前言
最近在学NTFS,发现网上的博客千篇一律,讲的不够通透,于是决定自己写一篇。
本文章通过寻找文件地址这个任务,讲述了NTFS文件系统$Boot文件、$MFT文件的结构,对$MFT文件中的A0、80属性进行了重点分析。
本文对于NTFS的具体每种属性的字段含义不会详细阐述,因此可以预先了解相关知识,或者在看到文中提到这些知识时使用搜索引擎详细查证一下。
个人认为讲的比较好的博客和资源:
- https://www.cnblogs.com/lsh123/p/15789479.html
- https://blog.csdn.net/enjoy5512/article/details/50935972
- https://www.ntfs.com/ntfs-partition-boot-sector.htm
- https://github.com/BigGan/Windows-Hack-Programming/issues/3
- https://www.intohard.com/thread-61790-1-1.html
任务背景
在一块NTFS硬盘中存在如下文件:
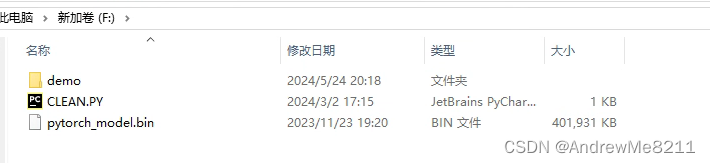
其中demo文件夹中有如下文件:

目标是,通过解析NTFS底层数据,找到上述所有文件的源数据。
当然,无论是010 editor还是winhex还是各类工具,其实都能够很快的通过程序找到上述文件,但是为了探究系统文件寻址的底层流程,我们认为有必要在不使用解析程序的条件下走一遍这样的流程。
实验过程
使用winhex打开硬盘:

硬盘的前8个字节告诉我们这是一块NTFS的硬盘。
众所周知,NTFS包含了16个元文件和数据区,其结构如下:

其中最开头的Boot Sector则对应了$Boot元文件,它从0号扇区开始,向后占用16个扇区。Master File Table则对应了$MFT文件,其开始位置可以在$Boot元文件中找到。要找到硬盘文件的具体位置,主要就分析这两个文件。
1. 分析$Boot文件
$Boot文件(后简称Boot文件)在第一扇区(0号扇区),从偏移量为BH的位置开始,长度为73个字节的数据为文件内的BPB结果,该结构记录了有关文件系统的重要信息。
在样例中,Boot文件内容如下所示,图中勾选内容为其BPB字段。

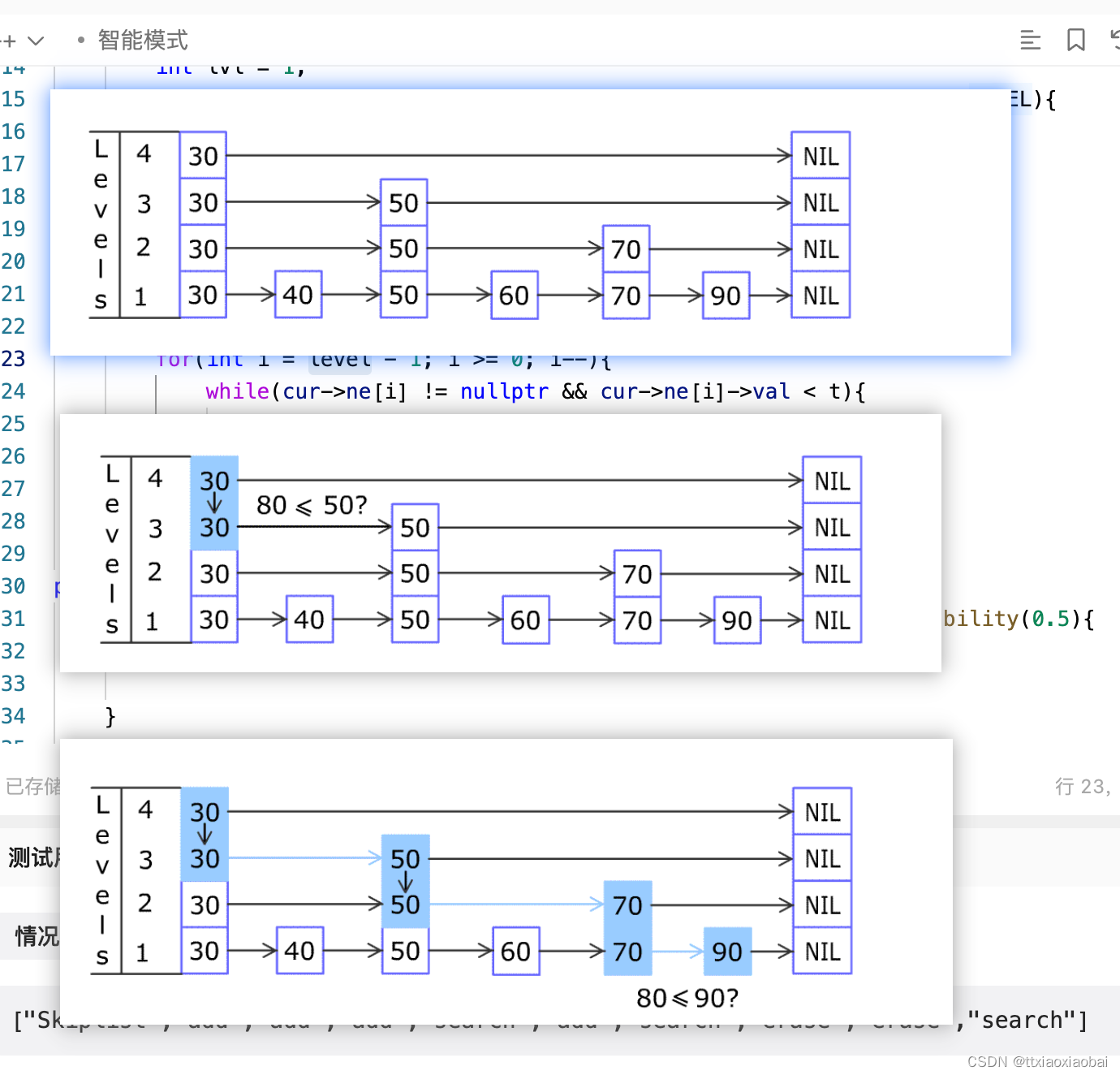
BPB中比较重要的是如下几个字段:
| Offsets | 数据 | 含义 |
|---|---|---|
| BH-CH | 00 02 | 每个扇区512字节,0.5KB |
| DH | 08 | 每个簇8个扇区,4096字节 |
| 30H-37H | 00 00 0C 00 00 00 00 00 | $MFT文件开始簇号为786432 |
| 40H-43H | F6 00 00 00 | 每个MFT记录占246簇 |
| 44H-47H | 01 00 00 00 | 每个索引占1簇 |
此时可以通过上述数据计算$MFT文件所在扇区。由于一个簇8个扇区,因此$MFT文件所在扇区为786432x8=6291456,跳转到该扇区后数据内容如下所示:

2. 分析$MFT文件
$MFT文件(简称MFT文件)包含了多个文件目录项,每一个文件目录项占用2个扇区,以46 49 4C 45H(FILE)开头。并且,MFT文件中的第一个文件目录项必然是MFT元文件自身,第6个文件目录必然是根目录。为了找到具体的文件,我们需要找到根目录的文件目录项。由于MFT文件目录项所在扇区为786432x8=6291456,因此根目录文件目录项和MFT文件目录项相差5个扇区,在6291456+5x2=6291466扇区,数据内容如下。

一般而言,根目录的文件目录项中会存在10H、30H、40H、50H、90H、A0H、B0H几种属性,而根目录的具体内容则在A0H属性中解析。图中的A0H属性使用了run list。一般而言,属性的长度如果不够存数据,则会使用run list进行跳转,将数据存在另外的空间中。如果某属性只有1个run list的话,只需按照如下方式解析即可:

如果有多个run list,解析方式可以看这个链接:
https://github.com/BigGan/Windows-Hack-Programming/issues/3
基于这种方式,由于上图的run list为11 01 24H,解析结果说明run list指向的起始簇号为24H=36簇,即36x8=288扇区,且大小为1簇,即4KB。跳转到288扇区得到根目录的具体数据(索引缓冲区)如下:

3. 分析根目录索引缓冲区
文件目录索引缓冲区的阅读方法类似于单向链表的遍历方式,系统需要先从索引头开始,读取第一个索引项的起始位置,并且结合索引项的长度计算下一个索引项的起始位置。为了方便表述先假设上述缓冲区开始的偏移是0H(本来是24000H)。
索引缓冲区索引头以49 4E 44 58H(INDX)开头,在其偏移为18H处保存了第一个索引项的偏移地址,即图中的40H,因此得到第一个文件的索引项的开始位置为18H+40H=58H。从索引项的开头向后数的第9个字节,即偏移为8H的位置的一个字节,为该索引项的长度,图中为68H,因此得到该索引在68H+58H=C0H处结束,此时可以确定第一个文件的索引项内容如下:

以此类推,可以得到根目录中所有文件索引项的起始位置和大小:
| 文件ID | 开始位置 | 索引项大小 | 文件信息 |
|---|---|---|---|
| 1 | 58H | 68H | … |
| 2 | 58H+68H=C0H | 68H | … |
| 3 | C0H+68H=128H | 60H | … |
| … | … | … | … |
| 13 | 4F0H | 68H | CLEAN.PY |
| 14 | 558H | 60H | demo文件夹 |
| 15 | 5B8H | 78H | pytorch_model.bin |
解析根目录中索引项的目的在于读取文件的MFT参考号,这一数据项的含义在于确定该文件在MFT文件中是第几个文件记录。在索引项中,MFT参考号为索引项的第一个字节。以demo文件夹为例,其索引项如下所示:

得到其MFT参考号为29H,即41。这说明该文件夹是MFT文件中第41个文件记录。由于MFT文件在6291456扇区,而一个文件记录占用2个扇区,因此该文件夹的MFT文件记录在磁盘中的位置为6291456+41x2=6291538扇区,具体内容如下:

4.寻找demo文件夹和demo.txt
此时我们已经找到了demo文件夹的具体内容。为了找到demo文件夹中的demo.txt,我们需要解析其中的90H属性。
90H属性是索引根属性,A0H是索引分配属性。为什么之前根目录没有分析90H属性,而在demo文件夹这个目录中我们就要分析90H属性呢?
这和目录大小有关。当一个目录很小时,就可以完全存放在索引根属性(90H属性)中,这时该目录就只需要一个属性来描述。但是有的目录太大不能完全存放在索引根中时,这时就要用到$INDEX_ALLOCATION(A0H)索引分配属性来存放它的索引项。
而上面的demo文件夹中不存在A0H属性,说明90H属性足够存放目录内容
解析上述90H属性,发现其中只存在一个索引项,MFT参考号为2AH,即40,这意味着demo.txt存储在MFT文件的第40个文件记录中,计算得到该文件所在扇区编号为6291540,数据内容如下所示。

能很清楚的看到文本中的内容,说明数据读取无误。
5.寻找pytorch_mode.bin
在根目录索引缓冲区中,pytorch_model.bin的索引项如下所示:

其MFT参考号为为27H,用前文所述方法可以计算出文件的MFT目录项在6291534扇区,内容如下:
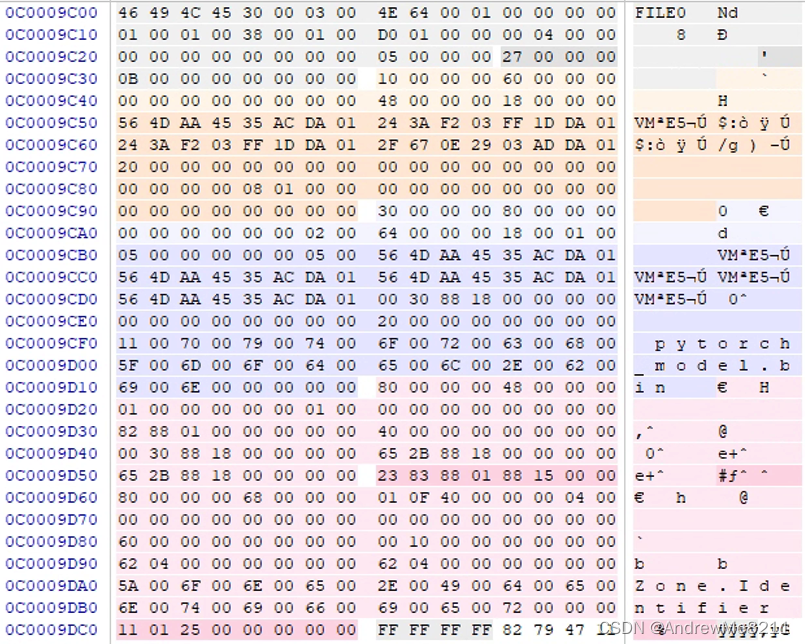
由于该文件是一个大文件,因此数据属性(80H属性)使用了run list。
第一个run list的内容为23 83 88 01 88 15,解析结果为,数据大小为018883H(100483),起始簇号为1588H(即5512簇,5512*8=44096扇区)。跳转到44096扇区,可以看到该文件的第一部分:

第二个run list为11 01 25,解析得出该文件在37簇,内容如下:

至此所有文件在底层的位置已经全部找到。