InternVL 由 OpenGVLab 开发,是一个开源的多模态对话模型,其性能接近商业化的 GPT-4V 模型。
GPT-4V 是 OpenAI 去年推出的多模态模型,使用它你可以分析所需的任何类型的图像并获取有关该图像的信息。
1. InternVL 开源模型
而今天的主角研究成果 InternVL 发布在 CVPR 2024 上,并提供了多种模型版本以适应不同的应用场景,如 InternVL−Chat−V1.5 支持 4K 图像和强大的光学字符识别(OCR)功能。
开源地址:https://github.com/OpenGVLab/InternVL2. 支持特性
InternVL 家族通过提供多种模型版本,支持从图像分类到多模态对话的多种功能。以下是一些关键特性:
多语言支持:InternVL 能够支持超过 110 种语言的生成。
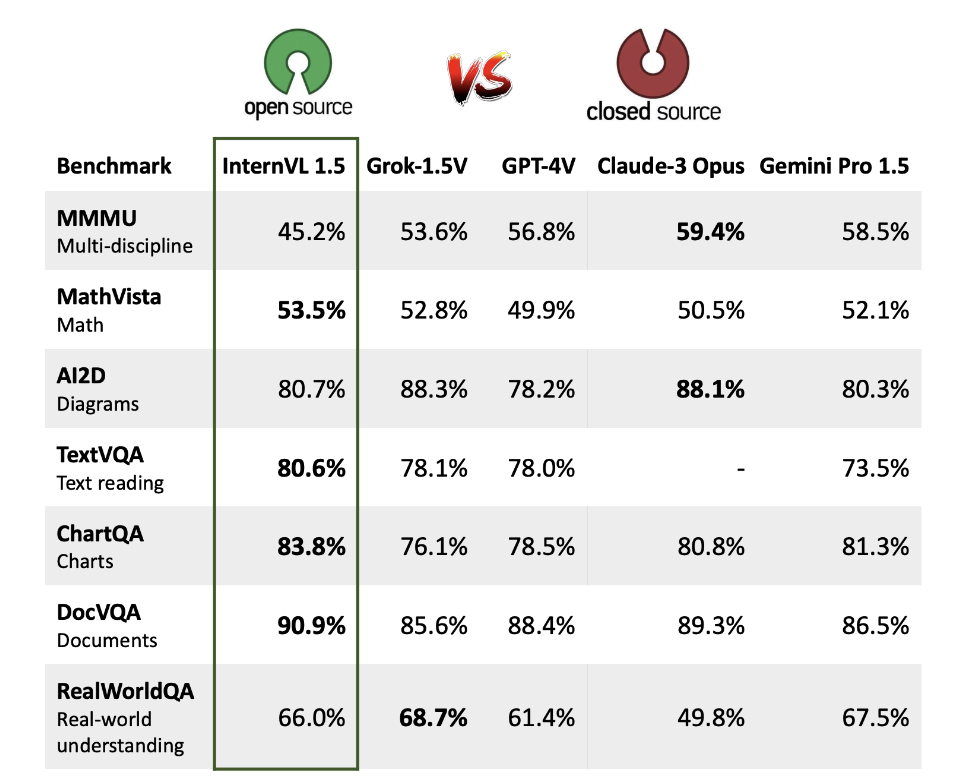
高性能:在多个基准测试中,InternVL-Chat-V1.5 接近 GPT-4V 和 Gemini Pro 的性能。
多种模型选择:提供了不同参数规模的模型,从 6B 到 19B 不等,以适应不同的计算资源和应用需求。
跨模态检索:支持英文和中文的零样本图像-文本检索,以及多语言零样本图像-文本检索。
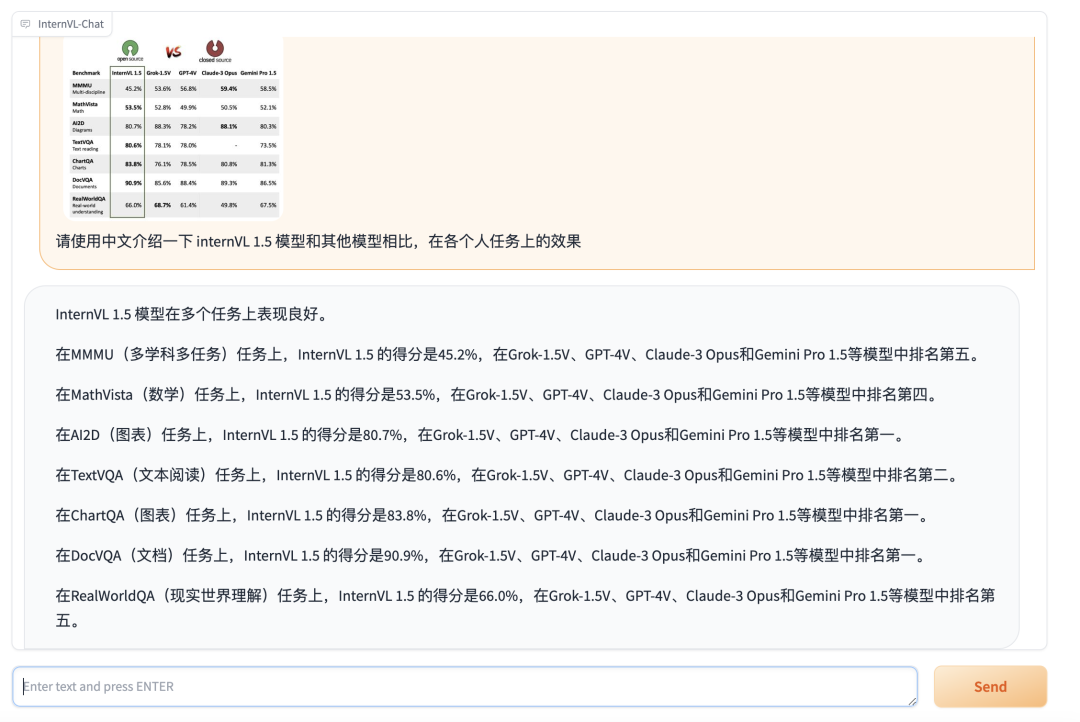
以下是 InternVL 在不同任务上的性能对比图:
3. 效果怎么样?
我把上图给到开源模型,让他自己介绍一下图片中的内容:
算个数学题:

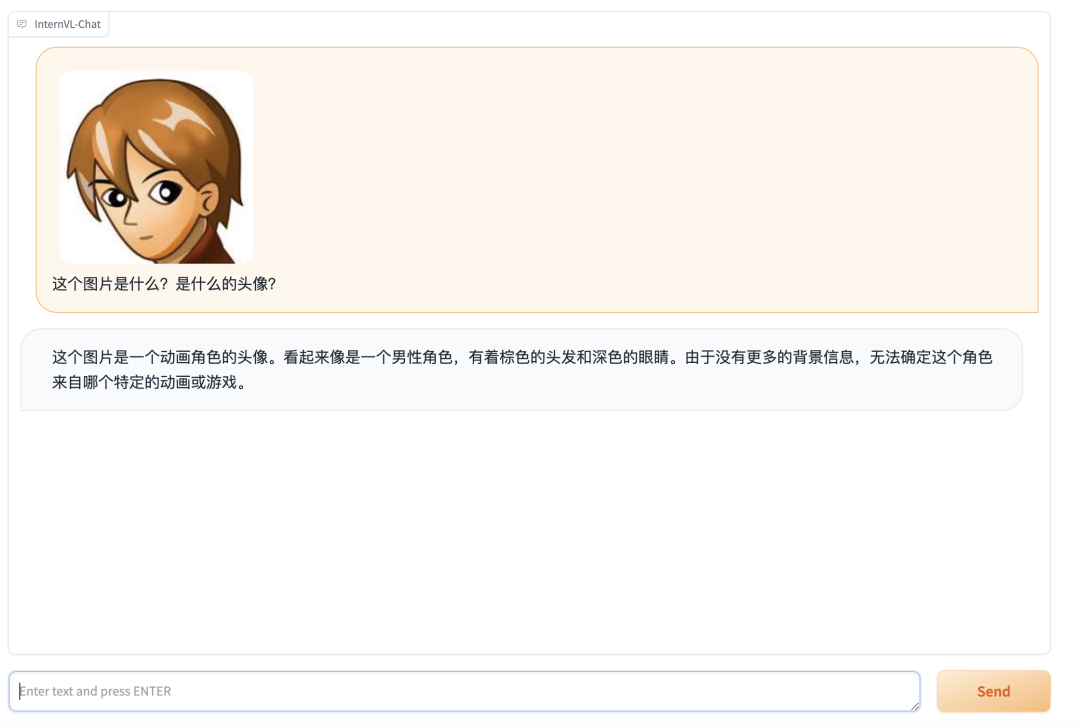
还能感知颜色:
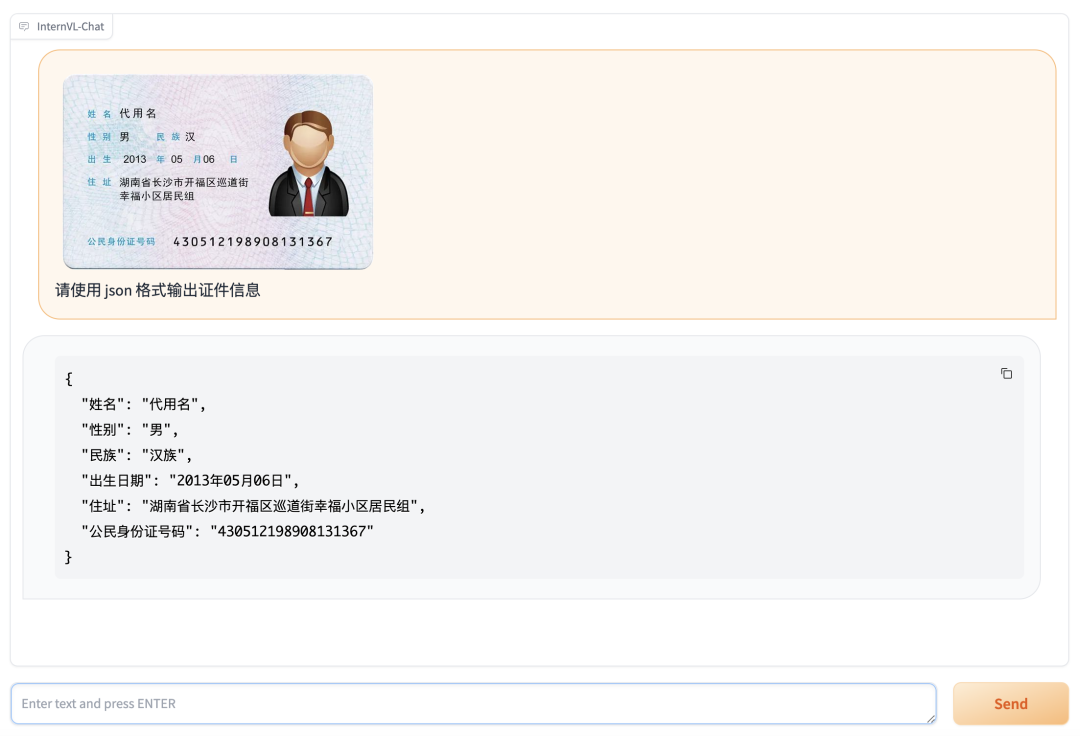
智能 OCR:
4. 代码示例
以下是使用 InternVL-Chat 模型进行单轮对话的示例代码:
from transformers import AutoTokenizer, AutoModel
import torch
import torchvision.transforms as T
from PIL import Image
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=T.InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
# 省略部分代码...
model = AutoModel.from_pretrained(
"OpenGVLab/InternVL-Chat-V1-5",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True).eval().cuda()
tokenizer = AutoTokenizer.from_pretrained("OpenGVLab/InternVL-Chat-V1-5", trust_remote_code=True)
pixel_values = load_image('./examples/image1.jpg', max_num=6).to(torch.bfloat16).cuda()
generation_config = dict(
num_beams=1,
max_new_tokens=512,
do_sample=False,
)
# 单轮对话
question = "请详细描述图片" # Please describe the picture in detail
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(question, response)历史盘点
逛逛 GitHub 每天推荐一个好玩有趣的开源项目。历史推荐的开源项目已经收录到 GitHub 项目,欢迎 Star:
地址:https://github.com/Wechat-ggGitHub/Awesome-GitHub-Repo
推荐阅读
1. GitHub 上有什么好玩的项目?
2. 推荐 5 个本周很火的 GitHub 项目
3. 推荐 5 个近期火火火的 GitHub 项目
4. 推荐 5 个令人惊艳的 GitHub 项目