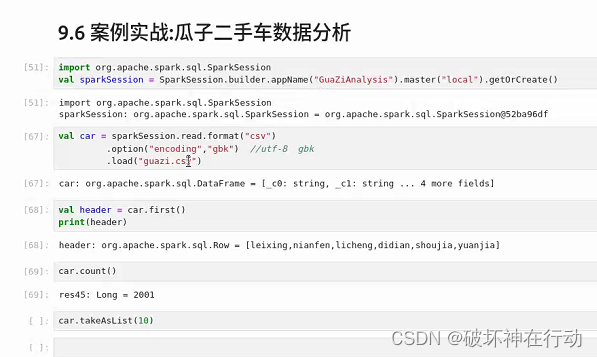
9.2 创建DataFrame对象的方式
val dfUsers = spark.read.load("/usr/local/spark/examples/src/main/resources/users.parquet")
dfUsers: org.apache.spark.sql.DataFrame = [name: string, favorite_color: string ... 1 more field]
dfUsers.show()
+------+--------------+----------------+ | name|favorite_color|favorite_numbers| +------+--------------+----------------+ |Alyssa| NULL| [3, 9, 15, 20]| | Ben| red| []| +------+--------------+----------------+
9.2.2 json文件创建DataFrame对象
val dfGrade = spark.read.format("json").load("file:/media/sf_download/grade.json")
dfGrade: org.apache.spark.sql.DataFrame = [Class: string, ID: string ... 3 more fields]
dfGrade.show(3)
+-----+---+----+-----+-----+ |Class| ID|Name|Scala|Spark| +-----+---+----+-----+-----+ | 1|106|Ding| 92| 91| | 2|242| Yan| 96| 90| | 1|107|Feng| 84| 91| +-----+---+----+-----+-----+ only showing top 3 rows
9.2.3 RDD创建DataFrame对象
val list = List(
("zhangsan" , "19") , ("B" , "29") , ("C" , "9")
)
val df = sc.parallelize(list).toDF("name","age")
list: List[(String, String)] = List((zhangsan,19), (B,29), (C,9)) df: org.apache.spark.sql.DataFrame = [name: string, age: string]
df.printSchema()
root |-- name: string (nullable = true) |-- age: string (nullable = true)
df.show()
+--------+---+ | name|age| +--------+---+ |zhangsan| 19| | B| 29| | C| 9| +--------+---+
9.2.4 SparkSession创建DataFrame对象
// 1.json创建Datarame对象
val dfGrade = spark.read.format("json").load("file:/media/sf_download/grade.json")
dfGrade.show(3)
+-----+---+----+-----+-----+ |Class| ID|Name|Scala|Spark| +-----+---+----+-----+-----+ | 1|106|Ding| 92| 91| | 2|242| Yan| 96| 90| | 1|107|Feng| 84| 91| +-----+---+----+-----+-----+ only showing top 3 rows
dfGrade: org.apache.spark.sql.DataFrame = [Class: string, ID: string ... 3 more fields]
Selection deleted
// 2.csv创建Datarame对象
val dfGrade2 = spark.read.option("header",true).csv("file:/media/sf_download/grade.json")
dfGrade2: org.apache.spark.sql.DataFrame = [{"ID":"106": string, "Name":"Ding": string ... 3 more fields]
dfGrade2.show(3)
+-----------+-------------+-----------+----------+-----------+
|{"ID":"106"|"Name":"Ding"|"Class":"1"|"Scala":92|"Spark":91}|
+-----------+-------------+-----------+----------+-----------+
|{"ID":"242"| "Name":"Yan"|"Class":"2"|"Scala":96|"Spark":90}|
|{"ID":"107"|"Name":"Feng"|"Class":"1"|"Scala":84|"Spark":91}|
|{"ID":"230"|"Name":"Wang"|"Class":"2"|"Scala":87|"Spark":91}|
+-----------+-------------+-----------+----------+-----------+
only showing top 3 rows
Selection deleted
// 3.Parquet创建Datarame对象
val dfGrade3 = spark.read.parquet("file:/usr/local/spark/examples/src/main/resources/users.parquet")
dfGrade3: org.apache.spark.sql.DataFrame = [name: string, favorite_color: string ... 1 more field]
dfGrade3.show(3)
+------+--------------+----------------+ | name|favorite_color|favorite_numbers| +------+--------------+----------------+ |Alyssa| NULL| [3, 9, 15, 20]| | Ben| red| []| +------+--------------+----------------+
9.2.5 Seq创建DataFrame对象
val dfGrade4 = spark.createDataFrame(
Seq(
("A" , 20 ,98),
("B" , 19 ,93),
("C" , 21 ,92),
)
)toDF("Name" , "Age" , "Score")
dfGrade4: org.apache.spark.sql.DataFrame = [Name: string, Age: int ... 1 more field]
dfGrade4.show()
+----+---+-----+ |Name|Age|Score| +----+---+-----+ | A| 20| 98| | B| 19| 93| | C| 21| 92| +----+---+-----+
9.3 DataFrame对象保存为不同格式
9.3.1 write.()保存DataFrame对象
DataFrame.write() 提供了一种方便的方式将 DataFrame 保存为各种格式。以下是几种常见格式的保存方法:
1. 保存为JSON格式
df.write.json("path/to/file.json")
2. 保存为Parquet文件
df.write.parquet("path/to/file.parquet")
3. 保存为CSV文件
df.write.csv("path/to/file.csv")
9.3.2 write.format()保存DataFrame对象
DataFrame.write.format() 提供了一种更灵活的方式来保存 DataFrame,可以通过指定格式名称来选择输出格式。以下是几种常见格式的保存方法:
1. 保存为JSON格式
df.write.format("json").save("path/to/file.json")
2. 保存为Parquet文件
df.write.format("parquet").save("path/to/file.parquet")
3. 保存为CSV文件
df.write.format("csv").save("path/to/file.csv")
9.3.3 先将DataFrame对象转化为RDD再保存文件
虽然可以直接使用 DataFrame 的 write 方法保存文件,但有时需要先将 DataFrame 转换为 RDD 再进行保存。这可能是因为需要对数据进行一些 RDD 特定的操作,或者需要使用 RDD 的保存方法。
rdd = df.rdd.map(lambda row: ",".join(str(x) for x in row))
rdd.saveAsTextFile("path/to/file.txt")
注意:
- 上述代码将 DataFrame 的每一行转换为逗号分隔的字符串,并将结果保存为文本文件。
- 可以根据需要修改代码以使用不同的分隔符或保存为其他格式。
9.4 DataFrame对象常用操作
9.4.1 展示数据
1. show()
// 显示前20行数据
gradedf.show()
// 显示前10行数据
gradedf.show(10)
// 不截断列宽显示数据
gradedf.show(truncate=False)
2. collect()
// 将 DataFrame 转换成 Dataset 或 RDD,返回 Array 对象
gradedf.collect()
3. collectAsList()
// 将 DataFrame 转换成 Dataset 或 RDD,返回 Java List 对象
gradedf.collectAsList()
4. printSchema()
// 打印 DataFrame 的模式(schema)
gradedf.printSchema()
5. count()
// 统计 DataFrame 中的行数
gradedf.count()
6. first()、head()、take()、takeAsList()
// 返回第一行数据
gradedf.first()
// 返回前3行数据
gradedf.head(3)
// 返回前5行数据
gradedf.take(5)
// 返回前5行数据,以 Java List 形式
gradedf.takeAsList(5)
7. distinct()
// 返回 DataFrame 中唯一的行数据
gradedf.distinct.show()
8. dropDuplicates()
// 删除 DataFrame 中重复的行数据
gradedf.dropDuplicates(Seq("Spark")).show()
9.4.2 筛选
1. where()
- 根据条件过滤 DataFrame 中的行数据。
- 示例: gradedf.where("Class = '1' and Spark = '91'").show()
2. filter()
- 与 where() 功能相同,根据条件过滤 DataFrame 中的行数据。
- 示例: gradedf.filter("Class = '1'").show()
3. select()
- 选择 DataFrame 中的指定列。
- 示例: gradedf.select("Name", "Class","Scala").show(3,false)
修改名称:gradedf.select(gradedf("Name").as("name")).show()
4. selectExpr()
- 允许使用 SQL 表达式选择列。
- 示例: gradedf.selectExpr("name", "name as names" ,"upper(Name)","Scala * 10").show(3)
5. col()
- 获取 DataFrame 中指定列的引用。
- 示例: gradedf.col("name")
6. apply()
- 对 DataFrame 中的每一行应用函数。
- 示例: def get_grade_level(grade): return "A" if grade > 90 else "B"
gradedf.select("name", "grade", "grade_level").apply(get_grade_level, "grade_level")
7. drop()
- 从 DataFrame 中删除指定的列。
- 示例: gradedf.drop("grade")
8. limit()
- 限制返回的行数。
- 示例: gradedf.limit(10)
9.4.3 排序
按ID排序
1. orderBy()、sort()
orderBy() 和 sort() 方法都可以用于对 DataFrame 进行排序,它们的功能相同。
// 按id升序排序
gradedf.orderBy("id").show()
gradedf.sort(gradedf("Class").desc,gradedf("Scala").asc).show(3)
// 按id降序排序
gradedf.orderBy(desc("id")).show()
gradedf.sort(desc("id")).show()
2. sortWithinPartitions()
示例:gradedf.sortWithinPartitions("id").show(5)
引申:sortWithinPartitions() 方法用于对 DataFrame 的每个分区内进行排序。
// 首先对 DataFrame 进行重新分区,使其包含两个分区
val partitionedDF = gradedf.repartition(2)
// 对每个分区内的 id 进行升序排序
partitionedDF.sortWithinPartitions("id").show()
需要注意的是,sortWithinPartitions() 方法不会改变 DataFrame 的分区数量,它只是对每个分区内部进行排序。
9.4.4 汇总与聚合
1. groupBy()
groupBy() 方法用于根据指定的列对 DataFrame 进行分组。
(1) 结合 count()
// 统计每个名字的学生人数
gradedf.groupBy("name").count().show()
(2) 结合 max()
// 找出每个课程学生的最高成绩
gradedf.groupBy("Class").max("Scala","Spark").show()(3) 结合 min()
// 找出每个名字学生的最低成绩
gradedf.groupBy("name").min("grade").show()
(4) 结合 sum()
// 计算每个名字学生的总成绩
gradedf.groupBy("name").sum("grade").show()
gradedf.groupBy("Class").sum("Scala","Spark").show()
(5) 结合 mean()
// 计算课程的平均成绩
gradedf.groupBy("Class").sum("Scala","Spark").show()2. agg()
agg() 方法允许对 DataFrame 应用多个聚合函数。
(1) 结合 countDistinct()
// 统计不重复的名字数量
gradedf.agg(countDistinct("name")).show()
(2) 结合 avg()
gradedf.agg(max("Spark"), avg("Scala")).show()
// 计算所有学生的平均成绩
gradedf.agg(avg("grade")).show()
(3) 结合 count()
// 统计学生总数
gradedf.agg(count("*")).show()
(4) 结合 first()
// 获取第一个学生的姓名
gradedf.agg(first("name")).show()
(5) 结合 last()
// 获取最后一个学生的姓名
gradedf.agg(last("name")).show()
(6) 结合 max()、min()
// 获取最高和最低成绩
gradedf.agg(max("grade"), min("grade")).show()
(7) 结合 mean()
// 计算所有学生的平均成绩
gradedf.agg(mean("grade")).show()
(8) 结合 sum()
// 计算所有学生的总成绩
gradedf.agg(sum("grade")).show()
(9) 结合 var_pop()、variance()
// 计算成绩的总体方差
gradedf.agg(var_pop("grade"), variance("grade")).show()
(10) 结合 covar_pop()
// 计算 id 和 grade 之间的总体协方差
gradedf.agg(covar_pop("id", "grade")).show()
(11) 结合 corr()
gradedf.agg(corr("Spark","Scala")).show()9.4.5 统计