Exploring Hybrid Active-Passive RIS-Aided MEC Systems: From the Mode-Switching Perspective
abstract
移动边缘计算(MEC)被认为是支持延迟敏感和计算密集型服务的有前途的技术。 然而,随机信道衰落特性导致的低卸载率成为制约MEC性能的主要瓶颈。 幸运的是,可重构智能表面(RIS)可以缓解这个问题,因为它可以提高频谱效率和能源效率。 与采用完全主动或完全被动RIS的现有工作不同,我们提出了一种新型混合RIS,其中反射单元可以在主动和被动模式之间灵活切换。 为了实现延迟和能耗之间的权衡,通过联合优化传输时间、发射功率、接收波束成形向量、相移矩阵、模式切换因子、 放大因子、卸载比因子和用户计算能力,其中用户最大能量、RIS最大功率、最小计算任务、传输时间、卸载比因子、模式等约束 考虑了开关因子、无源单元的单元模量和计算能力。 考虑到上述问题的复杂性,我们开发了一种基于交替优化的迭代算法,通过结合逐次凸逼近法、变量替换和奇异值分解来获得次优解。 此外,为了更深入地了解该问题,我们考虑了涉及延迟最小化问题和能耗最小化问题的两种特殊情况,并分别分析了有源单元和无源单元数量之间的权衡。 仿真结果验证了该算法能够实现灵活的模式切换,并且显着优于现有算法。
introduction
background
物联网技术的发展和普及极大地促进了智能应用(如增强现实、自主导航、语音识别、电子医疗等)的实现[1]。 然而,这些应用和服务通常需要大量设备来执行计算密集型和延迟敏感的任务,这给尺寸受限和低功耗设备带来了巨大的挑战。 移动云计算利用来自远程的强大集中式云的计算和存储资源,被认为是卸载计算任务的有效方法[2]。 然而,虽然移动云计算可以增强用户的计算能力,但其应用仍然存在一些潜在的问题,例如难以忍受的高延迟以及长距离传输和回程导致的连接不稳定等。
为了补充移动云计算并解决这些潜在问题,移动边缘计算(MEC)作为传统移动云计算的延伸,已成为一种有前景的解决方案[3]。 与移动云计算不同,分布式MEC服务器部署在无线网络边缘,更接近用户,可以提供更低的延迟并节省回程带宽。 一般来说,MEC有两种卸载模式[4]:1)二进制卸载,适用于未分区的简单任务; 2)部分卸载,适用于由多个并行段组成的复杂任务。 然而,卸载过程仍然存在一些潜在的问题。 当信道条件较差时,卸载速率通常较低,这将导致较高的延迟,甚至比完全本地计算的性能更差。 因此,人们投入了大量的研究工作来研究如何在性能保证的情况下提高MEC的卸载率[5]-[10]。 一般来说,有四种典型的技术来解决这些问题[11]。 第一种技术是通过部署海量小型基站形成异构网络,可以提高接入可用性和频谱利用率[5]。 该技术允许用户选择其他边缘服务器进行协同卸载,将MEC服务器无法处理的任务进一步卸载到云中心,从而减轻计算负担[6]。 第二个技术是在基站部署大量天线,以增强阵列和分集增益以及干扰抑制能力[7]。 该技术可以在不增加发射功率和带宽的情况下有效提高频谱效率,已成为5G及其后的关键技术之一[8]。 第三种技术将可用带宽扩展到更高的频段,例如毫米波[9]。 毫米波技术因其巨大的带宽和高传输速率而适合MEC辅助系统,可以成倍地提高MEC的卸载能力。 第四种技术是将MEC功能部署到无人机上,无人机可以利用其机动性、灵活性和可操作性来维持信息的视距传输并提高卸载率,特别是当 通信基础设施被自然灾害摧毁[10]。 尽管上述技术能够有效提升MEC的性能,但也存在部署成本高、硬件结构复杂、能源成本高、信号处理复杂等问题。 因此,上述观察激励我们寻求6G时代MEC的其他有效解决方案。
近年来,可重构智能表面(RIS),也称为智能反射表面(IRS),受到学术界和工业界的广泛关注,并被公认为6G的潜在技术[12]、[13]。 由于其优势,RIS辅助无线通信在信道估计中引起了广泛关注[14]、[15]。 此外,RIS还促进了各种先进技术的发展,例如全息多输入多输出表面,它可以结合密集排列的亚波长贴片天线以实现可编程无线环境[16]。 与上述四种典型技术相比,RIS可以同时提高频谱效率和能量效率,且能耗低、成本低,为MEC辅助系统的稳定传输开辟了新途径。 到目前为止,已经有一些研究 RISaided 通信系统的工作[17]-[24]。 特别是,[17]针对单用户和多用户场景研究了延迟最小化问题,验证了与传统 MEC 辅助系统相比,RIS 可以显着减少延迟。 此外,RIS 辅助的 MEC 系统已扩展到无线供电通信网络,以提供可持续的能源供应并最大限度地减少能源消耗[18]。 文献[19]通过设计相移、数据大小、传输速率、功率控制和解码顺序对能耗进行了优化,证明了该算法的高能效。 此外,[20]中的作者探索了基于优化和数据驱动的解决方案,以最大化已完成的任务输入位数,提出了一种用于高效解决方案的三步块坐标下降算法,并构建了用于在线实现的深度学习架构,显示出有希望的 性能和实用性。 [21] 中的作者评估了 RIS 对计算性能的影响,其中考虑了部分计算卸载。 与以往的工作不同,工作[22]比较了时分多址(TDMA)和非正交多址(NOMA)方案用于上行链路卸载的性能,采用三种不同的RIS波束成形方案在系统性能和性能之间取得平衡。 信令开销。 为了获得可实现的速率和能耗之间的最佳权衡,[23]中通过 NOMA 考虑了计算能源效率最大化。 工作[24]将被动RIS扩展到主动RIS,研究主动RIS在不同多址方案下的性能。 此外,提出了混合TDMA-NOMA方案并验证了主动RIS的性能。
Motivation and Contributions
尽管进行了上述工作,RIS 辅助的 MEC 系统中的一些基本问题仍未解决。 一方面,无源RIS会受到“双路径损耗”效应,即级联通道的路径损耗远大于直接通道的路径损耗,这已成为制约RIS性能的重大瓶颈 -辅助MEC系统。 尽管存在一些方案来解决这个问题,例如部署大量反射单元以实现更高的无源波束形成增益,但这些方案将增加反馈信道中显着的相移反馈压缩开销[25],因此在 实践。 另一方面,有源RIS不仅可以像无源RIS一样调整相移来实现无源波束形成,而且可以放大接收到的信号,这确实可以减轻“双路径损耗”效应[26]。 然而,从RIS侧的能耗来看,RIS始终采用全主动式架构是不合理的,因为主动式RIS的功耗远高于被动式RIS,其功耗不容忽视。 此外,有一些工作表明主动 RIS 和被动 RIS 之间的优势是互补的 [27]、[28],即主动 RIS 并不总是优于被动 RIS。 因此,无论是完全主动的RIS还是完全被动的RIS都不能有效地发挥RIS的全部潜力。
受上述观察的启发,我们研究并分析了混合 RIS 辅助 MEC 系统1,其中混合 RIS 中的反射单元可以灵活地切换为两种模式,即被动模式和主动模式。 无源单元可以在反射单元切换到无源模式时通过调整相移来实现无源波束形成,而有源单元在反射单元切换到有源模式时不仅可以调整相移还可以放大接收信号。 通过应用模式切换方案,MEC系统可以实现无源RIS和有源RIS之间的性能互补,弥补各自的缺点,在保证低能耗的同时实现低延迟。 这使得MEC系统能够更好地适应各种通信场景和应用需求。 请注意,混合 RIS 辅助系统很少受到关注,并且只有 [29]、[30] 与这项关于混合 RIS 的工作相关。 然而,[29]中考虑了一种主动 RIS 和一种被动 RIS 的联合优化。 在给定功率预算下,[30]探索了混合RIS中主动和被动单元数量的优化,这与我们工作中给定反射单元数量下提出的模式切换方案不同。 本文的主要贡献总结如下。
对于混合RIS辅助MEC系统,每个用户基于部分卸载将其计算任务分为两部分。 一部分在本地计算,另一部分在混合 RIS 的帮助下通过 TDMA 协议卸载到 MEC。 为了实现时延和能耗之间的权衡,通过联合优化传输时间、发射功率、接收波束赋形向量、相移矩阵、模式切换因子、放大因子、卸载,使总成本最小化 比率因子,以及受用户最大能量约束、RIS最大功率约束、最小计算任务约束、传输时间约束、卸载比率因子约束、模式切换因子约束、单位模数约束的计算能力 无源单元的约束,以及计算能力的约束。
鉴于公式化问题的棘手性,我们开发了一种基于交替优化(AO)的算法,该算法采用变量替换法、逐次凸逼近(SCA)法和奇异值分解(SVD)法来获得相应的 次优解决方案。 具体地,基于线性最小均方误差(MMSE)检测获得接收波束形成矢量的闭合形式解。
为了更深入地了解主动和被动反射单元数量之间的权衡,我们将原始优化问题分别简化为延迟最小化问题和能耗最小化问题。 特别是,对于延迟最小化问题,我们推导了放大因子和活动单元数量的闭式解,这表明当信道条件较差时,所有反射单元将切换到活动模式,而反射单元将切换到活动模式。 当信道状况好于一定值时,设备将逐渐切换到被动模式。 对于能耗最小化问题,必须保证卸载要求。 当分流任务较大、或者发射功率较低、信道条件较差时,就会出现分流中断的情况。 然后,增加有源单元的数量和放大倍数可以有效提高分流速率,保证分流要求。
仿真结果验证了所提出的模式切换算法的有效性,并且所提出的算法优于基线算法。 此外,该算法下的反射单元可以在主动和被动模式之间灵活切换,以最小化总成本。
SYSTEM MODEL AND PROBLEM FORMULATION
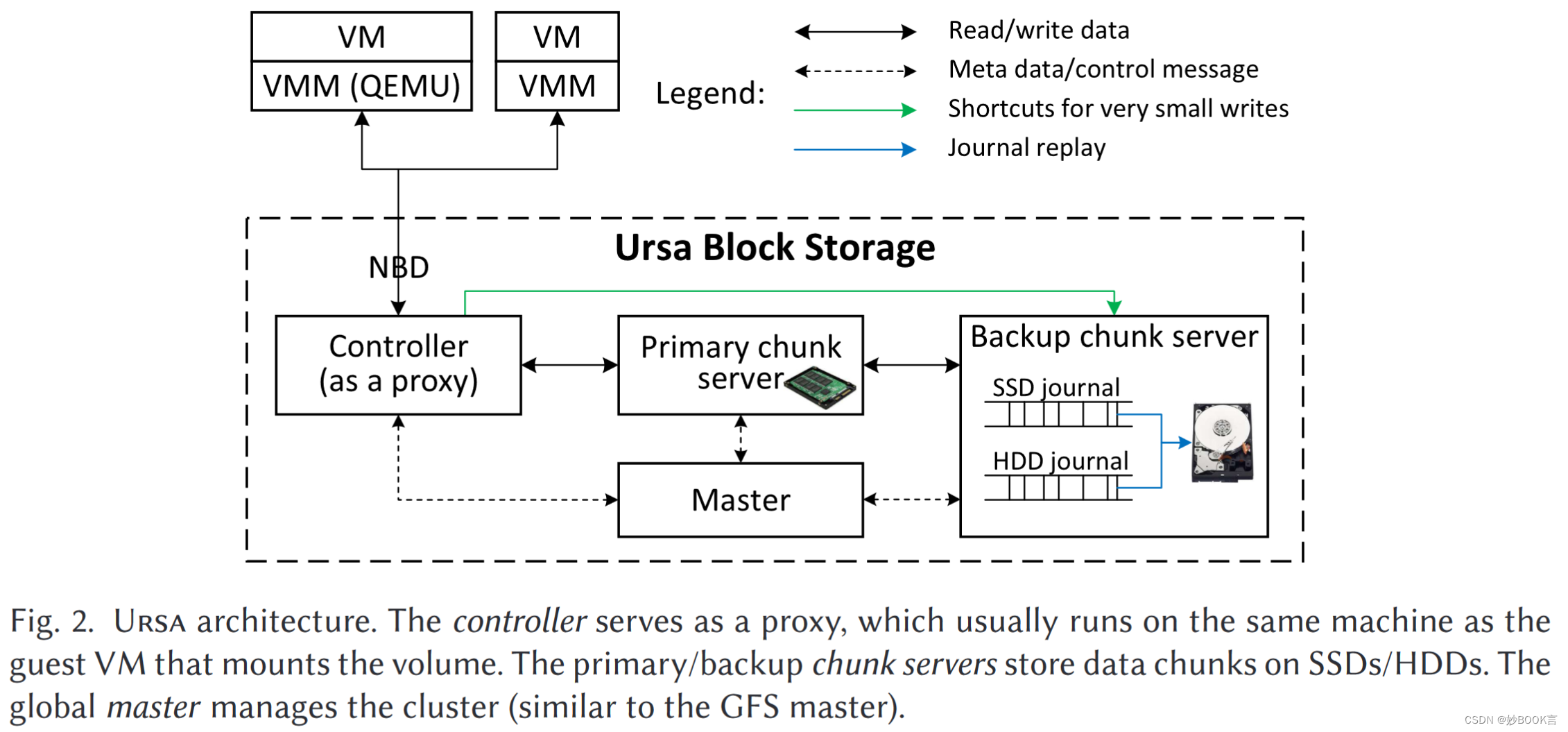
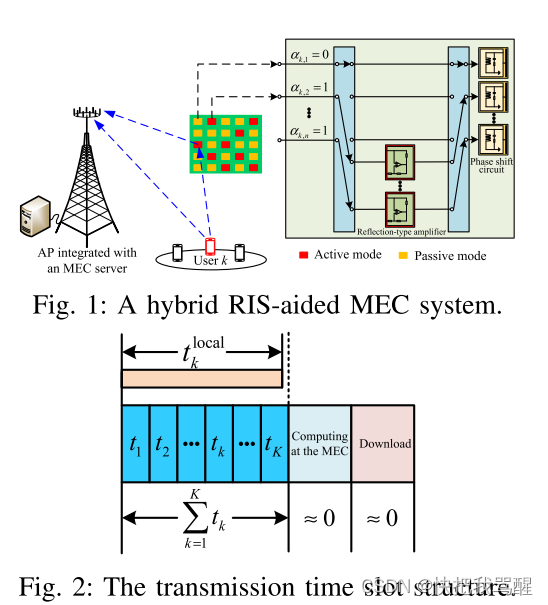
如图 1 所示,我们考虑一个混合 RIS 辅助 MEC 系统,由具有 M 个天线的接入点 (AP)、一个 MEC、一个混合 RIS 和 K 个单天线用户组成。 用户通过 TDMA 协议将任务卸载到 MEC。 AP 和 MEC 之间的延迟被认为可以忽略不计,因为假设 MEC 和 AP 位于同一位置并通过高吞吐量和低延迟光纤连接。 小区内部署配备N个反射单元的混合RIS,用于辅助用户的计算卸载,其中反射单元可以在主动模式和被动模式之间切换。 该系统假设准静态平坦衰落信道,其中信道状态信息(CSI)在信道相干帧内保持恒定,但可能针对不同的帧而改变。 所考虑系统的传输时隙结构如图2所示。这里,计算时间和下载时间可以忽略不计,因为MEC的计算能力比用户强得多,并且与计算结果相关的位数 非常小,在现有作品中普遍使用(参见,例如[35],[36])。 同时,每个用户可以在总卸载时间内执行本地计算,因为每个用户在计算单元和卸载单元之间具有独立的电路架构[36],[37]。
我们假设每个用户都有一个计算任务,并将 Tk = (Sk, Ck) 表示为用户 k 的任务,其中 Sk 是输入数据大小,单位是位。 Ck表示执行该任务所需的CPU周期总数,单位为cycle。 考虑部分卸载策略,其中每个用户通过本地计算和任务卸载来处理其计算任务。 下面给出本地计算过程和任务卸载过程。
Local Computing
定义 f k l o c a l f^{local}_k fklocal为用户k的计算能力,本地计算所需的时间由[4],[38],[39]给出
t k l o c a l = ( 1 − β k ) C k f k l o c a l , t_k^{\mathrm{local}}=\frac{(1-\beta_k)C_k}{f_k^{\mathrm{local}}}, tklocal=fklocal(1−βk)Ck,
其中βk表示卸载比率因子。 第k个用户进行本地计算的能耗可表示为[4],[38],[39]
E
k
l
o
c
a
l
=
(
1
−
β
k
)
C
k
κ
(
f
k
l
o
c
a
l
)
2
,
E_k^{\mathrm{local}}=(1-\beta_k)C_k\kappa{(f_k^{\mathrm{local}})}^2,
Eklocal=(1−βk)Ckκ(fklocal)2,
其中 κ 是取决于芯片架构的系数。
Task Offloading
AP 处接收到的信号公式为
y
k
=
(
h
d
,
k
+
H
H
Λ
k
Θ
k
h
r
,
k
)
p
k
s
k
+
H
H
A
k
Λ
k
Θ
k
z
k
+
n
k
,
\mathbf{y}_{k}=(\mathbf{h}_{\mathrm{d},k}+\mathbf{H}^{H}\mathbf{\Lambda}_{k}\mathbf{\Theta}_{k}\mathbf{h}_{\mathrm{r},k})\sqrt{p_{k}}s_{k}\\+\mathbf{H}^{H}\mathbf{A}_{k}\mathbf{\Lambda}_{k}\mathbf{\Theta}_{k}\mathbf{z}_{k}+\mathbf{n}_{k},
yk=(hd,k+HHΛkΘkhr,k)pksk+HHAkΛkΘkzk+nk,
在第 k k k 个用户的传输功率和卸载信号分别表示为 p k p_{k} pk 和 s k s_{k} sk 的情况下, h d , k ∈ C M × 1 \mathbf{h}_{\mathrm{d},k} \in \mathbb{C}^{M \times 1} hd,k∈CM×1 和 h r , k ∈ C N × 1 \mathbf{h}_{\mathrm{r},k} \in \mathbb{C}^{N \times 1} hr,k∈CN×1 分别表示从 k k k 个用户到AP和RIS的信道向量。 H ∈ C N × M \mathbf{H} \in \mathbb{C}^{N \times M} H∈CN×M 表示从RIS到AP的信道矩阵。 Θ k ≜ d i a g ( e j θ k , 1 , ⋯ , e j θ k , n , ⋯ , e j θ k , N ) \Theta_k \triangleq \mathrm{diag}(e^{j\theta_{k,1}}, \cdots, e^{j\theta_{k,n}}, \cdots, e^{j\theta_{k,N}}) Θk≜diag(ejθk,1,⋯,ejθk,n,⋯,ejθk,N) 是时间槽 k k k 中的对角相移矩阵,其中 θ k , n \theta_{k,n} θk,n 表示相应的相移。 A k = d i a g ( α k , 1 , ⋯ , α k , N ) \mathbf{A}_k = \mathrm{diag}(\alpha_{k,1}, \cdots, \alpha_{k,N}) Ak=diag(αk,1,⋯,αk,N) 表示模式切换矩阵。 Λ k = d i a g ( ρ k , 1 α k , 1 , ⋯ , ρ k , n α k , n , ⋯ , ρ k , N α k , N ) \mathbf{\Lambda}_k = \mathrm{diag}(\rho_{k,1}^{\alpha_{k,1}}, \cdots, \rho_{k,n}^{\alpha_{k,n}}, \cdots, \rho_{k,N}^{\alpha_{k,N}}) Λk=diag(ρk,1αk,1,⋯,ρk,nαk,n,⋯,ρk,Nαk,N) 表示反射放大矩阵,其中 ρ k , n α k , n \rho_{k,n}^{\alpha_{k,n}} ρk,nαk,n 表示第 n n n 个反射单元的放大因子。当 α k , n = 1 \alpha_{k,n}=1 αk,n=1 时,第 n n n 个反射单元的主动模式被激活,放大因子为 ρ k , n \rho_{k,n} ρk,n;否则,被动模式被激活,放大因子为1。 z k ∈ C N × 1 \mathbf{z}_{k} \in \mathbb{C}^{N \times 1} zk∈CN×1 是由于信号放大引入的主动反射单元的热噪声,假设服从独立的圆对称复高斯分布,即 z k ∼ C N ( 0 , σ 2 I N ) \mathbf{z}_k \sim \mathcal{CN}(\mathbf{0}, \sigma^{2} \mathbf{I}_{N}) zk∼CN(0,σ2IN)。 n k ∼ C N ( 0 , δ 2 I M ) \mathbf{n}_{k} \sim \mathcal{CN}(0, \delta^{2} \mathbf{I}_{M}) nk∼CN(0,δ2IM) 表示AP处的加性白高斯噪声(AWGN)。为了增强第 k k k 个用户卸载的信号,应用了一个波束成形向量 w k ∈ C M × 1 \mathbf{w}_k \in \mathbb{C}^{M \times 1} wk∈CM×1,且 ∥ w k ∥ 2 = 1 \|\mathbf{w}_k\|^2 = 1 ∥wk∥2=1。因此,AP处恢复的信号表示为
y k = w k H y k = w k H ( h d , k + H H Λ k Θ k h r , k ) p k s k + w k H H H A k Λ k Θ k z k + w k H n k . \begin{aligned} y_{k}& =\mathbf{w}_{k}^{H}\mathbf{y}_{k} \\ &=\mathbf{w}_{k}^{H}(\mathbf{h}_{\mathrm{d},k}+\mathbf{H}^{H}\mathbf{\Lambda}_{k}\mathbf{\Theta}_{k}\mathbf{h}_{\mathrm{r},k})\sqrt{p_{k}}s_{k} \\ &+\mathbf{w}_{k}^{H}\mathbf{H}^{H}\mathbf{A}_{k}\mathbf{\Lambda}_{k}\mathbf{\Theta}_{k}\mathbf{z}_{k}+\mathbf{w}_{k}^{H}\mathbf{n}_{k}. \end{aligned} yk=wkHyk=wkH(hd,k+HHΛkΘkhr,k)pksk+wkHHHAkΛkΘkzk+wkHnk.
然后,恢复的第 k 个用户信号的信号干扰加噪声比 (SINR) 为
γ
k
=
p
k
∣
w
k
H
(
h
d
,
k
+
H
H
Λ
k
Θ
k
h
r
,
k
)
∣
2
σ
2
∥
w
k
H
H
H
A
k
Λ
k
Θ
k
∥
2
+
δ
2
.
\gamma_k=\frac{p_k|\mathbf{w}_k^H(\mathbf{h}_{\mathrm{d},k}+\mathbf{H}^H\mathbf{\Lambda}_k\mathbf{\Theta}_k\mathbf{h}_{\mathrm{r},k})|^2}{\sigma^2\|\mathbf{w}_k^H\mathbf{H}^H\mathbf{A}_k\mathbf{\Lambda}_k\mathbf{\Theta}_k\|^2+\delta^2}.
γk=σ2∥wkHHHAkΛkΘk∥2+δ2pk∣wkH(hd,k+HHΛkΘkhr,k)∣2.
用 B Hz 表示系统带宽,第 k 个用户可实现的计算卸载率可表示为
R
k
=
B
log
2
(
1
+
γ
k
)
.
R_k=B\log_2(1+\gamma_k).
Rk=Blog2(1+γk).