💛前情提要💛
本文是传知代码平台中的相关前沿知识与技术的分享~
接下来我们即将进入一个全新的空间,对技术有一个全新的视角~
本文所涉及所有资源均在传知代码平台可获取
以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦!!!
以下内容干货满满,跟上步伐吧~
📌导航小助手📌
- 💡本章重点
- 🍞一. 概述
- 🍞二. 论文思路
- 🍞三. 方法原理
- 🍞四. 实验过程
- 🍞五. 使用方式
- 🫓总结
💡本章重点
- 基于扩散模型的无载体图像隐写术
🍞一. 概述
当前的图像隐写技术主要集中在基于载体图(cover image)的方法上,这些方法通常存在泄露隐藏图(secret image)的风险和对退化容器图(container image)不鲁棒的风险。受到最近扩散模型(diffusion models)发展的启发,作者发现了扩散模型的两个特性,即无需训练即可实现两张图像之间的转换以及对噪声数据有天然的鲁棒性。这些特性可以用来增强图像隐写任务中的安全性和鲁棒性。这是首次将扩散模型引入图像隐写领域的尝试。与基于载体图的图像隐写方法相比,作者提出的CRoSS框架在可控性、鲁棒性和安全性方面具有明显优势。
🍞二. 论文思路
💡技术要点:
本文将无载体图图像隐写任务表示为三个图像和两个过程组成:这三个图像指的是秘密图像xsec、容器图像xcont和揭示图像xrev,而这两个过程是隐藏过程和揭示过程。秘密图像xsec是我们想要隐藏的图像,并通过隐藏过程隐藏在容器图像xcont中。通过互联网传输后,容器图像xcont可能会退化,得到容器图像的退化图像x’cont,我们通过揭示过程从中提取显示的图像xrev。根据上述定义,我们可以将隐藏过程视为秘密图像xsec和容器图像xcont之间的翻译,将揭示过程视为隐藏过程的反向过程。
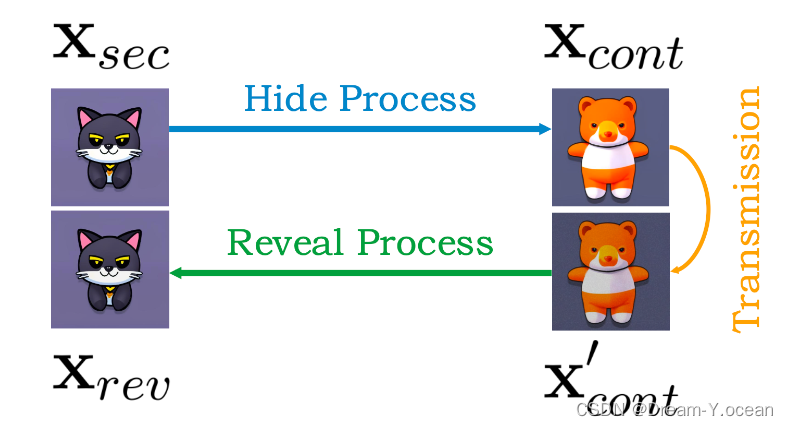
本文使用条件扩散模型来将秘密图像进行加密使之转换为容器图像,并使用DDIM反转来实现图像分布和噪声分布之间的双向转换,允许可逆图像转换,这样的方法使得容器图像能够成功被还原为秘密图像。

🍞三. 方法原理
1、CRoSS的隐藏过程
(1)原理:使用 DDIM 的前后向过程对秘密图像进行处理,得到容器图像。首先,使用一个私钥作为条件,对秘密图像进行加噪(前向过程),接着使用一个公钥作为条件,进行去噪(后向过程),这样就可以生成一个可以在互联网上传播的容器图像了。私钥用于描述秘密图像中的内容,而公钥用于控制容器图像中的内容。

如上图所示,prompt1是私钥,prompt2是公钥。并列的三幅图中,第一幅是秘密图像,第二幅是容器图像,第三幅是揭示图像。
(2)算法思路
输入:将被隐藏的秘密图像xsec,带有噪声估计器εθ的预训练条件扩散模型,采样时间步数T,以及作为私钥和公钥的两个不同条件kpri和kpub。
输出:用于隐藏秘密图像xsec的容器图像xcont。
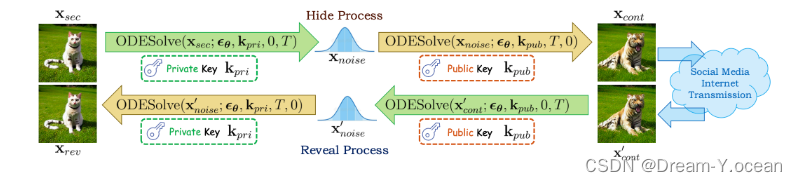
2、CRoss的揭示过程
(1)原理:在揭示阶段,假设容器图像已通过互联网传输,并可能已损坏为x’cont,接收器需要使用相同的条件扩散模型和相应提示词,通过相同的正向和后向过程的逆过程将其显示回秘密图像。在整个无载体图像隐写过程中,我们不专门为图像隐写任务训练或微调扩散模型,而是依靠DDIM反转保证的固有可逆图像翻译。
(2)算法思路
输入:通过互联网传输的容器图像x’cont(可能从xcont退化),带有噪声估计器εθ的预训练条件扩散模型,采样时间步数T,私钥kpri和公钥kpub。
输出:从容器图像中揭示出的图像xrev。
🍞四. 实验过程
1、实验设置
实验选择了稳定Stable Diffusion v1.5作为条件扩散模型,并使用了确定性DDIM采样算法。由秘密图像生成噪声图和由噪声图生成容器图各自都由50步组成。为了实现可逆图像转换,我们将稳定扩散的引导刻度设置为1。对于作为私钥和公钥的给定条件,我们有三个选项:prompts(提示词)、ControlNets条件(depth maps, scribbles, segmentation maps)和LoRAs。
2、数据准备
实验收集了总共260张图像,并生成专门为无载体图像隐写术量身定制的提示词,称为Stego260。实验将数据集分为三类,即人类、动物和一般物体(如建筑、植物、食物、家具等)。数据集中的图像来自公开的数据集和谷歌搜索引擎。为了生成提示密钥,我们使用BLIP生成私钥,并使用ChatGPT或人工调整来执行语义修改并批量生成公钥。
下图为使用ChatGPT生成公钥的过程。

3、核心代码
class ODESolve:
def __init__(self, model, NUM_DDIM_STEPS=50):
scheduler = DDIMScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", clip_sample=False,
set_alpha_to_one=False)
self.model = model
self.num_ddim_steps = NUM_DDIM_STEPS
self.tokenizer = self.model.tokenizer
self.model.scheduler.set_timesteps(self.num_ddim_steps)
self.prompt = None
self.context = None
def prev_step(self, model_output: Union[torch.FloatTensor, np.ndarray], timestep: int, sample: Union[torch.FloatTensor, np.ndarray]):
prev_timestep = timestep - self.scheduler.config.num_train_timesteps // self.scheduler.num_inference_steps
alpha_prod_t = self.scheduler.alphas_cumprod[timestep]
alpha_prod_t_prev = self.scheduler.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.scheduler.final_alpha_cumprod
beta_prod_t = 1 - alpha_prod_t
pred_original_sample = (sample - beta_prod_t ** 0.5 * model_output) / alpha_prod_t ** 0.5
pred_sample_direction = (1 - alpha_prod_t_prev) ** 0.5 * model_output
prev_sample = alpha_prod_t_prev ** 0.5 * pred_original_sample + pred_sample_direction
return prev_sample
def next_step(self, model_output: Union[torch.FloatTensor, np.ndarray], timestep: int, sample: Union[torch.FloatTensor, np.ndarray]):
timestep, next_timestep = min(timestep - self.scheduler.config.num_train_timesteps // self.scheduler.num_inference_steps, 999), timestep
alpha_prod_t = self.scheduler.alphas_cumprod[timestep] if timestep >= 0 else self.scheduler.final_alpha_cumprod
alpha_prod_t_next = self.scheduler.alphas_cumprod[next_timestep]
beta_prod_t = 1 - alpha_prod_t
next_original_sample = (sample - beta_prod_t ** 0.5 * model_output) / alpha_prod_t ** 0.5
next_sample_direction = (1 - alpha_prod_t_next) ** 0.5 * model_output
next_sample = alpha_prod_t_next ** 0.5 * next_original_sample + next_sample_direction
return next_sample
def get_noise_pred_single(self, latents, t, context):
noise_pred = self.model.unet(latents, t, context)["sample"]
return noise_pred
def get_noise_pred(self, latents, t, is_forward=True, context=None):
if context is None:
context = self.context
guidance_scale = GUIDANCE_SCALE
uncond_embeddings, cond_embeddings = context.chunk(2)
noise_pred_uncond = self.model.unet(latents, t, uncond_embeddings)["sample"]
noise_prediction_text = self.model.unet(latents, t, cond_embeddings)["sample"]
noise_pred = noise_pred_uncond + guidance_scale * (noise_prediction_text - noise_pred_uncond)
if is_forward:
latents = self.next_step(noise_pred, t, latents)
else:
latents = self.prev_step(noise_pred, t, latents)
return latents
@torch.no_grad()
def latent2image(self, latents, return_type='np'):
latents = 1 / 0.18215 * latents.detach()
image = self.model.vae.decode(latents)['sample']
if return_type == 'np':
image = (image / 2 + 0.5).clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).numpy()[0]
image = (image * 255).astype(np.uint8)
return image
@torch.no_grad()
def image2latent(self, image):
with torch.no_grad():
if type(image) is Image:
image = np.array(image)
if type(image) is torch.Tensor and image.dim() == 4:
latents = image
else:
image = torch.from_numpy(image).float() / 127.5 - 1
image = image.permute(2, 0, 1).unsqueeze(0).to(device)
latents = self.model.vae.encode(image)['latent_dist'].mean
latents = latents * 0.18215
return latents
@torch.no_grad()
def init_prompt(self, prompt: str):
uncond_input = self.model.tokenizer(
[""], padding="max_length", max_length=self.model.tokenizer.model_max_length,
return_tensors="pt"
)
uncond_embeddings = self.model.text_encoder(uncond_input.input_ids.to(self.model.device))[0]
text_input = self.model.tokenizer(
[prompt],
padding="max_length",
max_length=self.model.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_embeddings = self.model.text_encoder(text_input.input_ids.to(self.model.device))[0]
self.context = torch.cat([uncond_embeddings, text_embeddings])
self.prompt = prompt
@torch.no_grad()
def get_text_embeddings(self, prompt: str):
text_input = self.model.tokenizer(
[prompt],
padding="max_length",
max_length=self.model.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_embeddings = self.model.text_encoder(text_input.input_ids.to(self.model.device))[0]
return text_embeddings
4、实验结果
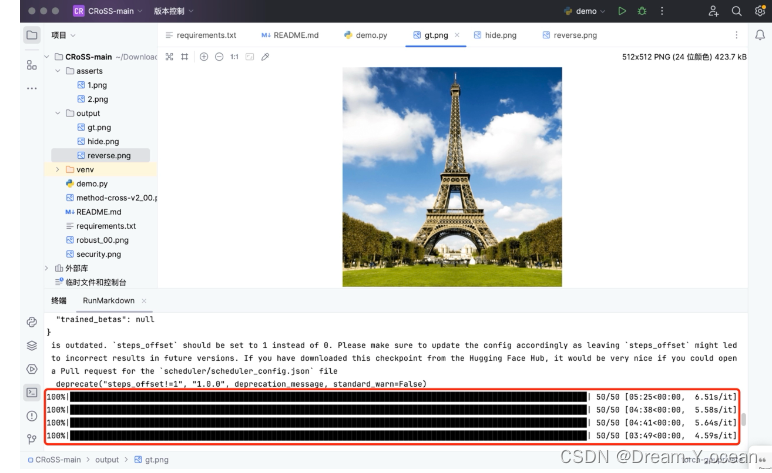
运行ReadMe文件中的以下代码,快速运行代码进行图片加密解密。
python demo.py --image_path ./asserts/1.png --private_key "Effiel tower" --public_key "a tree" --save_path ./output --num_steps 50
成功运行界面如下:
打开output文件夹,查看实验过程中的三幅图像
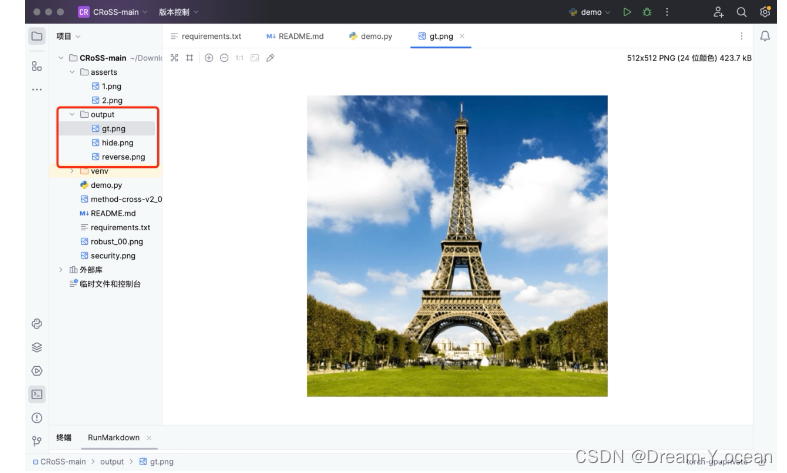
待加密图像:

容器图像:

揭示图像:

可以发现,隐写后的图片自然且清晰度高,不易被察觉到隐藏了秘密图像,揭示图像还原度高,经过网络传输后仍然能够很好地被还原。
🍞五. 使用方式
编译器采用Pycharm,下载好项目代码后,阅读ReadMe文件以及“requirements.txt”。
首先运行ReadMe文件中的以下代码,下载好实验所需的所有库并配置好环境。
pip install -r requirements.txt
然后运行ReadMe文件中的以下代码,快速运行代码进行图片加密解密。
python demo.py --image_path ./asserts/1.png --private_key "Effiel tower" --public_key "a tree" --save_path ./output --num_steps 50
上述image_path后面的参数是要加密图像在设备上的路径,可以根据自己的图片路径进行调整;private_key后面的参数是私钥,根据不同待加密图片的内容自行调整;public_key后面的参数是公钥,根据想要生成的容器图像内容进行调整;save_path后面的参数是加密后的容器图像的保存地址,如果不修改的话每次运行程序都会覆盖前一次的运行结果;num_steps后面的参数是迭代次数,可以根据自己的需要进行调整,一般迭代次数越多效果越好,花费的时间越长。
🫓总结
综上,我们基本了解了“一项全新的技术啦” 🍭 ~~
恭喜你的内功又双叒叕得到了提高!!!
感谢你们的阅读😆
后续还会继续更新💓,欢迎持续关注📌哟~
💫如果有错误❌,欢迎指正呀💫
✨如果觉得收获满满,可以点点赞👍支持一下哟~✨
【传知科技 – 了解更多新知识】