上一篇如下
视频拼接融合产品的产品与架构设计(三)内存和显存单元数据迁移
视频合并单元说明
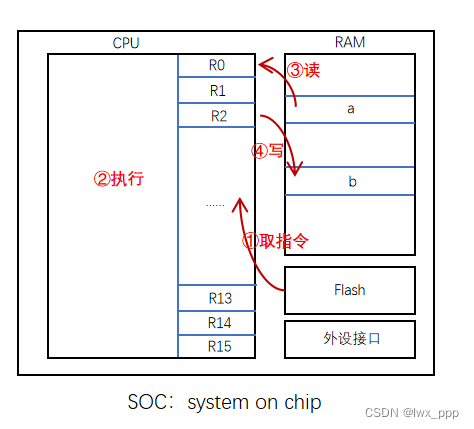
对下面这张图做些说明,视频接入是比较常见,可以说是普通,但是做到接入后随即进行比较重的算法运算,这个在视频领域并不多见,可以说做得好的几乎没有,而要做到在分布式上再把视频接入再进行合并,是比较难的,我们的选择也都在前面几章里面,就是把视频在gpu上处理,在没有nvlink或者其他显卡合并数据的方式下,通过gpu方式下放到内存进行合并。

嵌入式说明
如果不是x86 架构的模式下,不一定存在显存,即:不是拥有单独分配的显存而是使用共享内存
1 英伟达nvidia的内存体系里面,他是有一体化内存这个概念的,只要查询以下这个api,就可以得到更多信息
#include <cuda_runtime.h>
int main() {
float* data;
cudaMallocManaged(&data, size, cudaMemAttachGlobal);
// ...
return 0;
}
2 rk3588
RK3588芯片集成的是ARM Mali G610 GPU,该GPU并没有独立的显存(dedicated video RAM),而是采用共享系统内存(Unified Memory Architecture,UMA)的设计。这意味着GPU与CPU共享同一块物理内存(通常是LPDDR4x或LPDDR5)
3 华为昇腾310b4
也是一样没有显存单元,这个时候都是利用其他方式去操作硬件。这是我的另外一篇文章,可以参考一下
华为昇腾CANN使用opencv4.9
编码预置
接下来我们还是说在有显存的情况下,我们必须下放到内存去合并,
我们依然使用ffmpeg去编码,由于使用分布式方式处理图像,并且涉及到多个gpu 设备合并数据,合并单元单独成为一个block, 我们创建好AVFrame,并且直接从gpu 把数据down到AVFrame内存单元中,注意他们各自的linesize, 由于需要硬件编码,我们采用nv12 的数据下载,因此涉及到NV12 的两个平面,Y品面和UV平面,相应的,ffmpeg的数据同样涉及data[0] 和data[1]
AVFrame* NV12Init(int w, int h)
{
AVFrame* frame = av_frame_alloc(); // 分配 AVFrame 结构体内存
frame->format = AV_PIX_FMT_NV12; // 设置像素格式为 YUV420P
frame->width = w; // 设置图像宽度
frame->height = h; // 设置图像高度
if (!frame) {
return NULL;
}
int ret = av_frame_get_buffer(frame, 0); // 分配图像数据内存
if (ret < 0) {
av_frame_free(&frame); // 释放 AVFrame 结构体内存
return NULL;
}
return frame;
}
转换测试
AVFrame* CreateNV12_2_BGR24Frame(int w1, int h1, int w2, int h2, AVFrame* src_frame)
{
int w = w1 + w2;
int h = h1 > h2 ? h1 : h2;
// 创建SwsContext
struct SwsContext* sws_ctx = sws_getContext(
w, h, AV_PIX_FMT_NV12, // 源格式、宽度、高度
w, h, AV_PIX_FMT_BGR24, // 目标格式、宽度、高度
SWS_BILINEAR, NULL, NULL, NULL); // 选择缩放算法等
if (!sws_ctx) {
// 错误处理
return NULL;
}
// 创建目标AVFrame用于BGR24数据
AVFrame* dst_frame = av_frame_alloc();
dst_frame->format = AV_PIX_FMT_BGR24;
dst_frame->width = w;
dst_frame->height = h;
if (av_frame_get_buffer(dst_frame, 0) < 0) {
// 错误处理
sws_freeContext(sws_ctx);
return NULL;
}
// 执行转换
sws_scale(sws_ctx, src_frame->data, src_frame->linesize,
0, src_frame->height, dst_frame->data, dst_frame->linesize);
sws_freeContext(sws_ctx);
return dst_frame;
}
单元测试
int main()
{
cv::cuda::setDevice(0);
cv::Mat image1 = cv::imread("d:/left.jpg");
cv::Mat image2 = cv::imread("d:/right.ipg");
if (image1.empty() || image2.empty()) {
std::cerr << "Failed to load input image!" << std::endl;
return -1;
}
int w1 = image1.cols;
int h1 = image1.rows;
int w2 = image2.cols;
int h2 = image2.rows;
cv::cuda::GpuMat g1;
g1.upload(image1);
cv::cuda::GpuMat g2;
g2.upload(image2);
void* c1 = createNV12Context(w1, h1, 0);
void* c2 = createNV12Context(w2, h2, 0);
swscale_gpu(c1, g1.data, g1.step);
swscale_gpu(c2, g2.data, g2.step);
w2 = 0;
h2 = 0;
AVFrame* frame = NV12Init(w1+w2, h1>h2?h1:h2);
download_gpu(c1, NULL, frame->data[0], frame->linesize[0], frame->data[1], frame->linesize[1]);
AVFrame* dst_frame = CreateNV12_2_BGR24Frame(w1, h1, w2, h2, frame);
// 创建cv::Mat对象,注意:OpenCV使用BGR通道顺序
cv::Mat image(dst_frame->height, dst_frame->width, CV_8UC3, dst_frame->data[0], dst_frame->linesize[0]);
cv::Mat imdst;
cv::resize(image, imdst, cv::Size(image.cols / 4, image.rows / 4), 0, 0, cv::INTER_LINEAR);
cv::imshow("BGR Image", imdst);
//av_freep(&frame->data[0]);
av_frame_free(&frame);
//av_freep(&dst_frame->data[0]);
av_frame_free(&dst_frame);
cv::waitKey(0);
}
后续的改变
后面我会改变产品形态,准备写视频湖仓一体平台,着手创建这个产品,视频拼接和融合只是一个小功能,也不打算自己做这种产品了,而是做出工具来让其他专业或者非专业的人来做,以插件的模式来提供便利。




![[Vulnhub]Vulnix 通过NFS挂载+SSH公钥免密登录权限提升](https://img-blog.csdnimg.cn/img_convert/9e8ac1bb31bdaea11cd53452eba24e7e.jpeg)






![QT安装和配置[安装注意点][QT找不到python27.dll][缩小空间]](https://img-blog.csdnimg.cn/direct/6656a766531540248b42805857ac16ac.png)


