文章目录
- 1. 单线程
- 2. 线程池ThreadPoolExecutor
1. 单线程
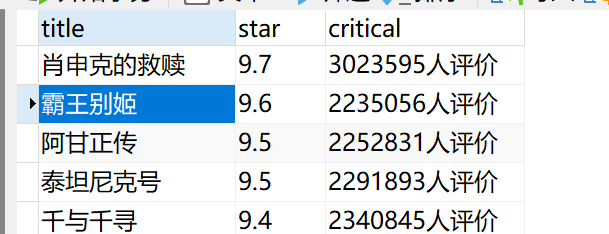
现在有1154张图片需要顺时针旋转后保存到本地,一般使用循环1154次处理,具体代码如下所示,img_paths中存储1154个图片路径,该代码段耗时约用97ms。
t1=time.time()
for imgpath in img_paths:
img=cv2.imread(imgpath,0)
img=cv2.rotate(img,cv2.ROTATE_90_CLOCKWISE)
info=imgpath.split("/")
parent,filename=info[-2],info[-1]
filename=parent+"_"+filename.split(".")[0].zfill(5)+".jpg"
dst_save_path=os.path.dirname(imgpath).replace(f"{sub}","result/")+filename
cv2.imwrite(dst_save_path,img)
t2=time.time()
print(t2-t1)
可以看到CPU运行状态,只有一个在运行:

2. 线程池ThreadPoolExecutor
对于这种没有数据交换的任务,可以使用多线程。python中有很多多线程、多进程的库,这里试试线程池ThreadPoolExecutor。
这个库核心有两个:
- with ThreadPoolExecutor(max_workers=batch_size) as executor:创建一个上下文管理的执行器,并制定线程池中线程个数;
- executor.map(process_image, batch):process_image是执行的函数,接受一个路径,batch是储存多个路径的列表,大小等于小于执行器的max_workers。这个方法会为batch中的每个图像路径启动一个线程(最多同时运行max_workers数量的线程),并在每个线程中调用之前定义的process_image函数处理对应的图像。map方法会等待所有线程完成后再继续下一轮循环,确保每个批次内的图像处理是并行且同步完成的。
下方的代码耗时约37ms
import cv2
import os
from concurrent.futures import ThreadPoolExecutor
def process_image(imgpath):
# 读取并旋转图像
img = cv2.imread(imgpath, 0)
img = cv2.rotate(img, cv2.ROTATE_90_CLOCKWISE)
# 分割路径以获取父目录和文件名
info = imgpath.split("/")
parent, filename = info[-2], info[-1]
# 重命名文件
base_name = filename.split(".")[0]
new_filename = f"{parent}_{base_name.zfill(5)}.jpg"
# 构建保存路径
dst_save_path = os.path.dirname(imgpath).replace("sub", "result/") + new_filename
# 保存处理后的图像
cv2.imwrite(dst_save_path, img)
def batch_process_images(img_paths, batch_size=15):
with ThreadPoolExecutor(max_workers=batch_size) as executor:
for i in range(0, len(img_paths), batch_size):
# 每次处理batch_size个图像路径
batch = img_paths[i:i+batch_size]
executor.map(process_image, batch)
# 假设img_paths是包含所有图像路径的列表
img_paths = [...] # 这里填充实际的图像路径列表
batch_process_images(img_paths)
可以看到,15个cpu都被调用起来了



![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-23.3,4,5,6 讲 I2C驱动-读取AP3216C传感器](https://img-blog.csdnimg.cn/direct/1b32965dd5fe484a9f9f9ad63e4d088e.png)