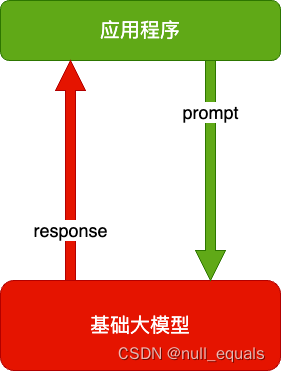
Prompt
就像和一个人对话,你说一句,ta 回一句,你再说一句,ta 再回一句……
-
Prompt 就是你发给大模型的指令,比如「讲个笑话」、「用 Python 编个贪吃蛇游戏」、「给男/女朋友写封情书」等
-
貌似简单,但意义非凡
-
「Prompt」 是 AGI 时代的「编程语言」
-
「Prompt 工程」是 AGI 时代的「软件工程」
-
「提示工程师」是 AGI 时代的「程序员」
-
-
学会提示工程,就像学用鼠标、键盘一样,是 AGI 时代的基本技能
-
提示工程「门槛低,天花板高」,所以有人戏称 prompt 为「咒语」
Prompt门槛低到什么程度呢?任何一个人,给他看一眼他就会了,天花板高到什么程度呢?想要一个语义非常精确的,所有大模型都能理解的Prompt太难了,经常会出现,少说一句话大模型返回的数据就不能被我们的代码解析。
下面是一个简单的例子来带我们了解Prompt:
推荐流量包的智能客服
某运营商的流量包产品:
| 名称 | 流量(G/月) | 价格(元/月) | 适用人群 |
| 经济套餐 | 10 | 50 | 无限制 |
| 劲爽套餐 | 100 | 180 | 无限制 |
| 无限套餐 | 1000 | 300 | 无限制 |
| 校园套餐 | 200 | 150 | 在校生 |
需求:智能客服根据用户的咨询,推荐最适合的流量包。
对话系统的基本模块和思路
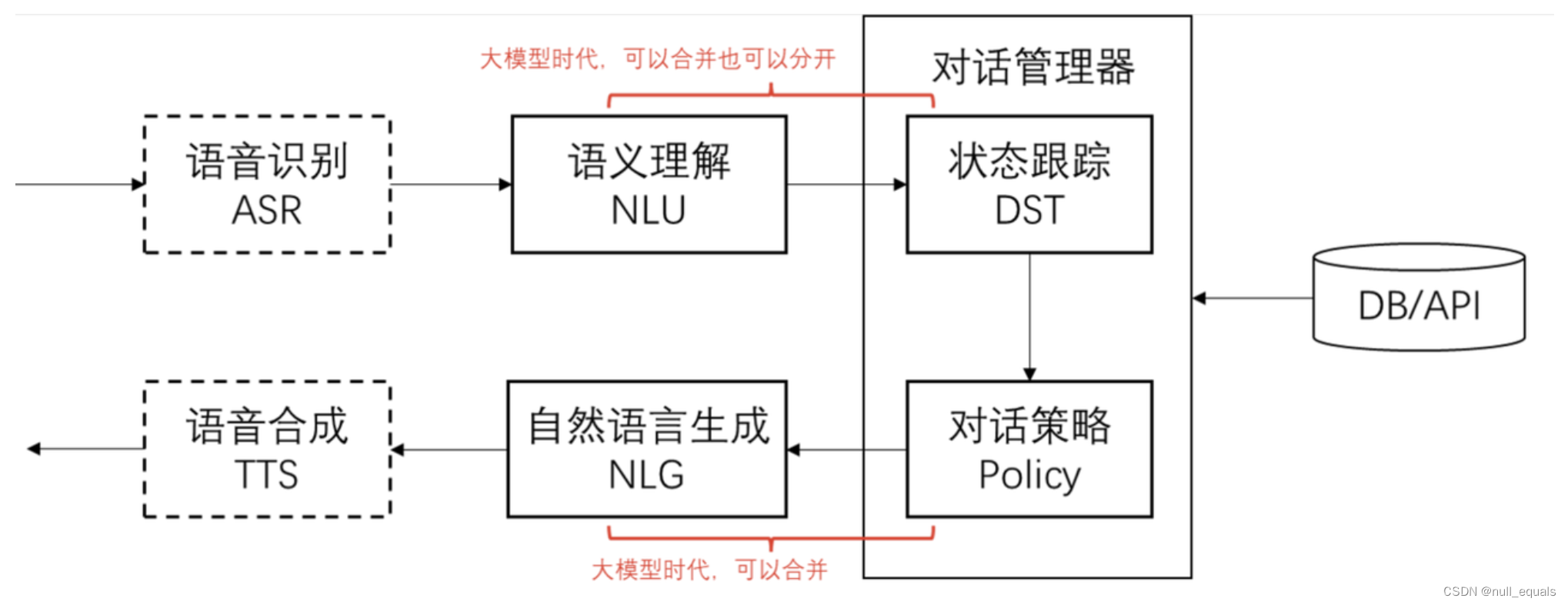
对话流程举例:
| 对话轮次 | 用户提问 | NLU | DST | Policy | NLG |
| 1 | 流量大的套餐有什么 | sort_descend=data | sort_descend=data | inform(name=无限套餐) | 我们现有无限套餐,流量不限量,每月 300 元 |
| 2 | 月费 200 以下的有什么 | price<200 | sort_descend=data price<200 | inform(name=劲爽套餐) | 推荐劲爽套餐,流量 100G,月费 180 元 |
| 3 | 算了,要最便宜的 | sort_ascend=price | sort_ascend=price | inform(name=经济套餐) | 最便宜的是经济套餐,每月 50 元,10G 流量 |
| 4 | 有什么优惠吗 | request(discount) | request(discount) | confirm(status=优惠大) | 您是在找优惠吗 |
解释:
NLU:代表自然语言理解(Natural Language Understanding),在人机对话系统(例如聊天机器人、语音助手)中,NLU 是捕获用户意图和提取相关信息(例如实体、上下文)的关键组件。
DST:对话状态追踪 (Dialogue State Tracking),在对话系统(尤其是计算机辅助的对话)中,它是一个跟踪用户意向和对话上下文(如用户提到的关键信息)的机制。对话状态追踪帮助系统保持对用户意图的连贯理解,即便在多轮对话中。
Policy:对话管理策略(Dialogue Management Policy),它是决定系统如何响应用户输入的一套规则或策略。对话管理策略的目的是根据当前对话的状态以及用户的意图和提供的信息来决定下一步该如何有效地进行对话。 NLG:代表自然语言生成(Natural Language Generation),在对话系统中,NLG的角色是根据系统的内部表示或意图来生成自然、流畅且准确的语句或语音输出,与用户进行有效沟通。
核心思路:
-
把输入的自然语言对话,转成结构化的表示
-
从结构化的表示,生成策略
-
把策略转成自然语言输出
初始化OpenAI Client
import json
import os
from openai import OpenAI
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
# OPENAI_BASE_URL="https://api.fe8.cn/v1"
client = OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("OPENAI_BASE_URL")
)
def get_completion(prompt, model="gpt-3.5-turbo"):
messages = [{"role": "user", "content": prompt}]
response1 = client.chat.completions.create(
model=model,
# response_format={ "type": "json_object" },
messages=messages,
temperature=0,
)
return response1.choices[0].message.content注册openai请求密钥 DevAGI
简单的prompt
# 任务描述
instruction = """
你的任务是识别用户对手机流量套餐产品的选择条件。
每种流量套餐产品包含三个属性:名称,月费价格,月流量。
根据用户输入,识别用户在上述三种属性上的倾向。
"""
# 用户输入
input_text = """
办个10G的套餐。
"""
# prompt 模版。instruction 和 input_text 会被替换为上面的内容
prompt = f"""
{instruction}
用户输入:
{input_text}
"""
response = get_completion(prompt)
print(response)要求以json格式输出
# 用户输入
input_text = """
有没有流量大,又便宜的套餐
"""
# 以json格式输出
output_text = """
以 JSON 格式输出
"""
prompt = f"""
{instruction}
{output_text}
用户输入:
{input_text}
"""
# 调用大模型
response = get_completion(prompt)
print(response)大模型是懂 JSON 的,但需要对 JSON 结构做严格定义。
把输出格式定义的更精细
# 任务描述增加了字段的英文标识符
instruction = """
你的任务是识别用户对手机流量套餐产品的选择条件。
每种流量套餐产品包含三个属性:名称(name),月费价格(price),月流量(data)。
根据用户输入,识别用户在上述三种属性上的倾向。
请说出你的思考逻辑
"""
# 输出格式增加了各种定义、约束
output_format = """
以JSON格式输出。
1. name字段的取值为string类型,取值必须为以下之一:经济套餐、劲爽套餐、无限套餐、校园套餐 或 null;
2. price字段的取值为一个结构体 或 null,包含两个字段:
(1) operator, string类型,取值范围:'<='(小于等于), '>=' (大于等于), '=='(等于)
(2) value, int类型
3. data字段的取值为取值为一个结构体 或 null,包含两个字段:
(1) operator, string类型,取值范围:'<='(小于等于), '>=' (大于等于), '=='(等于)
(2) value, int类型或string类型,string类型只能是'无上限'
4. 用户的意图可以包含按price或data排序,以sort字段标识,取值为一个结构体:
(1) 结构体中以"ordering"="descend"表示按降序排序,以"value"字段存储待排序的字段
(2) 结构体中以"ordering"="ascend"表示按升序排序,以"value"字段存储待排序的字段
只输出中只包含用户提及的字段,不要猜测任何用户未直接提及的字段,不输出值为null的字段。
"""
#input_text = "办个100G以上的套餐"
#input_text = "我要无限量套餐"
#input_text = "流量比较大的有哪些套餐"
input_text = "便宜的套餐"
prompt = f"""
{instruction}
{output_format}
用户输入:
{input_text}
"""
response = get_completion(prompt)
print(response)添加例子
可以让输出更稳定。
# 添加例子
examples = """
便宜的套餐:{"sort":{"ordering"="ascend","value"="price"}}
有没有不限流量的:{"data":{"operator":"==","value":"无上限"}}
流量大的:{"sort":{"ordering"="descend","value"="data"}}
100G以上流量的套餐最便宜的是哪个:{"sort":{"ordering"="ascend","value"="price"},"data":{"operator":">=","value":100}}
月费不超过200的:{"price":{"operator":"<=","value":200}}
就要月费180那个套餐:{"price":{"operator":"==","value":180}}
经济套餐:{"name":"经济套餐"}
"""
#input_text = "有没有便宜的套餐"
# input_text = "有没有土豪套餐"
# input_text = "办个200G的套餐"
# input_text = "有没有流量大的套餐"
input_text = "200元以下,流量大的套餐有啥"
# input_text = "你说那个10G的套餐,叫啥名字"
# 有了例子
prompt = f"""
{instruction}
{output_format}
例如:
{examples}
用户输入:
{input_text}
"""
response = get_completion(prompt)
print(response)划重点:「给例子」很常用,效果特别好
支持多轮对话 DST
在 Prompt 中加入上下文
# 多轮对话的例子
instruction = """
你的任务是识别用户对手机流量套餐产品的选择条件。
每种流量套餐产品包含三个属性:名称(name),月费价格(price),月流量(data)。
根据对话上下文,识别用户在上述属性上的倾向。识别结果要包含整个对话的信息。
"""
# 输出描述
output_format = """
以JSON格式输出。
1. name字段的取值为string类型,取值必须为以下之一:经济套餐、畅游套餐、无限套餐、校园套餐 或 null;
2. price字段的取值为一个结构体 或 null,包含两个字段:
(1) operator, string类型,取值范围:'<='(小于等于), '>=' (大于等于), '=='(等于)
(2) value, int类型
3. data字段的取值为取值为一个结构体 或 null,包含两个字段:
(1) operator, string类型,取值范围:'<='(小于等于), '>=' (大于等于), '=='(等于)
(2) value, int类型或string类型,string类型只能是'无上限'
4. 用户的意图可以包含按price或data排序,以sort字段标识,取值为一个结构体:
(1) 结构体中以"ordering"="descend"表示按降序排序,以"value"字段存储待排序的字段
(2) 结构体中以"ordering"="ascend"表示按升序排序,以"value"字段存储待排序的字段
只输出中只包含用户提及的字段,不要猜测任何用户未直接提及的字段。不要输出值为null的字段。
"""
# 多轮对话的例子
examples = """
客服:有什么可以帮您
用户:100G套餐有什么
{"data":{"operator":">=","value":100}}
客服:有什么可以帮您
用户:100G套餐有什么
客服:我们现在有无限套餐,不限流量,月费300元
用户:太贵了,有200元以内的不
{"data":{"operator":">=","value":100},"price":{"operator":"<=","value":200}}
客服:有什么可以帮您
用户:便宜的套餐有什么
客服:我们现在有经济套餐,每月50元,10G流量
用户:100G以上的有什么
{"data":{"operator":">=","value":100},"sort":{"ordering"="ascend","value"="price"}}
客服:有什么可以帮您
用户:100G以上的套餐有什么
客服:我们现在有畅游套餐,流量100G,月费180元
用户:流量最多的呢
{"sort":{"ordering"="descend","value"="data"},"data":{"operator":">=","value":100}}
"""
input_text = "流量最多的呢"
#input_text = "无限量哪个多少钱"
#input_text = "流量最大的多少钱"
# 多轮对话上下文
context = f"""
客服:有什么可以帮您
用户:有什么100G以上的套餐推荐
客服:我们有畅游套餐和无限套餐,您有什么价格倾向吗
用户:{input_text}
"""
prompt = f"""
{instruction}
{output_format}
{examples}
{context}
"""
response = get_completion(prompt)
print(response)-
Prompt 的典型构成
-
角色:给 AI 定义一个最匹配任务的角色,比如:「你是一位软件工程师」「你是一位小学老师」
-
指示:对任务进行描述
-
上下文:给出与任务相关的其它背景信息(尤其在多轮交互中)
-
例子:必要时给出举例,学术中称为 one-shot learning, few-shot learning 或 in-context learning;实践证明其对输出正确性有很大帮助
-
输入:任务的输入信息;在提示词中明确的标识出输入
-
输出:输出的格式描述,以便后继模块自动解析模型的输出结果,比如(JSON、XML)
-
实现对话策略和 NLG
把刚才的能力串起来,构建一个「简单」的客服机器人
import json
import copy
from openai import OpenAI
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
client = OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
base_url=os.getenv("OPENAI_BASE_URL")
)
instruction = """
你的任务是识别用户对手机流量套餐产品的选择条件。
每种流量套餐产品包含三个属性:名称(name),月费价格(price),月流量(data)。
根据用户输入,识别用户在上述三种属性上的倾向。
"""
# 输出格式
output_format = """
以JSON格式输出。
1. name字段的取值为string类型,取值必须为以下之一:经济套餐、畅游套餐、无限套餐、校园套餐 或 null;
2. price字段的取值为一个结构体 或 null,包含两个字段:
(1) operator, string类型,取值范围:'<='(小于等于), '>=' (大于等于), '=='(等于)
(2) value, int类型
3. data字段的取值为取值为一个结构体 或 null,包含两个字段:
(1) operator, string类型,取值范围:'<='(小于等于), '>=' (大于等于), '=='(等于)
(2) value, int类型或string类型,string类型只能是'无上限'
4. 用户的意图可以包含按price或data排序,以sort字段标识,取值为一个结构体:
(1) 结构体中以"ordering"="descend"表示按降序排序,以"value"字段存储待排序的字段
(2) 结构体中以"ordering"="ascend"表示按升序排序,以"value"字段存储待排序的字段
只输出中只包含用户提及的字段,不要猜测任何用户未直接提及的字段。
不要携带markdown的标签
DO NOT OUTPUT NULL-VALUED FIELD! 确保输出能被json.loads加载。
"""
examples = """
便宜的套餐:{"sort":{"ordering"="ascend","value"="price"}}
有没有不限流量的:{"data":{"operator":"==","value":"无上限"}}
流量大的:{"sort":{"ordering"="descend","value"="data"}}
100G以上流量的套餐最便宜的是哪个:{"sort":{"ordering"="ascend","value"="price"},"data":{"operator":">=","value":100}}
月费不超过200的:{"price":{"operator":"<=","value":200}}
就要月费180那个套餐:{"price":{"operator":"==","value":180}}
经济套餐:{"name":"经济套餐"}
"""
class NLU:
def __init__(self):
self.prompt_template = f"{instruction}\n\n{output_format}\n\n{examples}\n\n用户输入:\n__INPUT__"
def _get_completion(self, prompt, model="gpt-3.5-turbo"):
messages = [{"role": "user", "content": prompt}]
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0, # 模型输出的随机性,0 表示随机性最小
)
print(response)
semantics = json.loads(response.choices[0].message.content)
return {k: v for k, v in semantics.items() if v}
def parse(self, user_input):
prompt = self.prompt_template.replace("__INPUT__", user_input)
return self._get_completion(prompt)
class DST:
def __init__(self):
pass
def update(self, state, nlu_semantics):
if "name" in nlu_semantics:
state.clear()
if "sort" in nlu_semantics:
slot = nlu_semantics["sort"]["value"]
if slot in state and state[slot]["operator"] == "==":
del state[slot]
for k, v in nlu_semantics.items():
state[k] = v
return state
class MockedDB:
def __init__(self):
self.data = [
{"name": "经济套餐", "price": 50, "data": 10, "requirement": None},
{"name": "畅游套餐", "price": 180, "data": 100, "requirement": None},
{"name": "无限套餐", "price": 300, "data": 1000, "requirement": None},
{"name": "校园套餐", "price": 150, "data": 200, "requirement": "在校生"},
]
def retrieve(self, **kwargs):
records = []
for r in self.data:
select = True
if r["requirement"]:
if "status" not in kwargs or kwargs["status"] != r["requirement"]:
continue
for k, v in kwargs.items():
if k == "sort":
continue
if k == "data" and v["value"] == "无上限":
if r[k] != 1000:
select = False
break
if "operator" in v:
if not eval(str(r[k])+v["operator"]+str(v["value"])):
select = False
break
elif str(r[k]) != str(v):
select = False
break
if select:
records.append(r)
if len(records) <= 1:
return records
key = "price"
reverse = False
if "sort" in kwargs:
key = kwargs["sort"]["value"]
reverse = kwargs["sort"]["ordering"] == "descend"
return sorted(records, key=lambda x: x[key], reverse=reverse)
class DialogManager:
def __init__(self, prompt_templates):
self.state = {}
self.session = [
{
"role": "system",
"content": "你是一个手机流量套餐的客服代表,你叫小瓜。可以帮助用户选择最合适的流量套餐产品。"
}
]
self.nlu = NLU()
self.dst = DST()
self.db = MockedDB()
self.prompt_templates = prompt_templates
def _wrap(self, user_input, records):
if records:
prompt = self.prompt_templates["recommend"].replace(
"__INPUT__", user_input)
r = records[0]
for k, v in r.items():
prompt = prompt.replace(f"__{k.upper()}__", str(v))
else:
prompt = self.prompt_templates["not_found"].replace(
"__INPUT__", user_input)
for k, v in self.state.items():
if "operator" in v:
prompt = prompt.replace(
f"__{k.upper()}__", v["operator"]+str(v["value"]))
else:
prompt = prompt.replace(f"__{k.upper()}__", str(v))
return prompt
def _call_chatgpt(self, prompt, model="gpt-3.5-turbo"):
session = copy.deepcopy(self.session)
session.append({"role": "user", "content": prompt})
response = client.chat.completions.create(
model=model,
messages=session,
temperature=0,
)
return response.choices[0].message.content
def run(self, user_input):
# 调用NLU获得语义解析
semantics = self.nlu.parse(user_input)
print("===semantics===")
print(semantics)
# 调用DST更新多轮状态
self.state = self.dst.update(self.state, semantics)
print("===state===")
print(self.state)
# 根据状态检索DB,获得满足条件的候选
records = self.db.retrieve(**self.state)
# 拼装prompt调用chatgpt
prompt_for_chatgpt = self._wrap(user_input, records)
print("===gpt-prompt===")
print(prompt_for_chatgpt)
# 调用chatgpt获得回复
response = self._call_chatgpt(prompt_for_chatgpt)
# 将当前用户输入和系统回复维护入chatgpt的session
self.session.append({"role": "user", "content": user_input})
self.session.append({"role": "assistant", "content": response})
return response
prompt_templates = {
"recommend": "用户说:__INPUT__ \n\n向用户介绍如下产品:__NAME__,月费__PRICE__元,每月流量__DATA__G。",
"not_found": "用户说:__INPUT__ \n\n没有找到满足__PRICE__元价位__DATA__G流量的产品,询问用户是否有其他选择倾向。"
}
dm = DialogManager(prompt_templates)
response = dm.run("200元以内的套餐有什么")
response = dm.run("流量大的")
print("===response===")
print(response)-
纯prompt实现一个完整的客服系统例子
def print_json(data):
"""
打印参数。如果参数是有结构的(如字典或列表),则以格式化的 JSON 形式打印;
否则,直接打印该值。
"""
if hasattr(data, 'model_dump_json'):
data = json.loads(data.model_dump_json())
if (isinstance(data, (list, dict))):
print(json.dumps(
data,
indent=4,
ensure_ascii=False
))
else:
print(data)
# 定义消息历史。先加入 system 消息,里面放入对话内容以外的 prompt
messages = [
{
"role": "system",
"content": """
你是一个手机流量套餐的客服代表,你叫小瓜。可以帮助用户选择最合适的流量套餐产品。可以选择的套餐包括:
经济套餐,月费50元,10G流量;
畅游套餐,月费180元,100G流量;
无限套餐,月费300元,1000G流量;
校园套餐,月费150元,200G流量,仅限在校生。
"""
}
]
def get_completion(prompt, model="gpt-3.5-turbo"):
# 把用户输入加入消息历史
messages.append({"role": "user", "content": prompt})
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0,
)
msg = response.choices[0].message.content
# 把模型生成的回复加入消息历史。很重要,否则下次调用模型时,模型不知道上下文
messages.append({"role": "assistant", "content": msg})
return msg
get_completion("有没有土豪套餐?")
get_completion("多少钱?")
get_completion("给我办一个")
print_json(messages)好了,到这里,一个简单的通过Prompt+OpenAI实现的人工智能客服就完成了。
这里面用的模型是gpt-3.5-turbo,当然也可以换成gpt-4,效果可能会更好。看到这里大家是不是觉得用Prompt+OpenAI实现一个简单的小工具非常简单呢?

![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-23.3,4,5,6 讲 I2C驱动-读取AP3216C传感器](https://img-blog.csdnimg.cn/direct/1b32965dd5fe484a9f9f9ad63e4d088e.png)