CUDA线程调用与存储器架构
- 前几节简单讲了如何编写CUDA程序,利用GPU的处理能力并行执行多个线程和块。
- 之前所有程序里的线程是相互独立的,没有多个线程之间的通信
- 多是实际应用程序需要中间线程之间的通信,本文将仔细讲解线程调用以及CUDA的分层存储架构,以及加速CUDA代码是使用不同存储器之间的区别。
1. 线程调用
- CUDA 关于并行执行具有分层结构。每次内核启动时可以被切分成多个并行执行的块,而每个块又可以进一步的被切分成多个线程
- GPU 中 1个块中的线程可以相互通信,即启动 1 个具有多个线程的块让里面的线程能够相互通信是一个优势
- 最大的块能有1024个线程,但是我们在执行程序时需要开启所有线程吗?答案时不一定的,可以同时启动 多个块+块中的多个线程。假设一个向量加法例子需要启动 N=50000 这么多的线程,可以这样调用内核:
//如果块数量 N 不是512的倍数,需要加上511,然后再除以512
gpu<< <(N + 511) /512), 512 > >>(d_a,d_b,d_c)
1.1 向量加法
- 简单描述一下GPU的结构,众所周知它是由很多块组成的计算单元,它的形态可以看作好多个魔方(立方体)拼接而成的结构,因此每个块可以通过x,y,z三个方向来确定它的位置或者id,下边举例说明一个通过启动 x 方向多个块 和 块中多个线程来实现向量加法,并给出详细分析
#include "stdio.h"
#include<iostream>
#include <cuda.h>
#include <cuda_runtime.h>
//Defining number of elements in Array
#define N 50000
//Defining Kernel function for vector addition
__global__ void gpuAdd(int *d_a, int *d_b, int *d_c) {
//Getting block index of current kernel
int tid = threadIdx.x + blockIdx.x * blockDim.x;
while (tid < N)
{
d_c[tid] = d_a[tid] + d_b[tid];
tid += blockDim.x * gridDim.x;
}
}
- 上述先给出了核函数,与之前程序不同的是
tid的计算方式,即tid = blockIdx.x(当前块的ID) * blockDim.x(当前快里面的线程数量) + threadIdx.x(当前线程在块中的ID) - 另一个不同的是 while 部分每次增加现有的线程数量(因为你没有启动到N),知道达到N。这就如同你有一个卡,一次最多只能启动100个块,每个块里有7个线程,也就是一次最多启动700个线程。但N的规模是8000,远远超过700,因此通过while循环可以实现第一次处理[0,699],第二次处理[700,1400],第三次处理[1400,2100]…直到这8000个元素全都被处理完
- 因此,计算那每一个线程的总ID,可以通过如下数学表达式:
tid = hreadIdx.x + blockIdx.x * blockDim.x
- main函数掉调用如下:
int main(void) {
//Defining host arrays
int h_a[N], h_b[N], h_c[N];
//Defining device pointers
int *d_a, *d_b, *d_c;
// allocate the memory
cudaMalloc((void**)&d_a, N * sizeof(int));
cudaMalloc((void**)&d_b, N * sizeof(int));
cudaMalloc((void**)&d_c, N * sizeof(int));
//Initializing Arrays
for (int i = 0; i < N; i++) {
h_a[i] = 2 * i*i;
h_b[i] = i;
}
// Copy input arrays from host to device memory
cudaMemcpy(d_a, h_a, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, N * sizeof(int), cudaMemcpyHostToDevice);
//Calling kernels with N blocks and one thread per block, passing device pointers as parameters
gpuAdd << <512, 512 >> >(d_a, d_b, d_c);
//Copy result back to host memory from device memory
cudaMemcpy(h_c, d_c, N * sizeof(int), cudaMemcpyDeviceToHost);
cudaDeviceSynchronize();
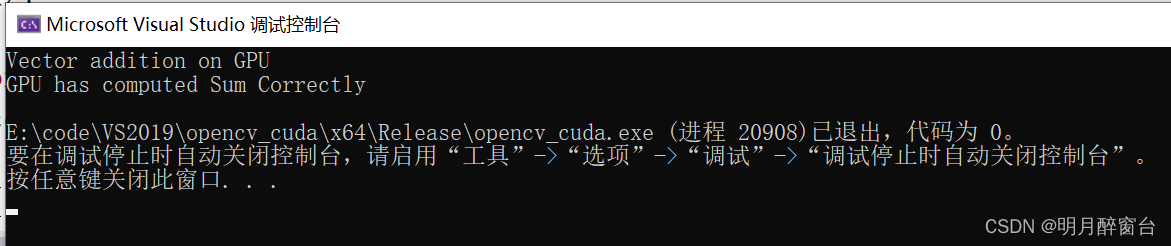
int Correct = 1;
printf("Vector addition on GPU \n");
//Printing result on console
for (int i = 0; i < N; i++) {
if ((h_a[i] + h_b[i] != h_c[i]))
{
Correct = 0;
}
}
if (Correct == 1)
{
printf("GPU has computed Sum Correctly\n");
}
else
{
printf("There is an Error in GPU Computation\n");
}
//Free up memory
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
return 0;
}
1.2 矩阵加法
-
下边再给两个例子做比较吧
- 通过一个块中的多个线程计算矩阵相加
- 通过多个块的多个线程计算矩阵相加
-
- 启动一个块中的多个线程
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) {
//Getting block index of current kernel
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
int numblocks = 1;
dim3 threadsPerblock(N, N);
MatAdd << <numblocks, threadsPerblock >> > (d_a, d_b, d_c);
...
}
-
- 启动多个块中的多个线程
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) {
//Getting block index of current kernel
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if(i<N&&j<N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
//...
//核函数定义
dim3 threadsPerBlock(16, 16);
dim3 numsBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd << < numsBlocks, threadsPerBlock >> > (A, B, C);
}
2. 存储器架构
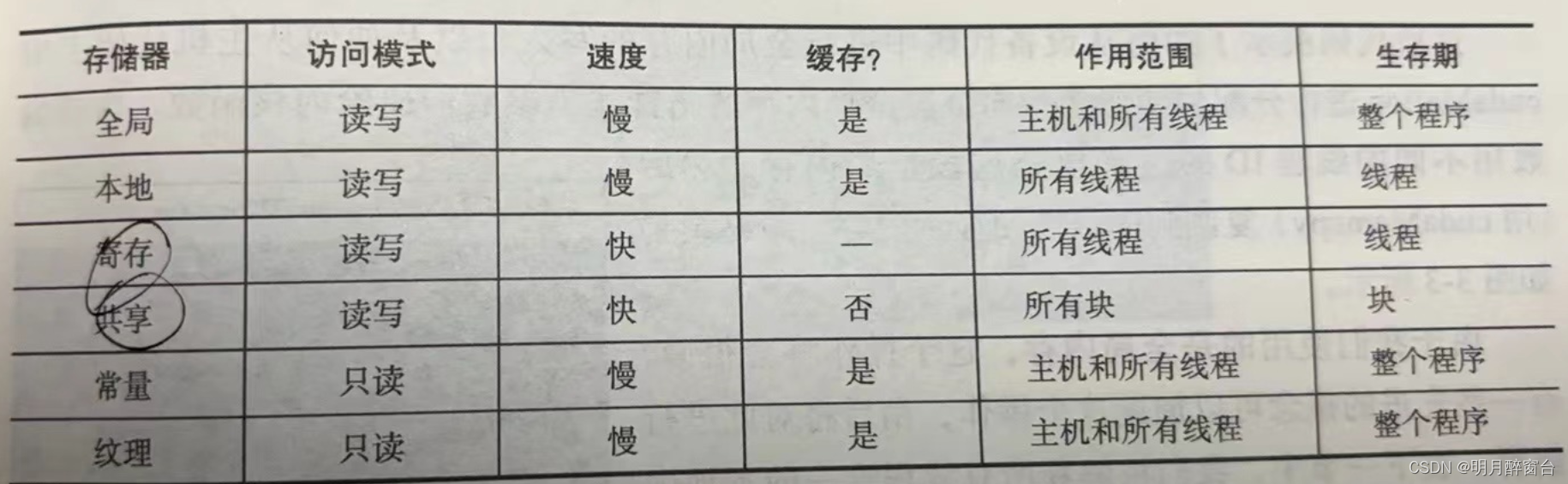
- 在GPU上的代码执行被划分为流多处理器、块和线程。
- GPU有几个不同的存储器空间,每个存储器空间都有特定的特征和用途以及不同的速度和范围。这个存储空间按层次结构被分为不同的组块,比如全局内存、共享内存、本地内存、常量内存和纹理内存,每个组块都可以从程序中的不同点访问。
- 存储器架构如图:

- 如图所示,每个线程都有自己的本地存储器和寄存器堆。与处理器不同的是,GPU核心有很多寄存器来存储本地数据
- 当线程使用的数据不适合存储在寄存器堆中或者寄存器堆中装不下的时候,将会使用本地内存。
- 寄存器堆和本地内存对每个线程都是唯一的,寄存器堆时最快的一种存储器
- 同一块中的线程具有可有该块中所有线程访问的共享内存。全局内存可被所有的线程访问,它具有相当大的访问延迟,但存在缓存这种东西来给他提速
- GPU有以及和二级缓存(即L1缓存和L2缓存)。常量内存则是用于存储常量和内核参数之类的只读数据
- 纹理内存可以利用各种2D和3D的访问模式
- 所有存储区的特征总结如下:
2.1 全局内存
- 所有的块都可以对全局内存进行读写,该存储器较慢,但是可以从你的代码的任何地方进行读写
- 缓存可以加速对全局内存的访问
- 所有通过 cudaMalloc 分配的存储器都是全局内存
- 来个例子吧
#include <stdio.h>
#define N 5
__global__ void gpu_global_memory(int *d_a)
{
// "array" is a pointer into global memory on the device
d_a[threadIdx.x] = threadIdx.x;
}
int main(int argc, char **argv)
{
// Define Host Array
int h_a[N];
//Define device pointer
int *d_a;
cudaMalloc((void **)&d_a, sizeof(int) *N);
// now copy data from host memory to device memory
cudaMemcpy((void *)d_a, (void *)h_a, sizeof(int) *N, cudaMemcpyHostToDevice);
// launch the kernel
gpu_global_memory << <1, N >> >(d_a);
// copy the modified array back to the host memory
cudaMemcpy((void *)h_a, (void *)d_a, sizeof(int) *N, cudaMemcpyDeviceToHost);
printf("Array in Global Memory is: \n");
//Printing result on console
for (int i = 0; i < N; i++)
{
printf("At Index: %d --> %d \n", i, h_a[i]);
}
return 0;
}
2.2 本地内存和寄存器堆
- 本地内存和寄存器堆对每个线程都是唯一的,寄存器时每个线程可用的最快存储器
- 当内核中使用的变量在寄存器堆中装不下的时候,将会使用本地内存存储它们,这叫寄存器溢出
- 本地内存使用有两种情况:一种是寄存器不够了,一种是某些情况根本不能放在寄存器中,例如堆一个局部数组的下标进行不定索引的时候
- 相比寄存器堆,本地内存要慢很多,虽然本地内存通过L1、L2缓存进行了缓冲,但寄存器溢出可能会影响你程序的性能
- 举个例子:
#include <stdio.h>
#define N 5
__global__ void gpu_local_memory(int d_in)
{
int t_local;
t_local = d_in * threadIdx.x;
printf("Value of Local variable in current thread is: %d \n", t_local);
}
int main(int argc, char** argv)
{
printf("Use of Local Memory on GPU:\n");
gpu_local_memory << <1, N >> > (5);
cudaDeviceSynchronize();
return 0;
}
- 代码中的
t_local变量是每个线程中局部唯一的,将被存储在寄存器堆中。用这种变量计算的时候,计算速度将是最快速的

2.3 高速缓冲存储器
- 在较新的GPU上,每个流多处理器都含有自己独立的L1缓存,以及GPU有L2缓存,L2缓存是被所有的GPU中的流多处理器都共有的,所有的全局内存访问和本地内存访问都使用这些内存,因为L1缓存在流多处理器内部独有,接近下称执行所需要的硬件单位,所以它的速度非常快
- 一般来说,L1缓存和共享内存公用同样的存储硬件,一共是64KB,可以配置它们所占内存的比例
- 所有的全局内存通过L2缓存进行,纹理内存和常量内存也分别有它们独立的缓存