送给大家一句话:
人要成长,必有原因,背后的努力与积累一定数倍于普通人。所以,关键还在于自己。 – 杨绛
从零开始认识进程间通信
- 1 为什么要进程间通信
- 2 进程如何通信
- 3 进程通信的常见方式
- 4 管道
- 4.1 什么是管道
- 4.2 管道通信的系统调用
- 4.3 小试牛刀
- 5 总结
- Thanks♪(・ω・)ノ谢谢阅读!!!
- 下一篇文章见!!!
1 为什么要进程间通信
以前我们学习的过程中,进程是具有独立性的。但有些时候需要多个进程进行协同,这时候就需要进程间的通信来保证信息的互通。
就比如学校就分有教务处 , 学生处,教研组,班主任等部分。如果学校想要组织一场考试,就通知教务处安排好考场和监考员,告诉教研组老师需要出卷子,等教务处与教研组完成对应工作再告知学生处和班主任,然后通知学生进行考试,班主任和学生处做好考试监督工作。
这里面就少不了沟通交流,传递信息。进程工作也是这样:进程的协同工作需要一个前提提交——通信。通信就是传递数据,控制相关信息
2 进程如何通信
首先 , 我们知道进程是具有独立性的,一个进程的状态不会影响其他进程的运行。而独立性的本质是进程 = 内核数据结构 + 代码和数据 ,内核数据结构PCB是独立的,代码和数据是独立的 , 进程自然就是独立的。
所以,进程间通信的成本的成本稍微高一些,因为进程本身是独立的,两个进程天然是无法进行数据共享的!
可是子进程建立的时候不是会拷贝(继承)一份父进程的数据吗,这不是进行通信吗???
这就要我们明确区分两个概念:能通信与可以一直通信是不一样的。子进程继承的父进程数据是只读的,而且只进行一次。而一直通信是时不时就“打个电话”。
所以进程间通信的前提是:先让不同的进程看到同一份(操作系统)资源(“一段内存”)。
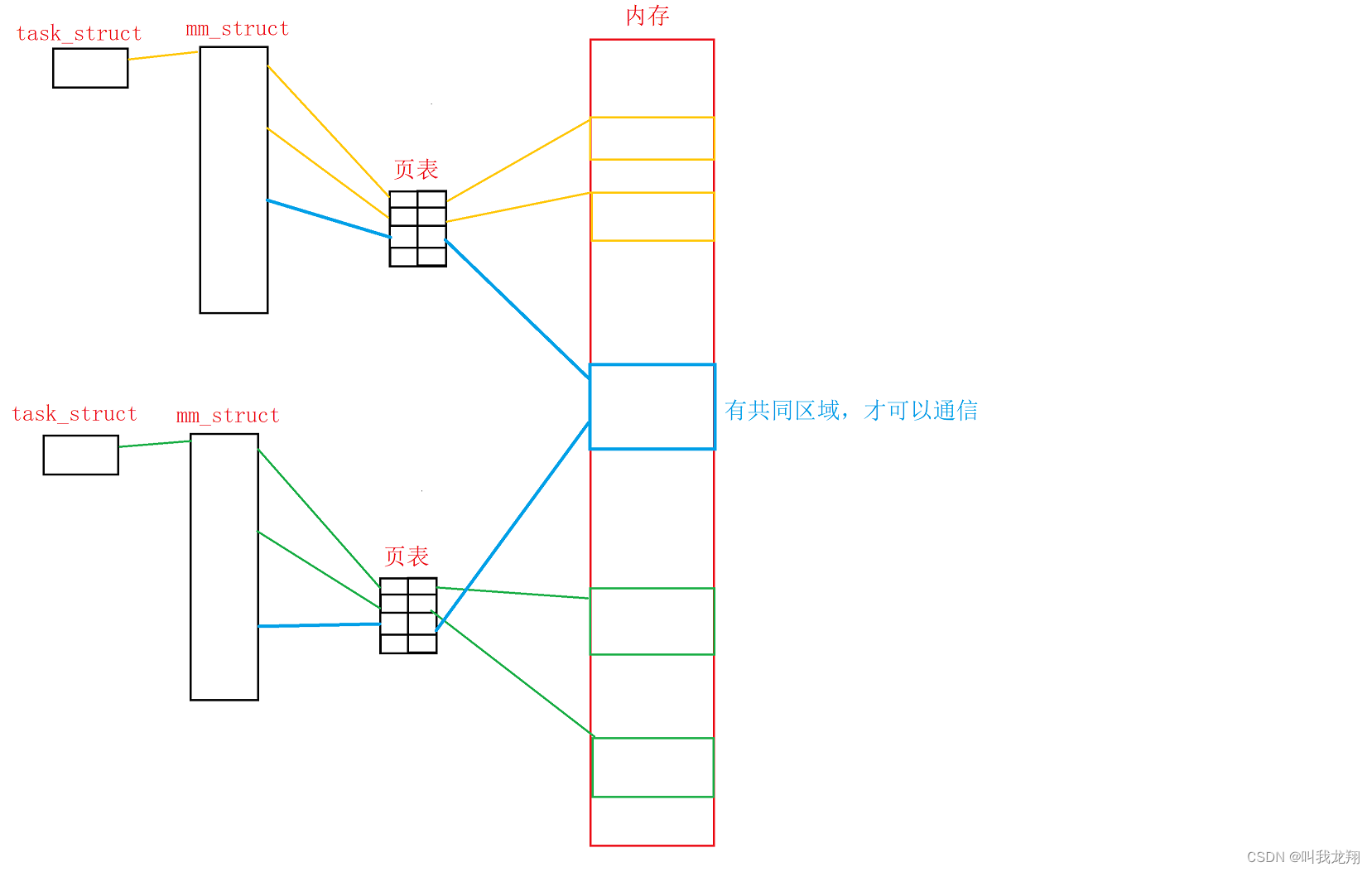
- 首先,一定是某一个进程先需要通信,让OS创建一个共享资源
- 那么OS必须通过对应的系统调用来创建共享资源
- OS创建的共享资源的不同 , 系统调用接口的不同----就导致进程间通信会有不同的种类
3 进程通信的常见方式
一般通信有以下种类:
- 管道
- 匿名管道pipe
- 命名管道
- System V IPC 标准 (早期的本地通信)
- System V 消息队列
- System V 共享内存
- System V 信号量
- POSIX IPC 标准(现代版本)
- 消息队列
- 共享内存
- 信号量
- 互斥量
- 条件变量
- 读写锁
今天来讲解管道
早期的时候,程序员们面对通信的需求时,不想再单独设计一个通信模块,直接复用内核级代码,就产生了管道!!!管道分为命名管道和匿名管道。
4 管道
4.1 什么是管道
【Linux】 拿下 系统 基础文件操作!!!
【Linux】开始了解重定向
这两篇文章了我们讲解了文件的底层,知道每一个进程都有对应的文件管理结构体,文件管理结构体中有管理已经打开文件的数组。数组下标为文件描述符,指向文件结构体,而文件结构体又会指向文件真正属性inode。
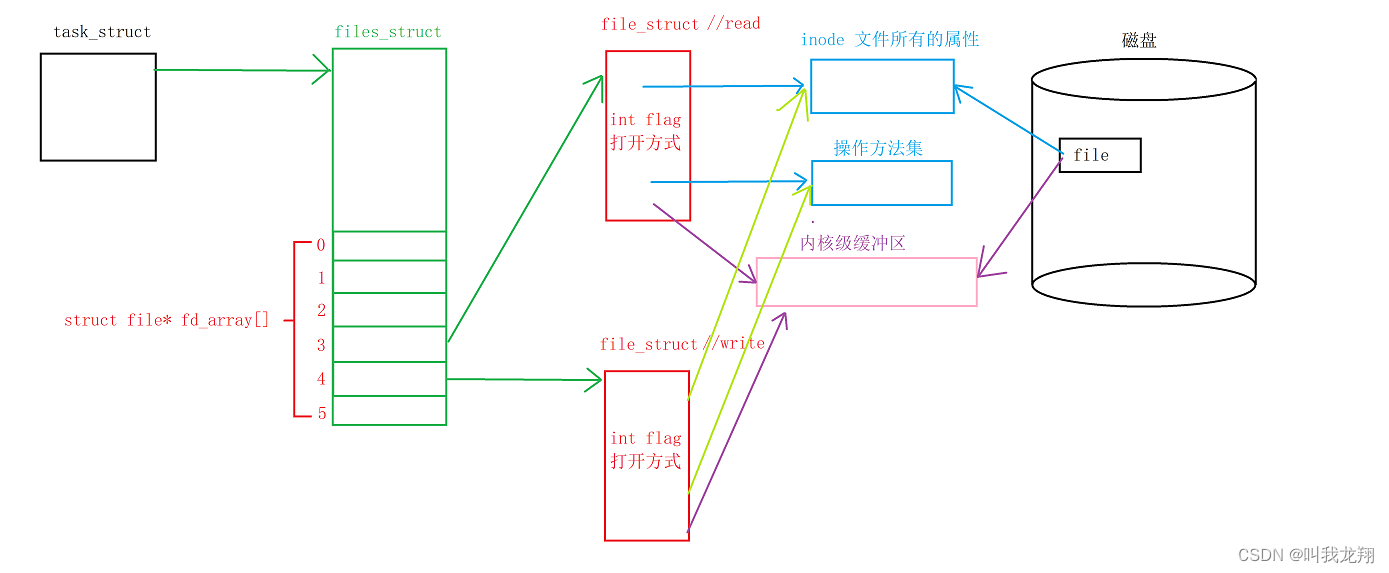
当我们以不同方式打开文件时,只需要在内存中加载一份数据(通过引用计数来管理),以读写方式打开,便会有两个对应的文件结构体。他们共同使用一份代数据,那自然就使用同一个内核级缓冲区。
那么为了要通信,不用在写一个新的模块,直接建立一个子进程来通信多简单。子进程会以父进程为模版进行写时拷贝。
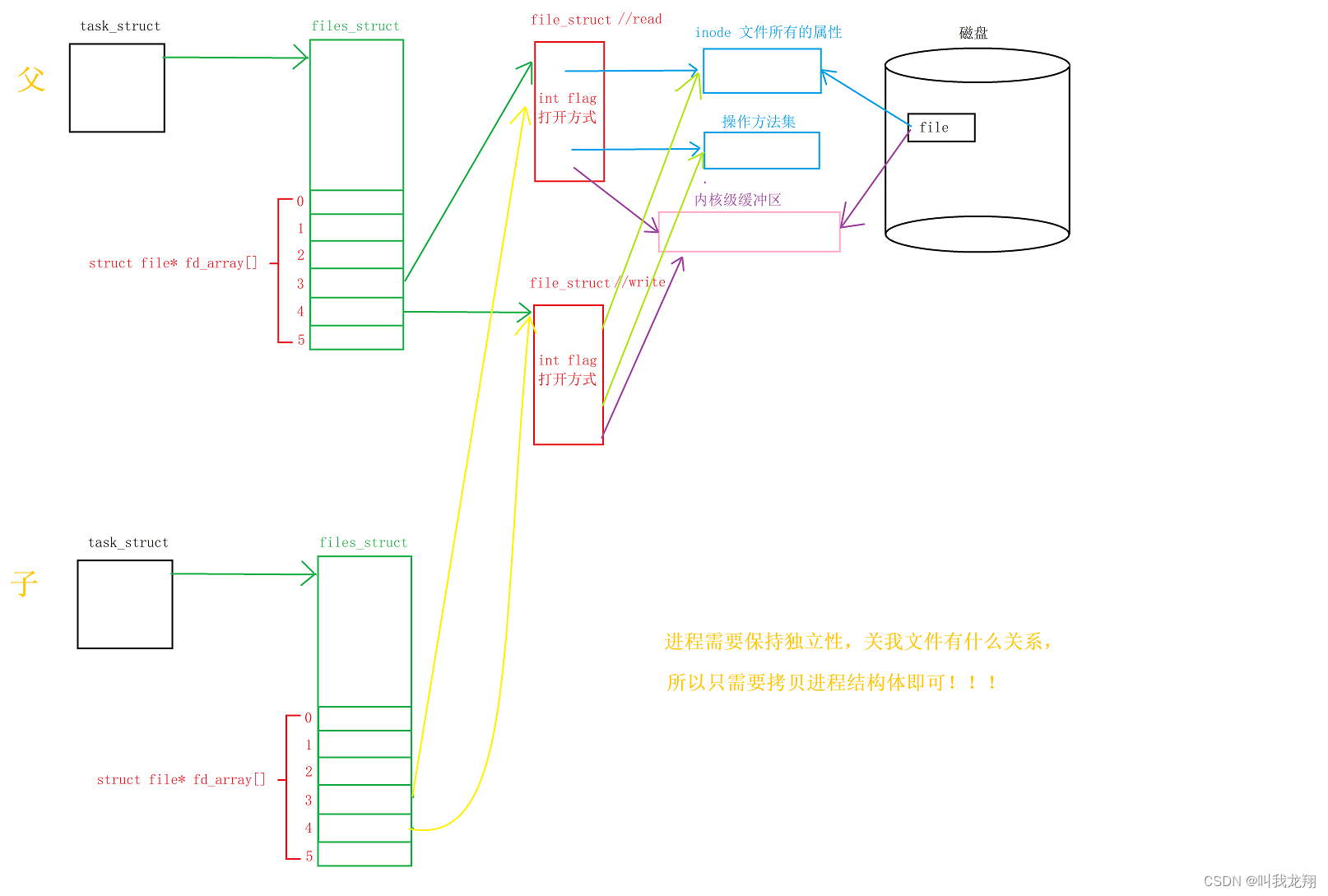
进行拷贝的只有进程对应的结构体,因为进程具有独立性,而文件系统我们可没提过什么对立性,所以文件管理数组进行浅拷贝,同样指向原先的文件结构体。
这时也就理解为什么父子进程会向同一块显示器终端打印数据了。
也理解为什么进程会默认打开012三个标准输入输出:因为所有进程都是bash的子进程,而bash打开了这三个文件,所以自然就打开了!!!
子进程要主动close(0 / 1 /2)不影响父进程继续使用显示器文件!只有引用计数(类似硬链接数)归零才会清理数据
今天我们进行进程间通信的前提——先让不同的进程看到同一份(操作系统)资源,不就解决了吗!!!
文件的内存缓冲区不就是两个进程共享的一份资源吗!而所谓的管道文件就是这个文件缓冲区!
但是呢,管道只允许进行单向通信(父->子 或 子->父),因为管道如果允许父子进程都可以写,就会导致数据紊乱!进行通信的时候,每个进程关闭不需要的文件描述符,然后通过缓冲区来单向通信。一个进程把信息写入缓冲区,另一个进程从缓冲区读取数据,不需要刷新到硬盘,直接从内存进行操作!
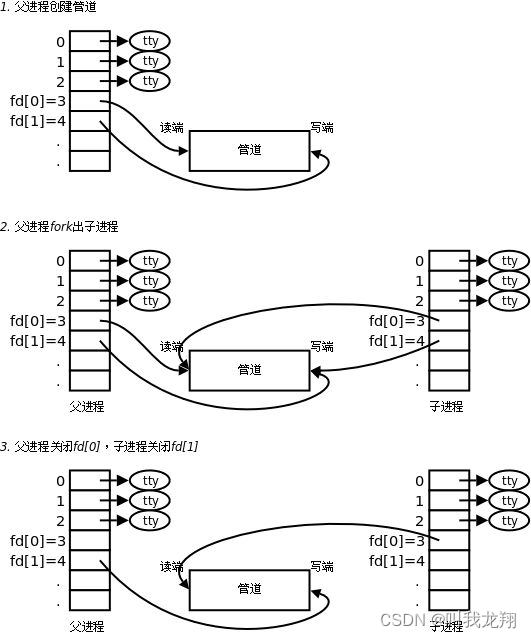
有个问题:父子既然要关闭不需要的fd那为什么曾经还要打开呢?可以不关闭吗?
如果父进程只打开读写的fd,那么子进程也就只能继承读写的fd,这就坏事了,总得有人写入吧!那为什么不直接以读写方式打开一个fd呢?这样肯定不可以,子进程继承后也具有读写,也坏事了!
所以不关闭是为了让子进程可以继承下去,到时候关闭不需要的就可以了!当然也可以不关闭,只要你不乱使用,所以为了排除风险,建议直接关闭
4.2 管道通信的系统调用
了解了管道是什么,我们就来看看关于管道的系统调用是什么吧?
通过手册我们可以看到:
PIPE(2) Linux Programmer's Manual PIPE(2)
NAME
pipe, pipe2 - create pipe
SYNOPSIS
#include <unistd.h>
/* On Alpha, IA-64, MIPS, SuperH, and SPARC/SPARC64; see NOTES */
struct fd_pair {
long fd[2];
};
struct fd_pair pipe();
/* On all other architectures */
int pipe(int pipefd[2]);
#define _GNU_SOURCE /* See feature_test_macros(7) */
#include <fcntl.h> /* Obtain O_* constant definitions */
#include <unistd.h>
int pipe2(int pipefd[2], int flags);
新的pipe(int pipefd[2]) 是今天的主角(Ubuntu提供了新的选择pipe2),其实底层就是open。
pipefd[2] 这是一个输出型参数,把以读方式打开的文件描述符rfd和以写方式打开的文件描述符wfd记录下来!
和open不同的是,这个系统调用不需要文件路径和文件名,所以才叫匿名管道!
那么如果我们想要双向通信呢???
干脆建两个管道不就行了!
那为什么要进行单向通信呢?
因为这个管道的单向通信简单,对代码的复用率很高!
4.3 小试牛刀
接下来我们就来写一个demo,来试试管道接口。
首先我们来搭建一个框架:
- 建立一个管道,得到对应的文件描述符
- 创建子进程,关闭对应文件
- 我们进行子进程写入,父进程读取
- 等待子进程退出,避免僵尸进程出现!
#include<iostream>
#include<unistd.h>
#include<cstring>
#include<sys/wait.h>
#include<cerrno>
using namespace std;
void SubProcessWrite(int wfd)
{
}
void FatherProcessRead(int rfd)
{
}
int main()
{
//创建管道
int pipefd[2];//[0] -> r | [1] -> w
int n = pipe(pipefd);
if(n != 0)
{
perror("创建管道错误!\n");
}
cout << "pipefd[0] : " << pipefd[0] << " pipefd[1] :" << pipefd[1] << endl;
//创建子进程
//关闭对应文件
pid_t id = fork();
if(id == 0)
{
//子进程 -- write
close(pipefd[0]);
SubProcessWrite(pipefd[1]);
//使用完都关闭
close(pipefd[1]);
exit(0);
}
//父进程 -- read
close(pipefd[1]);
FatherProcessRead(pipefd[0]);
//使用完都关闭
close(pipefd[0]);
pid_t rid = waitpid(id ,nullptr , 0 );
if(rid > 0)
{
cout << "wait child process done!" << endl;
}
return 0;
}
管道本质也是文件,我们读写同样使用write和read。
我们完善一下代码:
- 子进程每隔一秒写入一次数据
- 父进程每隔一秒读取一次数据
#include<iostream>
#include<unistd.h>
#include<cstring>
#include<string>
#include<sys/wait.h>
#include<cerrno>
using namespace std;
string GetOtherMessage()
{
static int cnt = 0;
string messageid = to_string(cnt);
cnt++;
pid_t self_id = getpid();
string stringid = std::to_string(self_id);
string message = "messageid : ";
message += messageid;
message += "my pid :";
message += stringid;
return message;
}
void SubProcessWrite(int wfd)
{
string messages = "father,I am your soon process !";
while (true)
{
string info = messages + GetOtherMessage();
//写入管道时没有写入'\0',没有必要。在读取时添加
write(wfd , info.c_str() , info.size());
sleep(1);
}
}
#define size 1024
void FatherProcessRead(int rfd)
{
char inbuffer[size];
while (true)
{
//注意传入的参数 , 读取 rfd 内的数据到inbuffer中,返回成功读取的个数。
ssize_t n = read(rfd , inbuffer , sizeof(inbuffer) - 1);
if( n > 0 )
{
inbuffer[n] = '\0';//添加'\0'
cout << "father get message: " << inbuffer << endl;
}
}
}
int main()
{
//创建管道
int pipefd[2];//[0] -> r | [1] -> w
int n = pipe(pipefd);
if(n != 0)
{
perror("创建管道错误!\n");
}
cout << "pipefd[0] : " << pipefd[0] << " pipefd[1] :" << pipefd[1] << endl;
sleep(1);
//创建子进程
//关闭对应文件
pid_t id = fork();
if(id == 0)
{
cout << "子进程关闭不需要的fd , 准备开始发消息" << endl;
sleep(1);
//子进程 -- write
close(pipefd[0]);
SubProcessWrite(pipefd[1]);
//使用完都关闭
close(pipefd[1]);
exit(0);
}
cout << "子进程关闭不需要的fd , 准备开始接收消息" << endl;
sleep(1);
//父进程 -- read
close(pipefd[1]);
FatherProcessRead(pipefd[0]);
//使用完都关闭
close(pipefd[0]);
pid_t rid = waitpid(id ,nullptr , 0 );
if(rid > 0)
{
cout << "wait child process done!" << endl;
}
return 0;
}
运行看看:

这样验证管道通信的可行性。
5 总结
管道的4种情况
- 如果管道内部是空的 && write fd没有关闭:
读取条件不具备,读取进程会被阻塞 – wait 等待条件具备(写入了数据) - 管道别写满 && read fd 不读且没有关闭 :
管道被写满,写进程会被阻塞,写条件不具备-- wait 等待条件具备(读取走一部分数据才能继续写) - 管道一直在被读 && 写端关闭了wfd:
读端read的返回值会读到 0 ,表示到了文件结尾!!!所以可以在读取的时候进行一下判断,为0就直接退出读取! - rfd 直接关闭 , 写端wfd一直在写入:
首先管道只有一对读写端,读端被关闭了,那么管道就不能称之为管道了。OS系统也不会做这样的无用功,直接把broken pipe坏的管道 进行杀掉!会发送对应的13号信号SIGPIPE:

我们可以总结出管道的5 种特征:
- 匿名管道:只用来进行父子进程之间,因为他们可以看到同一资源
- 同步性:管道内部自带进程之间的同步机制!同步是多执行流代码的时候,具有明显的顺序性。父子进程的读写一定要同步进行,不然可能会出现并发读取的情况,出现错误!
- 文件的生命周期是随进程的:当一个文件没有进程调用的时候,就会释放掉!
- 管道在通信的时候,是面向字节流的:write 的次数和read的次数不是一一匹配的!
我们让子进程疯狂的写,父进程也一直读。子进程每 1 s写一次,写入时也向标准错误里进行打印(为了好观察)。父进程每5s读一次,并打印到显示器:
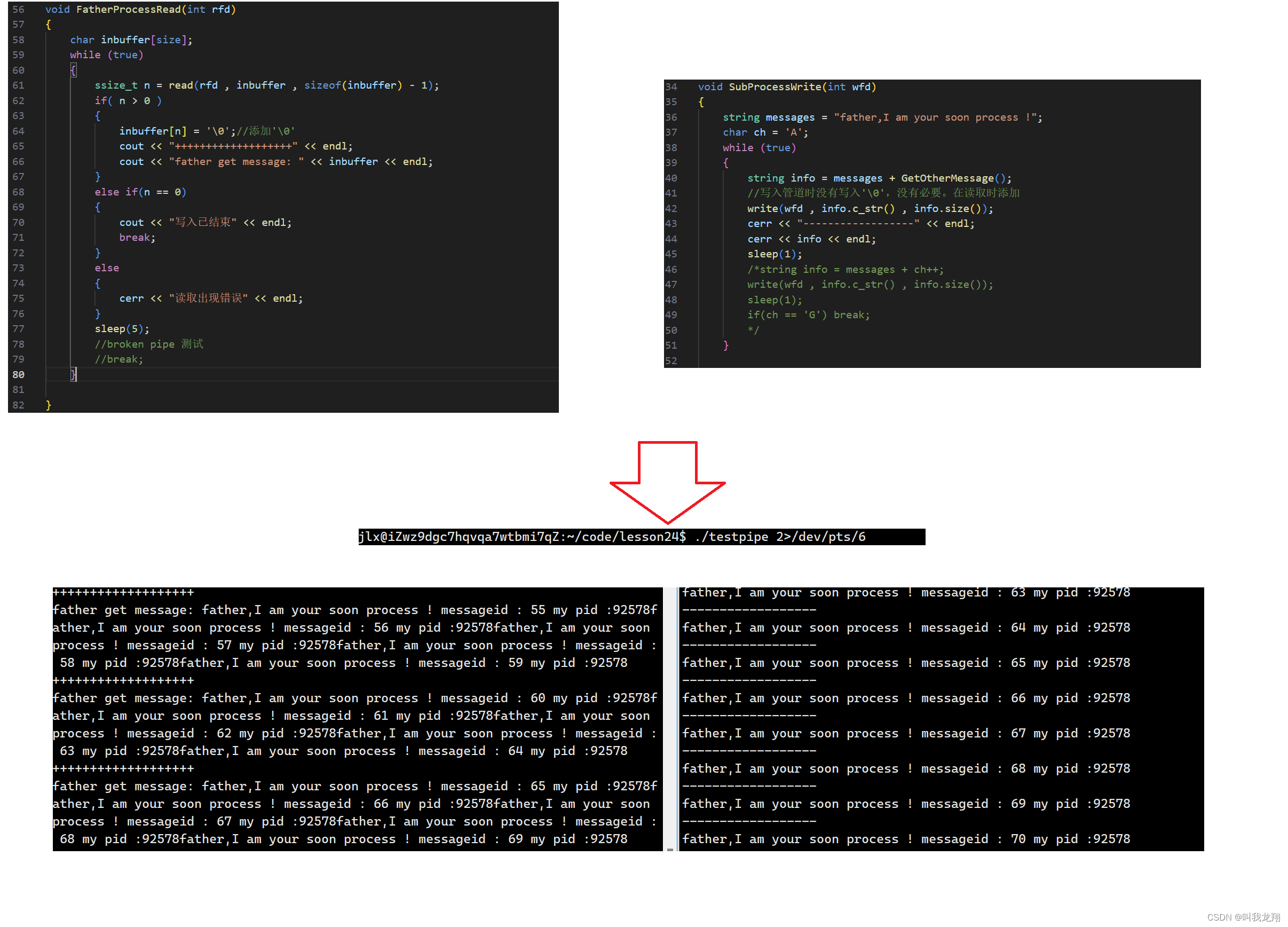
可以看到,右侧的子进程,左边是父进程。子进程写入好几次的数据,会被父进程一次读取一大批!!! - 管道的通信模式,是一种特殊的半双工模式:与之对应的是全双工模式,即双方交流可以同时说话。半双工是只能一方说话,一方聆听,不能同时说(对讲机模式)。
这里提一个概念,在管道读写是"原子"的,每个"原子"是 4096 bytes。只有小于这个大小,就不会在读写时被其他人影响。如果大于一个原子的大小,就不能保证安全了。

下一篇文章我们进行管道的实战——进程池项目!