1. 概念
RAG(Retrieval Augmented Generation)检索增强生成,它结合了搜索技术和大语言模型的提示词功能,以搜索算法找到的信息作为背景上下文,来辅助大语言模型(Large Language Model, LLM)生成答案。
常见的RAG业务流程为:
- 文档预处理流程:将文本切分成小段,利用某种向量编码器模型,将这些文本段转换成向量形式,把所有向量汇集到一个索引里。
- 用户使用流程:用户输入一个Query, 通过向量索引找到与Query相关的文档片段Relevant Documents,通过设计提示词来指导大语言模型(LLM)根据这些Document chunks回答用户的查询,并生成答案。
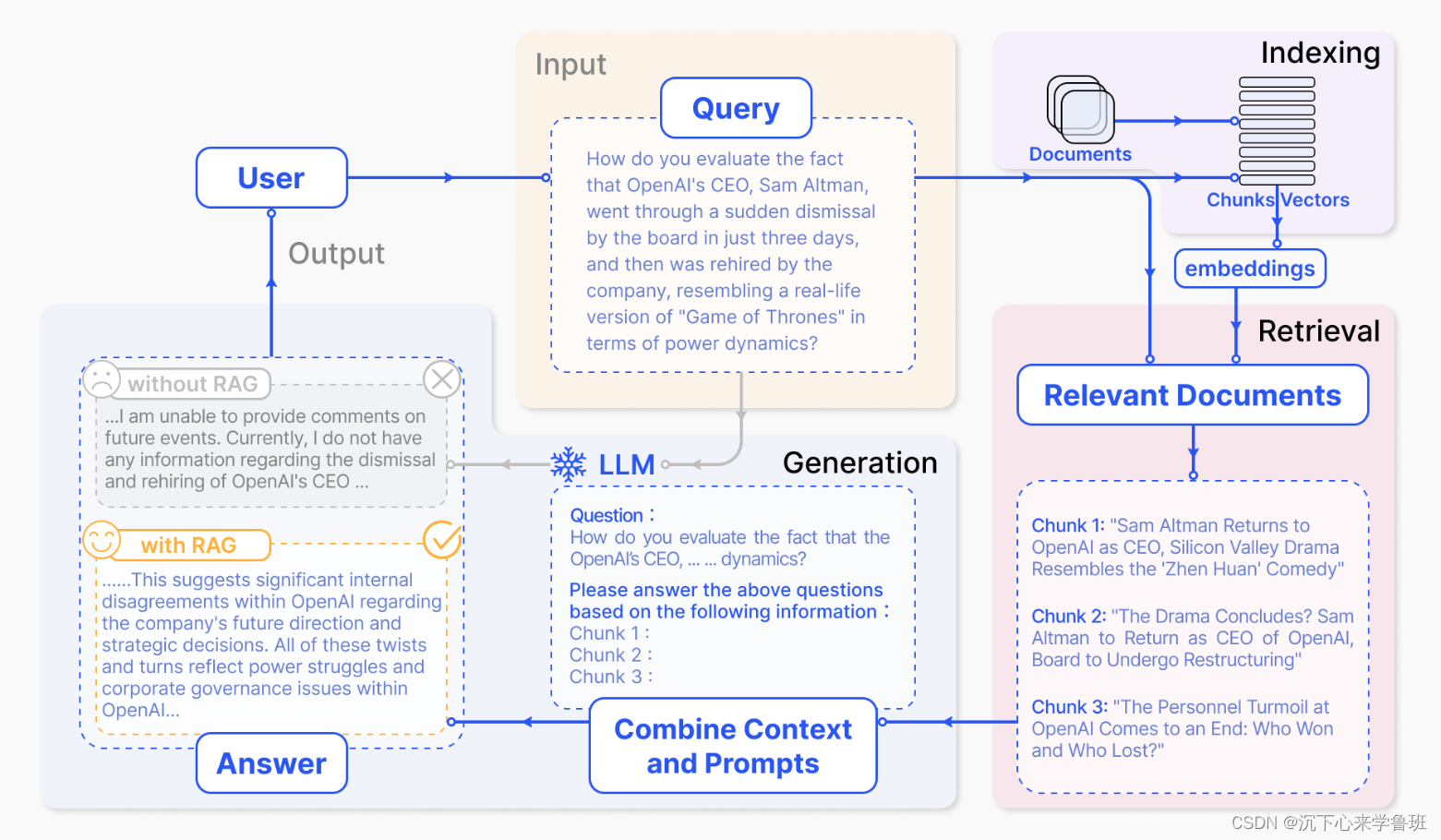
RAG基本模块组成:
- 文档加载:用来加载文档,并对文档进行分段切割。
- 向量嵌入:使用一个embedding模型对文档片段进行向量化嵌入。
- 向量检索:用来根据 Query (问题)检索相关的文档片段。
- 语言模型:根据检索出来的文档片段,使用大模型的能力来回答用户的问题。
在本文中,我们的目标是构建纯本地的RAG,一个比较大的挑战在于本地机器资源是否能将嵌入模型和语言模型跑起来,特别是语言模型,对硬件资源要求往往都比较高。
下面我们会先做一个准备工作,调研模型文件是否能在本地跑起来。
2. 准备工作
这里主要是准备要用的模型文件,包括嵌入模型和语言模型。
2.1 嵌入模型下载
嵌入模型选择moka公司出的中文语言嵌入模型:m3e-base
模型来源:modelscope
选择m3e-base作为嵌入模型主要参考了这篇文章:开源中文嵌入模型m3e
先安装下载脚本所依赖的库:
pip install modelscope
使用官方给的脚本来下载模型:
from modelscope import snapshot_download
snapshot_download('xrunda/m3e-base', cache_dir='/Users/a200007/work/models/', revision='master')
xrunda/m3e-base:模型名称cache_dir:本地保存路径revision:下载的分支版本,类似于git上的代码分支概念,这里选择master.
下载的过程如下:
2024-05-18 22:56:32,400 - modelscope - INFO - PyTorch version 2.2.2 Found.
2024-05-18 22:56:32,403 - modelscope - INFO - Loading ast index from /Users/a200007/.cache/modelscope/ast_indexer
2024-05-18 22:56:32,403 - modelscope - INFO - No valid ast index found from /Users/a200007/.cache/modelscope/ast_indexer, generating ast index from prebuilt!
2024-05-18 22:56:32,572 - modelscope - INFO - Loading done! Current index file version is 1.13.2, with md5 c1be71e2a72027a0333aadbdf480be8e and a total number of 972 components indexed
2024-05-18 23:22:16,156 - modelscope - WARNING - Using the master branch is fragile, please use it with caution!
2024-05-18 23:22:16,167 - modelscope - INFO - Use user-specified model revision: master
Downloading: 100%|████████████████████████████████████| 190/190 [00:00<00:00, 932kB/s]
Downloading: 100%|███████████████████████████████████| 932/932 [00:00<00:00, 4.55MB/s]
Downloading: 100%|████████████████████████████████████| 199/199 [00:00<00:00, 966kB/s]
Downloading: 100%|████████████████████████████████████| 112/112 [00:00<00:00, 541kB/s]
Downloading: 100%|█████████████████████████████████| 390M/390M [00:48<00:00, 8.44MB/s]
Downloading: 100%|███████████████████████████████████| 229/229 [00:00<00:00, 1.02MB/s]
Downloading: 100%|█████████████████████████████████| 390M/390M [00:37<00:00, 11.0MB/s]
Downloading: 100%|███████████████████████████████████| 865/865 [00:00<00:00, 4.20MB/s]
Downloading: 100%|███████████████████████████████| 26.0k/26.0k [00:00<00:00, 1.18MB/s]
Downloading: 100%|██████████████████████████████████| 53.0/53.0 [00:00<00:00, 398kB/s]
Downloading: 100%|████████████████████████████████████| 125/125 [00:00<00:00, 525kB/s]
Downloading: 100%|█████████████████████████████████| 429k/429k [00:00<00:00, 3.09MB/s]
Downloading: 100%|███████████████████████████████████| 342/342 [00:00<00:00, 1.69MB/s]
Downloading: 100%|█████████████████████████████████| 107k/107k [00:00<00:00, 1.38MB/s]
下载成功后本地相应的目录中有如下文件:
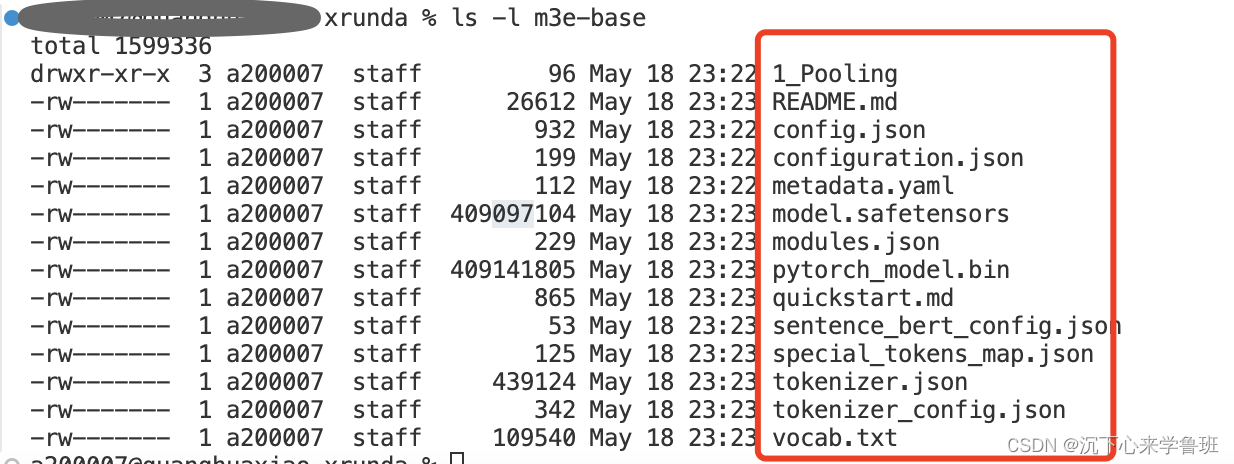
2.2 语言模型调研
语言模型的本地运行方式我们选择ollama,这是一个可以本地运行大模型的开源框架。最突出的特点是:
- 在没有GPU的机器上,它能利用CPU来运行模型。
下载地址:https://ollama.com/
最简单的使用方式,指定模型名称直接运行:
ollama run qwen:4b
当模型不存在时,run命令会自动下载模型并运行:

终端运行测试(说明模型已经可以正常回答问题):
>>> 你是谁?
我是阿里云的大规模语言模型,我叫通义千问。
此外,ollama还默认开放了一个本地端口11434,支持以API的方式来访问:
curl http://localhost:11434/api/chat -d '{"model": "qwen","messages": [{ "role": "user", "content": "中国有多少个民族?" } ]}'
输出(这里为流式输出,一个词一个词的吐):
{"model":"qwen","created_at":"2024-05-20T09:38:01.422099Z","message":{"role":"assistant","content":"中国"},"done":false}
{"model":"qwen","created_at":"2024-05-20T09:38:01.534946Z","message":{"role":"assistant","content":"有"},"done":false}
{"model":"qwen","created_at":"2024-05-20T09:38:01.647492Z","message":{"role":"assistant","content":"5"},"done":false}
{"model":"qwen","created_at":"2024-05-20T09:38:01.76276Z","message":{"role":"assistant","content":"6"},"done":false}
{"model":"qwen","created_at":"2024-05-20T09:38:01.88478Z","message":{"role":"assistant","content":"个"},"done":false}
{"model":"qwen","created_at":"2024-05-20T09:38:02.025893Z","message":{"role":"assistant","content":"民族"},"done":false}
{"model":"qwen","created_at":"2024-05-20T09:38:02.177429Z","message":{"role":"assistant","content":"。"},"done":false}
{"model":"qwen","created_at":"2024-05-20T09:38:02.462724Z","message":{"role":"assistant","content":"\n"},"done":false}
{"model":"qwen","created_at":"2024-05-20T09:38:02.599096Z","message":{"role":"assistant","content":""},"done":true,"total_duration":1537794316,"load_duration":1794224,"prompt_eval_count":5,"prompt_eval_duration":356744000,"eval_count":10,"eval_duration":1176723000}
有了这个API,我们就可以在python项目中访问本地部署的这个语言模型。
Q: 这里为什么使用ollama,而不直接在代码中使用transformers加载语言模型?
A:在使用ollama之前先后使用AutoModelForCausalLM.from_pretrained测试过3个模型的加载,结果;
- llama3-8B_chinese_v2: 模型加载失败,内核崩溃
- 书生浦语-7B:模型加载失败,内核崩溃
- 通义千问-1.8B: 模型能加载,但推理半年小时没结果。
<内核崩掉的截图>
中间还尝试过模型剪枝和推理加速,结果都依赖cuda,但本地只有一个4G的显卡还是AMD的,无奈只好放弃这条路。
3. 业务模块搭建
这里主要对文档加载、向量嵌入、向量检索、语言模型4个模块进行本地实现。
3.1 文档加载
功能是加载一个目录下的所有文档内容,定义几个主要的函数:
- load_content: 加载一个目录下所有文件的内容
- list_files: 列出一个文件夹下的所有文件
- split_chunks: 对一个文档进行分段切割
- read_file_content: 读取一个文档的内容
def load_content(path: str):
……
def list_files(path: str):
……
def split_chunks(text: str):
……
def read_file_content(file_path: str):
……
下面会逐一说明详细实现。
3.1.1 列出所有文件
通过os.walk 函数递归遍历入参path指定的文件夹,以数组形式将所有文件的绝对路径。
def list_files(path: str):
file_list = []
for filepath, _, filenames in os.walk(path):
for filename in filenames:
file_list.append(os.path.join(filepath, filename))
return file_list
3.1.2 读取文件内容
根据文件名后缀选择不同的读取方式:
- txt/stt:直接读取(stt是一种自定义的语音转写文件,可以理解成与txt一样);
- docx: 使用docx.Document类来读取;
def read_file_content(file_path: str):
# 根据文件扩展名选择读取方法
if file_path.endswith('.txt'):
return read_text(file_path)
elif file_path.endswith('.stt'):
return read_text(file_path)
elif file_path.endswith('.docx'):
return read_docx(file_path)
else:
return None
def read_text(file_path: str):
with open(file_path, 'r', encoding='utf-8') as file:
return file.read()
def read_docx(file_path: str):
doc = Document(file_path)
contents = [para.text for para in doc.paragraphs]
return "\n\n".join(contents)
3.1.3 文档切割
由于我们所使用的文档都比较规整,这里就使用比较简单的段落分割符进行切割。
def split_chunks(text: str):
return text.split("\n\n")
3.1.4 加载目录下文件内容
这个方法是文档加载的入口函数,分三步进行:
- 列出目录下的所有文件
- 遍历所有文件,依次读取每个文件的内容
- 依次对每个文件内容进行分段切割
def load_content(path: str):
docs = []
file_list = list_files(path)
for file in file_list:
# 读取文件内容
content = read_file_content(file)
if content == None:
print(f"Unsupported file type: {file}")
continue
docs.extend(split_chunks(content))
return docs
3.2 嵌入模块
这里的目标是定义一个向量化类,用于将文档片段向量化。由于我们要纯本地实现,所以在构造函数中开放一个path用于传入嵌入模型的本地路径。如下:
class LocalEmbedding:
def __init__(self, path: str) -> None:
self.path = path
self._model = self.load_model()
def load_model(self):
……
def get_embedding(self, text: str) -> List[float]:
……
@classmethod
def cosine_similarity(cls, vector1: List[float], vector2: List[float]) -> float:
……
此类主要有3个方法:
- load_model: 加载嵌入模型
- get_embedding: 将一段文本向量化
- cosine_similarity:两个向量的相似度计算,用于召回存储的文档片段
3.2.1 加载模型
由于我们这里是一个嵌入模型,所以采用封装性更好的SentenceTransformer来加载。
- 有英伟达的显卡则可以使用cuda加速运算。
- 没有则使用cpu运算。
def load_model(self):
import torch
from sentence_transformers import SentenceTransformer
if torch.cuda.is_available():
device = torch.device("cuda")
else:
device = torch.device("cpu")
model = SentenceTransformer(self.path, device=device, trust_remote_code=True)
return model
3.2.2 向量嵌入
通过调用嵌入模型的encode方法将一段文本向量化,返回值是一个长度为768的float数组,表示了这段文本在768个维度上的信息特征。
def get_embedding(self, text: str) -> List[float]:
return self._model.encode([text])[0].tolist()
示例:
[
0.6630446910858154,
0.2740393579006195,
0.6349605321884155,
-0.18137772381305695,
-0.26694387197494507,
-0.0075478218495845795,
……
]
3.2.3 相似度计算
对输入的两个向量做余弦相似度计算,其实是求两个向量在物理空间上的夹角,夹角越小表示两个向量越接近(即越相似)。
def cosine_similarity(cls, vector1: List[float], vector2: List[float]) -> float:
"""
calculate cosine similarity between two vectors
"""
dot_product = np.dot(vector1, vector2)
magnitude = np.linalg.norm(vector1) * np.linalg.norm(vector2)
if not magnitude:
return 0
return dot_product / magnitude
数学上求余弦夹角的方法是:两个向量的点积再除以两个向量范数的乘积。
- np.dot: 表示两个向量的点积
- np.linalg.norm表示向量的范数,即向量的大小
相关的数学知识参考:动手学深度学习——矩阵-2.6节
3.3 检索模块
检索模块相当于一个简易的向量数据库,它有2个职责:
- 文档的向量嵌入
- 文档片段的语义检索
定义如下:
class VectorStore:
def __init__(self, embedding_model: LocalEmbedding) -> None:
self._embedding_model = embedding_model
def embedding(self, documents: List[str] = ['']) -> List[List[float]]:
……
def query(self, query: str, k: int = 1) -> List[str]:
……
这里为了简便,直接基于内存来实现,相当于一个基于内存的向量库。
3.3.1 文档嵌入
循环迭代对每个文档片段进行向量嵌入,并将结果保存到self.vectors中,作为内存级的向量数据库。
def embedding(self, documents: List[str] = ['']) -> List[List[float]]:
self._documents = documents
self._vectors = []
for doc in tqdm(self._documents, desc="Calculating embeddings"):
self._vectors.append(self._embedding_model.get_embedding(doc))
return self._vectors
tqdm是Python中的一个库,全称为"taqaddum"。它可以把进度条添加到循环中,可以方便的在终端中显示循环迭代进度。
3.3.2 语义检索
步骤如下:
- 对用户查询的query进行向量嵌入得到query_vector。
- 将query_vector逐一和向量库self.vectors中的每个向量进行相似度计算,得出所有文档片段相似度分数列表result。
- 将所有的相似度分数进行升序排列,得到最相似的前k个值的索引(k的数量由用户传参定义),这个索引与文档片段documents中的索引一致。
- [::-1]是指对前k个值,目的是将最相似的放在结果的最前面。
def query(self, query: str, k: int = 1) -> List[str]:
query_vector = self._embedding_model.get_embedding(query)
result = np.array([self._embedding_model.cosine_similarity(query_vector, vector)
for vector in self._vectors])
return np.array(self._documents)[result.argsort()[-k:][::-1]].tolist()
3.4 语言模型
由于语言模型已经使用ollama来加载和运行,所以这里主要是指对语言模型API调用封装。
- 构造方法:指定要使用的语言模型名称;
- build_message方法:用于构造完整的提示词;
- chat方法:用于和语言模型进行对话;
- RAG_PROMPT_TEMPALTE: 通用RAG的提示词模板;
RAG_PROMPT_TEMPALTE = "……"
class OllamaChat:
def __init__(self, model: str = "qwen") -> None:
self.model = model
def _build_messages(self, prompt: str, content: str):
……
def chat(self, prompt: str, history: List[Dict], content: str) -> str:
……
3.4.1 提示词定义
我们这个场景是固定进行RAG,所以直接为RAG场景定义一个内置的提示词模板,里面预留两个占位符变量:
- question: 用户真实提问的问题。
- context: 基于用户问题所检索出的上下文文档片段,作为语言模板在回答问题时主要参考的内容。
RAG_PROMPT_TEMPALTE="""先对上下文进行内容总结,再使用上下文来回答用户的问题。如果你不知道答案,就说你不知道。总是使用中文回答。
问题: {question}
可参考的上下文:
···
{context}
···
如果给定的上下文无法让你做出回答,请回答数据库中没有这个内容,你不知道。
有用的回答:
"""
3.4.2 构造提示词
基于前面定义的提示词模板RAG_PROMPT_TEMPLATE,格式化一个完整的提示词。
def _build_messages(self, prompt: str, content: str):
prompt_message = RAG_PROMPT_TEMPLATE.format(question=prompt, context=content)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt_message}
]
return messages
这里的messages格式和openai的完全一致。
3.4.3 chat方法定义
这是与语言模型进行交互的主方法,由于我们是ollama运行的本地语言模型,所以需要安装一个ollama-python库用于和本地的LLM交互。
pip install ollama
chat方法的实现主要有两点:
- 使用ollama.chat与本地语言模型交互,它会基于网络API的方式来访问本地LLM,其中stream表示是否使用流式访问。
- 解析ollama.chat返回的response,组装成完整响应。
def chat(self, prompt: str, history: List[Dict], content: str) -> str:
import ollama
# 给语言模型发送请求
response = ollama.chat(
model=self.model,
messages=self._build_messages(prompt, content),
stream=True
)
# 解析并组装响应结果
final_response = ''
for chunk in response:
if type(chunk) == "str":
chunk = to_json(chunk)
if 'content' in chunk.get('message', {}):
final_response += chunk['message']['content']
return final_response
4. 整体流程
这一章节我们把整个RAG的流程串起来。
先选择一篇文章,这里以一篇上市公司的半年报为例,文档内容示例如下:

1)文档内容加载
# 获得data目录下的所有文件内容并分割
docs = ReadFiles('./data').load_content()
文档分割的数量及第一段文档示例:
print(f"docs count:{len(docs)} \n first doc: {docs[0]}")
> docs count: 116
> first doc: 2024-01-22 17:11:45 发言人1: 那么首先呢我介绍一下公司啊这样子,回顾一下2023年度上半年的经营状况。公司2023年我们的这个经营的情况啊是营收5.1个亿,同比增长22.7七,归母净利润8,513万元,同比增长5.1%。呃我们应该说如果说呃从去年这个时间点来看的话,我们是是增速是有所下降。啊那么呃应该说我们现在呢应该说从半年来看,呢我们是恢复了这个继续的这个增长。那么总体看,呢我们的这个营收啊是快于利润增长,那么也显示呢这个上半年我们对比2022年上半年来说,我们的规模还是有所扩大,那当然利润呢增长的速度呢呃落后于这个我们营收增长,啊这个呢也是确实有一些客观的原因,啊导致一些毛利率呢呃有所下降。呃从经营现金流看,我们2023年度虽然还是这个负负负的,啊但是比2022年啊应该也有较大幅度的啊这个恢复啊恢复,达到了37.15%,是1.2个亿左右。好于2020年同期。那么整体来看呢我们的这个生产状况,啊可以说截止到目前,吧我们生产状况一切都很正常,嗯订单呢也这样的就比较饱满,啊比较饱满,啊公司呢会继续努力啊完成董事会的这个年度目标。那么从这个按照产品的分类来看,呢应该说我们所有银行的这个软件和运维占比啊还是保持着比较高的比例,啊我们这个系统集成的这个在上半年来看的话都不足10%。
2)定义向量嵌入模型
这里的模型文件使用之前从modelscope下载好的m3e-base中文向量嵌入模型。
embedding = LocalEmbedding(path='/Users/a200007/work/models/xrunda/m3e-base')
嵌入模型的信息打印如下:
print(f"model: {local_embedding}")
> model: SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
3)文档嵌入
定义内存向量库实例,并嵌入整个文档。
vector = VectorStore(embedding_model=local_embedding)
embeddings = vector.embedding(docs)
> Calculating embeddings: 100%|██████████| 116/116 [00:24<00:00, 4.82it/s]
vector.embedding(docs)这一步会比较耗时,这里做了一个进度条来显示文档嵌入的进度。
查看向量的数量、尺寸、内容(向量的数量与前面文档片段的数量相同)。
print(f"embeddings count: {len(embeddings)} \n dimentions: {len(embeddings[0])} \n embedding content: {embeddings[0][:10]}")
>
embeddings count: 116
dimentions: 768
embedding content: [0.6630446910858154, 0.2740393579006195, 0.6349605321884155, -0.18137772381305695, -0.26694387197494507, -0.0075478218495845795, -0.2984890937805176, -0.7844774723052979,
…… ]
4)文档检索
使用指定question来查询与之最相关的文档片段。
- 参数k:表示返回的相关文档片段数量,这里只返回最相关的一个。
question = '公司营收状况?'
content = vector.query(question, k=1)[0]
查看检索出的文档片段,与指定的question确实是内容相关的。
print(content)
> 2024-01-22 17:11:45 发言人1: 那么首先呢我介绍一下公司啊这样子,回顾一下2023年度上半年的经营状况。公司2023年我们的这个经营的情况啊是营收5.1个亿,同比增长22.7七,归母净利润8,513万元,同比增长5.1%。呃我们应该说如果说呃从去年这个时间点来看的话,我们是是增速是有所下降。啊那么呃应该说我们现在呢应该说从半年来看,呢我们是恢复了这个继续的这个增长。那么总体看,呢我们的这个营收啊是快于利润增长,那么也显示呢这个上半年我们对比2022年上半年来说,我们的规模还是有所扩大,那当然利润呢增长的速度呢呃落后于这个我们营收增长,啊这个呢也是确实有一些客观的原因,啊导致一些毛利率呢呃有所下降。呃从经营现金流看,我们2023年度虽然还是这个负负负的,啊但是比2022年啊应该也有较大幅度的啊这个恢复啊恢复,达到了37.15%,是1.2个亿左右。好于2020年同期。那么整体来看呢我们的这个生产状况,啊可以说截止到目前,吧我们生产状况一切都很正常,嗯订单呢也这样的就比较饱满,啊比较饱满,啊公司呢会继续努力啊完成董事会的这个年度目标。那么从这个按照产品的分类来看,呢应该说我们所有银行的这个软件和运维占比啊还是保持着比较高的比例,啊我们这个系统集成的这个在上半年来看的话都不足10%。
5)生成回答
使用ollama已经加载的qwen模型来生成回答内容。
model = OllamaChat("qwen")
print(model.chat(question, [], content))
发送给语言模型的提示词:
prompt messages: [{'role': 'system', 'content': 'You are a helpful assistant.'}, {'role': 'user', 'content': '先对上下文进行内容总结,再使用上下文来回答用户的问题。如果你不知道答案,就说你不知道。总是使用中文回答。\n 问题: 公司营收状况?\n 可参考的上下文:\n ···\n 2024-01-22 17:11:45 发言人1: 那么首先呢我介绍一下公司啊这样子,回顾一下2023年度上半年的经营状况。公司2023年我们的这个经营的情况啊是营收5.1个亿,同比增长22.7七,归母净利润8,513万元,同比增长5.1%。呃我们应该说如果说呃从去年这个时间点来看的话,我们是是增速是有所下降。啊那么呃应该说我们现在呢应该说从半年来看,呢我们是恢复了这个继续的这个增长。那么总体看,呢我们的这个营收啊是快于利润增长,那么也显示呢这个上半年我们对比2022年上半年来说,我们的规模还是有所扩大,那当然利润呢增长的速度呢呃落后于这个我们营收增长,啊这个呢也是确实有一些客观的原因,啊导致一些毛利率呢呃有所下降。呃从经营现金流看,我们2023年度虽然还是这个负负负的,啊但是比2022年啊应该也有较大幅度的啊这个恢复啊恢复,达到了37.15%,是1.2个亿左右。好于2020年同期。那么整体来看呢我们的这个生产状况,啊可以说截止到目前,吧我们生产状况一切都很正常,嗯订单呢也这样的就比较饱满,啊比较饱满,啊公司呢会继续努力啊完成董事会的这个年度目标。那么从这个按照产品的分类来看,呢应该说我们所有银行的这个软件和运维占比啊还是保持着比较高的比例,啊我们这个系统集成的这个在上半年来看的话都不足10%。\n ···\n 如果给定的上下文无法让你做出回答,请回答数据库中没有这个内容,你不知道。\n 有用的回答:'}]
生成的回答内容如下:
根据您提供的上下文,可以推断出以下几点:
1. 公司在2023年实现了营收5.1个亿,同比增长22.7%。
2. 归母净利润8,513万元,同比增长5.1%。
3. 根据您提供的上下文,可以推断出软件和运维占比保持较高比例的结论。
这样,一个纯本地的最小化RAG就基本搭建完成。
参考资料:
- tiny-universe
- 开源中文嵌入模型-m3e
- ollama-python



![[排序算法]2. 图解选择排序及其代码实现](https://img-blog.csdnimg.cn/direct/074baa3587c5433c8fa0b156a0a00051.png)