前言:在探索现代数据科学的前沿领域时,掩码自回归编码器法(Masked Autoencoder,简称MAE)无疑是一个引人注目的亮点。这一技术,凭借其独特的训练机制和卓越的性能,已经在图像识别、自然语言处理以及众多其他领域展现出强大的潜力。今天,我们就来深入剖析掩码自回归编码器法的核心原理、应用前景以及它如何引领我们迈向更加智能的数据分析新时代。
本文所涉及所有资源均在传知代码平台可获取
目录
概述
演示效果
核心代码
写在最后
概述
掩码自动编码器MAE是一款具有可扩展性的计算机视觉自我监控学习器。它可以从一个不完整或错误的图像序列中提取出感兴趣的信息来进行分类和识别,在图像处理领域得到了广泛的应用。MAE的核心策略包括:对输入图像的随机补丁进行屏蔽,并对遗失的像素进行重建,这一策略是基于两个主要的设计思路,如下:
1)一种非对称编码器-解码器架构,其中编码器只对可见的补丁子集进行操作(没有掩码标记)
2)一个轻量级解码器,它根据潜在表示和掩码标记重建原始图像
MAE的掩码自编码器是一种简单地自编码方法,它在给定原始信号的部分观测值的情况下重建原始信号。和所有的自编码器一样,MAE有一个将观察到的信号映射到潜在表示的编码器,以及一个从潜在表示重建原始信号的解码器,如下图所示:
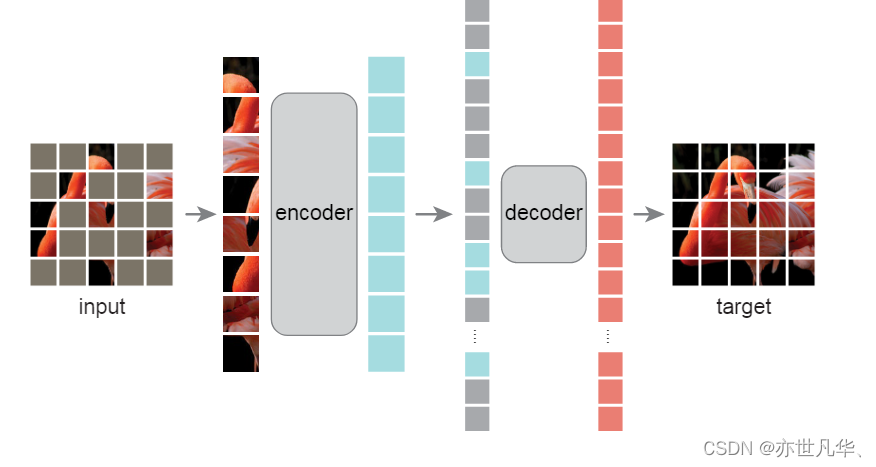
与经典的自编码器不同,MAE采用了一种非对称设计,允许编码器仅对部分观察到的信号进行操作(没有掩码标记),并采用了一个轻量级解码器,该解码器根据潜在表示和掩码标记重建全部信号,以下是对相关概念的讲解:
掩码:
与ViT方法相似,MAE将图像分为有规律的非重叠部分,然后MAE对补丁的子集进行取样,并对剩下的补丁进行屏蔽或移除。对于每个候选补丁而言,它是由一系列不同大小和位置分布的样本构成的集合,因此可以用多个阈值来确定这些样本的权重。MAE的取样方法相当直接,它对补丁进行随机取样,不做替换,并按照均匀的方式分布。为了提高效率和减少计算量,提出一种基于均匀抽样技术的快速修复算法。随机采样具有较高的掩码比(即去除补丁的比例),这在很大程度上减少了数据冗余。因此,这导致了一个问题,即不能仅通过从相邻的明显补丁中进行外推来解决。通过均匀分布,可以避免中心偏差(即图像中心附近的掩码补丁越多)。最后一个高度稀疏的输入为设计一个高效的编码器提供了可能性。
MAE编码器:
MAE中编码器为ViT,但仅适用于可见和不屏蔽补丁。与标准ViT类似,MAE中编码器也是通过增加位置嵌入线性投影嵌入补丁再经过一系列Transformer块对结果集进行处理。然而,MAE的编码器只对全集的一小部分(例如25%)进行操作。带MAE可以只利用小部分计算与内存,就可以训练出很大的编码器。
MAE解码器:
MAE解码器输入为编码器可见补丁与掩码令牌构成一个完整令牌集合。每一个掩码标记为共享和学习向量,表示是否有丢失补丁需要被预测。MAE将位置嵌入添加到该全集中的所有令牌中,如果没有这一点,掩码令牌将没有关于其在图像中的位置信息。MAE解码器仅在预训练期间用于执行图像重建任务(仅使用编码器生成识别用图像表示。)因此,可以以独立于编码器设计的方式灵活地设计解码器架构。
重建目标:
MAE通过预测每个掩码补丁的像素值来重建输入,解码器输出中的每个元素是表示补丁的像素值的矢量。解码器末层为线性投影且输出通道个数与块内像素值个数相等。重建解码器输出,形成重建图像。在像素空间中,MAE的损失函数用于计算重建图像与原始图像的均方误差(MSE),这与BERT是一致的,而MAE仅用于计算掩码补丁上的损失。MAE也研究了以各屏蔽补丁归一化像素为重构对象的变体。具体而言,MAE在一个Patch上计算所有像素的均值与标准差并用其归一化这个patch。以归一化像素为重构对象,改善表示质量。
简单实现:
首先,MAE为每个输入补丁生成一个标记(通过添加位置嵌入的线性投影),接下来,MAE随机打乱令牌列表,并根据屏蔽比率删除列表的最后一部分。这个过程为编码器生成一小部分标记,相当于采样补丁而不进行替换。编码后,MAE将一个掩码令牌列表添加到编码补丁列表中,并对这个完整列表纪念性unshuffle(反转随机混洗操作),以将所有标记与其目标对齐。编码器应用于该完整列表(添加了位置嵌入)。如前所述,不需要稀疏运算,这种简单地实现引入了可忽略不计的开销,因为混洗和取消混洗操作很快。
该编码方式参考如下论文内容,地址 :
演示效果
通过如下的方式对项目进行相关部署:
# linux系统下python=3.7
conda create -n mae python=3.7
conda activate mae
# 下载torch
wget https://download.pytorch.org/whl/cu116/torch-1.13.0%2Bcu116-cp37-cp37m-linux_x86_64.whl
pip install 'torch的下载地址'
# 下载torchvision
wget https://download.pytorch.org/whl/cu116/torchvision-0.14.0%2Bcu116-cp37-cp37m-linux_x86_64.whl
pip install 'torchvision的下载地址'
pip install timm==0.4.5
pip install ipykernel
pip install matplotlib
pip install tensorboardMAE随机掩码图像实现的效果如下:

核心代码
随机掩码的实现逻辑如下:
def random_masking(self, x, mask_ratio):
"""
Perform per-sample random masking by per-sample shuffling.
Per-sample shuffling is done by argsort random noise.
x: [N, L, D], sequence
"""
N, L, D = x.shape # batch, length, dim
# 确定需要保存多少个patch
len_keep = int(L * (1 - mask_ratio))
# [1,196] 用batch此时输入的图片可能不止一个,196表示patch的个数
noise = torch.rand(N, L, device=x.device) # noise in [0, 1]
# sort noise for each sample
# 默认按升序排序,此时返回的是序号,首先获取从低到高排列的序号
ids_shuffle = torch.argsort(noise, dim=1) # ascend: small is keep, large is remove
# 获取ids_shuffle从低到高排列的序号,这样就能还原原始的noise的情况
ids_restore = torch.argsort(ids_shuffle, dim=1)
# keep the first subset
ids_keep = ids_shuffle[:, :len_keep] # 保存数据少的情况
# [1,49,1024] dim=0 按列进行索引,dim=1按行进行索引,获取x的取值
x_masked = torch.gather(x, dim=1, index=ids_keep.unsqueeze(-1).repeat(1, 1, D))
# generate the binary mask: 0 is keep, 1 is remove
mask = torch.ones([N, L], device=x.device)
mask[:, :len_keep] = 0
# unshuffle to get the binary mask 为0表示没有被掩码,1表示被掩码
# 将是否被掩码通过mask表示出来
mask = torch.gather(mask, dim=1, index=ids_restore)
return x_masked, mask, ids_restore编码器的实现逻辑如下:
def forward_encoder(self, x, mask_ratio):
# embed patches [1,3,224,224]->[1,196,1024]
x = self.patch_embed(x)
# add pos embed w/o cls token 除了全局特征,全部加上了位置信息
x = x + self.pos_embed[:, 1:, :]
# masking: length -> length * mask_ratio
x, mask, ids_restore = self.random_masking(x, mask_ratio)
# id_restore保存的是原来的位置
# append cls token
cls_token = self.cls_token + self.pos_embed[:, :1, :]
cls_tokens = cls_token.expand(x.shape[0], -1, -1) # [1,1,1024]
# [1,50,1024] 要包含一个class的情况
x = torch.cat((cls_tokens, x), dim=1)
# apply Transformer blocks
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
return x, mask, ids_restore解码器的实现逻辑如下:
def forward_decoder(self, x, ids_restore):
# embed tokens [1,50,1024]->[1,50,512]
x = self.decoder_embed(x)
# append mask tokens to sequence 获取被掩码的token [1,147,512]
mask_tokens = self.mask_token.repeat(x.shape[0], ids_restore.shape[1] + 1 - x.shape[1], 1)
# 将经过编码的数据和原始的初始化为0的数据编码在一起。
x_ = torch.cat([x[:, 1:, :], mask_tokens], dim=1) # no cls token
# 将编码的和为编码的重新转变为原始的patch大小,其实本质上只需要考虑编码的位置,因为其余都是随机初始化的
x_ = torch.gather(x_, dim=1, index=ids_restore.unsqueeze(-1).repeat(1, 1, x.shape[2])) # unshuffle
x = torch.cat([x[:, :1, :], x_], dim=1) # append cls token
# add pos embed
x = x + self.decoder_pos_embed
# apply Transformer blocks
for blk in self.decoder_blocks:
x = blk(x)
x = self.decoder_norm(x)
# predictor projection 将其转换为所有像素
x = self.decoder_pred(x)
# remove cls token
x = x[:, 1:, :]
return x写在最后
掩码自回归编码器法(Masked Autoencoder, MAE)作为一种前沿的深度学习架构,尤其在处理大规模数据集和复杂特征空间时展现出了其独特的优势。通过对输入数据进行部分掩码(即随机遮盖部分输入),MAE迫使模型从剩余的可见数据中预测被遮盖的部分,这种自监督的学习方式有效地提高了模型的泛化能力和鲁棒性。然而,MAE也面临着一些挑战和限制。例如,如何确定最佳的掩码比例和策略仍然是一个开放的问题。此外,MAE在处理某些特定任务时可能不如其他方法有效,这需要根据具体任务和数据集进行选择和调整,我们有望进一步优化和完善MAE的性能,并将其应用于更加广泛和复杂的任务中。
详细复现过程的项目源码、数据和预训练好的模型可从该文章下方附件获取。
【传知科技】关注有礼 公众号、抖音号、视频号