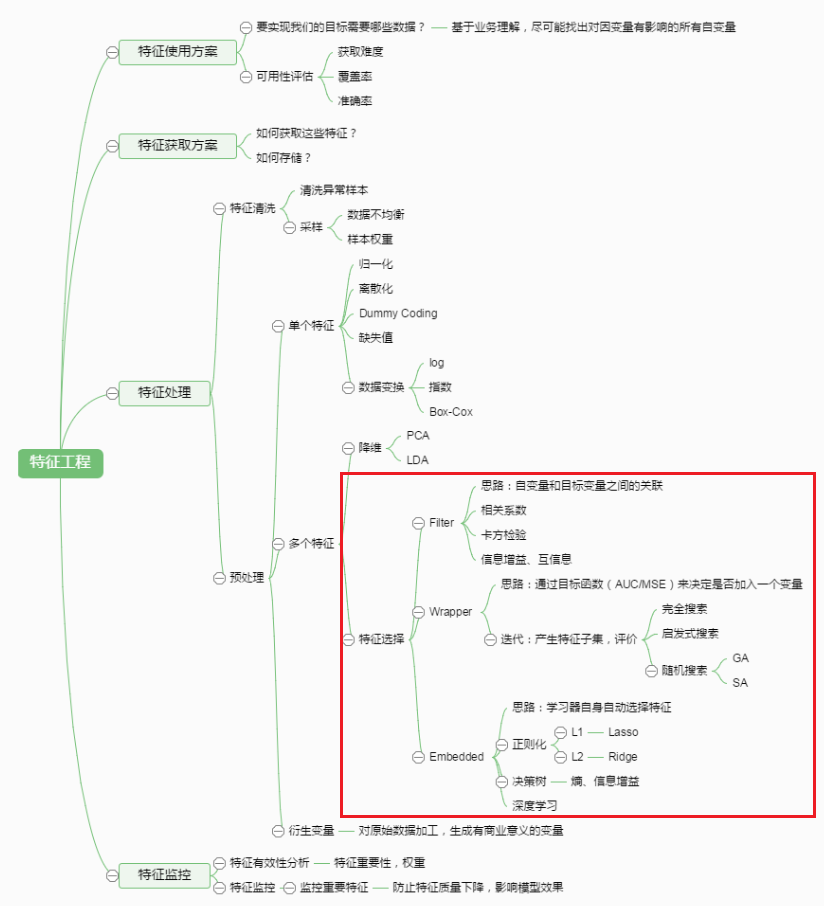
文章目录
- 1. 什么是特征选择
- 2. 特征选择与特征提取的区别
- 3. 特征选择的方法
- 3.1 Filtering过滤法
- 3.2 Wrapper包装法
- 3.3 Embedding嵌入法
- 4. 特征选择示例
- 4.1 方差选择法示例
- 4.2 递归特征消除法示例
1. 什么是特征选择
-
特征选择是特征工程的内容, 其目标是寻找最优特征子集。剔除不相关或冗余特征, 减小特征数量
-
特征选择的作用
- (1) 过拟合的表现是模型太贴合训练数据而在测试集上表现不好, 特征选择能通过减少不相关或冗余特征来降低过拟合的风险
- (2) 在数据预处理阶段, 能够帮助识别缺失值过多, 异常值过多, 特征高度相关的特征
- (3) 对大型数据集或实时应用来说, 能够减少计算量, 提高计算效率
- (4) 能够提高模型的可解释性。特征选择能够帮助识别哪些特征对模型预测有影响, 从而提高模型的可解释性
- (5) 特征选择还能降低数据维度, 同样的, 特征提取也可以降低维度
2. 特征选择与特征提取的区别
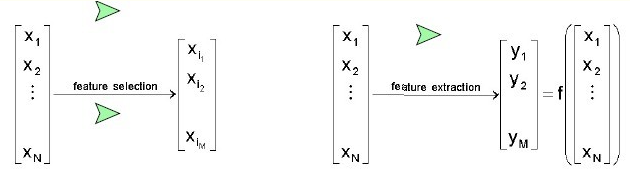
-
如上图所示, 用数学的话来解释:
- 特征选择后的特征是原来特征的一个子集
- 特征提取后的新特征是原来特征的一个映射
-
比如, 有长、宽两个特征,特征选择是根据模型的目标来选择长这个特征或者选择宽这个特征,而特征提取是把长和宽两个特征提取成面积这个"新特征"
3. 特征选择的方法
- 特征选择主要从两个方面考虑: 方差和相关性
- 方差:特征是否发散。如果一个特征不发散,比如方差接近0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用
- 相关性:特征与目标的相关性。与目标相关性高的特征,应当优选选择
3.1 Filtering过滤法
-
基本思想:分别对每个特征 x i x_i xi,计算 x i x_i xi相对于类别标签 y y y的信息量 S ( i ) S(i) S(i),得到 n n n个结果。然后将 n n n个 S ( i ) S(i) S(i)按照从大到小排序,输出前前k个特征,完成特征选择。问题的关键在于如何计算信息量 S ( i ) S(i) S(i)
-
过滤法方法如下:
- 方差选择法:
- 先计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征
- 不需要计算特征与标签的信息量
- 基于各特征分布方式较为接近的时候,才能以方差的逻辑来衡量信息量,连续变量不适合用方差选择法
- 可以使用sklearn.feature_selection库的VarianceThreshold类来选择k个最好的特征
- 相关系数法:
- 计算各个特征对目标值的相关系数以及相关系数的P值,选择k个最好的特征
- 相关系数是一种最简单的,能帮助理解特征和相应变量之间关系的方法。衡量的是变量之间的线性相关性,结果的取值区间为[-1, 1],-1表示表示完全负相关,+1表示完全正相关,0表示没有线性相关性
- 速度快,易于计算,数据清洗第一阶段可执行
- 明显缺陷是只对线性关系敏感,非线性关系即使一一对应,P相关系数也可能为0
- 可以用sklearn.feature_selection库的SelectKBest类结合相关系数来选择k个最好的特征
- 卡方验证:
- 构建卡方分布统计量,检验自变量n个取值对因变量m个取值的相关性
- 可以用sklearn.feature_selection库的SelectKBest类结合卡方检验来选择k个最好的特征
- 互信息法和最大信息系数法:
- 采用互信息评价定性自变量对定性因变量的相关性
- 互信息直接用于特征选择不方便,不方便归一化且不方便计算连续数据,需要对连续数据进行离散化
- 最大信息系数法统计定量数据
- 可以用sklearn.feature_selection库的SelectKBest类结合最大信息系数法来选择k个最好的特征
- 方差选择法:
3.2 Wrapper包装法
-
基本思想:基于留出法hold-out,对每一个待选的特征子集,都在训练集上训练一遍模型,然后在测试集上根据误差大小选择出特征子集。需要先选定特定算法,通常选用普遍效果较好的算法(想训练什么算法就选择什么算法进行评估),例如RF、SVM、KNN等
-
包装法方法如下:
- 前向搜索:每次增量从剩余未选特征中选出一个加入特征集,待达到阈值或n时,从所有的特征集中选出错误率最小的特征集。 O ( n 2 ) O(n^{2} ) O(n2)的时间复杂度
- 后向搜索:增量减,开始特征集包含{1,2,…,n},每次删除一个特征,直到达到阈值或为空。选择最佳的特征集。 O ( n 2 ) O(n^{2} ) O(n2)的时间复杂度
- 递归特征消除法:使用基模型进行多轮训练,每轮根据学习器返回的coeff和feature_importance来消除若干权重较低的特征,再根据新的特征集进行下一轮训练
3.3 Embedding嵌入法
- 基本思想:先使用某些机器学习的模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征,类似于Filtering,只不过系数是通过训练得到的
- 嵌入法的方法:
- 基于惩罚项的特征选择法:使用sklearn.feature_selection库的SelectFromModel类结合带L1以及L2惩罚项的基本模型如LR/SVM模型,来选择特征
- 基于树模型的特征选择法:树模型中选择GBT决策树作为基模型选择特征。使用sklearn.feature_selection库的SelectFromModel类结合GBDT模型,来选择特征
4. 特征选择示例
4.1 方差选择法示例
-
不使用基模型
-
不计算特征与目标相关性
-
设置过滤阈值
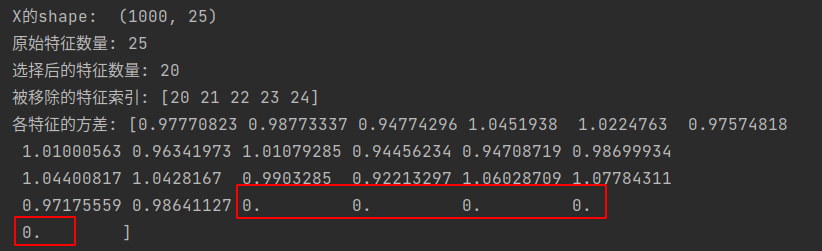
import numpy as np from sklearn.feature_selection import VarianceThreshold from sklearn.datasets import make_regression # 创建一个模拟的回归数据集,但是添加一些方差很低的特征 X, y = make_regression(n_samples=1000, n_features=20, noise=0.1) # 添加一些几乎恒定的特征 constant_value = 10 # 设定一个几乎恒定的值 X = np.hstack((X, np.ones((X.shape[0], 5)) * constant_value)) print("X的shape: ", X.shape) # [1000, 25] # 查看原始特征的数量 print(f"原始特征数量: {X.shape[1]}") # 初始化方差选择法,设定阈值为某个较小的值(例如,我们期望移除方差接近于0的特征) selector = VarianceThreshold(threshold=(.8 * (1 - .8))) # 假设我们设定阈值为方差的20% # 在数据上拟合方差选择法 X_new = selector.fit_transform(X) # 查看选择后的特征数量 print(f"选择后的特征数量: {X_new.shape[1]}") # 输出被移除的特征的索引 print(f"被移除的特征索引: {np.setdiff1d(np.arange(X.shape[1]), selector.get_support(indices=True))}") # 如果你想要查看每个特征的方差,可以使用numpy的var函数 variances = np.var(X, axis=0) print(f"各特征的方差: {variances}") # 可以看到,那些方差接近0的特征(即我们添加的恒定值特征)现在已经被移除了,如下图 -
被过滤掉的特征的方差:
4.2 递归特征消除法示例
-
可以使用LR、SVM等基模型,使用的模型最好是训练任务要用的模型
-
设置要保留的特征个数
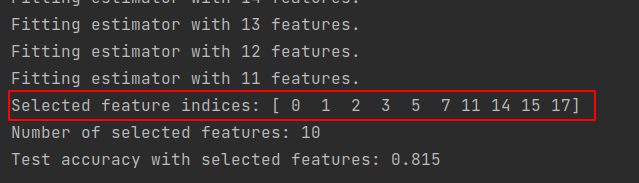
import numpy as np from sklearn.datasets import make_classification from sklearn.linear_model import LogisticRegression from sklearn.feature_selection import RFE from sklearn.model_selection import train_test_split # 创建一个模拟的二分类数据集,具有一些非线性关系 # 数据集有1000个样本, 特征数20, 其中10个是与输出相关的特征, 5个冗余特征 X, y = make_classification(n_samples=1000, n_features=20, n_informative=10, n_redundant=5, random_state=42) # 划分数据集为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 初始化逻辑回归模型 lr = LogisticRegression(solver='lbfgs', max_iter=1000, random_state=42) # 初始化递归特征消除对象,并设置要选择的特征数量(或者传递一个step参数来控制每次迭代中移除的特征数量) # 在这个例子中,我们让RFE自动决定保留的特征数量; 返回特征选择后的数 # 参数estimator为基模型; n_features_to_select为要选择的特征数量 rfe = RFE(estimator=lr, n_features_to_select=10, step=1, verbose=1) # 在训练数据上拟合RFE模型 rfe.fit(X_train, y_train) # 输出被选择的特征的索引: true表示特征被选择, false表示特征被排除 # print("Selected features indices:", rfe.support_(indices=True)) selected_feature_indices = np.where(rfe.support_)[0] print("Selected feature indices:", selected_feature_indices) # 输出被选择的特征数量 print("Number of selected features: %d" % rfe.n_features_) # 可以通过transform方法获取训练集和测试集上的所选特征 X_train_selected = rfe.transform(X_train) X_test_selected = rfe.transform(X_test) # print("所选择的训练特征: ", X_train_selected) # print("所选择的测试特征: ", X_test_selected) # 现在可以使用X_train_selected和X_test_selected在新的逻辑回归模型上进行训练和评估 lr_selected = LogisticRegression(solver='lbfgs', max_iter=1000, random_state=42) lr_selected.fit(X_train_selected, y_train) score = lr_selected.score(X_test_selected, y_test) print("Test accuracy with selected features:", score) -
被选择特征的索引:
创作不易,如有帮助,请 点赞 收藏 支持
[参考文章]
[1]. 特征选择vs特征提取
[2]. 特征工程和特征选择
[3]. 特征选择方法汇总
[4]. 百度文心一言大模型
created by shuaixio, 2024.05.24