目录
一、什么是Elasticsearch
二、安装Elasticsearch
三、配置es
四、启动es
1、下载安装elasticsearch的插件head
2、在浏览器,加载扩展程序
3、运行扩展程序
4、输入es地址就可以了
五、Elasticsearch 创建、查看、删除索引、创建、查看、修改、删除文档、映射关系
1、索引操作
1.1、创建索引
1.2、查看指定索引
1.3、查看全部索引 _cat/indices?v
1.4、删除索引
2、文档操作
2.1、创建文档
2.2、查询单个文档:主键id查询
2.3、查看所有文档:全量查询
2.4、修改文档中的全部字段
2.5、修改文档某一个字段
2.6、条件查询文档内容
2.7、分页查询和排序文档内容
2.8、多条件查询 and
2.9、多条件查询 or
2.10、多条件查询 :大于 小于
2.11、聚合查询 根据价格分组、对价格求平均值
3、映射操作
六、创建分片索引
七、故障转移
八、水平扩容
一、什么是Elasticsearch
是一个高度可扩展的开源全文搜索和分析引擎,它可实现数据的实时全文搜索搜索、支持分布式可实现高可用、提供API接口,可以处理大规模日志数据,比如:Nginx 、Tomcat、系统日志等功能 。
bin 可执行脚本目录
config 配置目录
jdk 内置 JDK 目录(ES是采用Java语言开发的)
lib 类库
logs 日志目录
modules 模块目录
plugins 插件目录
解后,进入 bin 文件目录,点击 elasticsearch.bat 文件启动 ES 服务。
二、安装Elasticsearch
1、下载es安装包
https://www.elastic.co/cn/downloads/past-releases#elasticsearch
2、使用rz命令上传至服务器别解压
3、使用tcp命令传值另外两个服务器
4、创建es用户
useradd elasticsearch
5、创建数据目录
[root@rabbitmq_2 es]# mkdir es_data
6、创建日志目录
[root@rabbitmq_2 es]# mkdir es_log
7、配置elasticsearch文件权限
chown -R elasticsearch:elasticsearch /home/es/elasticsearch-7.8.0
chown -R elasticsearch:elasticsearch /home/es/es_data
chown -R elasticsearch:elasticsearch /home/es/es_log
6、出现这个错误 max virtual memory areas vm.max_map_count [65530] is too low,
vim /etc/sysctl.conf
添加这个,保存退出,刷新
vm.max_map_count=262144
[root@rabbitmq_2 es]# sysctl -p
vm.max_map_count = 262144
8、这个错误 max file descriptors [4096] for elasticsearch process is too low
vim /etc/security/limits.conf
# End of file
elasticsearch soft nofile 65535
elasticsearch hard nofile 65535
保存退出三、配置es
[elasticsearch@rabbitmq_1 config]$ vim elasticsearch.yml
cluster.name: my-application
node.name: node-1
node.master: true //当前节点可以是master节点、也可以是数据节点
node.data: true
path.data: /home/es/es_data
path.logs: /home/es/es_log
network.host: 0.0.0.0
http.port: 9200
//用来查找集群节点的模块
discovery.seed_hosts: ["192.168.134.132", "192.168.134.133"]
// 集群内可以被选为主节点的节点列表
cluster.initial_master_nodes: ["node-1"]
//跨域配置
http.cors.enabled: true
http.cros.allow-origin: "*"如果是ES集群的话,只需要把边配置文件scp到其他节点即可
[elasticsearch@rabbitmq_1 config]$ vim elasticsearch.yml
cluster.name: my-application
node.name: node-2
node.master: true //当前节点可以是master节点、也可以是数据节点
node.data: true
path.data: /home/es/es_data
path.logs: /home/es/es_log
network.host: 0.0.0.0
http.port: 9200
//用来查找集群节点的模块,节点发现,有几个机器就写几个
discovery.seed_hosts: ["192.168.134.132", "192.168.134.133"]
// 集群内可以被选为主节点的节点列表
cluster.initial_master_nodes: ["node-1"]
//跨域配置
http.cors.enabled: true
http.cros.allow-origin: "*"四、启动es
因为安全问题,es不允许使用root 启动,所以需要创建es用户
useradd elasticsearch //创建用户
passwd 123456 //设置密码
//授权
chown -R elasticsearch:elasticsearch /path/to/elasticsearch
//切换用户
su - elasticsearch
[root@rabbitmq_2 bin]# sudo -u elasticsearch ./elasticsearch
[elasticsearch@rabbitmq_1 bin]$ ./elasticsearch
后台启动 街上 -d
有这一行表示启动成功
[node-1] Active license is now [BASIC]; Security is disabled
[elasticsearch@rabbitmq_1 bin]$ ./elasticsearch -d
然后去浏览器查看
http://192.168.134.132:9200/
{
"name" : "node-1",
"cluster_name" : "my-application",
"cluster_uuid" : "VI1zyRs3TRu3MDBGxrPh5w",
"version" : {
"number" : "7.8.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "757314695644ea9a1dc2fecd26d1a43856725e65",
"build_date" : "2020-06-14T19:35:50.234439Z",
"build_snapshot" : false,
"lucene_version" : "8.5.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
监控elasticsearch集群服务器的健康性
用curl命令对集群的健康性状态进行检查,如果返回值是green,说明正常,是yellow,说明是副本的分片丢失,如果是red,表示主片丢失。
[elasticsearch@rabbitmq_1 es_data]$ curl -sXGET http://192.168.134.132:9200/_cluster/health?pretty=true
{
"cluster_name" : "my-application",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}1、下载安装elasticsearch的插件head
地址:https://github.com/mobz/elasticsearch-head/raw/master/crx/es-head.crx
将下载好的es-head.crx 改为 es-head.rar,然后解压,解压后的目录
2、在浏览器,加载扩展程序

3、运行扩展程序
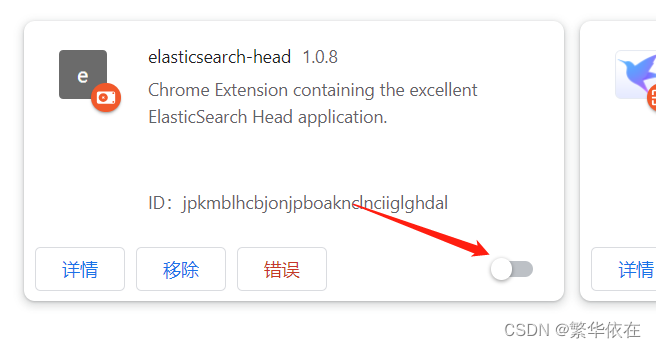
4、输入es地址就可以了
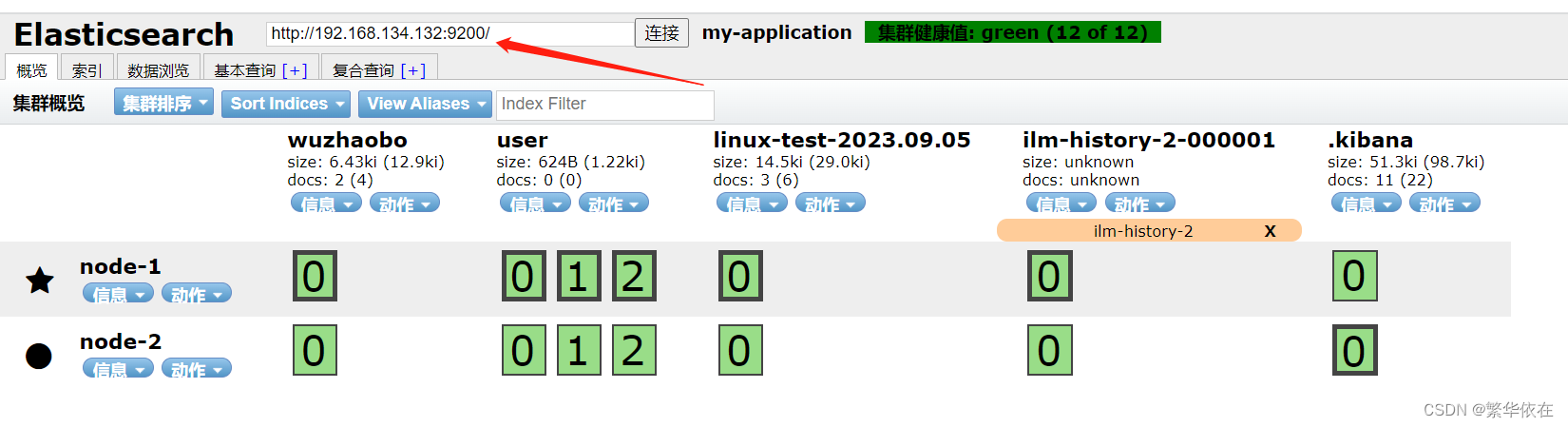
五、Elasticsearch 创建、查看、删除索引、创建、查看、修改、删除文档、映射关系
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。为了方便大家理解,我们将 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比。
ES 里的 Index 可以看做一个库,而 Types 相当于表,Documents 则相当于表的行。这里 Types 的概念已经被逐渐弱化,Elasticsearch 6.X 中,一个 index 下已经只能包含一个 type,Elasticsearch 7.X 中, Type 的概念已经被删除了。
索引的精髓:一切设计为了提高搜索性能
1、索引操作
1.1、创建索引
在ES中创建一个索引,就相当于在mysql中创建了一个数据库,而mysql中的数据库肯定是不能重复的,也即ES中的索引也不能重复,所以这是一个幂等性操作,需要发送PUT请求(如果重复发送PUT请求、重复添加索引,会返回错误信息),这里不能发送POST请求。

1.2、查看指定索引
在postman中,向ES服务器发送GET请求。这里的路径和上边的创建索引是一样的,只是请求方式不一样
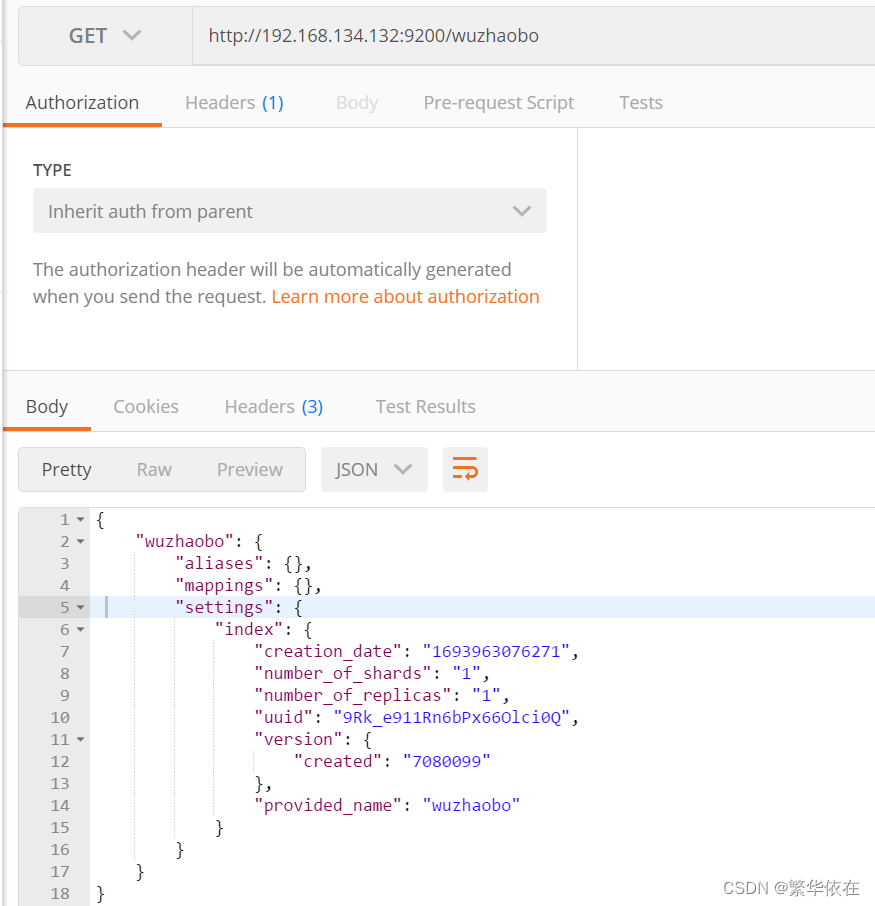
1.3、查看全部索引 _cat/indices?v
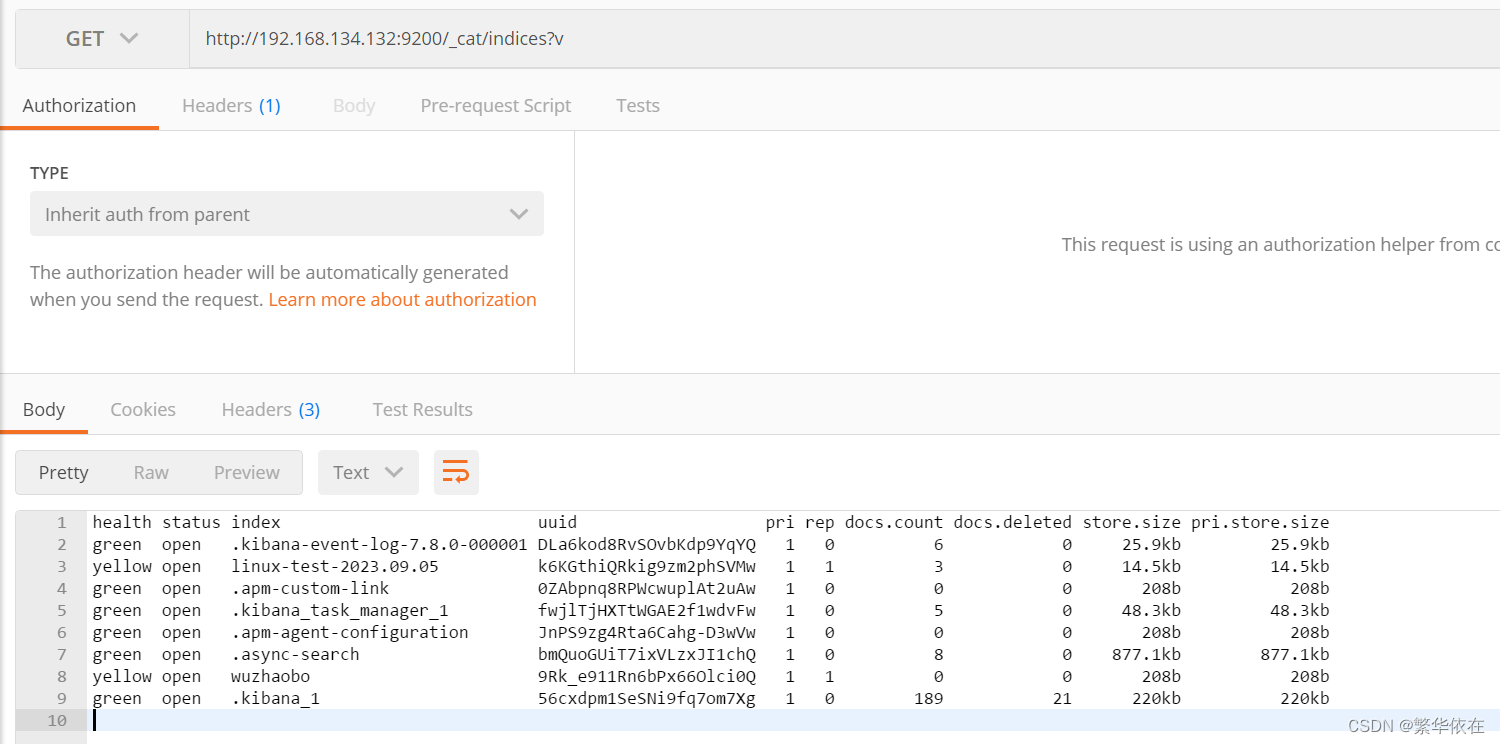
在 Postman 中,向 ES 服务器发 GET 请求。
http://192.168.134.132:9200/_cat/indices?v
health 当前服务器健康状态:green(集群完整) yellow(单点正常、集群不完整) red(单点不正常)
status 索引打开、关闭状态
index 索引名
uuid 索引统一编号
pri 主分片数量
rep 副本数量
docs.count 可用文档数量
docs.deleted 文档删除状态(逻辑删除)
store.size 主分片和副分片整体占空间大小
pri.store.size 主分片占空间大小
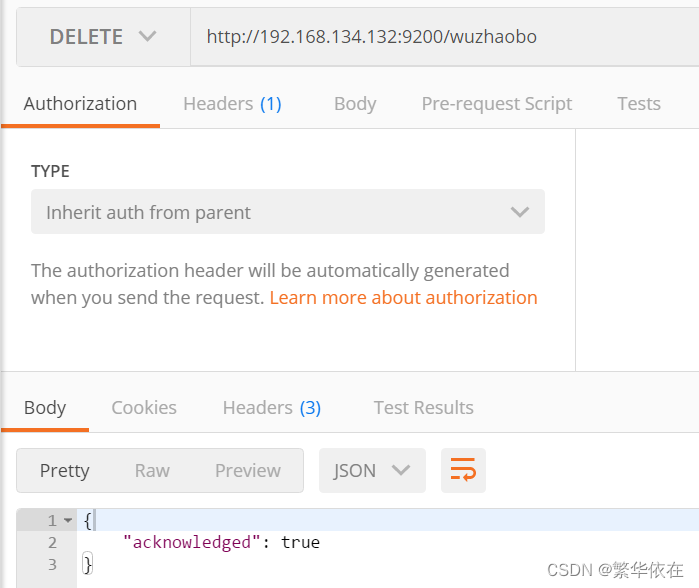
1.4、删除索引
在 Postman 中,向 ES 服务器发 DELETE 请求。
2、文档操作
2.1、创建文档
索引已经创建好了,接下来我们来创建文档,并添加数据。这里的文档可以类比为关系型数据库中的表数据,添加的数据格式为 JSON 格式 。在 Postman 中,向 ES 服务器发 POST 请求。
http://192.168.134.132:9200/wuzhaobo/_doc
请求体
{
"title":"小米手机",
"category":"小米",
"image":"http://www.szh.com/szh.jpg",
"price":3999.00
}
返回
{
"_index": "wuzhaobo",
"_type": "_doc",
"_id": "7E4haIoB8mJ8_ZzJqBEe",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
上面的数据创建后,由于没有指定数据唯一性标识(ID),默认情况下,ES 服务器会随机生成一个。
如果想要自定义唯一性标识,需要在创建时指定。推荐使用下面这种方式创建文档。
http://192.168.134.132:9200/wuzhaobo/_doc/1002
请求体和不变2.2、查询单个文档:主键id查询
查看文档时,需要指明文档的唯一性标识,类似于 MySQL 中数据的主键查询。在 Postman 中,向 ES 服务器发 GET 请求。
请求地址:http://192.168.134.132:9200/wuzhaobo/_doc/1002
返回:
{
"_index": "wuzhaobo",
"_type": "_doc",
"_id": "1002",
"_version": 1,
"_seq_no": 1,
"_primary_term": 1,
"found": true,
"_source": {
"title": "小米手机",
"category": "小米",
"image": "http://www.szh.com/szh.jpg",
"price": 3999
}
}2.3、查看所有文档:全量查询
"query":这里的query代表一个查询对象,里边有不通的查询属性
"match_all":查询类型,例如:match_all(代表查询所有),match、term、range等等
1、查询所有文档
GET 请求地址:http://192.168.134.132:9200/wuzhaobo/_search
"hits": [
{
"_index": "wuzhaobo",
"_type": "_doc",
"_id": "7E4haIoB8mJ8_ZzJqBEe",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"image": "http://www.szh.com/szh.jpg",
"price": 3999
}
},
{
"_index": "wuzhaobo",
"_type": "_doc",
"_id": "1002",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"image": "http://www.szh.com/szh.jpg",
"price": 3999
}
}
]2.4、修改文档中的全部字段
修改数据时,也可以只修改某一给条数据的局部信息,也可以修改所有字段信息。
修完完之后,再次发送GET请求,查看修改后的文档内容。
PUT 请求地址:http://192.168.134.132:9200/wuzhaobo/_doc/1002
请求体
{
"title":"华为手机",
"category":"华为",
"images":"http://www.szh.com/szh.jpg",
"price":2400.00
}
返回
{
"_index": "wuzhaobo",
"_type": "_doc",
"_id": "1002",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}2.5、修改文档某一个字段
使用post请求:http://192.168.134.132:9200/wuzhaobo/_doc/1002
请求体
{
"title":"苹果手机",
"category":"苹果",
}2.6、条件查询文档内容
http://192.168.134.132:9200/wuzhaobo/_search?q=category:苹果
上边这个容易乱码,建议使用请求体查询
GET请求地址:http://192.168.134.132:9200/wuzhaobo/_search
请求体:
{
"query" :{
"match" : {
"category" : "苹果"
}
}
}
2.7、分页查询和排序文档内容
默认情况下,Elasticsearch 在搜索的结果中,会把文档中保存在_source 的所有字段都返回。
如果我们只想获取其中的部分字段,我们可以添加_source 的过滤
sort 可以让我们按照不同的字段进行排序,并且通过 order 指定排序的方式。desc 降序,asc 升序。
from:当前页的起始索引,默认从 0 开始。 // (页码-1)*每页条数, 第一页:(1-1)*2=0, 第二页:(2-1)*2=2
size:每页显示多少条。
GET 请求地址:http://192.168.134.132:9200/wuzhaobo/_search
请求体
{
"query" :{
"match_all" : {
}
},
"from" : 0, //分页,
"size" : 2,
"_source" : ["title","price"], //过滤 只显示这两个参数
"sort" : { //排序
"price" : {
"order" : "desc"
}
}
}
2.8、多条件查询 and
bool把各种其它查询通过must(必须 and )、must_not(必须不)、should(应该 or)的方式进行组合 。
GET请求地址:http://192.168.134.132:9200/wuzhaobo/_search
请求体:
{
"query" :{
"bool" : {
"must" : [
{
"match" : {
"category" : "小米"
}
},
{
"match" : {
"price": 3999
}
}
]
}
}
}2.9、多条件查询 or
bool把各种其它查询通过 must(必须 and )、must_not(必须不)、should(应该 or)的方式进行组合 。
GET请求地址:http://192.168.134.132:9200/wuzhaobo/_search
请求体:
{
"query" :{
"bool" : {
"should" : [
{
"match" : {
"category" : "小米"
}
},
{
"match" : {
"price": 3999
}
}
]
}
}
}2.10、多条件查询 :大于 小于
range 查询找出那些落在指定区间内的数字或者时间。range 查询允许以下字符:
gt 大于> gte 大于等于 >= lt 小于 < lte 小于等于 <=
请求地址:http://192.168.134.132:9200/wuzhaobo/_search
请求体:
{
"query" :{
"bool" : {
"must" : [
{
"match" : {
"category" : "小米"
}
}
],
"filter" : { //过滤
"range" : {
"price" : {
"gt" : 3000,
"lt" : 4000
}
}
}
}
}
}2.11、聚合查询 根据价格分组、对价格求平均值
对某个字段取最大值 max
对某个字段取最小值 min
对某个字段求和 sum
对某个字段取平均值 avg
对某个字段的值进行去重之后再取总数 distinct
分组
{
"aggs" : { //聚合操作
"price_group" : { //名称,自定义
"terms" : { //分组、关键字
"field" : "price" //分组字段
}
}
},
"size" : 0
}
价格平均值
{
"aggs" : {
"fenzu" : {
"avg" : {
"field" : "price"
}
}
},
"size" : 0
}
价格最大值
{
"aggs" : {
"fenzu" : {
"max" : {
"field" : "price"
}
}
},
"size" : 0
}
3、映射操作
有了索引库,等于有了数据库中的 database。
接下来就需要建索引库(index)中的映射了,类似于数据库(database)中的表结构(table)。创建数据库表需要设置字段名称,类型,长度,约束等;索引库也一样,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做映射(mapping)。
字段名:任意填写,下面指定许多属性,例如:title、subtitle、images、price
type:类型,Elasticsearch 中支持的数据类型非常丰富,说几个关键的:
String 类型,又分两种:
text:可分词
keyword:不可分词,数据会作为完整字段进行匹配
Numerical:数值类型,分两类
基本数据类型:long、integer、short、byte、double、float、half_float
浮点数的高精度类型:scaled_float
Date:日期类型
Array:数组类型
Object:对象
index:是否索引,默认为 true,也就是说你不进行任何配置,所有字段都会被索引。
true:字段会被索引,则可以用来进行搜索
false:字段不会被索引,不能用来搜索
store:是否将数据进行独立存储,默认为 false
原始的文本会存储在_source 里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source 里面提取出来的。当然你也可以独立的存储某个字段,只要设置"store": true 即可,获取独立存储的字段要比从_source 中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置
analyzer:分词器,这里的 ik_max_word 即使用 ik 分词器
首先是 http://127.0.0.1:9200/user ,发送PUT请求,创建一个user索引,然后在这个索引下创建一个映射。
就类似于在mysql中创建一个名为 user 的数据库,在这个数据库中定义一张表的结构如下:👇👇👇
text 类型为true表示 name 字段可以支持 分词、拆解 操作的查询;而 keyword 类型为true表示 sex 字段仅支持完全匹配的模式;最后 keyword 类型为false表示 tel 字段不支持查询。
1、先创建一个索引
PUT请求地址:http://192.168.134.132:9200/user
然后在索引下创建映射
POST地址:http://192.168.134.132:9200/user/_mapping
{
"properties" : {
"name" : {
"type" : "text",
"index" : true
},
"sex" : {
"type" : "keyword",
"index" : true
},
"tel" : {
"type" : "keyword",
"index" : false
}
}
}
返回 :
{
"acknowledged": true
}
索引有了,映射也有了(数据库有了,表结构有了,就差向表中添加数据了),也就是需要添加文档内容。
post请求地址:http://192.168.134.132:9200/user/_doc/1001
请求体:
{
"name" : "吴兆波",
"sex" : "man",
"tel" : "11111111"
}
查询:get 请求地址:http://192.168.134.132:9200/user/_doc/1001
{
"_index": "user",
"_type": "_doc",
"_id": "1001",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"name": "吴兆波",
"sex": "man",
"tel": "11111111"
}
}
因为name字段是支持text模式查询,即支持分词、拆解操作,做倒排索引,所以虽然文档中的name字段为张起灵,但是经过分词拆解,name为徐、凤、年、凤年 这几种都可以查询出数据。
查询:get 请求地址:http://192.168.134.132:9200/user/_doc/1001
{
"query" : {
"match" : {
"name" : "兆"
}
}
}
由于 sex 字段不支持text分词拆解,仅支持keyword完全匹配的模式,所以源文档数据中 sex 为 man,这里只写个 m 是查询不到的。
最后的tel字段是最苛刻的,压根不支持text、keyword两种查询,所以这里就算是写成和文档中的 tel 一样,也查询不到,因为 tel 字段不支持查询。六、创建分片索引
PUT请求地址:http://192.168.134.132:9200/user
请求体
{
"settings" : {
"number_of_shards" : "3", //3个分片
"number_of_replicas" : "1" // 1个副本
}
}
返回:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "user"
}
去kibana 浏览器,就能看到创建的这个索引七、故障转移
因为在master上创建分片索引和副本之后,没有分配到其他节点,如果master宕机,存在数据丢失风险,所以需要启动节点2,副本会自动转移到节点2上,实现了故障转移
八、水平扩容
如果在使用过程中,容量不够了,就需要扩容,来启动节点3,
原则就是:1、主和副本是不能放在一起的 2、一定要保证均匀、让每个节点都能均匀的得到请求和访问
node1和node2上各有1个分片被迁移到node3上,现在每个节点都有2个分片,这样性能也得到了提升

![子比主题ACG美化插件[全开源]](https://img-blog.csdnimg.cn/direct/62c497bc5f044c7293552bf99ebdd8ae.jpeg#pic_center)