论文:SeaD: End-to-end Text-to-SQL Generation with Schema-aware Denoising
⭐⭐
NAACL 2022, arXiv:2105.07911
本论文提出 SeaD 模型,使用 schema-aware 的去噪方法来训练一个 end2end、seq2seq 的 Transformer 模型来实现 Text2SQL。
一、论文速读
给定一个 question Q Q Q 和一个 schema S S S,我们期望生成相应的 SQL 查询 Y Y Y。
1.1 model 的输入输出
SeaD 的输入输出如下图所示:
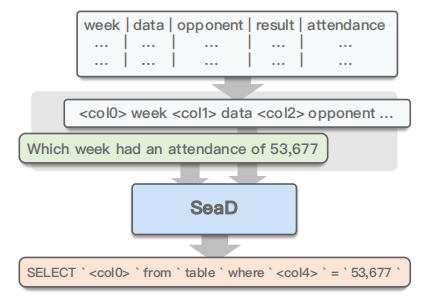
在 input 中,将 table headers 的各个 column name 前面加一个 <col n> 表示第几个 column,然后跟着 column name 和 type,比如对于 week 字段,就是 <col0>week:int。
在期待的 output 中,SQL 的 column name 使用 “`” 这个 token 围绕,并将 name 换为分隔符 <col n>,如上图所示。
1.2 Transformer with Pointer
该工作使用 Transformer 作为 backbone 来做 seq2seq 任务。
为什么使用 Transformer with Pointer?在 Text2SQL 任务中,大多数的 schema 和 value mentions 可以从 input seq 中抽取出来,所以在 Transformer 架构的最上面加了一个 Hybrid Pointer Generator Network 来生成 token,生成的 token 来自于 target vocabulary V V V 或者 copy from the input text。
target vocabulary V V V 由三个集合组合而成:
- V q V_q Vq 表示 corpora token vocabulary
- V c V_c Vc 表示 column token set
- V s V_s Vs 表示可用的 SQL keywords
Transformer with Pointer 的具体思路可以参考原论文,这里做一个概述:使用 Transformer 中 decoder 生成的 h d e c h_{dec} hdec 计算出 target vocabulary V V V 中各个 token 的 unnormalized scores s c o r e s v scores_{v} scoresv 和 input seq 中各个 token 的 unnormalized scores s c o r e s s scores_{s} scoress,然后将两个 scores 合并为 s c o r e h y b r i d score_{hybrid} scorehybrid,最终输出的概率分布就是 P = s o f t m a x ( s c o r e h y b r i d ) P = softmax(score_{hybrid}) P=softmax(scorehybrid)。
1.3 Schema-aware Denoising
与 masted LM 和其他去噪任务类似,这里提出了两个 schema-aware denoising 的训练方法:erosion 和 shuffle。
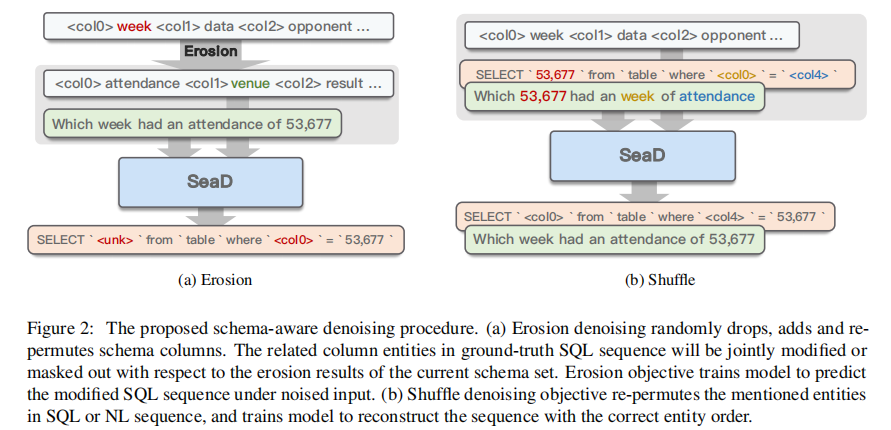
1.3.1 Erosion
参考上图,对 table schema
S
S
S 中的 column name 做 erosion 操作,主要是做重排、增加和删除操作来引入噪声,同时 <col n> 分隔符保持不变。
如果一个 column 被删除但是生成的 SQL 需要使用它,则生成 SQL 中使用 <unk> 来替代,这能让 model 学会当 schema 信息不足时抛出 unknown exception。
1.3.2 Shuffle
参考上图,将 source query Q Q Q 中的提及的实体(question 和 SQL)重新排序,而 schema seq S S S 保持不变。这个 denoisiong objective 训练模型重构实体顺序正确的查询序列 Q Q Q。
二、总结
实验在 test 结果上达到了 93 的准确率,但没有公开 code。但本文提出的思路还是值得学习的。