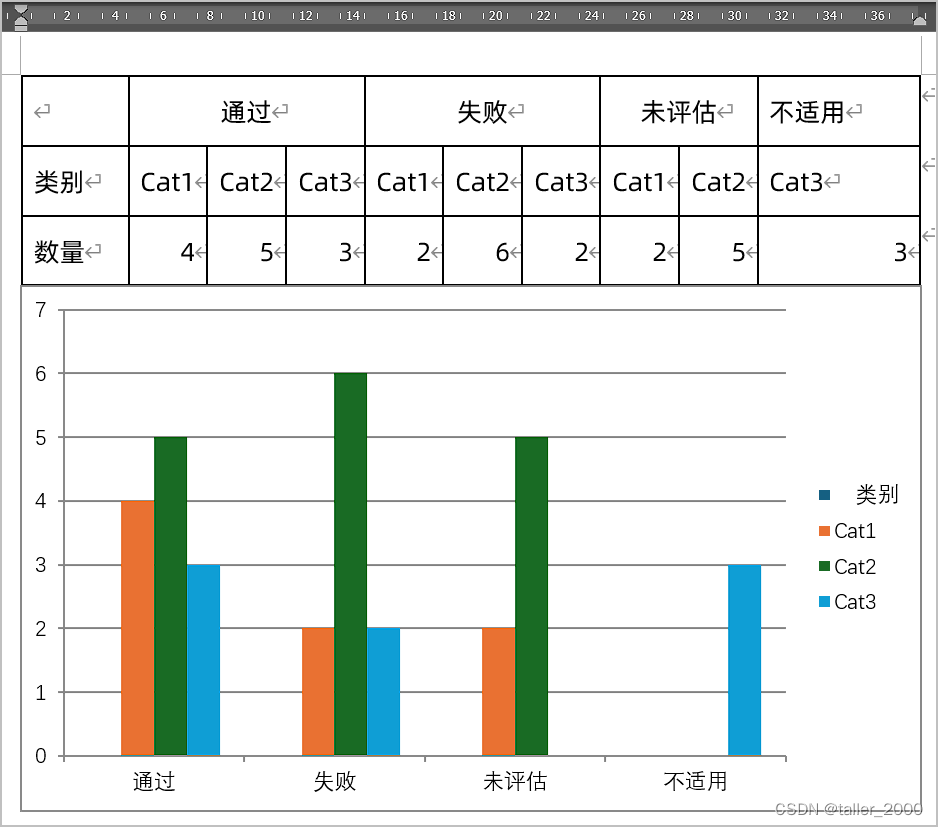
目的:整个大矩阵从 [Nx, Ny, Nz] 转到 [Nz, Nx, Ny]
每个进程的输入:大矩阵的 [Nx / total_proc_num, Ny, Nz] 的部分
每个进程的输出:大矩阵的 [Nz / total_proc_num, Nx, Ny] 的部分
一开始我大概有一个想法,假设两个进程的话,就把整个大矩阵分成 4 * 4 的块,进行分配,但是我不知道怎么分,就算是把转置之前的数据分布和转置之后的数据分布写出来了,也似乎找不到规律。
我做的图
xyz

zxy

后面通过 chatgpt 做出来了
#include <algorithm>
#include <iostream>
#include <mpi.h>
#include <vector>
void transpose_3d_block(int* local_A, int* local_A_T, int local_nx, int Ny, int Nz)
{
for (int i = 0; i < local_nx; ++i)
{
for (int j = 0; j < Ny; ++j)
{
for (int k = 0; k < Nz; ++k)
{
local_A_T[k * local_nx * Ny + i * Ny + j] = local_A[i * Ny * Nz + j * Nz + k];
}
}
}
}
int main(int argc, char** argv)
{
MPI_Init(&argc, &argv);
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
// 矩阵维度
const int Nx = 4, Ny = 6, Nz = 8;
const int local_nx = Nx / size;
const int new_local_nx = Nz / size;
// 创建局部数据块
std::vector<int> local_A(local_nx * Ny * Nz);
std::vector<int> local_A_T(new_local_nx * Nx * Ny);
// 初始化矩阵,仅在主进程上进行
if (rank == 0)
{
std::vector<int> A(Nx * Ny * Nz);
for (int i = 0; i < Nx * Ny * Nz; ++i)
{
A[i] = i;
}
// 分割矩阵到各个进程
for (int i = 0; i < size; ++i)
{
if (i == 0)
{
std::copy(A.begin(), A.begin() + local_nx * Ny * Nz, local_A.begin());
}
else
{
MPI_Send(A.data() + i * local_nx * Ny * Nz, local_nx * Ny * Nz, MPI_INT, i, 0, MPI_COMM_WORLD);
}
}
}
else
{
MPI_Recv(local_A.data(), local_nx * Ny * Nz, MPI_INT, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
}
// 局部转置 (local_nx, Ny, Nz) -> (Nz, local_nx, Ny)
transpose_3d_block(local_A.data(), local_A_T.data(), local_nx, Ny, Nz);
// 准备交换数据
std::vector<int> send_data(local_A_T);
std::vector<int> recv_data(send_data.size());
// 交换数据
MPI_Alltoall(send_data.data(),
new_local_nx * local_nx * Ny,
MPI_INT,
recv_data.data(),
new_local_nx * local_nx * Ny,
MPI_INT,
MPI_COMM_WORLD);
// 重组数据到local_result
std::vector<int> local_result(new_local_nx * Nx * Ny);
for (int i = 0; i < size; ++i)
{
for (int j = 0; j < new_local_nx; ++j)
{
std::copy(recv_data.begin() + (i * new_local_nx + j) * local_nx * Ny,
recv_data.begin() + (i * new_local_nx + j + 1) * local_nx * Ny,
local_result.begin() + j * Nx * Ny + i * local_nx * Ny);
}
}
// 输出转置结果,仅在主进程上进行检查
if (rank == 0)
{
std::vector<int> A_T(Nz * Nx * Ny);
std::copy(local_result.begin(), local_result.begin() + new_local_nx * Nx * Ny, A_T.begin());
for (int i = 1; i < size; ++i)
{
MPI_Recv(A_T.data() + i * new_local_nx * Nx * Ny,
new_local_nx * Nx * Ny,
MPI_INT,
i,
0,
MPI_COMM_WORLD,
MPI_STATUS_IGNORE);
}
std::cout << "Transposed matrix A_T:" << std::endl;
for (int i = 0; i < Nz; ++i)
{
for (int j = 0; j < Nx; ++j)
{
for (int k = 0; k < Ny; ++k)
{
std::cout << A_T[i * Nx * Ny + j * Ny + k] << " ";
}
std::cout << std::endl;
}
std::cout << std::endl;
}
}
else
{
MPI_Send(local_result.data(), new_local_nx * Nx * Ny, MPI_INT, 0, 0, MPI_COMM_WORLD);
}
MPI_Finalize();
return 0;
}
输出:
Transposed matrix A_T:
0 8 16 24 32 40
48 56 64 72 80 88
96 104 112 120 128 136
144 152 160 168 176 184
1 9 17 25 33 41
49 57 65 73 81 89
97 105 113 121 129 137
145 153 161 169 177 185
2 10 18 26 34 42
50 58 66 74 82 90
98 106 114 122 130 138
146 154 162 170 178 186
3 11 19 27 35 43
51 59 67 75 83 91
99 107 115 123 131 139
147 155 163 171 179 187
4 12 20 28 36 44
52 60 68 76 84 92
100 108 116 124 132 140
148 156 164 172 180 188
5 13 21 29 37 45
53 61 69 77 85 93
101 109 117 125 133 141
149 157 165 173 181 189
6 14 22 30 38 46
54 62 70 78 86 94
102 110 118 126 134 142
150 158 166 174 182 190
7 15 23 31 39 47
55 63 71 79 87 95
103 111 119 127 135 143
151 159 167 175 183 191