
【原文】众所周知,大型语言模型在小样本上下文学习(ICL)方面非常有效。多模态基础模型的最新进展实现了前所未有的长上下文窗口,为探索其执行 ICL 的能力提供了机会,并提供了更多演示示例。在这项工作中,我们评估了从少镜头到多镜头 ICL 的多模态基础模型的性能。我们在跨越多个领域(自然图像、医学图像、遥感和分子图像)和任务(多类、多标签和细粒度分类)的 10 个数据集上对 GPT-4o 和 Gemini 1.5 Pro 进行基准测试。我们观察到,在所有数据集中,与少样本(<100 个样本)ICL 相比,多样本 ICL(包括多达近 2,000 个多模态演示示例)带来了显着改进。此外,Gemini 1.5 Pro 的性能继续以对数线性方式提高,直至许多数据集上测试示例的最大数量。考虑到与多次 ICL 所需的长提示相关的高推理成本,我们还探讨了在单个 API 调用中批处理多个查询的影响。我们表明,批处理最多 50 个查询可以在零样本和多次 ICL 下提高性能,在多个数据集上的零样本设置中获得显着收益,同时大幅降低每个查询的成本和延迟。最后,我们测量模型的 ICL 数据效率,或者模型从更多演示示例中学习的速率。我们发现,虽然 GPT-4o 和 Gemini 1.5 Pro 在整个数据集上实现了相似的零样本性能,但 Gemini 1.5 Pro 在大多数数据集上表现出比 GPT-4o 更高的 ICL 数据效率。我们的结果表明,多次 ICL 可以使用户有效地将多模态基础模型适应新的应用程序和领域。
原文:Many-Shot In-Context Learning in Multimodal Foundation Models
地址:https://arxiv.org/abs/2405.09798v1
代码:https://github.com/stanfordmlgroup/ManyICL
出版:未知
机构: Stanford University \
1 研究问题
本文研究的核心问题是: 随着多模态基础模型使用的上下文长度大幅提升,如何探究在图像分类任务中使用大量演示样本进行上下文学习(in-context learning, ICL)的性能表现。
假设我们正在开发一个医疗影像分析系统,目标是根据胸部X光片诊断不同类型的肺部疾病。我们有一个预训练的多模态基础模型,它可以处理图像和文本。现在的问题是,我们应该在模型推理时提供多少相关的演示样本(比如一些带标注的X光片样例),才能最大程度地发挥模型的few-shot学习能力,以较低的成本获得较好的分类性能。
本文研究问题的特点和现有方法面临的挑战主要体现在以下几个方面:
-
现有的ICL研究大多局限于少样本(few-shot)场景,即在模型推理时只提供少量(通常<100个)演示样本。这主要是因为模型可以处理的上下文长度有限。然而,随着最新的多模态基础模型可用上下文长度大幅提升(如GPT-4o达到128,000 tokens,Gemini 1.5 Pro达到一百万tokens),研究多样本(many-shot)ICL的可能性和必要性凸显。
-
图像数据通常需要大量tokens来表示,这进一步限制了在给定上下文长度下可包含的演示样本数量。因此,研究many-shot ICL需要精心设计实验,在样本多样性和个体信息量之间平衡。
-
尚不清楚增加ICL演示样本在多大程度上、以何种模式提升模型性能。比如性能是否会在样本数达到一定规模后趋于饱和?不同数据集和任务之间表现是否一致?
-
加入大量演示样本势必导致输入序列急剧加长,大幅提高inference成本。如何在保证性能的同时控制计算开销,是many-shot ICL研究必须考虑的现实问题。
针对这些挑战,本文提出了一种全面评估many-shot ICL的实验范式:
本文选取了10个覆盖多个领域(自然图像、医学影像、遥感影像、分子影像)和任务(多分类、多标签、细粒度分类)的数据集,在每个数据集上都构建了一个较大规模(最多近2000个)的演示样本集。然后,分别使用GPT-4o和Gemini 1.5 Pro两个具有超长上下文的多模态基础模型,测试在不同演示样本规模下的few-shot到many-shot的性能变化曲线,由此系统地考察样本数量、数据集、任务、模型等因素的影响。针对计算成本问题,本文还巧妙地利用query batching技术,在每次API调用中打包多个query,从而在几乎不损失性能的情况下大幅降低了平均时延和费用。此外,本文还定义了一种ICL数据效率指标,用以衡量模型从增加演示样本中学习的能力。基于以上实验设计,本文系统地研究了多模态模型在many-shot场景下的行为特性,为相关研究提供了重要参考。
2 研究方法
2.1 模型选择与数据集介绍
本论文选择了两个最先进的多模态基础模型GPT-4o和Gemini 1.5 Pro进行实验。它们都具有公开的API接口,并且都支持超长的上下文窗口,为探索增加演示样本数量对性能的影响提供了机会。
论文在10个数据集上对模型进行了评估,这些数据集涵盖了多个领域(自然图像、医学图像、遥感、分子图像)和任务(多类别分类、多标签分类、细粒度分类)。表1总结了所使用的数据集的基本信息。
对于所有数据集,论文从原始的训练集和验证集中构建了一个演示样本集用于上下文学习,从原始的测试集(如果存在)中构建了一个测试集用于评估模型性能。构建过程是在原始数据集上进行无放回随机采样。对于多类别和细粒度分类任务,进行了按类别分层的采样,确保演示集和测试集中每个类别的样本数量相等。对于多标签分类任务(CheXpert),在演示集和测试集中对每个类别采样相等数量的正负样本。表1展示了每个数据集的完整演示集和测试集的大小。
2.2 Many-shot ICL方法

Many-shot ICL是指在查询前提供大量演示样本作为上下文信息,与zero-shot(无演示样本)和few-shot(少量演示样本)形成对比。图1直观地总结了它们之间的区别。本论文旨在通过many-shot ICL来探索增加演示样本数量能在多大程度上提升模型性能。
实验中所使用的prompt设计如下所示:
<<IMG>>Given the image above, answer the following question using the specified format.
Question: What is in the image above?
Choices: {str(class_desp)}
Answer Choice: {demo.answer}
其中<<IMG>>表示图像的占位符,{str(class_desp)}是类别的描述,{demo.answer}是演示样本的答案。测试阶段的prompt会让模型给出置信度:
Please respond with the following format:
---BEGIN FORMAT TEMPLATE---
Answer Choice: [Your Answer Choice Here]
Confidence Score: [Your Numerical Prediction Confidence Score Here From 0 To 1]
---END FORMAT TEMPLATE---
Do not deviate from the above format. Repeat the format template for the answer.
为了验证many-shot ICL对prompt设计的鲁棒性,论文在HAM10000和EuroSAT两个数据集上尝试了不同的prompt。结果表明虽然性能有轻微波动,但整体的对数线性提升趋势是一致的。
2.3 批量查询与消融实验
由于在prompt中包含大量演示样本会导致输入序列非常长,推理成本很高。为了降低单次查询的延迟和成本,论文探索了在一次请求中批量查询多个样本的方法。
具体而言,在many-shot ICL设置下,实验发现适度的批量大小(最多50个查询)基本不会损害性能,而大幅降低了单个样本的延迟和成本。更令人惊讶的是,在zero-shot设置下,批量查询不仅没有损害性能,在一些数据集上反而大幅提升了性能。
为了分析zero-shot批量查询提升性能的原因,论文设计了一系列消融实验:
-
为了测试领域校准(domain calibration)的作用,在prompt中包含来自同一类别的49张无标签图像
-
为了测试类别校准(class calibration)的作用,在prompt中包含来自所有类别的49张无标签图像
-
为了测试自生成演示样本的作用,使用zero-shot模型对随机采样的49张图像进行预测,并将预测标签加入prompt
结果表明,领域校准、类别校准和自生成演示样本都有助于提升zero-shot批量查询的性能,三者的组合与直接批量查询50个样本的性能相当。这说明它们是性能提升的主要原因。
2.4 评估指标
论文使用一些标准指标来评估模型在每个数据集上的性能。对于所有的多类别分类数据集,由于采样确保了类别平衡,因此使用准确率(accuracy)作为指标。对于多标签分类数据集CheXpert,使用宏平均F1值。为了估计评估指标的变化性,使用Bootstrap方法进行1000次重采样计算标准差。
除了标准指标,论文还定义了一个ICL数据效率指标来衡量模型从演示样本中学习的效率。具体地,在log(N+1) (N为样本数量)和模型性能之间进行线性回归,并强制回归线经过zero-shot性能点。这个指标近似了每增加10倍演示样本可以期望的性能提升。 第四步、实验部分详细撰写:
3 实验
3.1 实验场景介绍
该论文探究了在增加大量演示样例的情况下,多模态基础模型进行上下文内学习(in-context learning, ICL)的能力。主要研究many-shot ICL在不同任务和领域的数据集上的性能表现,以及批量查询对性能、推理延迟和成本的影响。
3.2 实验设置
-
Datasets: 10个跨领域的图像分类数据集,包括自然图像、医学图像、遥感和分子图像等,涵盖多分类、多标签和细粒度分类任务。
-
Models: GPT-4o、Gemini 1.5 Pro和GPT4(V)-Turbo
- Implementation details:
-
对多分类和细粒度分类数据集进行分层采样,保证每个类别样本数相同
-
使用markdown格式进行编码
-
- metric:
-
多分类数据集使用准确率(accuracy)
-
多标签分类数据集(CheXpert)使用宏平均F1值
-
ICL数据效率:log10(N+1)和性能之间的线性回归,估计演示样本数增加一个数量级带来的性能提升
-
3.3 实验结果
3.3.1 实验一、增加演示样例数对模型性能的影响

目的: 评估增加演示样例数对GPT-4o和Gemini 1.5 Pro性能的影响
涉及图表: 图2、表2
实验细节概述:在10个数据集上,通过增加演示样例数(从零样本到上千样本)来评估GPT-4o和Gemini 1.5 Pro的性能变化。同时测量了它们的ICL数据效率。
结果:
-
Gemini 1.5 Pro在除DrugOOD Assay外的所有数据集上,随着演示样例数的增加表现出稳定且显著的性能提升。在多数数据集上,性能随样本数对数线性提升。
-
GPT-4o在除FIVES和DrugOOD Assay外的所有数据集上也有性能提升,但不如Gemini 1.5 Pro稳定。
-
Gemini 1.5 Pro在多数数据集上比GPT-4o有更高的ICL数据效率。
-
在最优演示样本集规模下,两个模型相比zero-shot平均提升17%。
3.3.2 实验二、批量查询对性能的影响

目的: 研究在many-shot和zero-shot设置下,批量查询对Gemini 1.5 Pro性能的影响
涉及图表: 图3
实验细节概述:固定最优演示样本数,改变每个请求中包含的查询数量,比较many-shot ICL性能。同时在zero-shot下进行类似实验。
结果:
-
在合适的批大小下,many-shot ICL的批量查询相比单个查询没有性能下降,有时还有提升。
-
在zero-shot下,仅包含一个查询是次优的。在一些数据集上,最大批量的zero-shot性能大幅提升。
3.3.3 实验三、零样本下批量查询导致性能提升的原因探究

目的: 探究在zero-shot设置下批量查询导致性能提升的潜在原因
涉及图表: 图4
实验细节概述:设计消融实验,研究领域校准、类别校准和自生成演示三个因素对性能提升的贡献。
结果:
-
在TerraIncognita上,领域校准有3%的性能提升,而在UCMerced上会导致2.6%的性能下降。
-
类别校准使TerraIncognita提升6.5%,UCMerced提升4.5%,表明即使没有标签,类别平衡的图像也有帮助。
-
使用模型预测的标签进一步提升了性能,与直接批量查询的性能相近,说明这三个因素可以解释大部分性能提升。
3.3.4 实验四、推理延迟和成本分析
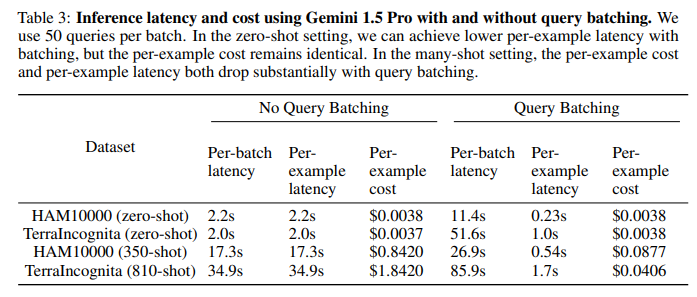
目的: 分析many-shot ICL的推理延迟和成本,以及批量查询的影响
涉及图表: 表3
实验细节概述:在HAM10000和TerraIncognita上,比较有无批量查询时的推理延迟和成本。批大小为50。
结果:
-
在zero-shot下,批量查询可以大幅降低单样本延迟,但单样本成本几乎不变。
-
在many-shot下,批量查询可以显著降低单样本延迟和成本。在HAM10000上,延迟降低35倍,成本降低10倍;在TerraIncognita上,延迟降低20倍,成本降低45倍。
4 总结后记
本论文针对多模态大语言模型(LMMs)的上下文学习问题,提出了一种"多样本上下文学习"(many-shot ICL)的方法。通过大幅增加输入给模型的演示样本数量(从几个到数千个),在多个涵盖不同领域和任务的数据集上取得了显著的性能提升。此外,通过对查询进行批处理,在保持性能的同时大大降低了每次查询的延迟和成本。实验结果表明,采用many-shot ICL可以显著提高LMMs在新领域和任务上的适应能力,为实现LMMs的快速定制化应用提供了新的思路。
疑惑和想法:
-
除了图像分类任务,many-shot ICL在其他多模态任务(如视觉问答、图像字幕等)上的效果如何?不同任务的最优演示样本数量是否存在差异?
-
在进行many-shot ICL时,演示样本的选择和排序方式是否会影响性能?是否可以设计一些策略来优化演示样本的构建?
-
Many-shot ICL的数据效率与传统的微调方法相比如何?是否可以将二者结合起来进一步提升性能和效率?
可借鉴的方法点:
-
Many-shot ICL的思想可以推广到其他需要快速适应新领域和任务的场景,如单模态的语言模型、强化学习等。
-
批处理查询的方法可以应用于其他需要大量调用LMMs的应用中,以提高效率和降低成本。
-
通过精心设计的上下文学习方式来提升模型性能,避免从头训练的思路值得借鉴,可以加速LMMs在实际应用中的部署。












![[读论文]精读Self-Attentive Sequential Recommendation](https://img-blog.csdnimg.cn/direct/1b6555189a434961b6e7f35f64d6c843.png)
