导读
导读
目标检测作为计算机视觉的核心任务之一,其研究已经从基于CNN的架构发展到基于Transformer的架构,如DETR,后者通过简化流程实现端到端检测,消除了手工设计的组件。尽管如此,DETR的高计算成本限制了其在实时目标检测领域的应用。为了解决这一问题,研究人员通过设计高效的编码器和改进查询初始化方法,优化了DETR,使其能够适应实时场景,同时避免了NMS带来的延迟,推动了目标检测技术在速度和准确性上的进一步提升。
复杂场景下的检测能力图示:

文章目录
- 摘要
- 一、介绍
- 二、目标检测器相关工作
- 1.从DETR到实时检测的创新
- 2.利用多尺度特征提高性能
- 三、端到端速度的优势
- 1.对NMS的分析
- 2.Anchor-Free检测其在实时推理中的优势
- 四、The Real-time DETR
- 1.RT-DETR的结构
- 2.混合编码器
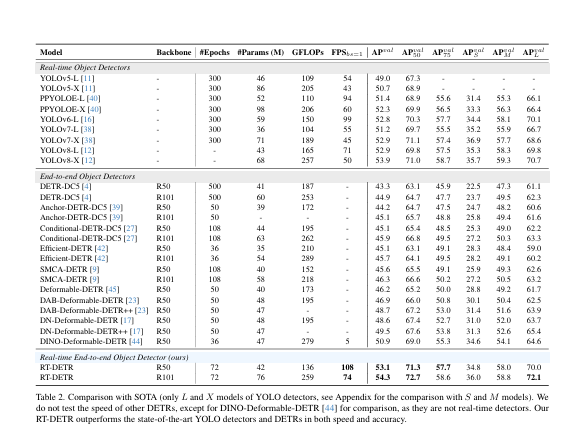
- 实验
- 1.与YOLO的比较
- 1.不同模块的消融研究
摘要
在这项工作中,作者提出了一个名为RT-DETR的实时端到端检测器,它成功地将DETR扩展到实时检测场景,并实现了最先进的性能。RT-DETR包括两个关键增强:一个高效的混合编码器,它可以迅速处理多尺度特征,以及最小化不确定性的查询选择,这提高了初始对象查询的质量。此外,RT-DETR支持灵活的速度调整,无需重新训练,并消除了由两个NMS阈值引起的不便,从而促进了其实际应用。RT-DETR及其模型扩展策略拓宽了实时目标检测的技术方法,为YOLO之外的多样化实时场景提供了新的可能性。
一、介绍
本文深入分析了现代实时目标检测器中非极大值抑制(NMS)对推理速度的负面影响,并提出了一种新型的Transformer架构——实时DEtection TRansformer(RT-DETR),它通过简化目标检测流程实现了端到端的检测。尽管如此,DETR的高计算成本问题仍然是其在实际应用中的一个限制。为了克服这一挑战,文中引入了IoU-Aware查询选择器,该方法在训练阶段利用IoU约束来优化解码器的初始目标查询,从而提供更高质量的查询,进一步提升了检测性能。
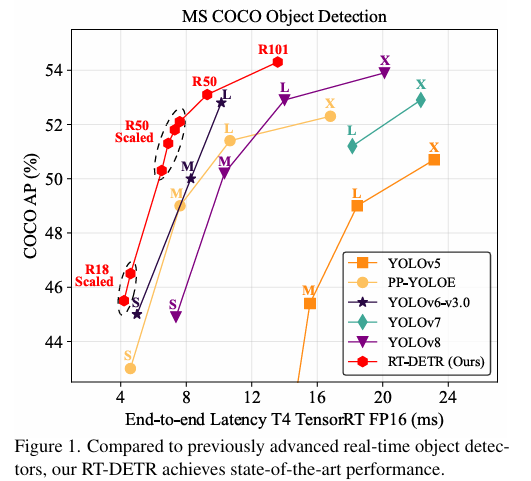
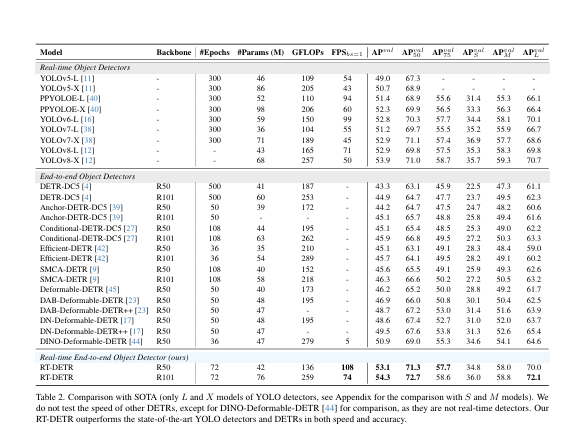
本文提出了一种新型的实时目标检测框架RT-DETR,旨在解决现有基于Transformer的目标检测器在计算成本和推理速度上的挑战。文中展示了RT-DETR-R50和RT-DETR-R101两种变体的性能:RT-DETR-R50实现了53.1%的平均精度(AP)和108帧每秒(FPS),而更高级的RT-DETR-R101变体则实现了54.3%的AP和74 FPS。特别值得一提的是,RT-DETR-R50在准确度和帧率上均优于DINO-Deformable-DETR-R50,显示出在实时目标检测任务中的优势。这些结果表明,RT-DETR在维持高准确度的同时,还能提供高帧率的检测,满足实时处理的需求。
二、目标检测器相关工作
1.从DETR到实时检测的创新
端到端目标检测器DETR(DEtection Transformer)以其简化的检测流程而备受关注,它通过二分匹配直接预测对象,避免了传统检测的Anchor和NMS组件。但是,DETR仍然存在训练收敛缓慢和查询优化难度大的问题。为了解决这些问题,人们提出了很多种DETR变体,比如Deformable DETR和Conditional DERT以及DAB-DETR等等,它们通过不同的方法进行优化效率和查询。DINO以之前的作品为基础,不断完善已经取得了巨大的成果。
2.利用多尺度特征提高性能
现代目标检测器通过使用多尺度特征,特别是小物体,已经有了显著的性能提升。FPN(特征金字塔网络)是实现这一目标的关键技术,通过融合不同尺度的特征来构建特征金字塔。而在DERT(DEtection Transformer)中,zhu等人首次引入了多尺度的特征,虽然提高了性能检测和模型收敛的速度,但是也增加了计算成本。即使后面的Deformable Attention在在一定程度上降低了这一成本,但是高计算成本的问题还是没有得到解决。
为了应对这些问题。一些研究高效DETR模型的团队设计了不同的DETR变体,如Efficient DETR通过优化目标查询的初始化来减少过程中解码和编码器的数量,来降低成本。还有Lite DETR通过减少级别特征的更新频率来提升编码器效率。
三、端到端速度的优势
1.对NMS的分析
NMS(非极大值抑制)是一种用于去除重叠预测框的常用后处理技术。它依赖于两个关键的超参数:得分阈值和loU(交并比)阈值。
具体操作中,首先过滤得分低于设定阈值的预测框。然后,对于剩余的预测框,如果俩个框之间的loU超过设定的loU阈值,那么得分低的框会被舍弃。这个过程会一直重复执行直到所有类别的预测框都被执行处理完成。所以NMS执行的时间主要是看,预测框的数量和俩个超参数。
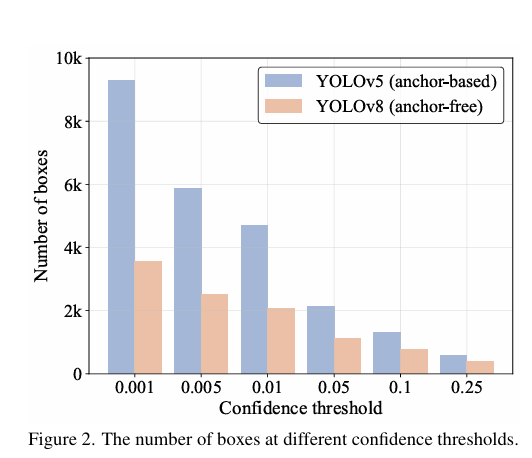
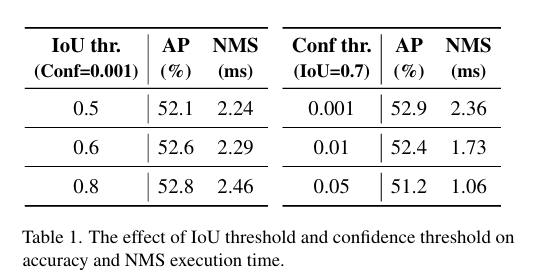
本图就是通过直方图的形式展示在相同输入图像下不同阈值下剩余的预测框的数量,此外还对YOLOv8进行不同NMS超参数下在COCO val2017的模型的准确性和时间,下图所示:
2.Anchor-Free检测其在实时推理中的优势
作者为了减少外在因素的影响建立了一个端到端的测试基准,并用COCO val2017作为默认数据集,同时也为后处理的实时检测器添加了TensorRT的NMS后处理插件。
根据数据可以看出来RT-DETR检测器在精度上要优于YOLO检测器。而出现这种情况也是因为Anchor-Free检测器上的预测框比Anchor-Base检测器多的多。
四、The Real-time DETR
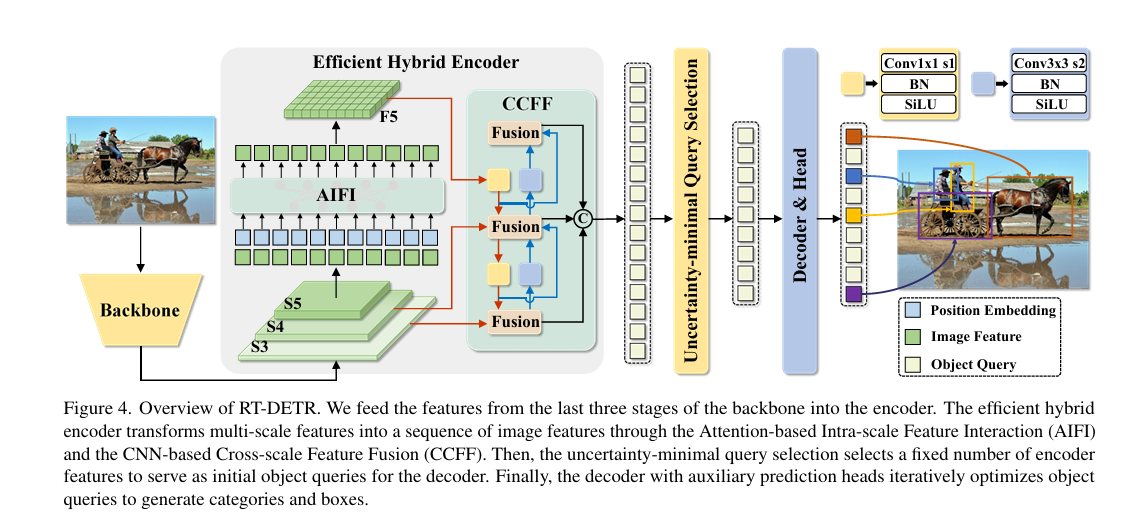
1.RT-DETR的结构
RT-DETR是由混合编码器和Backbone以及辅助预测头Transformer解码器组成。具体如下图所示:
2.混合编码器
作者等人为了加速训练收敛并提高性能提出了一种混合高效的混合编码器,混合编码器主要是俩个模块组成,即注意力的尺度内特征交互(AIFI)模块和神经网络的尺度特征融合模块(CCFM)。
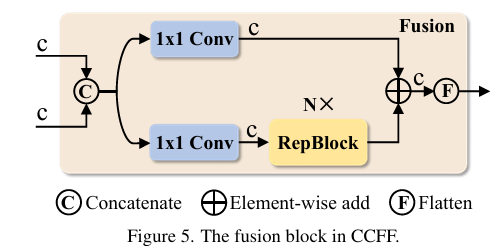
CCFM也基于变体D进行完善,如上图所示,也可以通过公式表达出来:

然而无论是Effificient detr和Dino以及Deformable detr的查询方案的哦是以Top-K个特征来初始化查询,导致探测器的性能削弱。为此作者提出了loU-Aware查询选择,它能为不同得分产生不同的分数线,具体的表示如下:

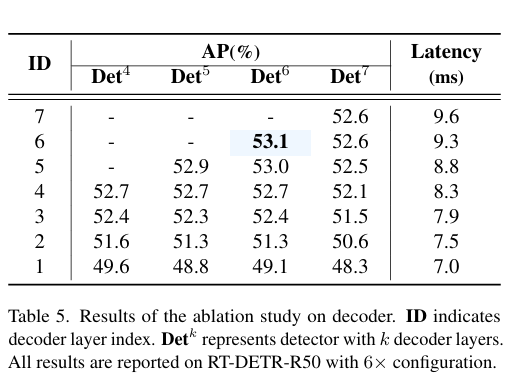
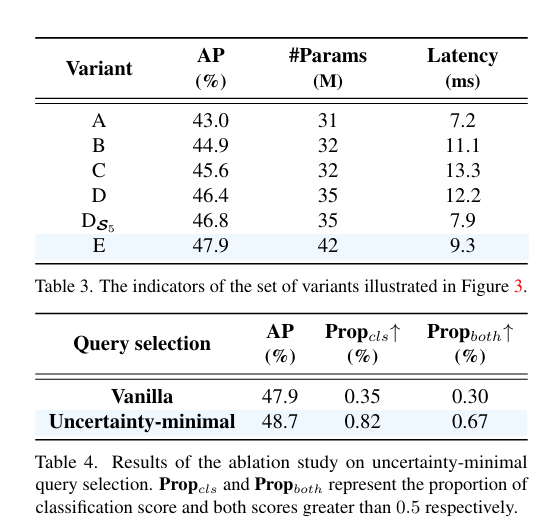
为了证明loU感知查询的可靠性,进行了如图所示的实验:
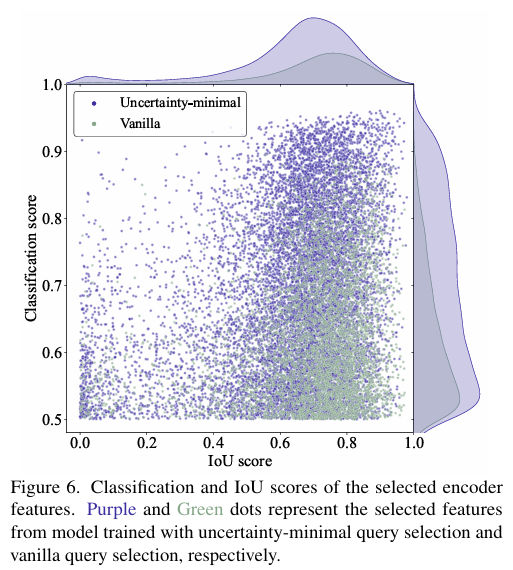
实验通过可视化和定量分析表明,使用IoU感知查询选择训练的模型(蓝色点)在生成高质量编码器特征方面优于普通查询选择训练的模型(红色点),这体现在蓝色点在散点图右上角的集中分布,以及在分类得分和IoU得分大于0.5时,蓝色点数量显著多于红色点,分别高出138%和120%。进而表示loU感知查询选择可以为对象查询提供更多具有准确分类和精确定位的编码器特征,从而提高检测器的准确性。
源码链接:hybrid_encoder
@register
@serializable
class HybridEncoder(nn.Layer):
__shared__ = ['depth_mult', 'act', 'trt', 'eval_size']
__inject__ = ['encoder_layer']
#初始化定义
def __init__(self,
in_channels=[512, 1024, 2048],
feat_strides=[8, 16, 32],
hidden_dim=256,
use_encoder_idx=[2],
num_encoder_layers=1,
encoder_layer='TransformerLayer',
pe_temperature=10000,
expansion=1.0,
depth_mult=1.0,
act='silu',
trt=False,
eval_size=None):
super(HybridEncoder, self).__init__()
self.in_channels = in_channels
self.feat_strides = feat_strides
self.hidden_dim = hidden_dim
self.use_encoder_idx = use_encoder_idx
self.num_encoder_layers = num_encoder_layers
self.pe_temperature = pe_temperature
self.eval_size = eval_size
# channel projection
self.input_proj = nn.LayerList()
for in_channel in in_channels:
self.input_proj.append(
nn.Sequential(
nn.Conv2D(
in_channel, hidden_dim, kernel_size=1, bias_attr=False),
nn.BatchNorm2D(
hidden_dim,
weight_attr=ParamAttr(regularizer=L2Decay(0.0)),
bias_attr=ParamAttr(regularizer=L2Decay(0.0)))))
# encoder transformer
self.encoder = nn.LayerList([
TransformerEncoder(encoder_layer, num_encoder_layers)
for _ in range(len(use_encoder_idx))
])
act = get_act_fn(
act, trt=trt) if act is None or isinstance(act,
(str, dict)) else act
# top-down fpn
self.lateral_convs = nn.LayerList()
self.fpn_blocks = nn.LayerList()
for idx in range(len(in_channels) - 1, 0, -1):
self.lateral_convs.append(
BaseConv(
hidden_dim, hidden_dim, 1, 1, act=act))
self.fpn_blocks.append(
CSPRepLayer(
hidden_dim * 2,
hidden_dim,
round(3 * depth_mult),
act=act,
expansion=expansion))
# bottom-up pan
self.downsample_convs = nn.LayerList()
self.pan_blocks = nn.LayerList()
for idx in range(len(in_channels) - 1):
self.downsample_convs.append(
BaseConv(
hidden_dim, hidden_dim, 3, stride=2, act=act))
self.pan_blocks.append(
CSPRepLayer(
hidden_dim * 2,
hidden_dim,
round(3 * depth_mult),
act=act,
expansion=expansion))
self._reset_parameters()
def _reset_parameters(self):
if self.eval_size:
for idx in self.use_encoder_idx:
stride = self.feat_strides[idx]
pos_embed = self.build_2d_sincos_position_embedding(
self.eval_size[1] // stride, self.eval_size[0] // stride,
self.hidden_dim, self.pe_temperature)
setattr(self, f'pos_embed{idx}', pos_embed)
#添加位置信息;
@staticmethod
def build_2d_sincos_position_embedding(w,
h,
embed_dim=256,
temperature=10000.):
grid_w = paddle.arange(int(w), dtype=paddle.float32)
grid_h = paddle.arange(int(h), dtype=paddle.float32)
grid_w, grid_h = paddle.meshgrid(grid_w, grid_h)
assert embed_dim % 4 == 0, \
'Embed dimension must be divisible by 4 for 2D sin-cos position embedding'
pos_dim = embed_dim // 4
omega = paddle.arange(pos_dim, dtype=paddle.float32) / pos_dim
omega = 1. / (temperature**omega)
out_w = grid_w.flatten()[..., None] @omega[None]
out_h = grid_h.flatten()[..., None] @omega[None]
return paddle.concat(
[
paddle.sin(out_w), paddle.cos(out_w), paddle.sin(out_h),
paddle.cos(out_h)
],
axis=1)[None, :, :]
def forward(self, feats, for_mot=False, is_teacher=False):
assert len(feats) == len(self.in_channels)
# get projection features
proj_feats = [self.input_proj[i](feat) for i, feat in enumerate(feats)]
# encoder
if self.num_encoder_layers > 0:
for i, enc_ind in enumerate(self.use_encoder_idx):
h, w = proj_feats[enc_ind].shape[2:]
# flatten [B, C, H, W] to [B, HxW, C]
src_flatten = proj_feats[enc_ind].flatten(2).transpose(
[0, 2, 1])
if self.training or self.eval_size is None or is_teacher:
pos_embed = self.build_2d_sincos_position_embedding(
w, h, self.hidden_dim, self.pe_temperature)
else:
pos_embed = getattr(self, f'pos_embed{enc_ind}', None)
memory = self.encoder[i](src_flatten, pos_embed=pos_embed)
proj_feats[enc_ind] = memory.transpose([0, 2, 1]).reshape(
[-1, self.hidden_dim, h, w])
# top-down fpn
inner_outs = [proj_feats[-1]]
for idx in range(len(self.in_channels) - 1, 0, -1):
feat_heigh = inner_outs[0]
feat_low = proj_feats[idx - 1]
feat_heigh = self.lateral_convs[len(self.in_channels) - 1 - idx](
feat_heigh)
inner_outs[0] = feat_heigh
upsample_feat = F.interpolate(
feat_heigh, scale_factor=2., mode="nearest")
inner_out = self.fpn_blocks[len(self.in_channels) - 1 - idx](
paddle.concat(
[upsample_feat, feat_low], axis=1))
inner_outs.insert(0, inner_out)
# bottom-up pan
outs = [inner_outs[0]]
for idx in range(len(self.in_channels) - 1):
feat_low = outs[-1]
feat_height = inner_outs[idx + 1]
downsample_feat = self.downsample_convs[idx](feat_low)
out = self.pan_blocks[idx](paddle.concat(
[downsample_feat, feat_height], axis=1))
outs.append(out)
return outs
@classmethod
def from_config(cls, cfg, input_shape):
return {
'in_channels': [i.channels for i in input_shape],
'feat_strides': [i.stride for i in input_shape]
}
@property
def out_shape(self):
return [
ShapeSpec(
channels=self.hidden_dim, stride=self.feat_strides[idx])
for idx in range(len(self.in_channels))
]
实验
1.与YOLO的比较
1.不同模块的消融研究