1.概述
扩散模型是最近出现的强大的深度生成模型,可用于生成高质量图像。扩散模型发展迅速,可应用于文本到图像生成、图像到图像生成、视频生成、语音合成和 3D 合成。
除了算法的改进,骨干网的改进在扩散建模中也发挥着重要作用。一个典型的例子是基于卷积神经网络(CNN)的 U-Net,它已被用于之前的研究中。 基于 CNN 的 UNet 的特点是一系列下采样块、一系列上采样块以及这些组之间的长跳接UNet 基于 CNN。它在图像生成任务的扩散模型中起着主导作用。
另一方面,视觉变换器(ViTs)在各种视觉任务中都取得了可喜的成果:在某些情况下,ViTs 的表现不亚于或优于基于 CNN 的方法。这就自然而然地提出了一个问题:是否有必要在扩散模型中依赖基于 CNN 的 U-Nets?
本评论文章提出了一种基于 ViT 的 UNet(U-ViT)。所提出的方法在 ImageNet 和 MS-COCO 上生成的图像达到了最高的 FID(衡量图像质量的标准)。
论文地址:https://arxiv.org/abs/2209.12152
源码地址:https://github.com/baofff/U-ViT.git
2.U-ViT构架
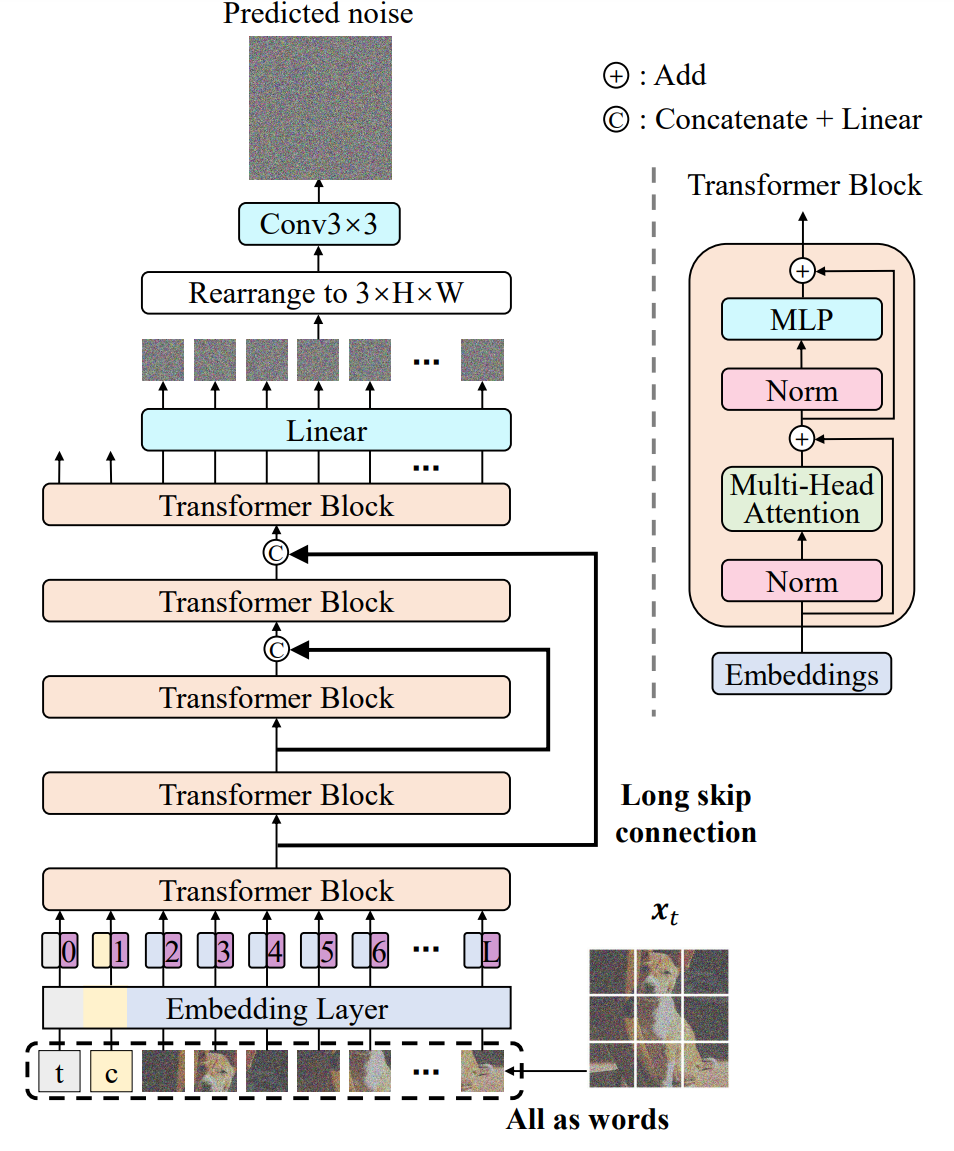
上图 是 U-ViT 的概览。该网络获取扩散过程的时间(t)、条件(c)和噪声图像 ( x t ) (x_t) (xt),并预测要注入到图像中的噪声 ( x t ) (x_t) (xt)。 按照 ViT 的设计方法,图像被划分为多个补丁,U-ViT 处理所有输入,包括时间、条件和图像补丁,并将所有输入视为标记(词)。并将所有输入视为标记(词)。
与基于 CNN 的 U-Net 一样,U-ViT 在浅层和深层之间使用长跳转连接。训练扩散模型是一项像素级的预测任务,对低层特征非常敏感。长跳转连接为低层特征提供了捷径,便于噪声预测网络的训练。
此外,U-ViT 还可选择在输出前添加一个 3x3 卷积块。这是为了防止变换器生成的图像中出现潜在的伪影。
以下各小节将提供有关 U-ViT 各部分的更多详细信息。
3.1 实施细节
本节将通过 CIFAR10 中生成图像的图像质量(FID)来优化 U-ViT 的结构。整体结果概览见下图 。
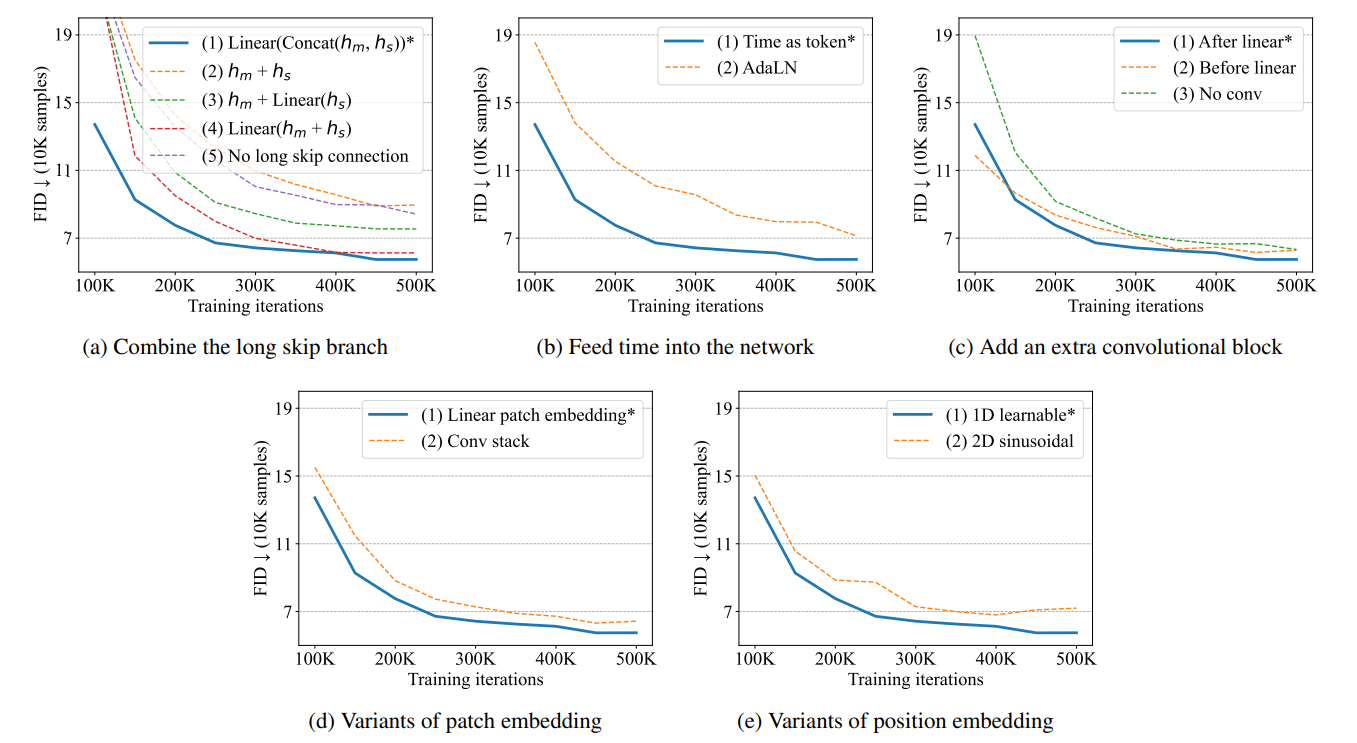
如何结合长跳转连接起来
首先让
h
m
,
h
s
R
L
×
D
h_m,h_sR^{L×D}
hm,hsRL×D成为主分支和长跳分支的嵌入。在将它们送入下一个变换块之前,考虑一些将它们组合起来的方法:
-
将 h m , h s h_m,h_s hm,hs连接起来,然后执行线性投影: L i n e a r ( C o n c a t ( h m , h s ) ) Linear(Concat(h_m,h_s)) Linear(Concat(hm,hs))。
-
直接添加 h m 、 h s : h m + h s h_m、h_s:h_m+h_s hm、hs:hm+hs。
-
在 h s h_s hs上进行线性投影,并将其添加到 h m : h m + h s h_m:h_m+h_s hm:hm+hs。
-
添加 h m 、 h s h_m、h_s hm、hs,然后进行线性投影: L i n e a r ( h m + h s ) Linear(h_m+h_s) Linear(hm+hs)。
-
删除长跳线连接
如上图所示,在这些方法中,第一种使用连接 LinearConcat ( h m , h s ) \text{Linear} \text{Concat}(h_m,h_s) LinearConcat(hm,hs)的方法效果最好。特别是,与不使用长跳转连接的方法相比,生成图像的质量明显提高。
如何输入时间条件
将时间条件 t 输入网络的方法有两种。方法(1) 是将它们视为标记,如图 1 所示。 方法(2)是在转换器模块中将层归一化后的时间纳入,这与 U-Net 中使用的自适应组归一化类似;第二种方法称为自适应层归一化(AdaLN)。 将时间视为标记的方法(1) 比 AdaLN 性能更好。
如何在变压器后添加卷积块
在变换器后添加卷积块有两种方法。(1) 在将标记嵌入映射到图像补丁的线性投影之后添加 3×3 卷积块。 (2)在线性投影之前添加一个 3×3 卷积块。此外,还可以将其与去掉附加卷积块的情况进行比较,在线性投影后添加 3×3 卷积块的方法(1) 的 性能略优于其他两种方案。
补丁嵌入法
传统的补丁嵌入是将补丁映射到标记嵌入的线性投影。除了这种方法,我们还考虑了另一种将图像映射到标记嵌入的方法,即使用 3 × 3 卷积块堆叠,然后再使用 1 × 1 卷积块。但是,如图 2(d) 所示,传统的补丁嵌入法效果更好,因此最终模型采用了这种方法。
位置嵌入方法
本文使用的是原 ViT 中提出的一维可学习位置嵌入。 也有一种替代方法,即二维正弦位置嵌入,一维可学习位置嵌入的效果更好。我们也尝试过不使用位置嵌入,但该模型无法生成清晰的图像,这表明位置信息对图像生成非常重要。
3.2 网络深度、宽度和补丁大小的影响
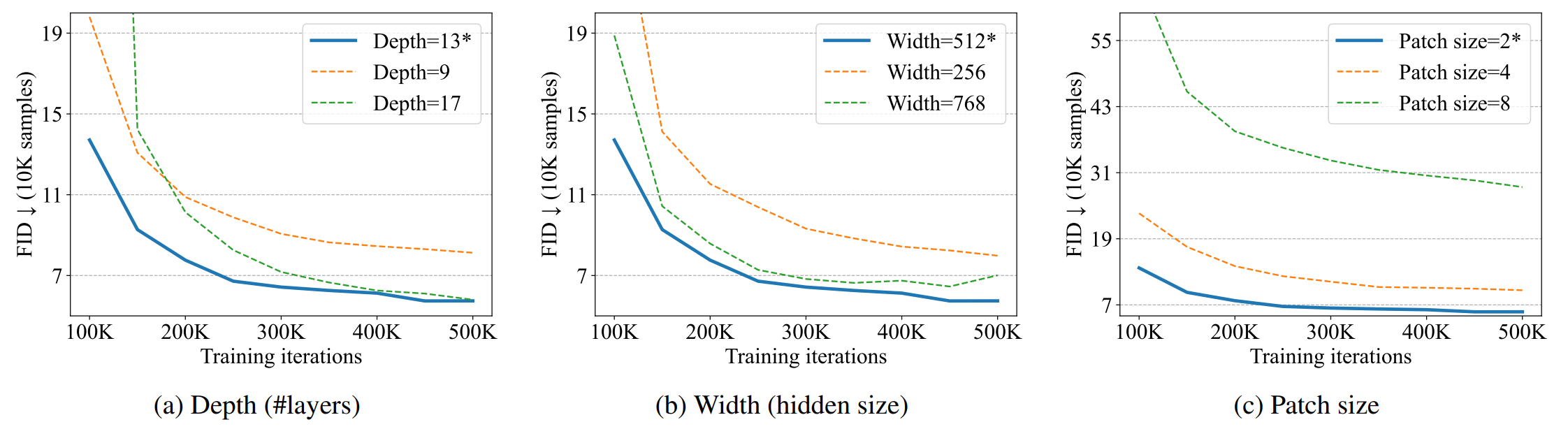
这里,我们在 CIFAR10 中研究了 U-ViT 的缩放特性,以考察层数、宽度和贴片尺寸的影响。如上图所示,将层数从 9 层增加到 13 层可提高性能,但对于深度超过 17 层的模型则没有影响。同样,增加宽度也能提高性能,但超过一定宽度就没有效果了。
减小贴片尺寸可以提高性能,但低于一定尺寸时性能就会下降。在扩散模型中,小补丁尺寸被认为适合低水平噪声预测任务。另一方面,对于高分辨率图像来说,使用小尺寸贴片的成本较高,因此必须先将图像转换为低维潜在表示,然后再用 U-ViT 进行建模。
4.试验
4.1 数据集和设置
U-ViT 的有效性在三个任务中进行了测试:无条件图像生成、类条件图像生成和文本到图像生成。
无条件图像生成实验在 CIFAR10(50,000 幅图像)和 CelebA 64×64 (162,770 幅图像)上进行。对于类别条件图像生成,在64×64 和 256×256ImageNet 数据集(包含来自 1,000 个不同类别的 1,281,167 幅训练图像)和 512×512 分辨率数据集上进行了实验。MS-COCO (82,783 幅训练图像和 40,504 幅验证图像)用于文本到图像的训练。
在生成256 × 256 和 512 × 512分辨率的高分辨率图像时,使用由潜在扩散模型(Latent diffusion models,LDM)[Rombach et.al, 2022]提供的预训练图像自动编码器,分别将 32 × 32 和 64 × 64 分辨率的潜在表征分别生成 32 x 32 和 64 x 64 分辨率的潜表征。然后使用 U-ViT 对这些潜表征进行建模。
在MS-COCO 中生成文本到图像时,使用 CLIP 文本编码器将离散文本转换为嵌入序列,然后将这些嵌入序列作为标记序列输入 U-ViT。
4.2 无条件和类条件图像生成

表 1.无条件图像生成和类别条件图像生成的结果
在这里,U-ViT 与之前基于 U-Net 的扩散模型和 GenViT 进行了比较,GenViT 是一种较小的 ViT,它没有长跳接,并在归一化层之前加入了时间。FID 分数用于衡量图像质量。
如表 1 所示,U-ViT 在无条件的 CIFAR10 和 CelebA 64×64 中表现出与 U-Net 相当的性能,并且比 GenViT 性能更好。对于有类别条件的 ImageNet 64×64,我们首先尝试了 U-ViT-M 配置,参数为 131M。如表 1 所示,其 FID 为 5.85,优于使用 U-Net 且参数为 100M 的 IDDPM 6.92。为了进一步提高性能,我们采用了 U-ViT-L 配置(287M 个参数),将 FID 从 5.85 提高到 4.26。
在有类别条件的 ImageNet 256×256 中,U-ViT 的最佳 FID 为 2.29,优于之前的扩散模型。表 2 显示,在使用相同采样器的不同采样步骤中,U-ViT 的表现优于 LDM。U-ViT 的表现也优于 VQ-扩散模型,后者是一种以变压器为骨干的离散扩散模型。同样,在参数和计算成本相同的情况下,U-ViT 也优于 UNet。
对于带有类别条件的 ImageNet 512×512,U-ViT 的表现优于直接对图像像素建模的 ADM-G。图 4 显示了 ImageNet 256×256 和 512×512 的部分样本以及其他数据集的随机样本,证实了图像的高质量和清晰度。
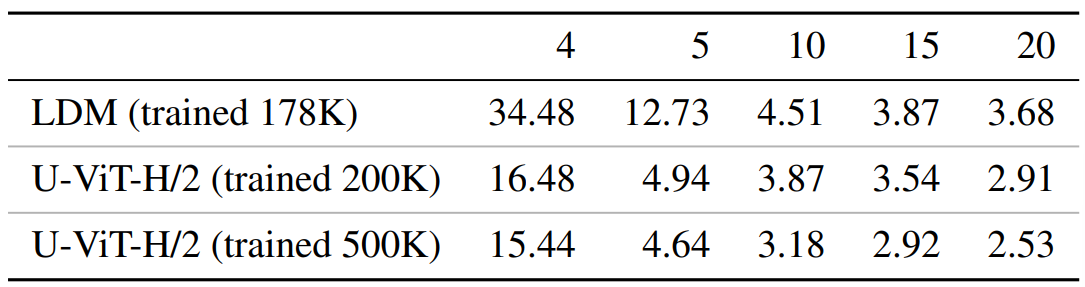
表 2:ImageNet 256×256 不同采样步数下的 FID 结果。

4.3 使用 MS-COCO 生成文本到图像
这里,我们使用 MS-COCO 数据集来评估 U-ViT 在文本到图像生成任务中的表现。我们还使用 U-Net 训练了另一个潜在扩散模型,模型大小与 U-ViT 相同,并与 U-ViT 进行了比较。
FID 分数用于衡量图像质量:从 MS-COCO 验证集中随机选取 30K 个提示,并利用这些提示生成样本来计算 FID。如表 3 所示,即使在生成模型的训练过程中不需要访问大型外部数据集,U-ViT 也能获得最先进的 FID。通过将层数从 13 层增加到 17 层,U-ViT-S(Deep)可以获得更好的 FID。
图 6 显示了 U-Net 和 U-ViT 使用相同的随机种子生成的样本,以进行定性比较;U-ViT 生成的样本质量更高,图像内容与文本的匹配度更高。
例如,给定文本 “棒球运动员挥棒击球”,U-Net 不会生成球棒或球,而 U-ViT 会生成球,U-ViT-S(Deep)会进一步生成球棒。这可能是由于与 U-Net 相比,U-ViT 中文本和图像之间每一层的交互更为频繁。
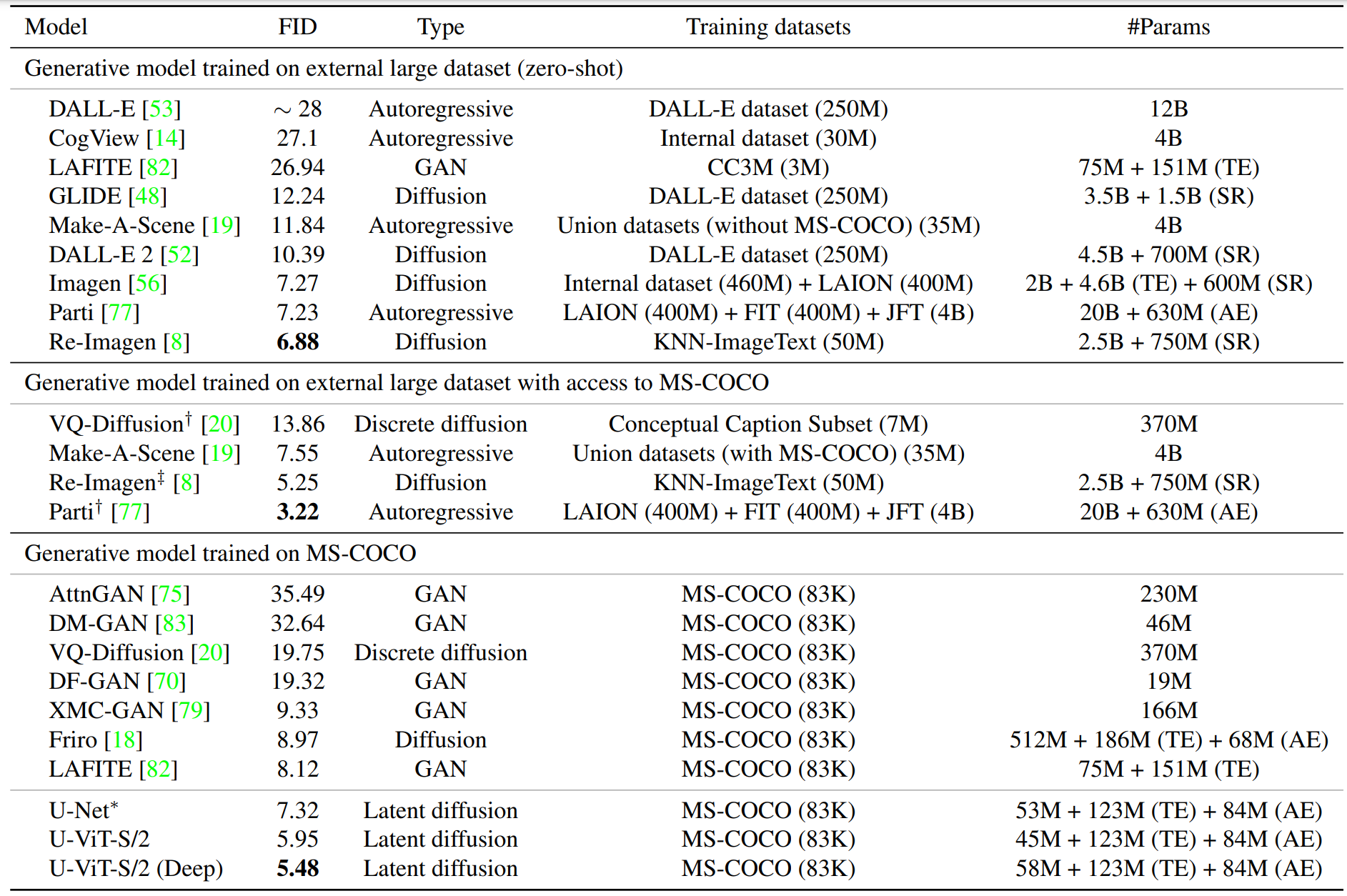
表 3.MS-COCO 的实验结果

5. 结论
U-ViT 将所有输入(时间、条件和噪声图像片段)视为标记,并在浅层和深层之间采用长跳转连接。U-ViT 已在无条件和有条件图像生成以及文本到图像生成等任务中进行了评估。
U-ViT 的性能与类似规模的基于 CNN 的 U-Nets 不相上下,甚至更好。这些结果表明,长跳接对于基于扩散的图像建模非常重要,而基于 CNN 的 U-Nets 并不总是需要向下向上采样运算符。
U-ViT 可以为未来的扩散建模骨干研究提供信息,并有利于在具有不同模式的大型数据集中进行生成建模。