AIGC002-LoRA让大模型微调更加轻盈方便!
文章目录
- 0 论文工作
- 1 论文方法
- 2 效果
0 论文工作
这篇论文名为 LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS,作者是 Edward Hu 等人。它提出了一种名为 低秩自适应 (Low-Rank Adaptation, LoRA) 的新方法,用于高效地适应大型语言模型到下游任务。
随着预训练语言模型规模的不断增大,对模型进行全参数微调变得越来越困难。例如,为每个任务部署一个独立的 175B 参数的 GPT-3 微调模型成本过高。为了解决这个问题,LoRA 冻结预训练模型的权重,并在 Transformer 架构的每一层注入可训练的低秩分解矩阵,从而大大减少了下游任务的可训练参数数量。与使用 Adam 微调的 GPT-3 175B 相比,LoRA 可以将可训练参数数量减少 10,000 倍,GPU 内存需求减少 3 倍。LoRA 在 RoBERTa、DeBERTa、GPT-2 和 GPT-3 上的模型质量与微调相当或更好,尽管可训练参数更少,训练吞吐量更高,并且与适配器不同,没有额外的推理延迟。论文还对语言模型适应中的秩亏现象进行了实证研究,阐明了 LoRA 的有效性。
这是一个很显著且有效微调大模型的工具。
在2d图像生成中最常用的工具之一。在3d生成中也有应用。
1 论文方法
LoRA 的核心思想是将预训练权重矩阵的更新表示为低秩分解矩阵的乘积。 对于一个预训练权重矩阵
W
0
∈
R
d
×
k
W_0 \in \mathbb{R}^{d \times k}
W0∈Rd×k,LoRA 将其更新
Δ
W
\Delta W
ΔW 表示为:
Δ
W
=
B
A
,
\Delta W = B A,
ΔW=BA,
其中
B
∈
R
d
×
r
B \in \mathbb{R}^{d \times r}
B∈Rd×r,
A
∈
R
r
×
k
A \in \mathbb{R}^{r \times k}
A∈Rr×k,
r
r
r 是 LoRA 模块的秩,且
r
<
<
min
(
d
,
k
)
r << \min(d, k)
r<<min(d,k)。
在训练过程中,
W
0
W_0
W0 被冻结,不进行梯度更新,而
A
A
A 和
B
B
B 包含可训练参数。 修改后的前向传播变为:
h
=
W
0
x
+
Δ
W
x
=
W
0
x
+
B
A
x
.
h = W_0 x + \Delta W x = W_0 x + BAx.
h=W0x+ΔWx=W0x+BAx.
在部署时,可以将
W
0
+
B
A
W_0 + BA
W0+BA 预先计算并存储,进行常规推理。切换到另一个下游任务时,可以通过减去
B
A
BA
BA 并添加不同的
B
′
A
′
B'A'
B′A′ 来快速恢复
W
0
W_0
W0。

- 优点:
参数效率: LoRA 大大减少了可训练参数的数量,降低了存储和计算成本,并使得在资源有限的设备上进行模型适应成为可能。
高效的训练: LoRA 由于冻结了大部分参数,训练速度更快,GPU 内存需求更低。
无推理延迟: LoRA 可以在部署时将学习到的矩阵与冻结的权重合并,因此不会引入额外的推理延迟。
任务切换: LoRA 允许通过简单地交换 LoRA 权重在不同任务之间快速切换,而无需加载整个模型。
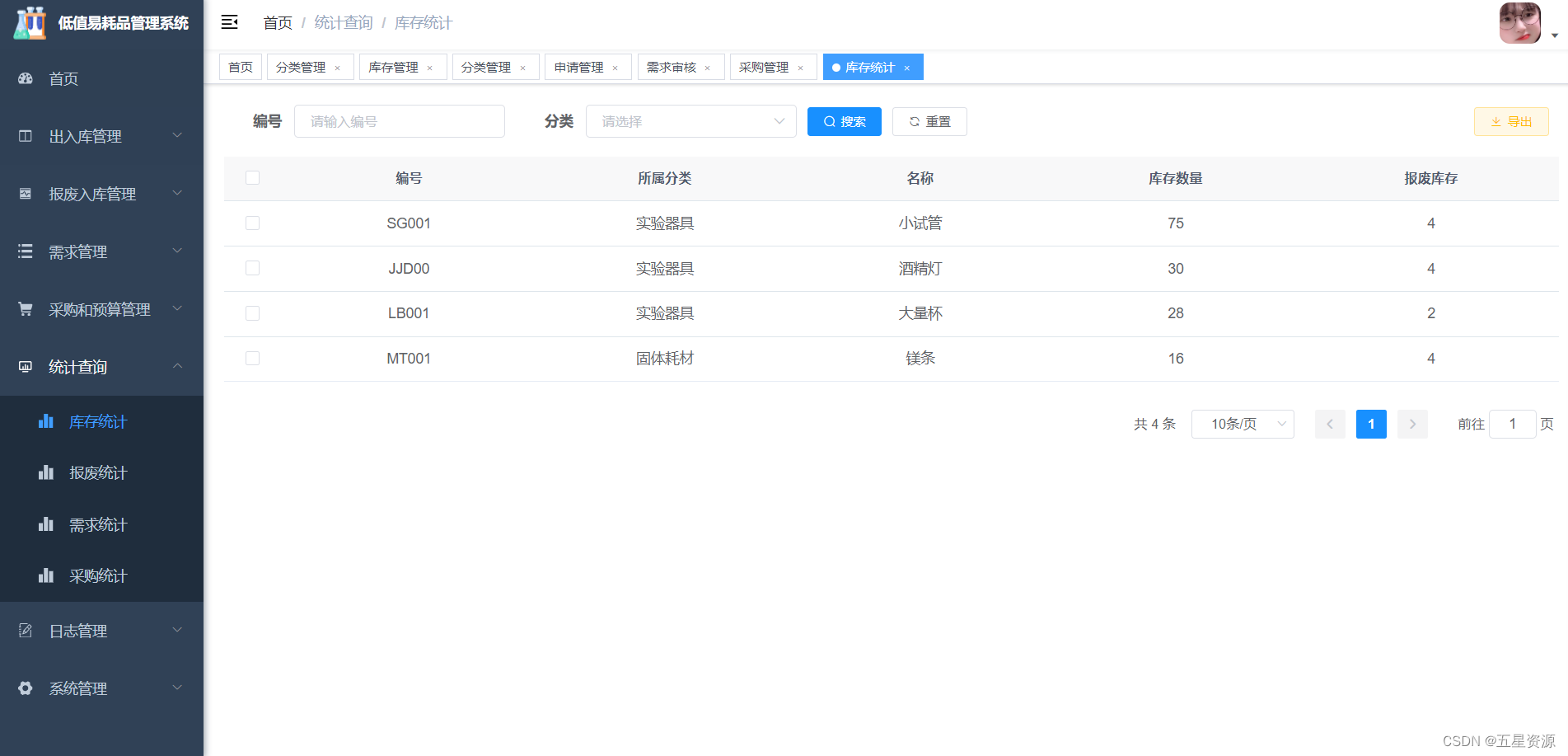
下面这个图可以看到d>>r所以微调的计算量显著降低,为什么能这么做,很多人从奇异值分解SVD来类比,认为用w种前r行r列相乘得到的矩阵和原来的矩阵保持基本一致的属性。

- 缺点:
并非所有任务都适用: 对于某些任务,LoRA 的低秩假设可能不成立,导致性能下降。
难以进行批量训练: 将 LoRA 应用于多个任务的批量训练时,需要为每个任务动态选择 LoRA 模块,增加了复杂性。 - SVD分解:
在线性代数中,奇异值分解(SVD)是将一个实或复矩阵分解为一个旋转矩阵、一个重新缩放矩阵和另一个旋转矩阵的因式分解方法。它将方阵的特征分解推广到任意 m×n 矩阵,该方阵具有正交特征基。
具体而言,奇异值分解(SVD)将一个m*n复矩阵 M 分解为以下形式的因式分解:
M = U Σ V ∗ \mathbf{M} = \mathbf{U \Sigma V^*} M=UΣV∗
其中,U 是一个 m×m 复酉矩阵,Σ 是一个 m×n 的对角矩阵,对角线上的元素为非负实数,V 是一个 n×n 复酉矩阵,而$ V ^∗$是V 的共轭转置。对于任何复矩阵,这种分解总是存在的。如果 M 是实数矩阵,则 U 和 V 可以是实正交矩阵;在这种情况下,SVD 通常表示为:
U
Σ
V
T
\mathbf{U \Sigma V^T}
UΣVT

在另外一个图M用A替代,SVD的分解可以用三个矩阵中每个的一小部分相乘得到和原来矩阵相似的矩阵。LoRA证明了一个类似的理论。

2 效果
实际LoRA可以用于任意的网络结构,不管是原始提出用在大语言模型上的Transformer还是SD的UNet结构。后面有很多人在不同的LoRA衍生。
当然我们也说过每个问题从不同角度去考虑的时候都有不同的调整方式。对于SD来说,也有dreambooth这种微调策略,也有超网络controlnet方式,还有插入新的没见过词向量
v
m
v_m
vm的这种方式。在科研路上的很多问题都在等不同研究者从不同角度去解析。也在等待不同的研究者提出一个个好的问题。