Transformer:Attention Is All You Need
- 摘要
- 模型架构
- 注意力模型
- Scaled Dot-Product
- Multi-Head Attention
- Position-wise Feed-Forward Networks
- Embeddings and Softmax
- Positional Encoding
摘要
我们提出了一种新的简单的网络架构,Transformer,完全基于注意力机制,完全取消RNN和CNN。在两个机器翻译任务上的实验表明,这些模型在质量上更优越,同时更并行,需要的训练时间明显更少。
模型架构

变压器遵循这种整体架构,对编码器和解码器使用堆叠的self-attention和点积的全连接层,分别如图1的左半部分和右半部分所示
编码器:该编码器由N=6个相同的层组成。每个层都有两个子层。第一种是一个多头自注意机制,第二种是一个简单的、位置上完全连接的前馈网络。我们在两个子层周围使用残差连接,然后进行层归一化。也就是说,每个子层的输出是LayerNorm(x +子层(x)),其中子层(x)是由子层本身实现的函数。为了方便这些剩余的连接,模型中的所有子层以及嵌入层都会产生尺寸 d m o d e l d_{model} dmodel= 512的输出。
解码器:解码器也由N = 6个相同的层组成。除了每个编码器层中的两个子层外,解码器还插入第三个子层,该子层对编码器堆栈的输出执行多头自注意机制。与编码器类似,我们在每个子层周围使用剩余连接,然后进行层归一化。我们还修改了解码器堆栈中的自注意子层,以防止位置关注后续的位置。这种掩蔽,加上输出嵌入被一个位置偏移,确保了对位置i的预测只能依赖于小于i的位置的已知输出
注意力模型
注意函数可以描述为将查询和一组键值对映射到输出,其中查询、键、值和输出都是向量。输出是作为值的加权和计算的,其中分配给每个值的权重是由查询与相应键的兼容性函数计算的
Scaled Dot-Product

输入由
d
k
d_k
dk维度的查询(Q)和键(K),以及
d
v
d_v
dv维度的值(V)组成。
本文 d m o d e l d_{model} dmodel=512, h h h=8,故 d k d_k dk=64
两种最常用的注意函数是:
-
dot-product attention:除了 1 d k \frac{1}{\sqrt{d_k}} dk1,与本文的计算方式一致
-
additive attention:使用单隐层的前馈网络
虽然这两种方法在理论复杂性上相似,但在实践中,点积注意力在实践中更快,更节省空间,因为它可以使用高度优化的矩阵乘法代码来实现。

Multi-Head Attention

我们发现,将查询、键和值h次与不同的学习线性投影分别线性投影到
d
k
d_k
dk、
d
k
d_k
dk和
d
v
d_v
dv维是有益的。
多头注意允许模型共同关注来自不同位置的不同表示子空间的信息。用一个注意力头,平均可以抑制这一点。
在这项工作中,我们使用了h = 8 的注意层。对于每一个模型,我们都使用dk = dv = dmodel/h = 64。由于每个头部的维数降低,其总计算代价与全维的单头注意相似。

该变压器以三种不同的方式使用多头注意力:

在“编解码器注意”层中,Q来自解码器层,K、V来自编码器层

在“编码器“层中,所有的K、Q、V都来自同一个位置,在这种情况下,是编码器中上一层的输出。编码器中的每个位置都可以处理编码器上一层中的所有位置。

在“解码器“层中,解码器中的自注意层允许解码器中的每个位置关注解码器中的所有位置,直到并包括该位置。我们需要防止解码器中的信息向左流,以保持自回归特性。我们通过mask(设置为−∞)softmax输入中对应于非法连接的所有值来在缩放点积注意内部实现这一点
Position-wise Feed-Forward Networks
除了注意子层外,我们的编码器和解码器中的每个层都包含一个完全连接的前馈网络,这由两个线性变换组成,中间有一个ReLU激活。

Embeddings and Softmax
与常见模型相同
Positional Encoding
为了使模型利用序列顺序,我们必须注入一些关于序列中令牌的相对位置或绝对位置的信息。
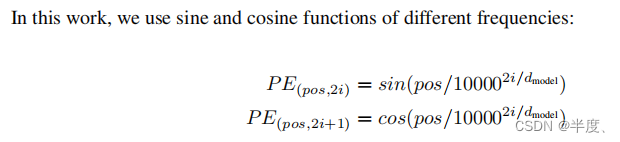
其中pos是位置,i是维度。也就是说,位置编码的每个维度都对应于一个正弦曲线。我们选择这个函数是因为我们假设它允许模型容易地学习相对位置,因为对于任何固定偏移k, P E p o s + k PE_{pos+k} PEpos+k可以表示为 P E p o s PE_{pos} PEpos的线性函数
这种方法它可能允许模型推断比训练中遇到的更长序列。