1.String类型基本介绍
redis 所有的 key 都是字符串,
value 的类型是存在差异的~~
一般来说,redis 遇到乱码问题的概率更小~~
Redis 中的字符串,直接就是按照二进制数据的方式存储的.
(不会做任何的编码转换【讲 mysql 的时候,知道 mysql 默认的字符集, 是拉丁文,插入中文,就会失败~~】,存的是啥,取出来就还是啥)
【不仅仅可以存储文本数据~~整数~~普通的文本字符串~~JSON~~xml~~二进制数据(图片,视频,音频....)(音频视频 体积可能会比较大~~Redis 对于 string 类型,限制了大小最大是 512M
Redis 单线程模型,希望进行的操作都能比较快速)】
2.set&get
2.1 set
- redis 文档给出的语法格式说明:
- []相当于一个独立的单元.
- 表示可选项 (可有可无的)
- 其中|表示"或者"的意思,多个只能出现一个,
- []和[]之间,是可以同时存在的.
- 如果 key 不存在,创建新的键值对,
- 如果 key 存在, 则是让新的 value 覆盖旧的 value.
- 可能会改变原来的数据类型,原来这个 key 的 ttl(生存时间) 也会失效
- flash all清除所有的数据库-对应MySQL的drop database

2.2 get
get key
对于 GET 来说, 只是支持,字符串类型的 value.
如果 value 是其他类型, 使用 GET 获取就会出错!!

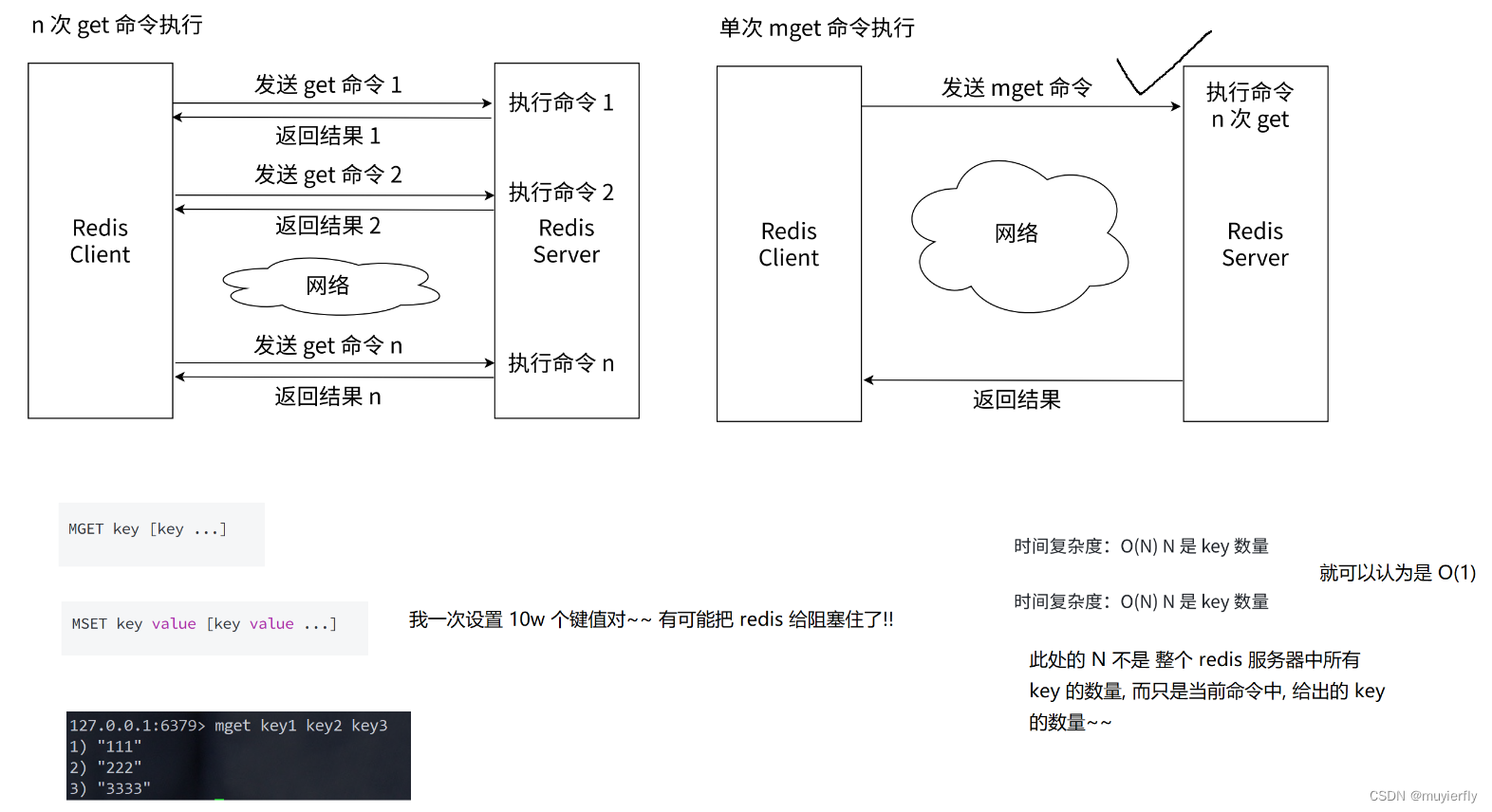
3.mset&mget
一次操作多组键值对。

可以提高效率 但也不要一次添加太多 会导致阻塞
4.SETNX&SETEX&PSETEX
- SETNX不存在才能设置.存在则设置失败~

- 返回值:1 表⽰设置成功。0 表⽰没有设置。
- SETEX设置 key 的过期时间,单位是秒
- PSETEX设置 key 的过期时间,单位是毫秒
5.incr&incrby&decr&decrby
incr
针对 value + 1
INCR将 key 对应的 string 表⽰的数字加⼀。如果 key 不存在,则视为 key 对应的 value 是 0。如果 key 对应的 string 不是⼀个整型或者范围超过了 64 位有符号整型,则报错。
- 命令有效版本:1.0.0 之后
- 时间复杂度:O(1)
- 返回值:integer 类型的加完后的数值。

incrby
针对 value + n
decr
针对 value -1
key 对应的 value 必须是整数,在 64位的范围内,如果这个 key 对应的value不存在则当做 0 来处理
decr 的运算结果,也是计算之后的值
decrby
针对 value -n
incrbyfloat
- 把 key 对应的 value 进行 +-运算,运算的操作数可以是浮点数。
- 只能用加上负数的形式来实现减法~~
- 虽然此处没有提供减法版本的命令,但是使用 redis 进行的计数操作,一般都是针对整数来进行的

- 上述操作的时间复杂度,都是 O(1)
- 由于 redis 处理命令的时候,是单线程模型,多个客户端同时针对同一个 key 进行 incr 操作,不会引起"线程安全”问题
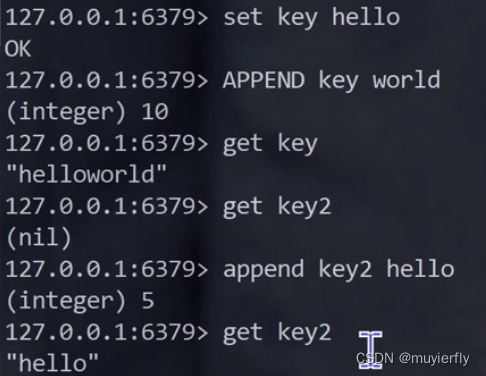
6.APPEND
- 字符串,也支持一些常用的操作.
- 拼接, 获取/修改 字符串的部分内容,获取字符串长度
append
- append 返回值, 长度的单位是 字节!!
- redis 的字符串,不会对字符编码做任何处理,(redis 不认识字符,只认识字节)
- 当前咱们的 xshell 终端,默认的字符编码是 utf8
- 在终端中输入汉字之后,也就是按照 utf8 编码的~~
- 1个汉字在 utf8 字符集中, 通常是 3 个字节的~
- 在启动 redis 客户端的时候,加上一个 --raw 这样的选项就可以使 redis 客户端能够自动的把二进制数据尝试翻译
- 操作 linux 的时候, 千万注意,不要乱按 ctrl +s
ctrl +s在 xshell 中的作用是"冻结当前画面"
ctrl + q 解除冻结~~



7.GETRANGE
返回 key 对应的 string 的⼦串,由 start 和 end 确定(左闭右闭)。可以使⽤负数表⽰倒数。-1 代表 倒数第⼀个字符,-2 代表倒数第⼆个,其他的与此类似。超过范围的偏移量会根据 string 的⻓度调整成正确的值。
- 由 start 和 end 确定(左闭右闭)
- redis 中指定的区间, 是闭区间!!!
- C++ 和 Java 中,谈到一个区间,大多都是 前闭后开(左闭右开)编程这个大圈子中,区间大多是前闭后开~~ 但是确实有特殊情况~~
- 正常下标都是 从 0 开始的整数,
- redis 的下标是可以支持负数的~~
- -1 倒数第一个元素.(Python 也是允许下标为 负数 的,此处的 规则 和 python 的设定是一致的)
- 下标为 len-1 的元素
- 如果字符串中保存的是汉字,此时进行子串切分,很可能切出来的就不是完整的汉字了~~
- 上述的代码,是强行切出了中间的四个字节.
- 随便这么一切,切出的结果在 utf8 码表上不知道能査出啥了~~
- 上述问题,在 C++ 中同样存在
Java 中就没事~
Java 中字符串的基本单位,是字符(ava 的字符, 占2 个字节的字符),帮我们把汉字的编码转换C++中字符串的基本单位是字节~~- Java 中相当于 String 帮我们把汉字的编码转换C++中字符串的基本单位是字节~~都处理好了~~
- C++这里头对于汉字的处理,是没那么完善的就需要程序猿手动处理了~~

8.SETRANGE
覆盖字符串的⼀部分,从指定的偏移开始。
语法:
SETRANGE key offset value
- 时间复杂度:O(N), N 为 value 的⻓度. 由于⼀般给的 value ⽐较短, 通常视为 O(1).
- 返回值:替换后的 string 的⻓度。
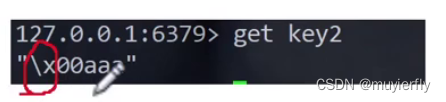
- 如果当前咱们 value 是一个中文字符串.进行 setrange 的时候, 是可能会搞出问题的!
- \x转义字符,16进制
- 凭空生成了一个字节,这个字节里的内容就是 0x00
- aaa 就被追加到 0x00 的后面了
setrange 针对 不存在的 key 也是可以操作的.不过会把 offset 之前的内容填充成0x00

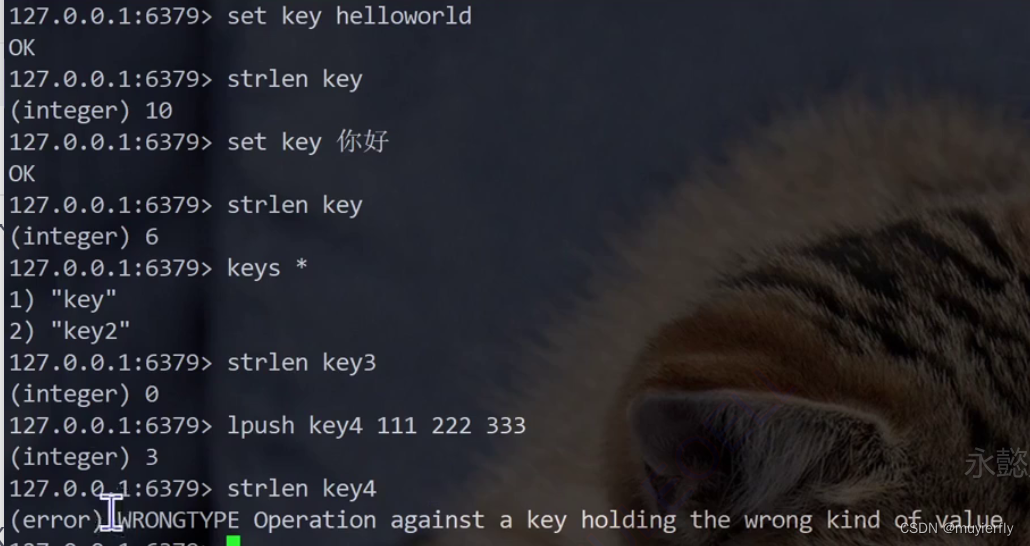
9.STRLEN
- 获取 key 对应的 string 的⻓度。单位是字节。
- 当 key 存放的类似不是 string 时,报错。
- C++中,字符串的长度本身就是用字节为单位,
Java 中,字符串的长度则是以字符为单位的.- Java 中的一个 char ==2 字节~~
Java 中的 char 基于 unicode 这样的编码方式
就能够表示中文等符号~~- MySQL 的时候.
varchar(N)
此处 N 的单位就是字符. mysq! 中的字符,也是完整的汉字
这样的一个字符,也可能是多个字节~~- 一个汉字通常是 3 个字节呀~~(编码方式是 utf8)Java 里头咋一个 2 字节的 char 就能表示汉字呢??【1个汉字几个字节是针对编码方式而言的】
- Java 中的 char 是用的 unicode.一个汉字使用两个字节的Java 中的 String, 则是用的 utf8.一个汉字就是3 个字节了Java 的标准库内部, 在进行上述的操作过程中,程序猿一般是感知不到编码方式的变换的~~
10.小节
| 命令 | 执⾏效果 | 时间复杂度 |
| set key value [key value...] | 设置 key 的值是 value | O(k), k 是键个数 |
| get key | 获取 key 的值 | O(1) |
| del key [key ...] | 删除指定的 key | O(k), k 是键个数 |
|
mset key value [key value
...]
| 批量设置指定的 key 和 value | O(k), k 是键个数 |
| mget key [key ...] | 批量获取 key 的值 | O(k), k 是键个数 |
| incr key | 指定的 key 的值 +1 | O(1) |
| decr key | 指定的 key 的值 -1 | O(1) |
| incrby key n | 指定的 key 的值 +n | O(1) |
| decrby key n | 指定的 key 的值 -n | O(1) |
| incrbyfloat key n | 指定的 key 的值 +n | O(1) |
| append key value | 指定的 key 的值追加 value | O(1) |
| strlen key | 获取指定 key 的值的⻓度 | O(1) |
| setrange key offset value | 覆盖指定 key 的从 offset 开始的部分值 |
O(n),n是字符 串⻓度, 通常视 为O(1)
|
| getrange key start end | 获取指定 key 的从 start 到 end 的部分值 |
O(n),n 是字符串⻓度, 通常视为 O(1)
|
![ChatGLM2-6B 模型基于 [P-Tuning v2]的微调](https://img-blog.csdnimg.cn/direct/59b132f34fa64e6d8128bb325732b79a.png)