让计算机把真实图片抽象成简笔画,这个任务很有挑战性,需要模型捕获最本质的特征

以往的工作是找了素描的数据集,而且抽象程度不够高,笔画是固定好的,素描对象的种类不多,使得最后模型的效果十分受限
之所以用CLIP是因为它可以不管图像的风格,都能把物体的视觉特征编码的特别好
本模型不仅是生成简笔画,还可以通过控制使用笔画的多少实现不同程度的抽象
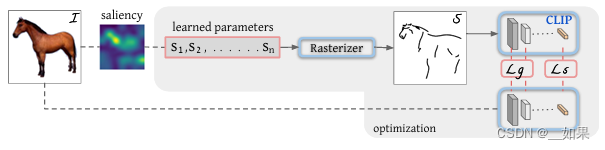
在白纸上随机初始化曲线,最后不断训练成简笔画
一个笔画1~4个点,点在空间中是二维的(x,y),模型训练更改四个点的位置,从而改变笔画的形状
learned parameters就是初始化的笔画
Rasterizer光栅化器是可导的,是图形学那边的工作
这篇文章的贡献在于前面如何更好的初始化,后面如何选择损失函数
像ViLD一样,在这里的ground truth是CLIP模型蒸馏,无论是原图还是简笔画,如果它们描述的是同一物体,那么最后得到的特征应该是差不多的,也就是Ls语义损失
但仅有语义不够,比如马头的位置反了,但还是马,这是语义相近,但是和原始输入图像就不匹配了,因此需要在几何形状上对模型的输出进行限制,即Lg。用前几层去算几何形状的loss,因为前几层语义空间较低,更关注形状的特征
做了几个实验后发现初始化位置很重要,作者提出saliency的方式:把图片扔进训练好的ViT,把最后一层的多头自注意力取一个加权平均,做成一个saliency map,然后看哪个区域更显著,到显著的区域上去采点

局限性:
当图像有背景的时候效果不好;笔画数是超参,无法自行调整