一 select 语句续
WHERE子句后面'跟着'的是'一个或多个条件',用于指定需要'检索的行'
COUNT(): 多少'条'数据where 1=1 和 count(1) 与 count(*)
count(1)、count(*)和count(指定字段)之间的区别
① order by 排序

mysql 之数据排序扩展
1、使用 'order by' 语句来实现'排序'
2、排序可针对'一个'或'多个'字段
3、ASC: 升序,'default 默认'排序方式 --> 'ascending'
4、DESC:降序 --> 'descending order'
5、order by的'语法'结构
select 字段1,字段2 from '表名' order by '字段1 desc|asc','字段2 desc|asc';
细节点:order by 也可以通过 'where 子句' 对查询结果进行进一步的过滤
重点: 通过在SELECT语句中添加 'ORDER BY' 子句来对'结果集'进行排序
原理:
1)使用select语句可以将'需要的数据'从 mysql 数据库中'查询出来'
2)如果对'查询的结果'进行排序操作,可以使用 'order by' 语句完成'排序'
3)并且最终将排序后的结果'返回'给客户
重点:使用'CASE'语句'自定义'排序规则
② limit 限制查询结果
注意: 在MySQL中,LIMIT子句和OFFSET子句的顺序是'固定'的,先写LIMIT再写OFFSET
场景: 有时候我们'只'需要检索'结果集的前几行'或'特定范围内'的数据
需求1: 可以使用LIMIT子句来限制'结果集'的大小
具体:只返回前'2条'记录
SELECT id, name FROM customers LIMIT 2;
需求2:们也可以使用'OFFSET子句'来指定结果集的'起始'位置,默认是'0'
例如: 但从'第2'记录开始,只返回'10条'记录
SELECT id, name FROM customers LIMIT 2 OFFSET 21;
注意: 在MySQL中LIMIT子句和OFFSET子句的顺序是'固定'的,先写LIMIT再写OFFSET
++++++++++++++++ "分割线" ++++++++++++++++
补充: 限制从第1行开始,最多返回2行,结果返回了第1~2行
使用SELECT * FROM user LIMIT 0, 2;
③ group by 分组子句
select 分组函数,列 (要求出现在group by的后面)
from 表
【where 筛选条件】 -- '分组前'的筛选条件
group by 分组的列表 -- '分组'
【order by 子句】
having -- '分组后'的筛选用having而'不是'where
作用是通过一定的规则将一个数据集划分成'若干个小的区域',然后针对'若干个小区域'进行数据处理
细节点:'该列'必须'包含'在聚合函数或 'GROUP BY' 子句中 --> '类(集合)'group by 深入学习 分组查询的基础
-- 姓名,部门,薪水,入职日期
create table if not exists deploy (
id int NOT NULL PRIMARY KEY AUTO_INCREMENT,
name varchar(11) COMMENT '名字',
dept varchar(20) NOT NULL,
salary int NOT NULL,de date
) default character set utf8;
insert into deploy values(1,'张三','开发部',4000,'2015-09-28');
insert into deploy values(2,'李四','设计部',4500,'2010-10-15');
insert into deploy values(3,'王五','销售部',6000,'2012-10-15');
insert into deploy values(4,'王明','开发部',2500,'2015-10-28');
insert into deploy values(5,'王雨','开发部',2500,'2015-10-28');
insert into deploy values(6,'赵八','销售部',6000,'2010-11-28');
insert into deploy values(7,'赵八','设计部',3000,'2011-11-28');
insert into deploy values(8,'孙九','销售部',5000,'2017-11-28');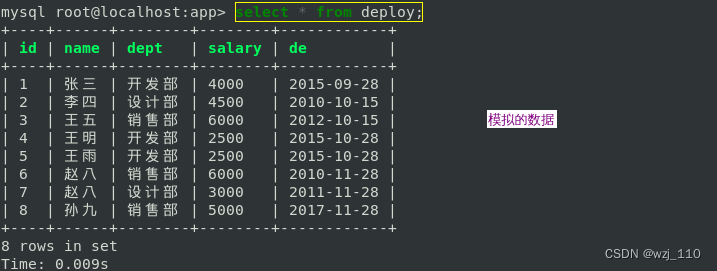
适用group by的'场景':出现函数如sum、max、avg、count,这种情况一般同时伴随着分组group by
④ having 筛选
+++++++++++++++ "mysql中的where和having子句筛选的区别" +++++++++++++++
1、having字句可以让我们筛选'成组后'的各种数据
2、where字句在'聚合前'先'筛选' row记录
备注: where'作用'在group by和having字句前,而 having子句在'聚合后'对'组记录'进行筛选
⑤ select 编排顺序

SELECT name, COUNT(*) as num_subscriptions
FROM customers
JOIN subscriptions ON customers.id = subscriptions.customer_id
WHERE name LIKE 'J%'
GROUP BY customers.id
HAVING num_subscriptions >= 2;
-- 该语句将按照名字以"J"开头的客户进行分组,并统计每个客户订阅的服务数量
-- 然后,它使用HAVING子句过滤掉订阅服务少于2个的客户












![题解:P9535 [YsOI2023] 连通图计数](https://img-blog.csdnimg.cn/img_convert/133179bda834c2975cdf87671dccb4d5.png)

