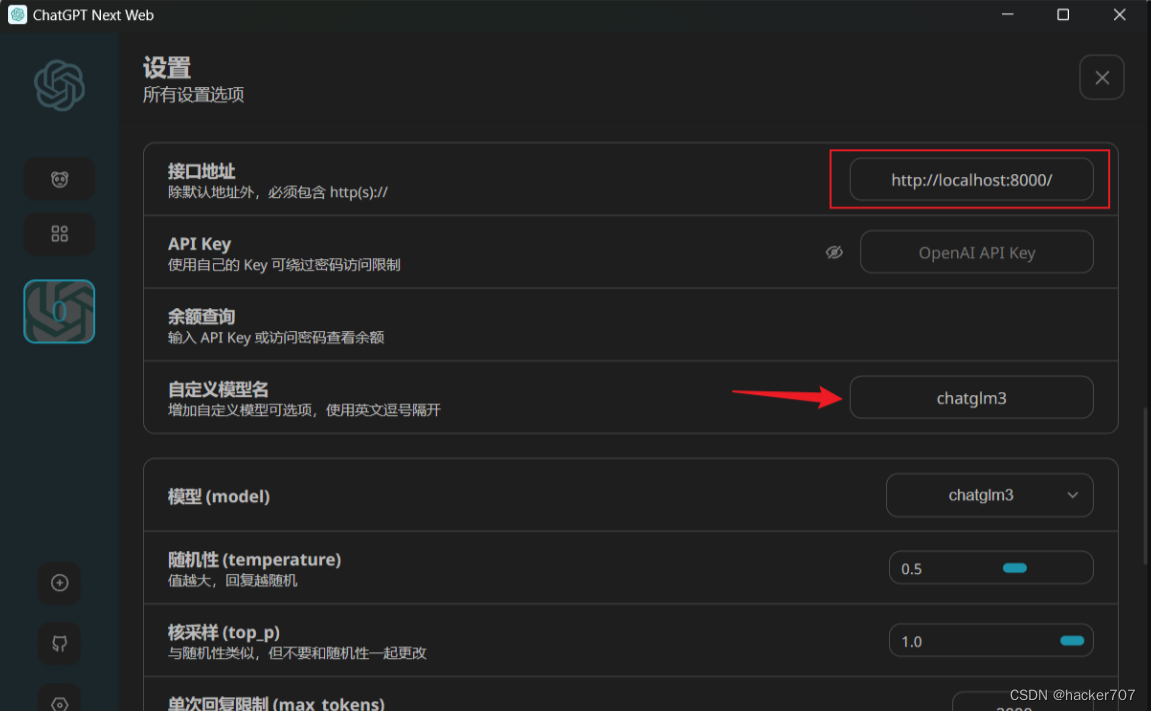
完成设置之后,API部署就完成了。
结束语
了解更多移动云产品请移步官网移动云官网