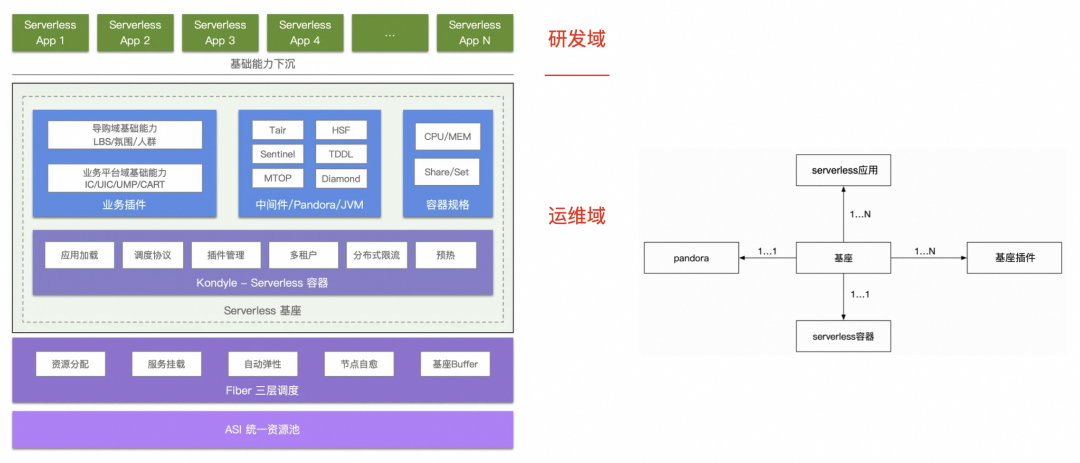
SERVERLESS能够将应用分为研发域和运维域,使两者独立迭代,降低运维成本,提升研发效率。点淘作为试点项目,经历了包括功能回归、压力测试和监控验证在内的质量保障流程,并在实践中遇到了各种问题,如依赖梳理、性能验证和监控建设等。文章还提到了SERVERLESS带来的部署效率提升,例如应用部署时长显著下降,并展望了未来通过基座插件化和分层自动化来进一步优化测试成本和功能保障。最后,文中列举了SERVERLESS升级带来的部署时间减少的具体案例,展示了实施SERVERLESS架构的收益。

aone serverless概念&背景
aone serverless简介:
serverless作为新兴技术,虽然有了统一的定义和鉴定原则,但普遍认为还没统一的实现标准。广义上指:构建和运行软件时不需要关心服务器的一种架构思想。虽然 serverless 翻译过来是 “无服务器”,但这并不代表着应用运行不需要服务器,而是开发者不需要关心服务器。
特别说明:aone serverless是结合阿里集团特点推出的对传统的集团内的企业级应用实现serverless化的解决方案,下文所提的serverless均是aone serverless的工程实践,可能和公网上所提的serverless略有不同。
aone serverless从本质上讲是一种新型的云原生架构,通过分层的思想,将原来的应用分离成研发域以及运维域,并通过『插件机制&三层调度』提供一个架构一致性的抓手,研发域由业务开发人员掌控,运维域由基座开发人员掌控,两者独立迭代,互不干扰。
本文主要讲aone serverless质量保障,概念本身此处不做过多展开。
内容技术开展&点淘APP先行的原因
降低运维成本、提升研发体验、提升交付效率。(顶层设计比较朴实,预研时很关注ROI)
集团在基础设施和实践经验上有了一定积累
点淘历史比淘内短,试错的成本和风险低于淘内,更适合做这种探索性工作

质量保障设计思路
serverless是一种新型云原生架构,那么对应的质量保障手段就绕不开常规的保障手段——回归。经历过PandoraBoot强势推进升级覆盖、集团整体上云等的同学应该都做过全应用回归。点淘做serverless在内容技术属于试点,集团可参考的团队不多,当时serverless对我们来说是相对黑盒的。同时流量高&资损点多,所以点淘回归做的比较重,同时重点关注应用性能表现。
serverless架构采用了分层的思想,质量上也应该分层保障。过往我们测试更关注研发域应用层的质量,后面运维域基座&插件的保障也应在工作范围内。同时架构升级和分层也导致了某些依赖关系发生改变,质量保障上也应更关注环境依赖相关功能的保障。
点淘serverless已开展了近半年,基于过往经验&踩坑,serverless质量保障可以做的更轻便,这块在「总结&展望」重点讲,此处不做过多展开。

升级质量保障实战
▐ 功能回归
业务梳理:
接口反推:根据升级应用内接口流量大小排序(如QPS>X),并且根据接口反推功能,确保大流量接口都能覆盖到。
专家经验:对资损、环境依赖、高舆情场景进行梳理和覆盖。
依赖梳理:结合流量调用分析对应用&接口的依赖关系进行梳理,对之前没有覆盖的对外依赖(如中间件、其他应用、外部SDK等)进行重点覆盖。
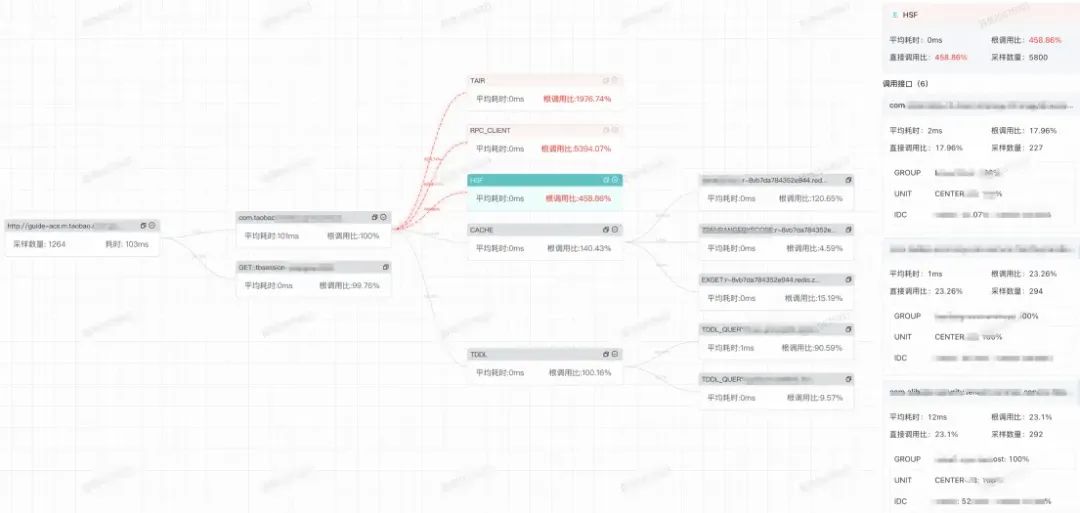
独立测试环境搭建&命中:
serverless升级主要是针对服务端的,但内容相关业务往往是端到端的。所以重点场景的功能测试是必不可少的。命中serverless独立测试环境可以提高功能测试效率,集团测试工具可以帮助测试流量快速&准确的命中到serverless机器上。
接口自动化测试:
接口自动化测试是做回归最直接的手段。如果待升级的应用已经有了自动化覆盖,那么质量保障成本会小很多。如果还没有自动化覆盖,可以参考一下我们以往踩的坑,提高工作效率。
对于功能回归我们很难覆盖业务线上流量的所有情况,所以需要进行全面的接口测试来对场景进行全面覆盖,为提高接口回归的效率与覆盖率,采用接口流量录制与回放的方式对接口进行回归。
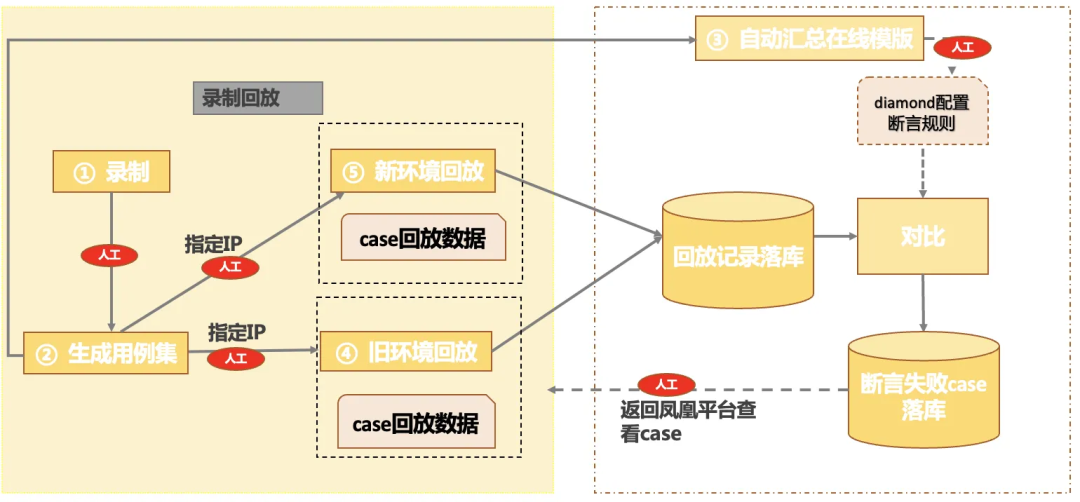
由于serverless本身机制问题,每次部署之后IP都会变化。经过调研,我们选择了自动化挂载比较方便的自动化平台。
▐ 压力测试
serverless升级主要是环境升级,需验证新容器比旧容器性能表现不明显下降。对性能敏感的应用,建议测试环境阶段就对serverless机器进行性能对比。对性能不敏感的应用,可以等灰度放量50%时和老容器进行流量和系统水位的对比。
压测方式:
优雅的压测方式:应采用统一环境隔离的方式,针对需要验证的机器做gray4的灰度环境压测。但因人员调整,gray4压测不再支持新业务接入,我们只能曲线救国。
曲线救国的压测方式:通过vipserver把指定接口路由到需压测的机器上去,再对实验组、对照组压测,观察性能表现。(此部分为研发工作量)
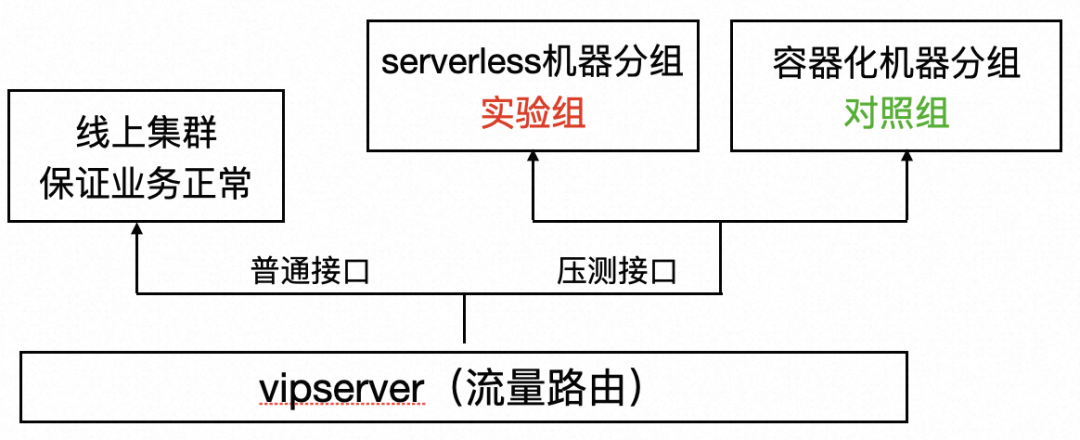
最省力的压测方式:对性能不敏感的应用,等灰度放量50%时和老容器进行流量和系统水位的对比。
压测验证方式:
执行压测前即可通过调用数据的traceid验证流量是否到指定机器上,确保实验组和对照组的前置条件符合预期,进而降低压测成本。
流量和系统水位观测:和普通压测类似,找到普通分组和serverless分组即可,然后对cpu、load等关键指标两个分组进行对比。但由于serverless基建还可能还不完善,建议多个平台对比系统水位,确保系统数据显示准确。
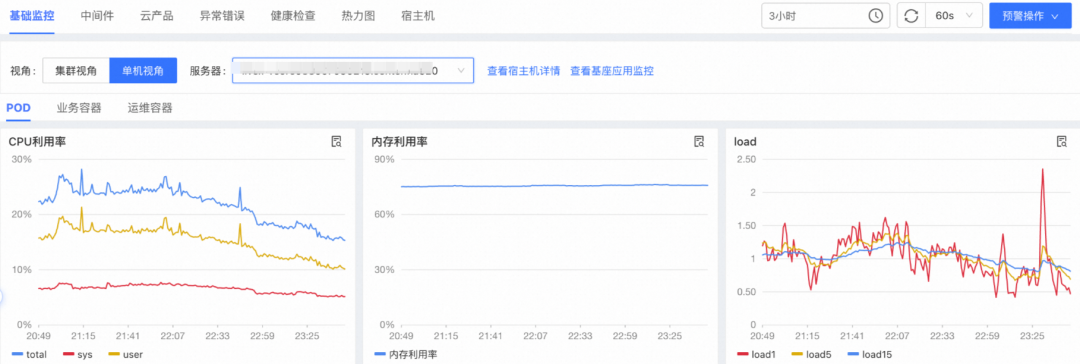
▐ 监控验证
应用serverless升级后在灰度放量前,我们需要单独对serverless的机器分组进行监控建设(主要覆盖核心场景)。
对于serverless的监控,研发一般会有两种操作:在原有监控基础上新增分组、新建监控。验证方式如下:
合理性验证:根据经验以及对应用的了解,和研发对齐监控设置的报警条件是否合理
有效性验证:这部分的验证手段可以利用混沌工程往日志文件中注入错误日志,看是否能够触发监控报警,在过程中主要关注两个点:报警是否订阅、报警达到阈值后能否及时报警
日志排查:对于应用的监控关注点,建议放在系统的异常日志,因为升级过程中遇到的各种因环境未ready造成的异常均可以体现在异常日志。
▐ 问题分析
近半年踩了不少坑,记录在案的有42个问题,仅3个和研发域上层应用升级相关。阿里serverless在上层应用升级上具备了可推广的条件。
研发域问题:参考历史问题,基本都集中在对外部有依赖的场景上(如中间件、其他应用、外部SDK等),升级时这部分需要重点关注
运维域问题:问题基本集中在监控系统数据统计和更底层的依赖上,随着这半年的踩坑,目前运维域升级也越来越顺畅
产品能力问题:serverless还是一个迭代中的新云原生架构,还有些细节问题不完善。目前这些问题都有比较定制的快速解决方法,优雅的解决方式还需要产品化的长远解决

总结&展望
▐ 总结
研发域的问题基本都和环境相关。和对外依赖、外连权限、系统变量、自定义变量等相关的要重点梳理,功能测试接口测试都尽可能覆盖。
运维域踩了最多的坑,一般和业务的性能统计性能表现相关,主要影响基座&插件相关的同学(少数)。
serverless还是一个发展过程中的产品,有它架构先进性和潜在收益。但也有大量的坑需要接入方去踩,一般这些坑踩过之后,别的应用也是受益的。一般产品能力问题都有黑科技可以解决,但长远支持还得看tre产品化能力支持。
目前serverless升级各阶段投入成本如下图。
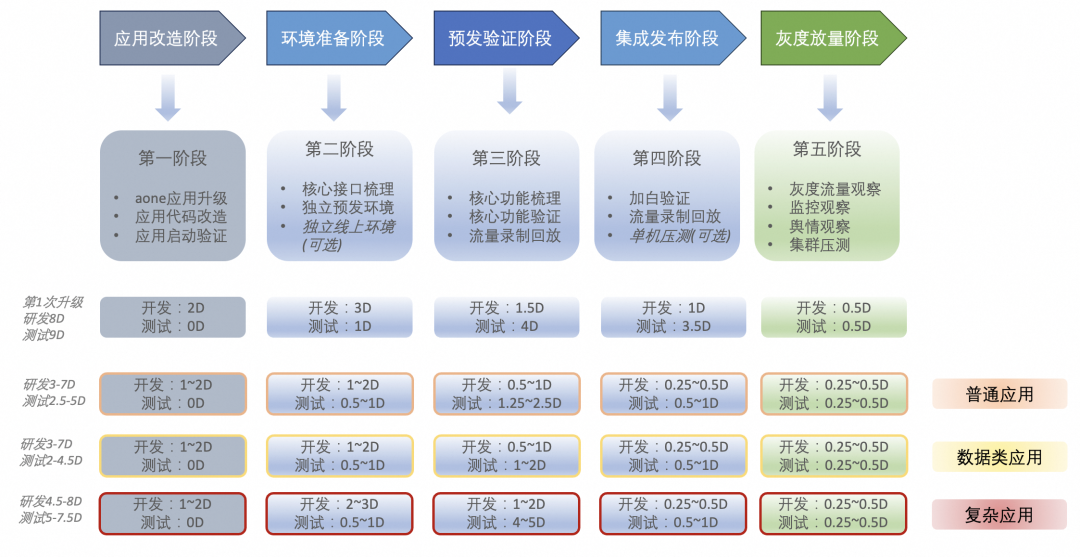
▐ 展望
点淘踩了半年的坑之后,serverless对我们也不再黑盒。后续环境依赖相关功能和P0级接口重点保障,其他功能通过线上监控保障。预估下来1个普通应用升级的测试成本可控制在0.5~1人日(现成本见上图),复杂应用得具体分析。
点淘已经基于基座做了工作,但目前基座上的插件还不多,S1点淘预计完成26+个基础能力的插件化。插件功能不会暴露hsf接口,1个基座同时会同时影响多个上层应用。所以分层自动化&分层容灾是必须要做的工作。最底层的单元测试我们将使用copilot对基座插件代码进行覆盖,试用下来有明显效率提升。
▐ 收益
【部署提效】应用部署构建时长平均减少17%,对于启动时长越长的应用,收益更好,并且由于引入surge模式,原有的2批发布改为一批发布,一线同学对于升级serverless之后的体感更强一些, 月度平均部署构建时长见下表。
应用举例
部署时长
构建时长
总时长
某大型业务应用
减少44.4%
减少17.2%
减少34.9%
某数据型应用
减少32%
减少6.5%
减少22.9%
某中型业务应用
减少25.6%
减少8.7%
减少18.9%
基座owner&插件升级者关注,对于其他一线开发同学无感


声明&致谢
serverless还是一个探索中的技术形态,故本次分享不是点淘serverless质量保障的最终形态,欢迎有兴趣的同学一起来探索更稳定更高效的保障策略。
本文部分设计思路和图表产自我的搭档,以及我的TL在方案设计和AI实践上的指导。
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法