你是否想知道Google 和 Bing 等搜索引擎如何收集搜索结果中显示的所有数据。这是因为搜索引擎对其档案中的所有页面建立索引,以便它们可以根据查询返回最相关的结果。网络爬虫使搜索引擎能够处理这个过程。
本文重点介绍了网络爬虫的重要方面、网络爬虫为何重要、其工作原理、应用程序和示例。
一、2024 年部分最佳网络爬虫

数据过滤标准:
- 员工人数: LinkedIn 员工人数超过 5 人
- B2B 客户评论数量: 在 G2、Trustradius 和 Capterra 等评论网站上有 5 条以上评论。
二、什么是网络爬虫?
网络爬虫,也称为网络蜘蛛、机器人、爬行代理或网络抓取器,是一种可以提供两种功能的程序:
- 系统地浏览网页以为搜索引擎索引内容。网络爬虫复制页面以供搜索引擎处理,搜索引擎会对下载的页面建立索引以便于检索,以便用户可以更快地获得搜索结果。这就是网络爬虫的最初含义。
- 自动从任何网页检索内容。这通常称为网络抓取。当搜索引擎以外的公司开始使用网络爬虫来检索网络信息时,网络爬虫的这个含义就出现了。例如,电子商务公司依靠竞争对手的价格进行动态定价。
三、什么是网络爬取?
网络爬取是使用程序或自动脚本对网页上的数据建立索引的过程。这些自动化脚本或程序有多个名称,包括网络爬虫、蜘蛛、蜘蛛机器人,并且通常缩写为爬虫。
四、网络爬虫如何工作?
- 网络爬虫通过下载网站的 robots.txt 文件开始爬行过程。该文件包含列出搜索引擎可以抓取的 URL 的站点地图。
- 一旦网络爬虫开始爬行页面,它们就会通过超链接发现新页面。
- 爬虫将新发现的 URL 添加到爬网队列中,以便稍后如果爬虫的开发人员有兴趣对其进行爬网,则可以对其进行爬网。
由于这种流程,网络爬虫可以索引连接到其他页面的每个页面。
robot.txt 文件示例:

五、您应该多久抓取一次网页?
由于网页会定期更改,因此确定抓取工具抓取网页的频率也很重要。
关于网站抓取的频率没有规定。这取决于网站更新其内容和链接的频率。如果您使用即用即付机器人服务,每天重新访问和抓取网页可能会成本高昂,并且会很快消耗您的抓取预算。
网络爬行过程中涉及的基本步骤:

六、什么是网络爬虫应用程序?
网络爬行通常用于为搜索引擎索引页面。这使得搜索引擎能够为查询提供相关结果。网络爬行也被用来描述网络抓取,从网页中提取结构化数据,网络抓取有许多应用。它还会通过向 Google 等搜索引擎提供输入来影响网站的SEO(搜索引擎优化),无论您的内容是否具有与查询相关的信息,或者是否是其他在线内容的直接副本。
七、构建网络爬虫或使用网络爬虫工具
7.1 内部网络爬虫
要构建内部网络爬虫,可以使用 javascript、python 等编程语言。例如,Googlebot 是用 C++ 和 Python 编写的内部网络爬虫最著名的示例之一。
根据您的网络爬行要求,您还可以使用开源网络爬虫。开源网络爬虫使用户能够根据自己的特定用途定制源代码。
自建爬虫系统的架构包括以下步骤:
- 种子 URL: 种子 URL,也称为启动器 URL,是网络爬虫用于启动索引和爬网过程的输入。
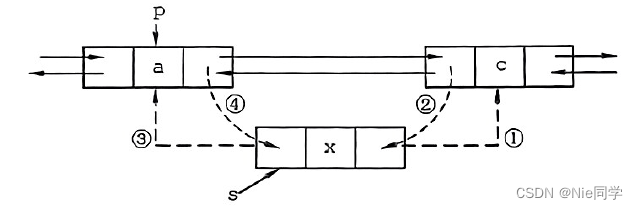
- URL边界: 爬行边界由网络爬虫访问网站时必须遵循的策略和规则组成。网络爬虫根据前沿的策略决定访问哪些页面(见图5)。爬行边界为每个URL分配不同的优先级(例如高优先级和低优先级URL),以便通知爬行器接下来要访问哪些页面以及应该访问该页面的频率。
- 获取和呈现 URL: URL 边界通知获取器应发出请求以从其源检索所需信息的 URL。然后,网络爬虫会呈现获取的 URL,以便在客户端屏幕上显示 Web 内容。
- 内容处理: 抓取到的网页内容一旦呈现,就会被下载并保存在存储中以供进一步使用。下载的内容可能包含重复页面、恶意软件等。
- URL 过滤: URL 过滤是出于某些原因删除或阻止某些 URL 在用户设备上加载的过程。URL 过滤器检查存储中的所有 URL 后,会将允许的 URL 传递给 URL 下载器。
- URL加载器: URL下载器判断网络爬虫是否爬取了某个URL。如果URL下载器遇到尚未爬取的URL,则会将其转发到URL前沿进行爬取。
7.1.1 优势
- 您可以根据自己的具体爬行需求定制自建网络爬虫。
7.1.2 弊端
- 自建网络爬虫需要开发和维护工作。
URL 边界如何工作:

7.2 外包网络爬虫
如果您没有技术知识或技术团队来开发内部网络爬虫,您可以使用预构建的(或商业网络爬虫)网络爬虫。
7.2.1 优势
- 预构建的网络爬虫不需要技术知识。
7.2.2 弊端
- 预构建的爬虫不如基于代码的爬虫灵活。
八、为什么网络爬行很重要?
由于数字革命,网络上的数据总量不断增加。预计未来两年(直至 2025 年)全球数据生成量将增加到 180 ZB 以上。根据 IDC 的数据,到 2025 年,全球80%的数据将是非结构化的。

同一时期,人们对网络抓取的兴趣超过了对网络爬行的兴趣。可能的原因有:
-
对分析和数据驱动决策的兴趣日益浓厚是公司投资抓取的主要驱动力。
-
搜索引擎进行的抓取不再是一个越来越受关注的话题,因为它是一个成熟的话题,自 20 世纪 90 年代末以来,公司一直在投资。
-
搜索引擎行业是一个成熟的行业,由Google、百度、Bing和Yandex等少数公司主导,因此很少有公司需要构建爬虫。
九、网络爬行和网络抓取有什么区别?
网络抓取是使用网络爬虫扫描并存储目标网页的所有内容。换句话说,网络抓取是网络爬行的一种特定用例,用于创建目标数据集,例如提取所有财经新闻进行投资分析和搜索特定公司名称。
传统上,一旦网络爬虫爬行并索引了网页的所有元素,网络爬虫就会从索引的网页中提取数据。然而,如今,抓取和爬行术语可以互换使用,区别在于爬虫更倾向于指搜索引擎爬虫。随着搜索引擎以外的公司开始使用网络数据,网络爬虫一词开始取代网络爬虫一词。
十、网络爬虫有哪些不同类型?
网络爬虫根据其运行方式分为四类。
- 聚焦式网络爬虫: 聚焦式网络爬虫是仅搜索、索引和下载与特定主题相关的网络内容以提供更加本地化的网络内容的网络爬虫。标准网络爬虫跟踪网页上的每个超链接。与标准网络爬虫不同,专注网络爬虫会寻找最相关的链接并为其建立索引,同时忽略不相关的链接,如下图。
标准网络爬虫与专注网络爬虫之间的差异图解:

-
增量爬虫: 一旦网页被网络爬虫索引并爬行,爬虫就会重新访问 URL 并定期刷新其集合,以用新 URL 替换过时的链接。重新访问 URL 并重新抓取旧 URL 的过程称为增量抓取。重新抓取页面有助于减少下载文档中的不一致。
-
分布式爬虫: 多个爬虫同时运行在不同的网站上,分布网络爬虫进程。
-
并行爬虫: 并行爬虫是并行运行多个爬行进程以最大化下载速率的爬虫。
十一、网络爬虫面临哪些挑战?
11.1 数据库新鲜度
网站内容定期更新。例如,动态网页会根据访问者的活动和行为更改其内容。这意味着您抓取网站后,网站的源代码不会保持不变。为了向用户提供最新的信息,网络爬虫必须更频繁地重新爬行这些网页。
11.2 爬虫陷阱
网站采用不同的技术(例如爬虫陷阱)来防止网络爬虫访问和爬行某些网页。爬虫陷阱或蜘蛛陷阱会导致网络爬虫发出无限数量的请求并陷入恶性爬行循环。网站也可能无意中创建爬虫陷阱。不管怎样,当爬虫遇到爬虫陷阱时,就会进入类似死循环的状态,浪费爬虫的资源。
11.3 网络带宽
下载大量不相关的网页、利用分布式网络爬虫、或者重新爬取大量网页都会导致网络容量的高消耗。
11.4 重复页面
网络爬虫机器人主要抓取网络上的所有重复内容;但是,只有页面的一个版本被索引。重复内容使搜索引擎机器人很难确定要索引和排名的重复内容版本。当 Googlebot 在搜索结果中发现一组相同的网页时,它会索引并仅选择其中一个页面来显示,以响应用户的搜索查询。
十二、3 个网络爬行最佳实践
12.1 爬行率
网站设置爬网速率来限制网络爬虫机器人发出的请求数量。爬网速率表示网络爬虫在给定时间间隔内可以向网站发出多少个请求(例如,每小时 100 个请求)。它使网站所有者能够保护其网络服务器的带宽并减少服务器过载。网络爬虫必须遵守目标网站的爬行限制。
12.2 Robots.txt合规性
robots.txt 文件是一组限制,用于通知网络爬虫机器人网站上可访问的内容。Robots.txt 指示抓取工具可以抓取网站上的哪些页面并建立索引以管理抓取流量。您必须检查网站的 robots.txt 文件并按照其中包含的说明进行操作。
12.3 动态IP
网站采用不同的反抓取技术(例如验证码)来管理爬虫流量并减少网络抓取活动。例如,浏览器指纹识别是网站用来收集访问者信息的跟踪技术,例如会话持续时间或页面浏览量等。这种方法允许网站所有者检测“非人类流量”并阻止机器人的 IP 地址。为了避免检测,可以将IP代理(例如住宅代理和反向连接代理)集成到网络爬虫中。
十三、网络爬行有哪些例子?
所有搜索引擎都需要有爬虫,示例如下:
- Amazonbot 是一个用于 Web 内容识别和反向链接发现的 Amazon 网络爬虫。
- 百度的 Baiduspider
- Bingbot,用于 Microsoft 的 Bing 搜索引擎
- DuckDuckGo 的 DuckDuckBot
- 法国搜索引擎 Exalead 的 Exabot
- 谷歌的 Googlebot
- 雅虎的 Yahoo! Slurp
- Yandex 的 Yandex Bot

核心概念-JSX](https://img-blog.csdnimg.cn/direct/b9c4626b55214dc2b4c4a90a66ec47d1.png)