作者:Madhusudhan Konda
如何选择最好的 k 和 num_candidates?
向量搜索在当前的生成式人工智能/机器学习领域中已经成为一个改变游戏规则的技术。它允许我们基于语义含义而不仅仅是精确的关键词匹配来找到相似的项目。
Elasticsearch的 k-近邻(kNN)算法是分类和回归任务中的一种基础机器学习技术。随着向量搜索功能的引入,它在 Elasticsearch 生态系统中占据了重要地位。在 Elasticsearch 8.5 中引入的基于 kNN 的向量搜索允许用户在密集向量字段上执行高速相似性搜索。
用户可以利用 kNN 算法,通过使用诸如欧几里得距离或余弦相似度等指定的距离度量来查找索引中与给定向量 “最接近” 的文档。这一特性标志着一个重要的进步,因为它在需要语义搜索、推荐以及其他如异常检测的应用中特别有用。有关更多向量相关性的内容,可以参阅文章 “Elasticsearch:向量相似度技术和评分”。
在 Elasticsearch 中引入密集向量字段和 k-近邻(kNN)搜索功能为实现超越传统文本搜索的复杂搜索能力开辟了新天地。
本文深入探讨了选择 k 值和 num_candidates 参数的最佳策略,并结合使用 Kibana 的实际例子进行了说明。
kNN 搜索查询
Elasticsearch 为最近邻提供了 kNN 搜索选项 - 如下所示:
POST movies/_search
{
"knn": {
"field": "title_vector.predicted_value",
"query_vector_builder": {
"text_embedding": {
"model_id": ".multilingual-e5-small",
"model_text": "Good Ugly"
}
},
"k": 3,
"num_candidates": 100
},
"_source": [
"id",
"title"
]
}如片段所示,knn 查询通过向量搜索获取与查询(电影标题为 “Good Ugly”)相关的结果。搜索在一个多维空间中进行,生成与给定查询向量最接近的向量。
从上述查询中,可以注意到两个属性:num_candidates,即初始候选池的数量,以及 k,最近邻的数量。
kNN 的关键参数 - k 和 num_candidates
为了有效利用 kNN 功能,需要对两个关键参数有深入的理解:k,即要检索的全局最近邻的数量;num_candidates,即在搜索过程中每个分片考虑的候选邻居的数量。
选择 k 和 num_candidates 的最佳值需要在精度、召回率和性能之间进行平衡。这些参数在高效处理机器学习应用中常见的高维向量空间中起着至关重要的作用。
k 的最佳值主要取决于具体的用例。例如,如果你在构建推荐系统,较小的 k(例如 10-20)可能就足以提供相关的推荐。而在需要聚类或异常检测能力的用例中,可能需要更大的 k。
需要注意的是,较高的 k 值会显著增加计算和内存使用,尤其是在处理大数据集时。因此,测试不同的 k 值以在结果相关性和系统资源使用之间找到平衡是很重要的。
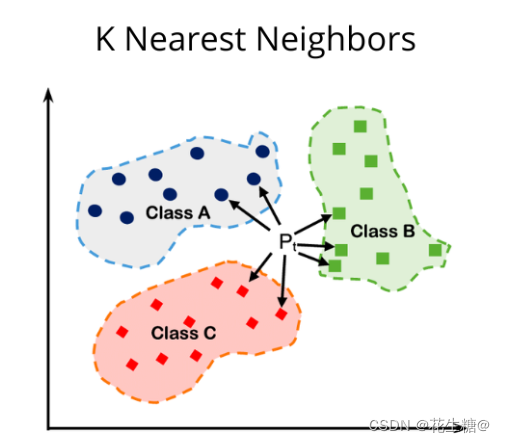
k:揭示最接近的邻居
我们可以根据需要选择 k 值。有时,设置较低的 k 值可以较准确地得到想要的结果,但少数结果可能不会出现在最终输出中。然而,设置较高的 k 值可能会扩大搜索结果的数量,但有时可能会收到多样化的结果。
想象一下,你在广阔的推荐图书库中寻找一本新书。k,也就是最近邻的数量,决定了你会看到多少本书。可以把它想象成你搜索结果的核心圈。让我们看看设置较低和较高的 k 值如何影响查询返回的书籍数量。
设置较低的 k 值
较低的 k 值设置优先考虑极高的精确度,这意味着我们将收到与查询向量最相似的几本书。这确保了与我们特定兴趣高度相关的结果。如果你在寻找一本具有非常具体主题或写作风格的书,这可能是理想的选择。
设置较高的 k 值
使用较大的 k 值,我们将获得更广泛的探索结果集。需要注意的是,结果可能不会与你的确切查询紧密匹配。然而,你会遇到更广泛的潜在有趣书籍。这种方法对于多样化你的阅读清单和发现意想不到的珍品可能非常有价值。
每当我们说较高或较低的 k 值时,实际的数值取决于多个因素,例如数据集的大小、可用的计算能力和其他因素。在某些情况下,k=10 可能是一个较大的值,但在其他情况下可能较小。因此,请注意这个参数所期望操作的环境。
num_candidates 属性:幕后揭秘
虽然 k 决定了你最终看到的书籍数量,但 num_candidates 在幕后起着关键作用。它本质上定义了每个分片的搜索空间 —— 从中识别出最相关的 k 个邻居的初始书籍池。当我们发出查询时,我们需要提示 Elasticsearch 在每个分片的前 “x” 个候选者中运行查询。
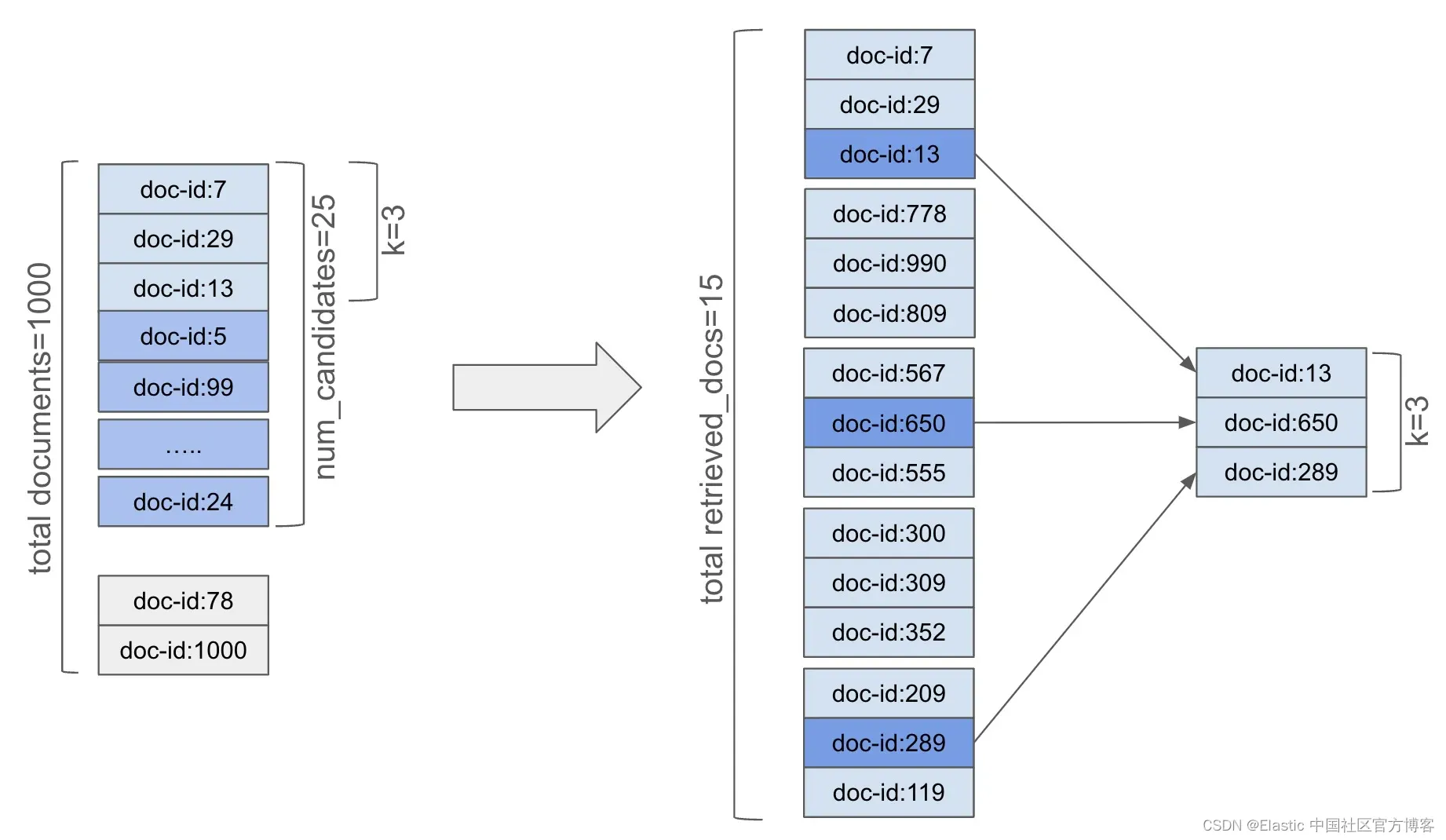
例如,假设我们的书籍索引包含 5000 本书,平均分布在五个主分片中(即每个分片约 1000 本书)。在执行搜索时,显然选择每个分片的所有1000 本书既不可行也不正确。相反,我们将从 1000 本书中选择最多 25 本书(即我们的 num_candidates)。这相当于 125 本书作为我们的总搜索空间(5个分片,每个分片 25 本书)。
我们会让 kNN 查询知道从每个分片选择 25 本书,这个数量就是 num_candidates 参数。当执行 kNN 搜索时,“协调” 节点将请求查询发送给所有相关分片。每个分片的 num_candidates 文档将构成搜索空间,并从该空间中获取前 k 个文档。假设 k 为 3,则每个分片的 25 个候选文档中的前 3 个文档将被选中并返回给协调节点。也就是说,协调节点将从所有相关节点接收总共 15 个文档。然后,这 15 个文档将被排名以获取全局前 3(k==3)个文档。
这个过程如图所示:
以下是 num_candidates 对你的搜索的含义:
设置较低的 num_candidates
这种方法可能会限制搜索空间,可能会遗漏一些在初始探索集中之外的相关书籍。可以将其想象为只调查了图书馆书架的一小部分。
设置较高的 num_candidates
较高的 num_candidates 值增加了在我们选择的 k 中找到真正最近邻的可能性。它扩展了搜索空间 —— 也就是说,考虑的候选数量更多 —— 因此会略微增加搜索时间。因此,较高的值通常会提高准确性(因为错过相关向量的机会减少了),但以性能为代价。
平衡精度和性能
k 和 num_candidates 的最佳值取决于一些因素和具体需求。如果我们优先考虑极高精度并希望获得一小组高度相关的结果,较低的 k 值和适中的 num_candidates 可能是理想的选择。相反,如果你的目标是探索和发现意想不到的书籍,那么较高的 k 值和较大的 num_candidates 可能更适合。
虽然没有硬性规定来定义 num_candidates 的 “较低” 或 “较高” 数值,但你需要根据你的数据集、计算能力和预期的精度来决定这个数值。
实验是关键
通过尝试不同的 k 和 num_candidates 组合并监控搜索结果和性能,你可以微调搜索以实现精度、探索和速度之间的完美平衡。 请记住,没有一刀切的解决方案 - 最佳方法取决于你独特的目标和数据特征。
使用 kNN 进行电影推荐
让我们考虑一个电影示例,创建一个手动 “简单” 框架,用于理解搜索电影时 k 和 num_candidates 属性的效果。
手动框架
让我们了解如何开发一个自制的框架,以调整 kNN 搜索中的 k 和 num_candidates 属性。
框架的机制如下:
- 创建一个电影索引,在映射中包含几个 dense_vector 字段,以保存我们的向量化数据。
- 创建一个嵌入管道,使每部电影的标题和简介字段都通过 multilingual-e5-small 模型进行嵌入,以存储向量。
- 执行索引操作,经过上述嵌入管道,相应字段将被向量化。
- 使用 kNN 功能创建一个搜索查询。
- 根据需要调整 k 和 num_candidates 选项。
让我们深入了解一下。
创建推理管道
我们需要通过 Kibana 索引数据 - 远非理想 - 但它对于手动框架理解来说是有用的。 然而,每部被索引的电影都必须对标题和概要字段进行向量化,以便能够对我们的数据进行语义搜索。 我们可以通过优雅地创建推理管道处理器并将其附加到我们的批量索引操作来做到这一点。
让我们创建一个推理管道:
# Creating an inference pipeline processor
# The title and synopsis fields gets vectorised and stored in respective fields
PUT _ingest/pipeline/movie_embedding_pipeline
{
"processors": [
{
"inference": {
"model_id": ".multilingual-e5-small",
"target_field": "title_vector",
"field_map": { "title": "text_field" }
}
},
{
"inference": {
"model_id": ".multilingual-e5-small",
"target_field": "synopsis_vector",
"field_map": { "synopsis": "text_field" }
}
}
]
}如上所示,推理管道 movie_embedding_pipeline 为 title 和 synopsis 字段创建向量字段文本嵌入。 它使用内置的 multilingual-e5-small 模型来创建文本嵌入。
创建索引映射
我们需要创建一个具有几个属性作为 dense_vector 字段的映射。 下面的代码片段完成了这项工作:
# Creating a movies index
# Note the vector fields
PUT movies
{
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"original": {
"type": "keyword"
}
}
},
"title_vector.predicted_value": {
"type": "dense_vector",
"dims": 384,
"index": true
},
"synopsis": {
"type": "text"
},
"synopsis_vector.predicted_value": {
"type": "dense_vector",
"dims": 384,
"index": true
},
"actors": {
"type": "text"
},
"director": {
"type": "text"
},
"rating": {
"type": "half_float"
},
"release_date": {
"type": "date",
"format": "dd-MM-yyyy"
},
"certificate": {
"type": "keyword"
},
"genre": {
"type": "text"
}
}
}
}执行上述命令后,我们将获得一个具有适当密集向量字段的新电影索引,包括保存各自向量的 title_vector.predicted_value 和 synopsis_vector.predicted_value 字段。
在版本 8.10 之前,索引映射参数默认设置为 false。 这在版本 8.11 中已更改,默认情况下该参数设置为 true,因此无需指定它。
下一步是摄取数据。
索引电影
我们可以使用 _bulk 操作来索引一组电影 - 我正在重用我为《Elasticsearch in Action》第二版书籍创建的数据集 - 可在此处获取:
为了完整起见,此处提供了使用 _bulk 操作进行摄取的片段:
POST _bulk?pipeline=movie_embedding_pipeline
{"index":{"_index":"movies","_id":"1"}}
{"title": "The Shawshank Redemption","synopsis": "Two imprisoned men bond over a number of years, finding solace and eventual redemption through acts of common decency.","actors": ["Tim Robbins", "Morgan Freeman", "Bob Gunton", "William Sadler"] ,"director":" Frank Darabont ","rating":"9.3","certificate":"R","genre": "Drama "}
{"index":{"_index":"movies","_id":"2"}}
{"title": "The Godfather","synopsis": "An organized crime dynasty's aging patriarch transfers control of his clandestine empire to his reluctant son.","actors": ["Marlon Brando", "Al Pacino", "James Caan", "Diane Keaton"] ,"director":" Francis Ford Coppola ","rating":"9.2","certificate":"R","genre": ["Crime", "Drama"] }
{"index":{"_index":"movies","_id":"3"}}
{"title": "The Dark Knight","synopsis": "When the menace known as the Joker wreaks havoc and chaos on the people of Gotham, Batman must accept one of the greatest psychological and physical tests of his ability to fight injustice.","actors": ["Christian Bale", "Heath Ledger", "Aaron Eckhart", "Michael Caine"] ,"director":" Christopher Nolan ","rating":"9.0","certificate":"PG-13","genre": ["Action", "Crime", "Drama"] }确保使用完整数据集替换脚本。
请注意,_bulk 操作带有管道后缀 (?pipeline=movie_embedding_pipeline),因此每部电影都通过此管道传递,从而生成向量。
当我们准备好用向量嵌入索引的电影时,是时候开始微调 k 和 num_candidates 属性的实验了。
kNN 搜索
由于我们的电影索引中有矢量数据,因此我们将使用近似 k 最近邻 (kNN) 搜索。 例如,要推荐具有父子情感的类似电影(“Father and son” 作为搜索查询),我们将使用 kNN 搜索来查找最近的邻居:
POST movies/_search
{
"_source": ["title"],
"knn": {
"field": "title_vector.predicted_value",
"query_vector_builder": {
"text_embedding": {
"model_id": ".multilingual-e5-small",
"model_text": "Father and son"
}
},
"k": 5,
"num_candidates": 10
}
}在给定的例子中,查询利用了顶层 kNN 搜索选项参数,直接专注于查找与给定查询向量最接近的文档。与在顶层使用 knn 查询相比,这种搜索的一个关键区别在于前者的查询向量将由机器学习模型动态生成。
粗体部分技术上不正确。动态向量生成仅在使用 query_vector_builder 而不是 query_vector 时实现,后者是传入在 ES 之外计算的向量。但无论是顶层 kNN 搜索选项还是 kNN 搜索查询,都提供了这一功能。
脚本根据我们的搜索查询(使用 query_vector_builder 块构建)获取相关结果。我们使用了随机设置的 k 和 num_candidates 值,分别为 5 和 10。
kNN 查询属性
上述查询包含了组成 kNN 查询的一组属性。以下关于这些属性的信息将帮助你更好地理解查询:
field 属性指定索引中包含文档向量表示的字段。在这个例子中,title_vector.predicted_value 是存储文档向量的字段。
query_vector_builder 属性是示例与简单的 kNN 查询显著不同的地方。这种配置不是提供一个静态的查询向量,而是使用文本嵌入模型动态生成查询向量。该模型将一段文本(示例中的 “Father and son”)转换成代表其语义含义的向量。
text_embedding 表示将使用文本嵌入模型生成查询向量。
model_id 是要使用的预训练机器学习模型的标识符,在此例中为 .multilingual-e5-small 模型。
model_text 属性是将由指定模型转换成向量的文本输入。这里是词组 “Father and son”,模型将语义地解释这些词以找到类似的电影标题。
k 是要检索的最近邻居的数量 —— 即,它决定基于查询向量返回多少最相似的文档。
num_candidates 属性是每个分片作为潜在匹配项的更广泛的候选文档集,以确保最终结果尽可能准确。
kNN 结果
执行 kNN 基本搜索脚本应该会为我们提供前 5 个结果 - 为简洁起见,我仅提供电影列表。
# The results should get you a set of 5 movies as shown in the list below:
"title": "The Godfather"
"title": "The Godfather: Part II"
"title": "Pulp Fiction"
"title": "12 Angry Men"
"title": "Life Is Beautiful"正如你所料,《教父 - Godfather》(两部分)是父子关系的一部分,而《低俗小说 - Pulp Fiction》不应该成为结果的一部分(尽管查询询问的是 “关系” —— 低俗小说都是关于关系的)在少数人中)。
现在我们有了基本的框架设置,我们可以调整适当的参数并推断出大致的设置。 在调整设置之前,我们先了解一下 k 属性的最佳设置。
选择最佳的 k 值
在 k 最近邻 (kNN) 算法中选择最佳的 k 值对于在我们的数据集上获得最佳性能并尽量减少错误至关重要。然而,并没有一个通用的答案,因为最佳的 k 值可能取决于一些因素,如我们的数据的具体情况以及我们试图预测的内容。
要选择一个最佳的 k 值,必须创建一个包含多种策略和考虑因素的自定义框架。
- k = 1:首先尝试使用 k=1 运行搜索查询。确保每次运行都更改输入查询。查询应该会给你不可靠的结果,因为更改输入查询会随时间返回错误的结果。这会导致一种称为 “过拟合 - overfitting” 的机器学习模式,其中模型过度依赖于直接邻域中的特定数据点。因此,模型难以泛化到未见的例子。
- k = 5:用 k=5 运行搜索查询并检查预测。搜索查询的稳定性理想情况下应该得到改善,你应该能得到足够可靠的预测。
你可以逐步增加 k 的值 —— 也许以 5 或 x 的步长增加 —— 直到你发现输入查询的结果几乎完全准确且错误数量较少的那个甜蜜点。
你也可以选择极端的 k 值,例如,选择较高的 k=50 值,如下所述:
- k = 50:将 k 值增加到 50 并检查搜索结果。错误的结果很可能会掩盖实际/预期的预测。这时你就知道你已经达到了 k 值的硬性边界。较大的 k 值会导致一种叫做 “欠拟合 - underfitting” 的机器学习特征 —— 在 KNN 中的欠拟合发生在模型过于简单,未能捕捉到数据中的潜在模式时。
选择最佳的 num_candidates 個数值
num_candidates 参数在寻找搜索精确度和性能之间的最佳平衡中扮演着关键角色。与直接影响返回搜索结果数量的 k 不同,num_candidates 确定了从中选出最终 k 个最近邻居的初始候选集的大小。如前所述,num_candidates 参数定义了每个分片上将选择多少个最近邻居。
调整此参数对于确保搜索过程既高效又产生高质量结果至关重要。
- num_candidates = 小值(例如,10):作为初步步骤,从较低的 num_candidates 值(“低值探索”)开始。此阶段的目标是建立性能的基线。由于候选集只有少数候选项,搜索将会非常快速,但可能错过相关结果 —— 这会导致精确度不高。这种情况有助于我们理解搜索质量明显受损的最低阈值。
- num_candidates = 中等值(例如,25?):将 num_candidates 增加到中等值(“中值探索”),并观察搜索质量和执行时间的变化。适量的候选项可能通过考虑更广泛的潜在邻居池来提高结果的精确度。随着候选数量的增加,资源成本也会增加,请注意这一点。因此,继续密切监控性能指标。然而,随着搜索精确度的提高,计算成本的增加可能是合理的。
- num_candidates = 逐步增加:继续逐步增加 num_candidates(逐步增加探索),可能以 20 或 50 的步长(取决于数据集的大小)。评估每次增加额外候选项是否对搜索精确度有意义的提高。会有一个收益递减点,此时进一步增加 num_candidates 几乎不会改善结果质量。同时你可能已经注意到,这将对我们的资源造成压力并显著影响性能。
- num_candidates = 高值(例如,1000,5000):通过高 num_candidates 值实验,以了解选择较高设置的影响的上限。由于包含了不太相关的候选项,你的搜索精确度可能稳定下来或略有下降。这可能会稀释最终 k 结果的精确度。请注意,正如我们所讨论的,高 num_candidates 值将始终增加计算负载 —— 因此查询时间更长和潜在的资源限制。
寻找最佳平衡
我们现在知道如何调整 k 和 num_candidates 属性,以及我们对不同设置的实验将如何改变搜索准确性的结果。
目标是找到一个最佳点,使搜索结果始终准确,并且处理大型候选集时的性能开销较低且易于管理。
当然,最佳值会根据数据的具体情况、向量的维数以及其他性能要求而有所不同。
总结起来
最佳 k 值在于通过实验和尝试找到最佳点。 你希望使用足够的邻居(k 为较低侧)来捕获基本模式,但不要太多(k 为较高侧),以免模型过度受到噪声或不相关细节的影响。 你还需要调整候选者,以便搜索结果在给定的 k 值下准确。
准备好自己尝试一下了吗? 开始免费试用。
想要获得 Elastic 认证吗? 了解下一次 Elasticsearch 工程师培训的举办时间!
原文:Elasticsearch kNN search: How to choose the best k and num_candidates — Elastic Search Labs


![buu[HCTF 2018]WarmUp(代码审计)](https://img-blog.csdnimg.cn/direct/01f80e3705d64460981b57a0e1829323.png#pic_center)