.shp文件的存储结构是怎样的?底层读取shapefile文件
- 基础知识
- shp的存储结构
- python 字节流读取Shp文件

基础知识
大家都比较熟悉shp文件,它是GIS软件可以读取的矢量文件。但是大家知道它的存储结构吗?这次带着大家聊聊shp文件的存储结构,并尝试用python从底层读取一个点shp文件。
在此之前,需要大家了解一下字节和字节流的概念。
首先我们从最开始的二进制位讲起,二进制位就是计算机最最底层的语言,又可以表示为逻辑开(1)和关(0)。一位二进制位只能表示两种状态,要么是0,要么是1,但是如果多个二进制位组合在一起,那就可以表示很多状态(2^n)。另外我们都学过不同进制之间的转换,例如我们都会将10进制与2进制之间互相转换。
下面进入正题:我们将一个二进制位称为1bit,8bit,也就是8个二进制位构成一个字节。我们看一下一个字节可以表达的十进制范围
00000000(二进制)→0(十进制)
11111111(二进制)→255(十进制)
可以看到,一个字节可以表达256个数字,c语言中的char变量就是占用1个字节。另外,我们需要了解常见变量类型所占字节数,例如c语言中int整型变量占用4个字节,float类型占用4个字节,double占用8个字节。
实际上4个字节就可以表达很大的整数了,可以表达2^32个值,也就是4294967296个值,但通常整型加上正负号范围也就是:-2147483647~+2147483647,可以满足大部分需求,当然还有占用很多字节的长整型,可以占用8个字节(天文数字)。为了降低空间浪费,也有占用2个字节的短整型。
shp的存储结构
接下来我们就看一下shp的存储,对于非文本文件,例如图片和音视频,当然还包括各种乱七八糟的格式,我们需要以字节流的方式读取文件,而了解文件的存储结构是读取文件的基础。在用python读取之前,我们需要了解shapefile是如何字节存储的。
首先每个shp文件都有一个文件头,包括两部分内容:基本识别信息和空间信息概况,而且文件头的长度是固定的,一定包括100字节!文件头之后就是详细的空间记录信息。
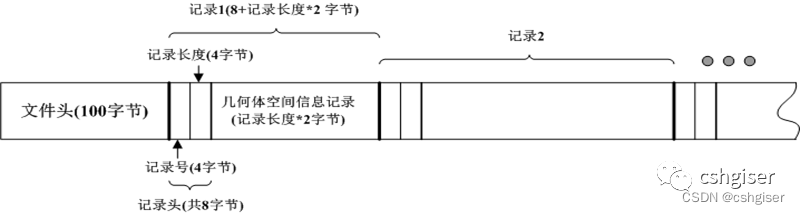
文件头包括内容如下:
| 变量 | 类型 | 占用字节 |
|---|---|---|
| 文件代码=9994 | int | 4 |
| 预留 | Int | 4 |
| 预留 | Int | 4 |
| 预留 | Int | 4 |
| 预留 | Int | 4 |
| 预留 | Int | 4 |
| 整个文件的长度(包括文件头,以双字节为单位) | int | 4 |
| 文件版本=1000 | Int | 4 |
| 几何体类型 | int | 4 |
| 所有X坐标最小值 | double | 8 |
| 所有Y坐标最小值 | double | 8 |
| 所有X坐标最大值 | double | 8 |
| 所有Y坐标最大值 | double | 8 |
| 所有Z坐标最小值 | double | 8 |
| 所有Z坐标最大值 | double | 8 |
| 所有M坐标最小值 | double | 8 |
| 所有M坐标最大值 | double | 8 |
| 合计 | 100 |
然后每个单独的空间记录信息都包括记录头和几何体记录信息两部分。其中,记录头共包括两个int类型,8个字节如下:
| 变量 | 类型 | 占用字节 |
|---|---|---|
| 记录号 | Int | Int |
| 记录长度(这个记录长度是几何体记录信息,也就是不包括记录头的空间信息记录长度,以双字节为单位) | Int | 4 |
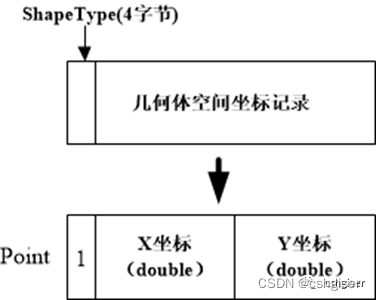
进一步,每个几何体记录信息分为两部分:shape类型(int类型,占用4字节)和空间坐标记录。
例如,最简单的,一个点坐标的记录固定占用20个字节,可以表示如下:
python 字节流读取Shp文件
下面开始用Python代码尝试用字节流读取shp文件!!!
首先,shp文件:
file_name= r'C:\Users\csh_g\Desktop\testdata\routeseg_ND_Junctions.shp'
然后,以二进制流读取模式打开文件:
f =open(file_name, "rb+")
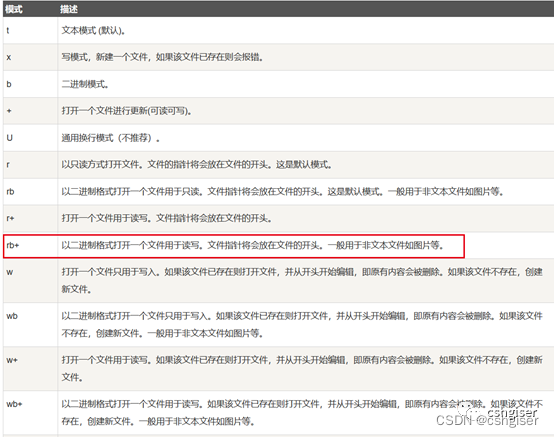
python open() 函数打开文件的读取模式(参考菜鸟教程)
然后读取第一个4字节,这个变量是文件代码,一定等于9994:
readStream= f.read(4)
fileCode= struct.unpack('>i',readStream)[0]
printfileCode
其中,struct.unpack() 就是解包的意思,把二进制解包为某一类型变量。第一个参数’i’就指定了将其解包为整型。
- 拓展:另外可以看到,i前还有个>号,是因为该数值在shp文件中按照大端(Big-endian)位序存储,位序指的是一个数字的各个数位在内存中的排列顺序,通常的PC平台都采用小端(Little-endian)位序,而在网络传输中通常采用大端为序,因此在PC机上读取shp文件时,这些大端位序整数要进过位序转换才能得到正确的数值。
剩下的读取文件头就不一一阐述,注释中都有说明:
# 读掉5个预留int
f.read(5*4)
# 文件长度
readStream = f.read(4)
fileLength = struct.unpack('>i',readStream)[0]
print fileLength
# 文件版本
readStream = f.read(4)
fileVersion = struct.unpack('i',readStream)[0]
print fileVersion
# 几何体类型
readStream = f.read(4)
shapeType = struct.unpack('i',readStream)[0]
print shapeType
# 最小空间矩形
readStream = f.read(8)
XMin = struct.unpack('d', readStream)[0]
print XMin
readStream = f.read(8)
YMin = struct.unpack('d', readStream)[0]
print YMin
readStream = f.read(8)
XMax = struct.unpack('d', readStream)[0]
print XMax
readStream = f.read(8)
YMax = struct.unpack('d', readStream)[0]
print YMax
readStream = f.read(8)
ZMin = struct.unpack('d', readStream)[0]
print ZMin
readStream = f.read(8)
ZMax = struct.unpack('d', readStream)[0]
print ZMax
readStream = f.read(8)
MMin = struct.unpack('d', readStream)[0]
print MMin
readStream = f.read(8)
MMax = struct.unpack('d', readStream)[0]
print MMax
接下来就需要我们读取空间信息了,由于每个几何记录是不定长的,所以在读取的过程中必须借助文件头和每个空间记录信息的记录头里的记录长度,并写循环读取。
下面是读取过程:
# 定义变量剩余文件长度,总字节长度减去之前读的100字节
fileRemainingLen = fileLength * 2 - 100
# 存储几何体
all_records = []
while fileRemainingLen > 0:
# 记录号
readStream = f.read(4)
recordID = struct.unpack('>i',readStream)[0]
fileRemainingLen -= 4
# 记录长度
readStream = f.read(4)
recordLen = struct.unpack('>i',readStream)[0]
fileRemainingLen -= 4
# 几何信息
recordRemainingLen = recordLen * 2
readStream = f.read(4)
shapeType = struct.unpack('i',readStream)[0]
fileRemainingLen -= 4
recordRemainingLen -= 4
if shapeType == 1: # 如果是点
# 存储单个几何体
record = []
while recordRemainingLen > 0:
# 一个点
readStream = f.read(8)
x = struct.unpack('d',readStream)[0]
recordRemainingLen -= 8
fileRemainingLen -= 8
readStream = f.read(8)
y = struct.unpack('d',readStream)[0]
recordRemainingLen -= 8
fileRemainingLen -= 8
record.append((x, y))
all_records.append(record)
print all_records
以上就是读取点shape的过程,就是辣么简单,最终,我打印出来的结果是这样的:
9994
28792
1000
1
0.17388360826
0.110210912643
4679.59934183
3331.86113716
0.0
0.0
0.0
0.0
[[(0.17388360826021199, 0.11021091264308325)], [(0.17388360826021199, 212.24160359604684)], [(0.17388360826021199, 238.02255434822587)], [(0.17388360826021199, 351.05137534680057)],……
- shapeType对应空间几何类型:
| 编号 | 集合类型 |
|---|---|
| 0 | Null Shape(表示这个Shapefile文件不含坐标) |
| 1 | Point(表示Shapefile文件记录的是点状目标,但不是多点) |
| 3 | Polyline(表示Shapefile文件记录的是线状目标) |
| 5 | Polygon(表示Shapefile文件记录的是面状目标) |
| 8 | MultiPoint(表示Shapefile文件记录的是多点,即点集合) |
| 11 | PointZ(表示Shapefile文件记录的是三维点状目标) |
| 13 | PolylineZ(表示Shapefile文件记录的是三维线状目标) |
| 15 | PolygonZ(表示Shapefile文件记录的是三维面状目标) |
| 18 | MultiPointZ(表示Shapefile文件记录的是三维点集合目标) |
| 21 | PointM(表示含有Measure值的点状目标) |
| 23 | PolygonM(表示含有Measure值的面状目标) |
| 25 | MultiPointZ(表示Shapefile文件记录的是三维点集合目标) |
| 28 | MultiPointM(表示含有Measure值的多点目标) |
以上是点shp图层的读取,即shapeType=1,存储结构最简单,相应读取也不麻烦,但若果是多义线,存储结构则更复杂,主要区别在于空间坐标记录部分。例如,多义线的空间坐标记录如下:
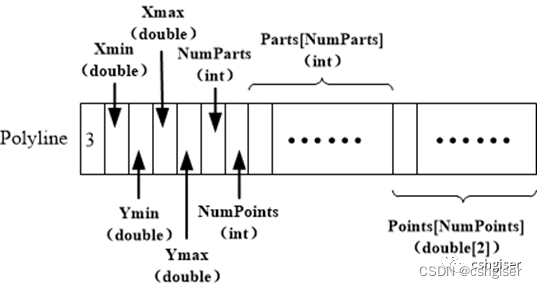 首先是前面4个double类型存储该要素的**最小包围矩形**;然后是**NumParts记录有多少分段**;然后是**NumPoints记录有多少坐标点**;然后是**Parts记录每个分段在坐标点集(Points)内的首点索引**;最后就是**Points坐标点集**了。
首先是前面4个double类型存储该要素的**最小包围矩形**;然后是**NumParts记录有多少分段**;然后是**NumPoints记录有多少坐标点**;然后是**Parts记录每个分段在坐标点集(Points)内的首点索引**;最后就是**Points坐标点集**了。
具体怎么读取大家可以尝试一下!!
- 拓展:为什么记录最小包围矩形?我们可以看到,无论是整个文件还是每个空间几何,都先都有最小包围矩形(minimum Bounding
rectangle,
MBR)。实际上这个MBR很有用处,尤其是空间数据量大的时候,我们做相交运算或查询操作,首先就是看MBR是否重合,只有MBR重合,才有可能两者相交或者在查询区域内。有了MBR就可以执行过滤-精简策略,很大程度上提高计算速度!