1. 需求任务列表
以下描述易学大模型软件的web应用的功能。
- 用户注册
- 用户邮箱,密码,验证码
- 开启官方邮箱,用来发验证码(QQ 网易都支持开启smtp协议,找教程,用邮箱不用手机号是为了省买发短信云服务的钱)
- 验证码缓存于redis,5min内有效
- 验证密码长度,验证码是否正确
- 新用户信息保存于mysql,密码使用md5第三方库进行加密
- 用户登录
- 用户邮箱与密码登录
- 校验身份
- 根据用户身份信息(也即邮箱,但不要包含密码)生成token
- 将token附带在响应中,发回客户端
- 用户完善身份信息
- 如姓名、年龄、性别
- 对自己的简单介绍等
- 用户创建专属知识库
- 用户可以创建属于自己的知识库,独立于其他用户的知识库存在
- 用户可以批量上传任意格式的文件,并将其加入知识库中
- 用户创建新会话
- 用户可以舍弃之前的上下文,创建一个全新的会话
- 该会话用户自己独立的上下文环境
- 用户还原历史会话
- 用户可以还原之前的历史会话信息,联系上下文继续与大模型chat
- 用户进行文件上传会话
- 用户可以上传一个或多个文件,但不添加至向量知识库,仅就这几个文件与大模型对话
- 用户创建易学知识博客
- 仿照csdn等博客网站,可以创建标题,提供博客标签,选择博客封面等进行博客撰写
- 支持markdown富文本编辑器
- 以markdown格式在网页端显示
- 易学贴吧/论坛
- 按时间分页显示近期的博客
- 用户可以收藏某一篇易学博客
- 用户可以在一篇易学博客下进行评论
- 管理员后台
- 可以查看任意用户的知识库、博客、与大模型的历史会话
- 可以封禁某用户及其邮箱,并以邮件的方式通知该用户
- 可以解禁某用户及其邮箱,并以邮件的方式通知该用户
2. 硬盘数据库选型
Sqlite(轻量级嵌入式数据库)+SqlAlchemy(Python的orm框架)
Sqlite官网:SQLite Home Page
SqlAlchemy官网:SQLAlchemy - The Database Toolkit for Python
2.1. Sqlite
作为一个嵌入式数据库,Sqlite不以服务进程的方式存在,而是作为文件嵌入在应用进程中。

这里的db文件就是Sqlite的嵌入式数据库文件,每次需要操作数据库时,打开该文件进行curd,操作数据库的会话提交一个事务时(commit),保存修改到该文件。
2.2. SqlAlchemy
SqlAlchemy是Python的一个orm框架,支持多种数据库驱动程序。官方统一地将连接数据库的函数封装了起来(对于所有驱动,都是同一个函数):
from sqlalchemy import create_engine
engine = create_engine("sqlite://", echo=True)
例如sqlite的连接方式就是”sqlite://{你的sqlite的db文件的路径}”。当然,其他数据库也可以,比如通过mysqlconnector进行Mysql数据库的连接。
值得一提的是,SqlAlchemy支持了两种非常强大的机制:类型映射以及依赖管理。此外,他还提供了相当多的语法糖。
类型映射
ORM Mapped Class Configuration — SQLAlchemy 2.0 Documentation
可以将python中的数据类型映射到对应数据库支持的数据类型,采用一个关键词叫做Mapped:
id: Mapped[int] = mapped_column(primary_key=True)
name: Mapped[str]
fullname: Mapped[str] = mapped_column(String(30))
nickname: Mapped[Optional[str]]
例如,也许你不知道字符串类型在Sqlite数据库中的具体形式,那么你就可以用Mapped[str]来将python的字符串类型自动映射到Sqlite的字符串类型上,同样的,int,bool,byte等等都可以进行映射。
依赖管理
可以说是关系型数据库外键(Foreign Key)的一个重要机制。
假设现在一个用户(User)有多个与大模型的会话(Conversation),那么显然Conversation表中应该包含对应于用户表主键的外键(例如,User.id)。依赖管理机制可以显式地管理这种一对一、一对多、多对一、多对多的依赖。
在User表的python DDL中:
conversations: Mapped[List["Conversation"]] = relationship(back_populates='owner') # 拥有的会话集合
List[”Conversation”]意味着一个用户可以有多个会话。
在Conversation的python DDL中:
owner: Mapped["User"] = relationship(back_populates='conversations')
“User”意味着一个会话只能属于一个用户。
CURD语法糖
这种有很多,比如增:
session.add(Conversation(id=conv_id, conv_name=nc.conv_name, create_time=datetime.datetime.utcnow(),
user_id=nc.user_id))
session.commit()
这里可以通过对象类型反解析出在哪个表插入数据。
查:
result = session.query(Record).filter(Record.conv_id == conv_id).all()
filter过滤器将充当where的条件,all返回所有满足条件的记录的列表。
其他功能,自查官方文档即可。
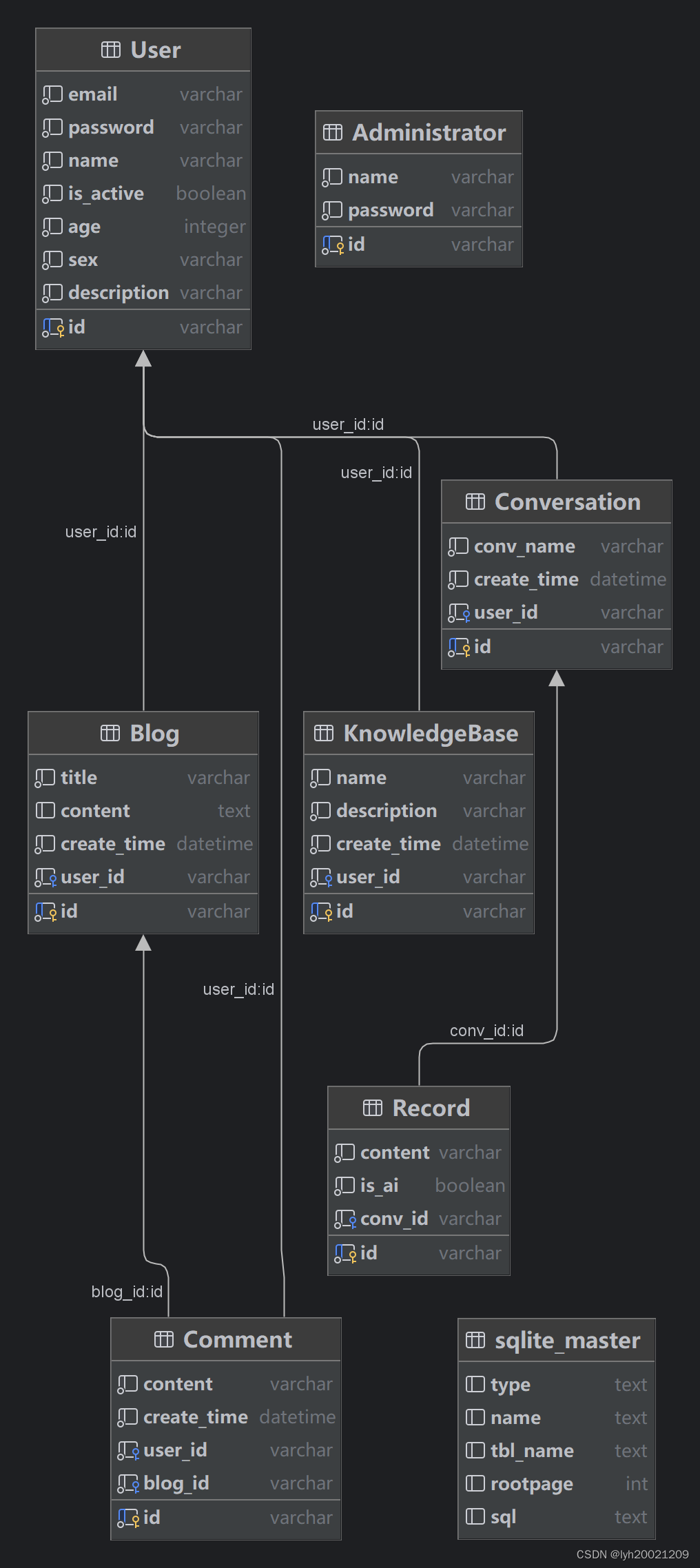
3. 数据库表设计
基于目前的需求,设计数据库表共七张:
- User:用户信息
- Conversation:用户与大模型会话信息
- Blog:用户博客信息
- KnowledgeBase:用户知识库metaData
- Comment:用户博客评论信息
- Record:用户与大模型对话记录信息
- Administrator:管理员信息
3.1. User表
class User(Base):
__tablename__ = 'User'
id: Mapped[str] = mapped_column(primary_key=True)
email: Mapped[str] = mapped_column() # 一个邮箱只能注册一个账号
password: Mapped[str] = mapped_column()
name: Mapped[str] = mapped_column()
is_active: Mapped[bool] = mapped_column(default=True) # 是否被封禁
age: Mapped[int] = mapped_column()
sex: Mapped[str] = mapped_column()
description: Mapped[str] = mapped_column()
conversations: Mapped[List["Conversation"]] = relationship(back_populates='owner') # 拥有的会话集合
blogs: Mapped[List["Blog"]] = relationship(back_populates='owner') # 拥有的博客集合
comments: Mapped[List["Comment"]] = relationship(back_populates='owner') # 拥有的评论集合
knowledge_bases: Mapped[List["KnowledgeBase"]] = relationship(back_populates='owner') # 拥有的知识库集合
def __repr__(self):
return f'<User(id={self.id}, email={self.email}, name={self.name})>'
3.2. Conversation表
class Conversation(Base):
__tablename__ = 'Conversation'
id: Mapped[str] = mapped_column(primary_key=True)
conv_name: Mapped[str] = mapped_column()
create_time: Mapped[datetime.datetime] = mapped_column(default=datetime.datetime.utcnow())
user_id: Mapped[str] = mapped_column(ForeignKey('User.id'))
owner: Mapped["User"] = relationship(back_populates='conversations')
records: Mapped[List["Record"]] = relationship(back_populates='conversation')
def __repr__(self):
return f'<Conversation(id={self.id}, conv_name={self.conv_name})>'
3.3. Blog表
class Blog(Base):
__tablename__ = "Blog"
id: Mapped[str] = mapped_column(primary_key=True)
title: Mapped[str] = mapped_column()
content: Mapped[Text] = Column(Text)
create_time: Mapped[datetime.datetime] = mapped_column(default=datetime.datetime.utcnow())
user_id: Mapped[str] = mapped_column(ForeignKey('User.id'))
owner: Mapped["User"] = relationship(back_populates='blogs')
comments: Mapped[List["Comment"]] = relationship(back_populates='blog')
def __repr__(self):
return f'<Blog(id={self.id}, title={self.title})>'
3.4. Comment表
class Comment(Base):
__tablename__ = "Comment"
id: Mapped[str] = mapped_column(primary_key=True)
content: Mapped[str] = mapped_column()
create_time: Mapped[datetime.datetime] = mapped_column(default=datetime.datetime.utcnow())
user_id: Mapped[str] = mapped_column(ForeignKey('User.id'))
blog_id: Mapped[str] = mapped_column(ForeignKey('Blog.id'))
owner: Mapped["User"] = relationship(back_populates='comments')
blog: Mapped["Blog"] = relationship(back_populates='comments')
def __repr__(self):
return f'<Comment(id={self.id}, content={self.content})>'
3.5. KnowledgeBase表
class KnowledgeBase(Base):
__tablename__ = "KnowledgeBase"
id: Mapped[str] = mapped_column(primary_key=True)
name: Mapped[str] = mapped_column()
description: Mapped[str] = mapped_column()
create_time: Mapped[datetime.datetime] = mapped_column(default=datetime.datetime.utcnow())
user_id: Mapped[str] = mapped_column(ForeignKey('User.id'))
owner: Mapped["User"] = relationship(back_populates='knowledge_bases')
def __repr__(self):
return f'<KnowledgeBase(id={self.id}, name={self.name})>'
3.6. Administrator表
class Administrator(Base):
__tablename__ = "Administrator"
id: Mapped[str] = mapped_column(primary_key=True)
name: Mapped[str] = mapped_column()
password: Mapped[str] = mapped_column()
def __repr__(self):
return f'<Administrator(id={self.id}, name={self.name})>'
3.7. Record表
class Record(Base):
__tablename__ = "Record"
id: Mapped[str] = mapped_column(primary_key=True)
content: Mapped[str] = mapped_column()
is_ai: Mapped[bool] = mapped_column()
conv_id: Mapped[str] = mapped_column(ForeignKey('Conversation.id'))
conversation: Mapped["Conversation"] = relationship(back_populates='records')
def __repr__(self):
return f'<Record(id={self.id}, content={self.content})>'
4. ER图
5. 依赖倒置原则下的数据库连接
仿照Spring的容器机制,我们希望一个组件的生命周期是伴随web应用的启动而创建,伴随web应用的结束而销毁。其中数据库连接就是这样的一个组件。
所有这样的组件,均在component包下,数据库连接引擎只是其中一个:
# DB_engine.py
db_lock = Lock()
engine = None
def init_db_conn():
global engine, db_lock
db_lock.acquire()
engine = create_engine(f'sqlite:///{SQLITE_CONNECTION["location"]}')
# 注册连接监听 连接时开启外键约束(默认不开启)
@event.listens_for(engine, "connect")
def enable_foreign_keys(dbapi_connection, connection_record):
cursor = dbapi_connection.cursor()
cursor.execute("PRAGMA foreign_keys=ON;")
logging.info("Sqlite数据库已开启外键约束")
cursor.close()
db_lock.release()
其中,全局变量engine即为数据库连接引擎。在web应用初始化时,我们调用init_db_conn,随后每次操作数据库,均使用该engine。
这里需要注意的是,Sqlite数据库连接时默认不开启外键约束(例如你可以在User根本不存在的情况下插入一条Conversation),因此我们开启连接时的监听,通过SQL语句打开外键约束选项。